TracedModule: 更友好的模型表示方案,模型训练到部署的桥梁
作者:互联网
作者:曹文刚 | 旷视 MegEngine 架构师
TracedModule 介绍
TracedModule 是 MegEngine 中的一种模型格式,用于脱离模型源码对模型进行训练、量化、图手术和模型转换,它是模型训练到部署之间的桥梁。
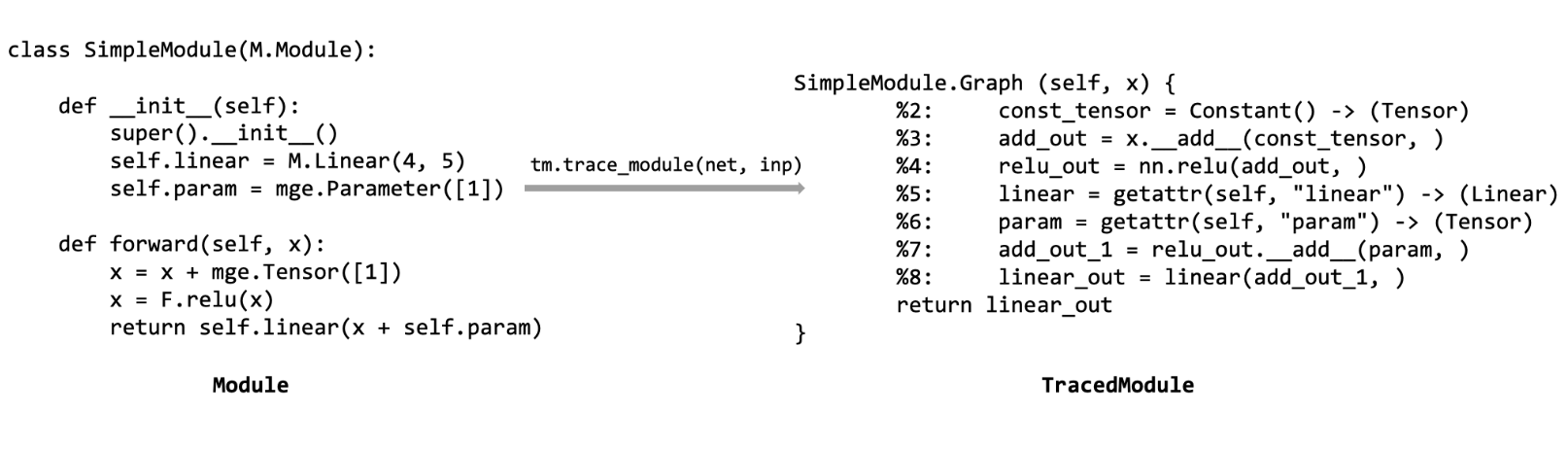
图 1 从一个普通 Module 生成 TracedModule
TracedModule 产生自普通的 Module,它通过以下两步得到:
- 运行一次 Module,记录并捕获模型运行过程中对输入 Tensor 的所有操作,对应图 1 中的
tm.trace_module - 通过一个由 5 种指令所构成的 “简单” 的 high-level IR(intermediate representation) 来描述捕获到的程序(普通 Module 中的 forward 方法),对应于图 1 中的
SimpleModule.Graph
TracedModule 的本质仍然是一个 Module,它与普通 Module 的区别在于: 普通 Module 通过用户实现的 forward 方法描述模型运行过程,而 TracedModule 通过 TracedModule IR 来描述模型的运行过程。TracedModule IR 由 python 的基本数据类型以及 Node 和 Expr 构成,其中:Node 用来表示一个 Tensor 或 Module,并记录了 Tensor 或 Module 的一些信息;Expr 用来表示对 Tensor 或 Module 的操作,它的输入和输出都是 Node。
TracedMdoule IR 中的 Expr 共有以下 5 种:
| OP | 含义 | 例子 |
|---|---|---|
| Input | 表示 Module 的输入,起到占位的作用 | \ |
| Constant | 表示产生一个常量 Tensor | mge.Tensor([1]) -> %2: const_tensor = Constant() -> (Tensor) |
| GetAttr | 表示获取 Module 的属性 | self.linear -> %5: linear = getattr(self, "linear") -> (Linear) |
| CallMethod | 表示调用 Module 的 forward 方法或 Tensor 的一些方法 | x + self.param -> %7: add_out_1 = relu_out.__add__(param, ) |
| CallFunction | 调用一个函数 | F.relu(x) -> %4: relu_out = nn.relu(add_out, ) |
通过以上 5 种 Expr 即可表示绝大部分模型的运行过程。
为什么要有 TracedModule?
