Phoenix 加盐与优化
作者:互联网
Phoenix 加盐与优化
1. Phoenix 加盐SALT_BUCKETS
HBASE建表之初默认一个region,当写入数据超过region分裂阈值时才会触发region分裂。
加盐原理图解:
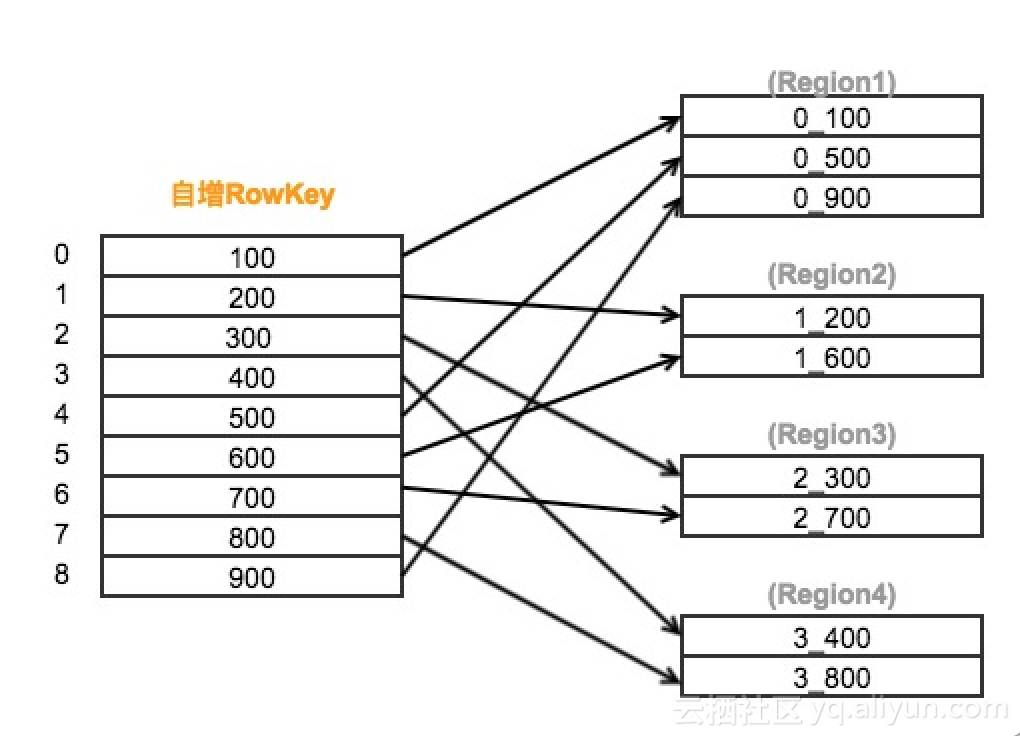
我们可以通过SALT_BUCKETS方法加盐,在表构建之初就对表进行预分区。SALT_BUCKETS值的范围是1~256(2的8次方),一般将预分区的数量设置为0.5~1 倍核心数。
加盐的原理是在原始的rowkey前加上一个byte,并填充由rowkey计算得出的hash值,使得原本连续的rowkeys被均匀打散到多个region中,有效地解决了读写热点问题。较多的region同时也增加了表读写并行度,从而提升了HBase表的读写效率。
Phoenix Salted Table是phoenix为了防止hbase表rowkey设计为自增序列而引发热点region读和热点region写而采取的一种表设计手段。通过在创建表的时候指定SALT_BUCKETS来实现pre-split(预分割)。如下表示创建表的时候将表预分割到20个region里面。
CREATE TABLE SALT_TEST (a_key VARCHAR PRIMARY KEY, a_col VARCHAR) SALT_BUCKETS = 20;
#表指定分区数 CREATE TABLE test_salt ( hrid varchar not null primary key, parentid bigint, departmentid varchar )SALT_BUCKETS=40; #索引指定分区数 (索引不指定预分区数时,其默认分区数与表保持一致) CREATE INDEX idx_test_salt_departmentid ON TESTN(departmentid) SALT_BUCKETS=20;
又譬如:
CREATE TABLE IF NOT EXISTS Product (
id VARCHAR not null,
time VARCHAR not null,
price FLOAT,
sale INTEGER,
inventory INTEGER,
CONSTRAINT pk PRIMARY KEY (id, time)
) COMPRESSION = 'GZ', SALT_BUCKETS = 6
默认情况下,对salted table创建二级索引,二级索引表会随同源表切进行Salted切分,SALT_BUCKETS与源表保持一致。当然,在创建二级索引表的时候也可以自定义SALT_BUCKETS的数量,phoenix没有强制它的数量必须跟源表保持一致。
由于加了盐的数据最前面多了一位,这样默认情况下,从不同 region server 取出来的数据无法按原来的 row key 排序,如果需要保证排序,需要改一个配置。
(1)实现原理
Phoenix Salted Table的实现原理是在将一个散列取余后的byte值插入到 rowkey的第一个字节里,并通过定义每个region的start key 和 end key 将数据分割到不同的region,以此来防止自增序列引入的热点问题,从而达到平衡HBase集群的读写性能的目的。
salted byte的计算方式大致如下:
hash(rowkey) % SALT_BUCKETS
SALT_BUCKETS的取值为1到256。
默认下salted byte将作为每个region的start key 及 end key,以此分割数据到不同的region,这样能做到具有相同salted byte的数据能够位于同一个region里面。
(2)SALT_BUCKET的本质
Salting能够通过预分区(pre-splitting)数据到多个region中来显著提升读写性能。
Salting 翻译成中文是加盐的意思,本质是在hbase中,rowkey的byte数组的第一个字节位置设定一个系统生成的byte值,这个byte值是由主键生成rowkey的byte数组做一个哈希算法,计算得来的。Salting之后可以把数据分布到不同的region上,这样有利于phoenix并发的读写操作。关于SaltedTable的说明在 http://phoenix.apache.org/salted.html。
