面向对象第四单元总结暨课程总结
作者:互联网
面向对象第四单元总结暨课程总结
fishlife
目录写在前面
最后一个单元在忙碌的考期中结束,我的OO课程在这画上了一个圆满的句号。
UML全称统一建模语言,其通过对一个系统进行建模,以图的方式描述了该系统的工作流程。且上述中”系统“并不局限于软件系统,UML也可以描述非软件系统的工作,可以说用途非常广泛。并且其代码层面采用了json格式描述其模型之间个元素的关系,这使其可以很容易地被不同的UML解析器进行解析,其中包括我们熟知的starUML。
本单元需要我们编写一个简易的UML解析器去解析UML模型中的各个元素。这个单元和上个单元相比,在抛开编程具体细节的情况下非常类似。具体的实现并不难,难点在于如何将模型结构体现在代码中,以模型结构为基础构建代码的结构,只要这步做好了,后面每条指令的实现就不算难。
本单元关键词:UML模型和阅读理解
UML模型是本次作业的重难点,也是我们编写代码的基础。UML模型通过将所有元素封装成一个个对象的形式来描述自己的模型。这为我们使用JAVA等面向对象语言对其进行分析和建模提供了非常大的便利,这个特性也增强了UML自身的通用性。
正如上文所言,本章的实现并不难,重点在于理解UML的模型结构。这部分的阅读理解和上一单元的“阅读理解”类似但又不同。类似的地方是都需要去理解一套体系或规范来为自己的代码编写提供依据。不同的地方在于JML部分理解的是JML规格,其规格编写使用的语法与程序语言和离散数学的语言还比较接近,理解起来相对容易。但UML结构使用的是类封装的形式描述,并且通过肉眼看上去毫无规律的ID来标识对象。所以其理解起来的难度会比较大。
UML解析器架构设计
由于三次作业都是在原有基础上添加指令,整体输入的UML图结构并没有改变。所以我代码的结构也没有什么改变。这里不按照每次作业分开介绍架构。而是总体进行介绍。同时对一些比较难实现的指令介绍一下我实现的算法。
解析器架构
详细介绍解析器架构之前,需要先了解UML的模型。
本次作业中涉及到的UML图有类图和顺序图和状态图,并且我们可以通过手册去迅速地了解每张图的具体架构。但是,手册上的架构图是不完全的,且图的展示思路和我的设计思路有所出路。所以下面放出我自己的三张在这单元作业中用到的元素组成的完整架构图。
首先是类图。

可以看到,我连接元素的依据是他们在json中的“父子关系”,即下层的元素的parentId对应的元素类型是其关系箭头指向的元素类型。而我的架构设计将基于这张图进行。
剩下的顺序图和状态图的构造原理相同。
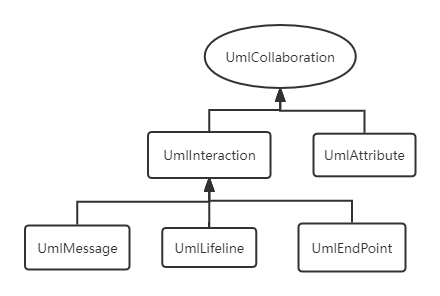
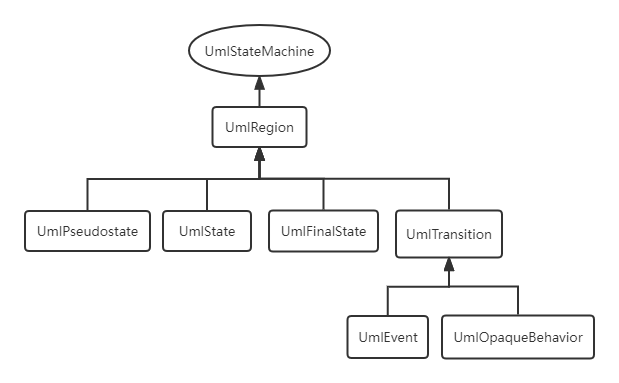
正如上面所言,箭头表示的是元素间“父子”关系。但是这里的“父子”关系实际上并不像面向对象里的子类与父类之间的关系,更像是一种聚合的关系。以类图为例,即UmlClass类内含有UmlAttribute、UmlOperation、UmlAssociation等对象,UmlOperation类内有UmlParameter等,其更像是一种一对多的聚合关系。所以在代码实现中我也是这么做的。并且使用了类似装饰者模式的设计,用一个类KernelABC来包装Uml模型元素类ABC,其属性包含了一个被包装类,并且增加了对被包装类处理进行处理的方法。比如KernelUmlOperation类的代码如下。
public class KernelUmlOperation {
private final UmlOperation operation;
private final HashMap<NamedType, ArrayList<UmlParameter>> namedParameters;
private final HashMap<ReferenceType, ArrayList<UmlParameter>> referenceParameters;
private UmlParameter returnValue;//不会在上面两个map中出现
public int calculateCouplingDegree(String classId) {
//只考虑referenceType
//自己这类不计入耦合度
//重复的Type只计算一次
//耦合度需要计算参数与返回值两类
HashSet<String> referenceTypeIdSet = new HashSet<>();
referenceTypeIdSet.add(classId);