如前文的介绍,TracedModule IR 是 TracedModule 中的核心数据结构,它用来描述深度学习模型的计算过程,使模型能够脱离源码而存在。不同的深度学习训练框架都有各自的 IR 描述模型,例如:PyTorch 中的 TorchScript,MindSpore 中的 MindIR,以及 onnx 等。这些 IR 大都是一些相对 low-level 的 IR,在模型源码向这些 IR 转换时常常会发生 python 的层 op 被转换为多个框架底层 op 组合的现象,例如 pytorch 中的 F.Linear 算子在导出到 TorchScript 时可能被导出为 matmul 和 add 的组合。用户在使用 low-levle 的 IR 表达的模型时会有很多的问题,例如:
- 不了解底层算子用户可能会很难从模型的可视化结构上与模型源码对应
- 普通用户学习 IR 结构较为困难,很难对模型进行图手术(修改模型图结构)或优化
这种 low-level 的 IR 表达能力往往更加完备,相应的也导致 IR 结构极其复杂,失去高层语义,使得用户难以做变换和优化,对模型设计者非常不友好。业界也提出了一些更加 high-level 的 IR 来解决这些问题,比如 torch.fx 和 pnnx 等,这些 IR 都对结构进行了简化,让 IR 的描述模型中的 op 粒度更高,更贴近算法工程师的视角,使得用户学习更简单,处理模型也更容易。
在 MegEngine 中,由多个底层 op 组合成的 python 层 op 更多,例如 "resize", "relu6", "softmax" 等,如果直接通过底层 op 表达模型,将会出现导出的模型结构谁也不认识的窘况。为了解决这些问题,MegEngine 参考 torch.fx 和 TorchScript 方案,改进得到 TracedModule 方案。TracedModule 的 IR 是一个 high-level 的 IR,它所描述的 op 粒度基本与 MegEngine 的 python 层的 op 一致,模型中的 op 粒度与用户视角一致,用户可以很容易地基于 TracedMdoule IR 对模型进行分析,优化和转换。另外前文提到 TracedMdoule 的本质是一个 Module,用户也可以方便地使用 MegEngine 的模型训练接口对 TracedModule 模型进行训练或参数微调。
TracedModule 好在哪?
TracedModule 全部由 python 层的数据结构构成,trace_module 函数在捕获用户代码的运行逻辑时仅记录模型中使用的 MegEngine python 层的 function 或 Module,这使得 TracedModule IR 所描述的 op 粒度基本与 MegEngine 的 python 接口一致,即 TracedModule IR 描述的模型是由更加接近用户视角的高层 op 构成,这使得用户对模型进行一些分析和优化时更加的容易,例如:
- 对 MegEngine 的 python 用户更加友好,熟悉 MegEngine python 接口的用户便天然的熟悉了由 TracedModule 表示的模型
- 转换出的模型结构可视化时更为干净清晰,用户很容易的便可将转换后的模型结构与模型源码对应
- 对模型进行分析,优化和向第三方推理框架转换时更容易,比如:模型量化,算子融合,转换器等
干净的模型表示
更高层 op 的粒度表示使得模型源码转换为 TracedModule 后的模型结构更加干净清晰,用户很容易的便可以将转换后的模型结构与模型源码进行对应,便于用户对模型进行分析和调试。
这里以一个常用的激活函数 relu6 为例,该激活函数在 MegEngine 中的 python 接口如下所示:
def relu6(x):
relu6 = _get_relu6_op(x.dtype, x.device)
(x,) = relu6(x)
return x
def _get_relu6_op(....)