salted table可以自动在每一个rowkey前面加上一个字节,这样对于一段连续的rowkeys,它们在表中实际存储时,就被自动地分布到不同的region中去了。当指定要读写该段区间内的数据时,也就避免了读写操作都集中在同一个region上。
简而言之,如果我们用Phoenix创建了一个saltedtable,那么向该表中写入数据时,原始的rowkey的前面会被自动地加上一个byte(不同的rowkey会被分配不同的byte),使得连续的rowkeys也能被均匀地分布到多个regions。
(3)实例
CREATE TABLE SALT_TEST (a_key VARCHAR PRIMARY KEY, a_col VARCHAR) SALT_BUCKETS = 4;
UPSERT INTO SALT_TEST(a_key, a_col) VALUES('key_abc', 'col_abc');
UPSERT INTO SALT_TEST(a_key, a_col) VALUES('key_ABC', 'col_ABC');
UPSERT INTO SALT_TEST(a_key, a_col) VALUES('key_rowkey01', 'col01');
从phoenix sqlline.py查询数据,没感觉有什么不同:
0: jdbc:phoenix:node1> select * from "SALT_TEST"; +---------------+----------+ | A_KEY | A_COL | +---------------+----------+ | key_ABC | col_ABC | | key_rowkey01 | col01 | | key_abc | col_abc | +---------------+----------+ 3 rows selected (0.024 seconds)
通过hbase shell 观察验证,观察到phoenix确实是在rowkey的第一个字节插入一个byte字节:
hbase(main):062:0* scan 'SALT_TEST' ROW COLUMN+CELL \x01key_ABC column=0:A_COL, timestamp=1539077357795, value=col_ABC \x01key_ABC column=0:_0, timestamp=1539077357795, value=x \x01key_abc column=0:A_COL, timestamp=1539077357747, value=col_abc \x01key_abc column=0:_0, timestamp=1539077357747, value=x \x03key_rowkey01 column=0:A_COL, timestamp=1539077359188, value=col01 \x03key_rowkey01 column=0:_0, timestamp=1539077359188, value=x 3 row(s) in 0.0440 seconds
这里,可以判断phoenix是在写入数据的时候做了处理,在插入数据的时候会计算一个byte字段并将这个字节插入到rowkey的首位置上;而在读取数据的API里面也相应地进行了处理,跳过(skip)第一个字节从而读取到正确的rowkey(注意只有salted table需要这么处理),所以只能通过phoenix接口来获取数据已确保拿到正确的rowkey。
(4)特别注意
可以看到,在每条rowkey前面加了一个Byte,这里显示为了16进制。也正是因为添加了一个Byte,所以SALT_BUCKETS的值范围在必须再1 ~ 256之间。而添加的这个Byte是根据什么来分的我就不得而知了,所以最好不要使用HBase的API插入数据。
因此,在使用SALT_BUCKETS的时候需要注意以下两点:
- 创建salted table后,应该使用Phoenix SQL来读写数据,而不要混合使用Phoenix SQL和HBase API
