用机器学习打造聊天机器人(三) 设计篇
作者:互联网
本文是用机器学习打造聊天机器人系列的第三篇,通过阅读本文你将对聊天机器人的实现有一个大致的思路。
我们的聊天机器人将具备什么样的特性?
- 用户可以使用人类自然语言的方式来表达自己的意图。
- 可以依据用户的反馈进行在线增量学习,使用的越久,能回答得问题越多。
- 采用非侵入式设计,通过几个简单的API就可以接入。
- 语料数据使用简单的txt格式,只要更换txt,就可以服务于不同的知识领域。
- 提供做为Demo的UI系统,带有简单的登录认证。
开源聊天机器人框架ChatterBot简介
本项目基于chatterbot0.8.7来开发,但不仅于此。让我们先对chatterbot做一个简单的了解。
什么是ChatterBot?
ChatterBot是一个基于机器学习的口语式对话引擎,基于python编写,可以基于已有的会话集合返回匹配问题的响应。ChatterBot的非侵入式语言设计,使得我们可以在其上训练任何语言的对话模型。
怎么使用chatterbot?
首先,安装chatterbot0.8.7版本:
pip install ChatterBot==0.8.7创建一个chat bot实例:
from chatterbot import ChatBot
chatbot = ChatBot("Ron Obvious")训练你的机器人:
from chatterbot.trainers import ListTrainer
# 对话语料对,一问一答
conversation = [
"Hello",
"Hi there!",
"How are you doing?",
"I'm doing great.",
"That is good to hear",
"Thank you.",
"You're welcome."]
trainer = ListTrainer(chatbot)
trainer.train(conversation)获取响应,"Thanks!"在上面的语料对中是没有的,但是其默认使用的Levenshtein distance算法能让引擎从问答对中选出一个相近的回答:
response = chatbot.get_response("Thanks!")
print(response) # 将输出You're welcome.ok,如果你也已经得到了上面的正确输出,你可能想说,就这么简单?其实如果从简单体验一下的角度来说,就是这么简单。但是如果你想做一个像那么回事的聊天机器人出来,那么还有一段路要走,比如Levenshtein distance算法其实过于简单了,会导致一些答非所问的情况,除此之外,还有一些其他我们需要完善的地方,具体会在下一个话题中讨论。
如此简单就实现了一个聊天机器人,其中有没有什么不妥?
的确,这里面是有一些问题的:
- chatterbot的默认实现,可以正常处理1000左右的问答对,但是随着数据量的继续增加,就会十几秒甚至几十秒才能获取到回答,以及更长的时间才能训练完成(这里有一点需要注意,就是chatterbot中提到的训练,其实就是将问答语料写入数据库中),这显然是不能接受的。
- 默认采用的Levenshtein distance算法在句子的相似度比较上过于简单了,它只关心一句话变成另一句话需要的最小的修改步骤有多少,认为步骤越少,两句话越相近,所以它并不会考虑句子中每个词的具体含义,比如不知道西红柿和番茄虽然每个字都不同,长度也不同,但是其实指的是同一个东西。
没错,我们要解决的主要问题就是上面列出的2个问题,概括来说就是2个方面,一个是性能,另一个是智能。虽然问题只有2个,但是解决起来确是要花费一番功夫的。
首先,让我们来分析一下性能的问题:
1、chatterbot默认采用sqlite数据库,sqlite是一个关系型数据库,非常轻量,无需配置和部署,但是当数据量比较大的时候,写性能相对mongodb等nosql数据库还是有差距的,对于我们的场景,由于不存在强事务要求,所以建议切换到mongodb数据库,你会发现训练速度会有较大的提升;
策略:chatterbot除了支持sqlite,还支持mongodb,所以可以通过修改配置的方式切换到mongodb数据库,示例如下:
chat = ChatBot(
bot_name,
database=bot_name,
database_uri=current_app.config['DATABASE_URI'],
storage_adapter="chatterbot.storage.MongoDatabaseAdapter")2、chatterbot将所有问答对存储在一起,比如在mongodb中,是存储在一个集合里的,这样匹配问题的时候,就要和所有的问答对数据比较一遍,如果数据量很大的话,效率肯定是很慢的;