...
def relu6(inputs, f, c):
(inp,) = inputs[0:1]
max_0 = f("max", inp, c(0))
min_6 = f("min", max_0, c(6))
oup = min_6
(oup_grad,) = yield (oup,)
...
return relu6
...
relu6 函数在 MegEngine 底层实际上是调用了两个算子,分别是模式为 MAX 和 MIN 的 Elemwise 算子,熟悉 MegEngine python 源码的同学应该能够从上面的代码中看出 relu6 的前向实现里调用了两个 elemwise 算子,如图 2 所示。

图 2 relu6 的 python 接口和底层实现
如果将一个调用了 relu6 函数导出至由底层 op 所构成的模型,其可视化结果将会如图3 所示,可以看到 relu6 变成了两个 Elmwise 算子,在这个结构中我们看不到任何关于 relu6 的信息,不熟悉 MegEngine 底层源码的用户面对这样一个模型是比较懵的。
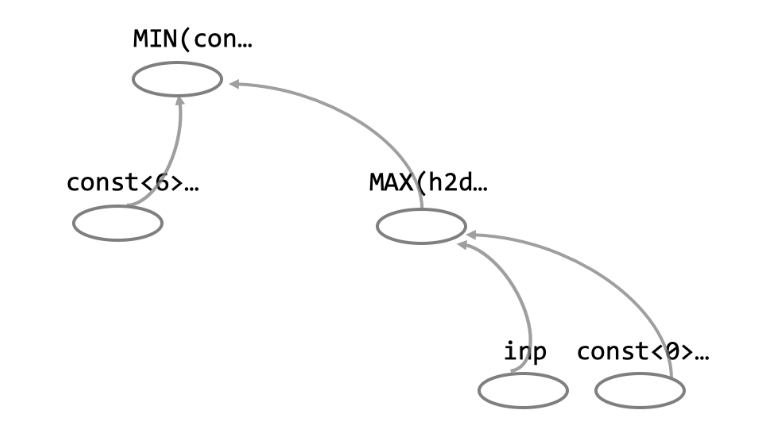
图 3 可视化由底层算子构成的 relu6
但如果将该模型代码转化至 TracedModule 后,将会得到如图 4 这样一个模型,可以看到 relu6 这个激活函数的信息完整的存在于 TracedModule 中,并不会被转变为 Elemwise 等其它算子。用户可以容易的从 TracedModule 中找到与模型源码所对应的模块。

图 4 转化到 TracedModule 中的 relu6
类似 relu6 这样的 op 在 MegEngine 中还有很多,例如 leaky_relu、interpolate、conv_transpose2d 等都由多个底层的 op 拼合而成,有些可以从 python 接口的源码中看出其在底层的实现,有些却不太容易看出。可以想象,一个看起来干净的使用 MegEngine python 层 op 构建的模型代码,在导出为由框架底层 op 构成的模型后,将会出现模型作者也很难从模型的可视化结构中找到模型某些结构的窘况。但将模型源码导出为由更高层 op 构成的 TracedModule 后,将不会或很少会出现模型作者不认识可视化出的模型。
直观的模型图手术
将一个 MegEngine 训练出的模型转换至第三方的推理框架进行推理时,常常需要通过图手术对模型结构进行一些修改来满足第三方框架的要求。基于 TracedModule 对模型进行修改是非常容易的,如前文提到 TracedModule 模型中的 op 粒度与用户视角一致,并且构成 TracedModule 的基本数据结构也都是用户熟悉的 python 数据结构,只需要了解 TracedModule IR 的基本组件,用户就可以方便的对 TracedModule 所表示的模型运行过程进行修改。
这里以一个常用于检测模型 Head 模块中 box 分支的操作为例:
F.relu(conv(bbox_subnet) * scale) / stride
其中 conv 是一个普通的卷积,scale 和 stride 是两个常量 Tensor。在 relu(x)∗y 中,当y>0 时,显然relu(x)∗y 与relu(x∗y)等价,所以在转换上述操作时,常常会将 scale 和 stride 吸到 conv 的权重中,吸掉 scale 和 stride 后的模型结构将更加的简单,并且也方便转换到一些算子较少的中间模型格式,例如 caffe。在 TracedModule 中我们可以很容易的定位上述操作,并利用 图手术接口 完成对 scale 和 stride 的吸收。图手术代码如下所示。
graph = traced_head.graph
# 由 conv 的权重吸收 sacle 和 stride
traced_head.conv.weight *= (traced_head.scale / traced_head.stride)
traced_head.conv.bias *= (traced_head.scale / traced_head.stride)
# 移除 Graph 中的乘 scale
mul_expr = graph.get_expr_by_id(5).as_unique()
graph.replace_node({mul_expr.outputs[0]: mul_expr.inputs[0]})