- 如果通过Phoenix创建了一个salted table,那么只有通过Phoenix SQL插入数据才能使得被插入的原始rowkey前面被自动加上一个byte,通过HBase shell插入数据无法prefix原始的rowkey
比如使用Hbase的BulkLoad API向SALT_BULKET的表中插入数据中插入数据,会出现ROW_KEY的第一个字节在Phoenix中查看少一位的情况,并且在Phoenix中使用ROW_KEY查询会出现查询不到结果的情况。
2. Pre-split
除了使用加盐直接指定分区数外,我们也可以使用split on手动设置分区。这种方法同样是在构建之初就对表进行预分区,较多的region能够增加hbase的并行度,从而提升读取、写入效率。由于对rowkey不引入额外的byte,因此不会改变rowkey的原始顺序。
#对表指定五个分区
CREATE TABLE test_split
(
hrid varchar,
parentid bigint,
departmentid varchar
CONSTRAINT my_pk PRIMARY KEY (departmentid, hrid))
SPLIT ON ('market','device','develop','sale');
3. 分列族
由于HBase表的不同列族是分开存储,因此把相关性大的列放在同一个列族,能够减少数据检索时扫描的数据量,从而提升读的效率。
#对列指定a、b两个列族 CREATE TABLE test_cf( a.hrid varchar not null primary key, a.parentid bigint, b.departmentid varchar);
4. 使用压缩
在数据量大的表上可以使用压缩算法来减少存储占用空间,从而提高性能 。常用的压缩方法有GZ,lzo等。
#对表实施GZ压缩 CREATE TABLE test_compress ( hrid varchar not null primary key, parentid bigint, departmentid varchar )COMPRESSION='GZ'
5. 二级索引
以Phoenix的全局索引为例,对departmentid建立全局索引,实际上是建立了一张索引表,索引表的rowkey由departmentid与原表rowkey拼接而来。由于departmentid是索引表rowkey的主维度,因此能够快速被查找并获取到对应的原表rowkey,再通过原表rowkey可以从原表中快速获取数据。
#建表 CREATE TABLE test_index ( hrid varchar not null primary key, parentid bigint, departmentid varchar ); #对departmentid建立全局索引 CREATE INDEX idx_test_index_departmentid ON test_index(departmentid);
6.参数优化
根据集群配置情况设置合理参数有助于优化HBase性能,可以在hbase-site.xml里配置以下参数
1. index.builder.threads.max (Default: 10) 为主表更新操作建立索引的最大线程数 2. index.writer.threads.max(Default: 10) 将索引写入索引表的最大线程数 3. hbase.htable.threads.max(Default: 2,147,483,647) 索引表写入数据的最大线程数 4. index.tablefactory.cache.size(Default: 10) 缓存10个往索引表写数据的线程 5. index.builder.threads.keepalivetime(Default: 60) 为主表更新操作建立索引的线程的超时时间 6. index.writer.threads.keepalivetime(Default: 60) 将索引写入索引表的线程的超时时间 7. hbase.htable.threads.keepalivetime(Default: 60) 索引表写入数据的线程的超时时间
标签:Phoenix,优化,region,索引,加盐,key,rowkey,byte,SALT 来源: https://www.cnblogs.com/tujic/p/13500985.html