for (ReferenceType type: referenceParameters.keySet()) {
referenceTypeIdSet.add(type.getReferenceId());
}
if (returnValue != null && returnValue.getType() instanceof ReferenceType) {
ReferenceType referenceType = (ReferenceType) (returnValue.getType());
referenceTypeIdSet.add(referenceType.getReferenceId());
}
return referenceTypeIdSet.size() - 1;
}
//其他方法略
}
其属性包括一个被包装类UmlOperation和图中显示的与其有聚合关系的UmlParameter。这里因为每个UML元素都有一个唯一的ID,所以采用HashMap对其进行存储。以上虽然只举了类图的例子,但是顺序图和状态图的道理是一样的。
为了方便编程,除了按照上面的图表示的聚合关系进行元素的包装之外,我对一些类进行了统一抽象。比如从类图的UML结构中可以看出,UmlClass和UmlInterface含有的元素实际上是完全一样的,并且那些关系(泛化、实现、关联)的两端既可能是类、也可能是接口。所以我使用一个抽象类AbstractUmlClassInterface对其进行了统一管理,让具体的KernelUmlClass和KernelUmlInterface继承它。
public abstract class AbstractUmlClassInterface {
private HashMap<String, UmlAttribute> attributeIdMap;
private HashMap<String, ArrayList<KernelUmlOperation>> operationNameMap;
private HashMap<String, KernelUmlOperation> operationIdMap;
private ArrayList<AbstractUmlClassInterface> generalizationClassInterfaces;
private ArrayList<KernelUmlInterface> realizationInterfaces;
private ArrayList<KernelUmlAssociation> associations;
private ArrayList<AbstractUmlClassInterface> children;
private String id;
public void init() {
this.associations = new ArrayList<>();
this.attributeIdMap = new HashMap<>();
this.generalizationClassInterfaces = new ArrayList<>();
this.operationIdMap = new HashMap<>();
this.realizationInterfaces = new ArrayList<>();
this.operationNameMap = new HashMap<>();
this.children = new ArrayList<>();
}
//其他方法略
}
public class KernelUmlClass extends AbstractUmlClassInterface {
private final UmlClass umlClass;
//方法略
}
public class KernelUmlInterface extends AbstractUmlClassInterface {
private final UmlInterface umlInterface;
//方法略
}
使用抽象类后,编写指令相关代码,尤其是涉及关联关系时就无需为了进行强制转换而考虑关联两端的具体类型。
类似地,顺序图中的UmlLifeline和UmlEndpoint也有着非常多类似的方法,他们都可以对信息进行收发等操作,所以我也将其抽象出一个
抽象类AbstractLifelineEndPoint。让KernelUmlLifeline和KernelUmlEndPoint继承它。