# 移除 Graph 中的除 stride
div_expr = graph.get_expr_by_id(8).as_unique()
graph.replace_node({div_expr.outputs[0]: div_expr.inputs[0]})
# 删除 Graph 中无有用的 expr
graph.compile()
如图 5 所示,模型修改完之后,通过 print(graph) 就能直接看到修改之后的图是否满足预期。另外,由于 TracedModule 的 runtime 是 MegEngine 的动态图,在模型运行或图手术时非常的容易调试。

图5 图手术优化前后的 Head 模块
写到这里可能有人会问,直接修改模型源码之后再转换岂不是更简单?但这会带来另外的问题,比如:模型落地过程中,模型可能会经过好几个人的处理;引用第三方库(例如 basecls 等) 进行模型生产时,直接修改底层源码显然是不通用的等。
为了提升用户体验,TraedMdoule 提供了许多常用的图手术接口,并尽可能的使用户在使用图手术接口时不需要理解和关注图内部的变化细节。在模型图手术之后,用户可以通过打印 Graph 查看图手术后的图是否符合预期,也可以像运行普通 Module 一样直接运行 TracedModule 来查看模型输出结果是否正确。能够使用 MegEngine 构建模型的用户,基本在了解 TracedModule 基本组件后,就可以对 TracedMdoule 模型进行图手术。另外,我们为每一个图手术接口写了详细的使用方法,并提供了一些常见的模型图手术 例子 供参考,欢迎大家来试用。
方便的量化模型部署
模型量化是深度学习模型部署过程中的一个重要环节,能够有效减少模型运行时所占用的计算资源,提高模型的运行速度。各个深度学习训练和推理框架都支持对模型的量化,MegEngine 同样提供了 模型量化模块 和丰富的模型量化算法。模型量化的方法大致可以分为以下两种:
- 量化感知训练(Quantization Aware Training, QAT),一般是在训练时插入伪量化算子来模拟量化,进而缓减量化带来精度损失
- 训练后量化(Post-Training Quantization, PTQ),一般是利用有限的输入数据对训练好的模型的权重和激活值进行量化
大多数的推理框架都支持 PTQ 方法对模型进行量化,用户只需要提供浮点模型和输入数据集,一般就可以利用框架提供的量化工具完成模型的量化。然而在 PTQ 无法满足模型的精度的要求时,便需要借助 MegEngine 等训练框架使用 QAT 方法对模型进行量化,进而提高模型量化的精度。
为了更好的支持 MegEngine 量化训练后的模型部署至第三方推理平台进行推理,MegEngine 团队开发了基于 TracedModule 模型转换工具 mgeconvert 来支持量化模型部署到第三方。TracedModule 不仅支持 MegEngine 底层的量化方式,同时也支持各种自定义的量化算法,这使得基于 TracedModule 导出的量化模型,一般在转换后也能够满足目标平台的量化要求,减小定点模型和伪量化模型之间的差异。用户只需要将 TracedModule 模型输入到 mgeconvert 就可以得到以下两类模型:
- 浮点模型表示(caffe, onnx, tflite)+ 量化参数文件
- 定点模型表示(tflite)
即 mgeconvert 既支持导出目标平台的浮点模型和量化参数文件,也支持导出目标平台的定点模型。用户可以方便的使用 MegEengine 量化模块对模型进行量化,量化后也可以方便的使用 mgeconvert 将模型转到预期的推理平台,mgeconvert 使用方法见 这里,欢迎试用。
总结
TracedModule 是 MegEngine 设计的一种模型格式,设计之初便着重考虑了面向用户视角的 op 粒度,模型图手术,量化模型部署等问题,并在文中对这些问题以及 TracedModule 的效果进行了简单的介绍。未来 MegEngine 团队也会开发更多基于 TracedModule 的模型发版工具,例如:模型量化工具,模型优化工具等。最后,欢迎大家来试用 TracedModule,也欢迎大家提出建议来一起完善 TracedModule。
标签:模型,IR,模型表示,MegEngine,量化,TracedModule,友好,op 来源: https://www.cnblogs.com/megengine/p/16482329.html