策略:将问答对分类存储,比如在mongodb中,不同类型的问答对存储在不同的集合里,这一步称为意图分类,所以我们需要通过另外的算法来确定输入句子的意图类别,然后在指定类别下去判断句子和哪些问题更为近似,然后返回对应的回答。这样做的好处是方便维护,大体量的问答对被拆分到各个对应的类别下,分别匹配,体量自然会减少很多,并且某一类型的问答对的数据量增加,对其他类型问答对的响应速度没有直接的影响。
3、chatterbot区分问题和答案是根据句子是否出现在in_response_to属性下的text属性中来判断的,这导致需要先查询出in_response_to下的所有text,然后根据text再查出所有属于问题的句子,这样的查询效率是很低的;
策略:在准备问答对语料的时候,分别对问题和答案进行标识,比如用Q和A做前缀,这样存储到数据库中后,查询的时候就可以用Q来直接匹配出问题,而不需要多次查询数据库。
4、chatterbot默认采用Levenshtein distance算法将当前输入的问题和数据库里每一个问答记录进行比较,具体做法是先查出所有的问答句子,然后for循环进行一一比较,选择出最相似的句子做为响应返回,效率自然不会高。
策略:改为使用词向量进行比较,具体在下面的智能度策略中有介绍。
ok,我们再来聊聊如何提升chatterbot的智能度:
1、采用余弦相似度算法代替Levenshtein distance算法
Levenshtein distance算法只是单纯的计算一个句子变成另一个句子需要经过的最小的编辑步骤,并没有考虑句子中词汇本身的含义,所以它并能识别出"苹果"比起"香水"来说和"香蕉"在语义上靠的更近。而余弦相似度是指比较两个向量之间的余弦相似度,向量当然分别是输入句子的句向量和数据库中所有问题句子的句向量,而句子转为向量的方式是采用的word2vec,该方法在后续讲原理的部分会具体介绍,这里我们只需要知道词向量模型可以将词转为对应的向量,这些向量在空间中呈现一种语义上的关系,比如用词向量表示我们的词的时候,会发现 King的向量-Man的向量+Woman的向量=Queen的向量。
那么句子又是怎么转成向量的呢?这里我们采用了平均向量的方法,就是先对句子分词,然后将词向量相加再除以向量的个数。至于为什么余弦值可以表示两个向量的相似度,我们同样也会在原理的部分进行介绍。
2、采用向量化并行计算策略代替for循环比对
有了句子的向量表示后,我们就可以采用一些并行计算的方式来代替for循环,具体的操作是将所有数据放到一个矩阵中一起计算,CPU虽然远比不上GPU的并行计算速度,但是比起for循环的方式仍然可以带来几十到几百倍计算速度的提升。在此也体现了chatterbot的优秀设计,使得我们可以在不更改源代码的情况下就替换掉原有的匹配算法,具体见代码篇的介绍。
一个问题从输入到给出回复将经历什么?
到此,我们解释了为什么需要基于chatterbot再做一些事情,以及如何做,现在我们来看看一个问题从输入到给出回复具体经历了哪些步骤:
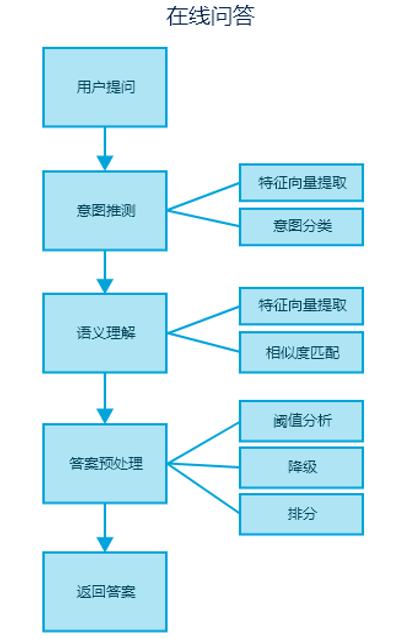
用户提问后,由意图推测组件接收问题,组件内部进行特征提 取后,传给意图分类器去预测问题所属的类别(比如:这是一个关于 “电影演员”的问题,或关于“电影上映时间”的问题),接着问题会传递到语义 理解模块,并自动触发合适的语义理解实例去尝试匹配问题对应的 答案,这里说的语义理解就是在指定的意图分类下,去匹配具体的问题,比如“你觉得功夫类电影谁演的好?”,或者“爱情片什么时间段上映比较合适?”等。整个过程主要是采用词向量模型构造问题句子的特征向量,通过贝叶斯算法进行意图分类,以及 采用余弦相似度算法计算问题和答案的匹配分数。此时引擎会根据 匹配分数结合阈值进行分析,从而决定是直接返回答案,还是降级处理,所以有些场景下可能会返回多个候选答案,候选答案会根据分数降序排列。
如何让机器人说我想听的话?
前面说的都是如何根据输入的问题给与合适的回复,本篇主要讨论如何调教机器人说你想听的回复,具体流程如下:
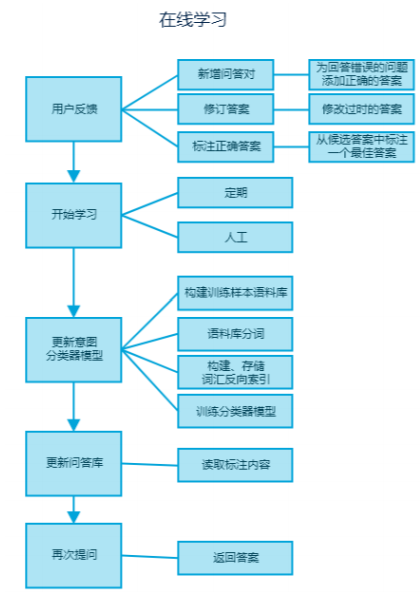
用户提问后,如果系统没能给出满意的答案,用户可以通过新增问答对、修订答案 2 种方式来进行反馈,当系统给出多个候选答 案,但是正确答案没有排在首位时,用户可以通过标注最佳答案来 进行反馈。可以定期让问答引擎自主学习用户的反馈,重新训练意 图分类器并更新问答语料库,当用户自己或其他用户再次问到相同 含义的问题时即可得到相应的答案。
由于我们可以自己调教机器人,所以你可以将其调教成仅属于你自己的独一无二的性格
标签:问答,机器人,问题,算法,聊天,打造,chatterbot,句子,向量 来源: https://www.cnblogs.com/anai/p/12012037.html