public abstract class AbstractLifelineEndpoint {
private HashMap<String, UmlMessage> otherSendMessageIdMap;//不包含lost消息
private HashMap<String, UmlMessage> lostMessageIdMap;
private HashMap<String, UmlMessage> otherReceivedMessageIdMap;//包含create消息,不包含found消息
private HashMap<String, UmlMessage> foundMessageIdMap;
private HashMap<String, ArrayList<UmlMessage>> creatorIdMessageMap;//创建者id映射创建消息
private ArrayList<UmlMessage> messages;
public void init() {
otherSendMessageIdMap = new HashMap<>();
lostMessageIdMap = new HashMap<>();
otherReceivedMessageIdMap = new HashMap<>();
foundMessageIdMap = new HashMap<>();
creatorIdMessageMap = new HashMap<>();
messages = new ArrayList<>();
}
//其他方法略
}
public class KernelUmlEndPoint extends AbstractLifelineEndpoint {
private final UmlEndpoint umlEndpoint;
//方法略
}
public class KernelUmlLifeline extends AbstractLifelineEndpoint {
private final UmlLifeline umlLifeline;
//方法略
}
同样地,状态图中的UmlPseudoState,UmlState和UmlFinalState实际上同样都是状态,只是UmlPseudoState和UmlFinalState分别代表initialState和finalState,有着一些额外的属性。所以这也很适合用一个抽象类AbstractUmlState去统一管理,让三个状态类去继承它。
public abstract class AbstractUmlState {
private HashMap<String, KernelUmlTransition> transitionIdMap;
private String id;
private String name;
public void init(String id, String name) {
this.transitionIdMap = new HashMap<>();
this.id = id;
this.name = name;
}
//其他方法略
}
public class KernelUmlPseudoState extends AbstractUmlState {
private final UmlPseudostate pseudoState;
//方法略
}
public class KernelUmlState extends AbstractUmlState {
private final UmlState umlState;
//方法略
}
public class KernelUmlFinalState extends AbstractUmlState {
private final UmlFinalState umlFinalState;
//方法略
}
综上,整体结构通过聚合关系以及一些抽象类的统一,基本按照上面三张图建立了起来。
指令及规则检查实现
由于有上面的结构支撑,实现指令的操作可以通过指令传递的形式实现。在我们负责的代码中,第一时间接收到指令的是我们实现UserApi的那个类(我的是KernelApi)。如果将所有信息都存放于这一级,那么指令自然可以在这一级执行,但是我的代码结构参照了三张UML结构图,所以最后出来的代码结构也会形成一种类似的层级结构。
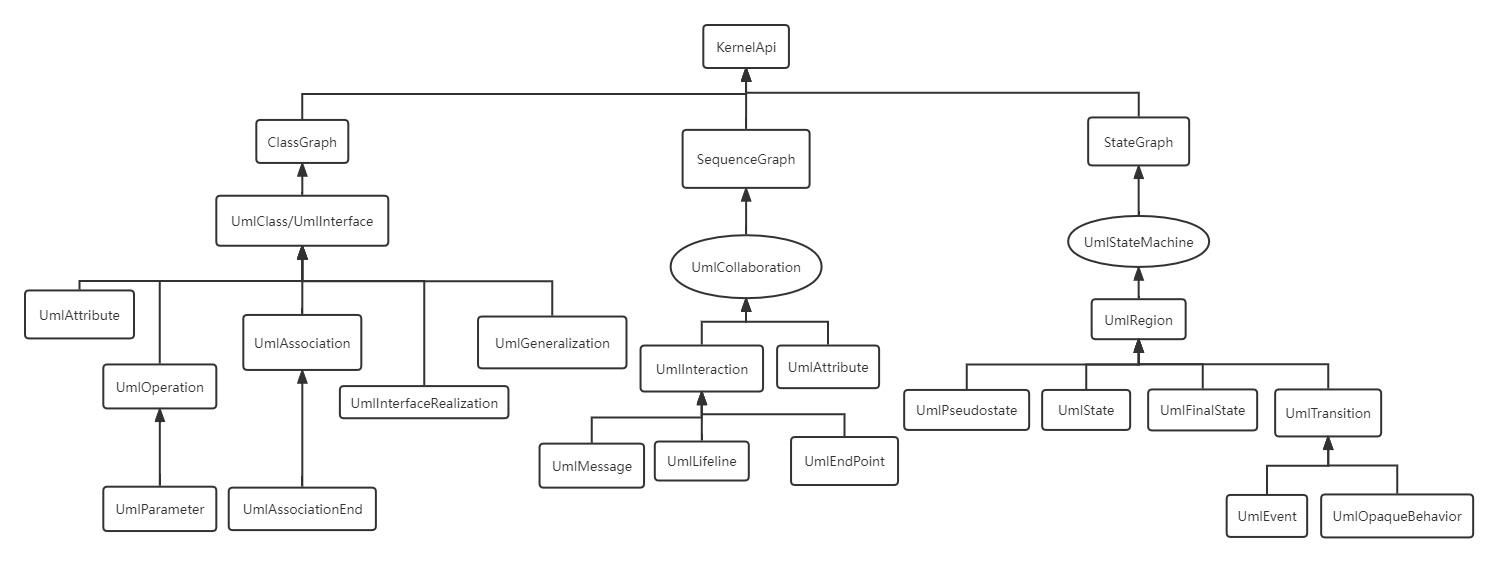
我的做法是,根据指令的要求,在每一级判断他是否能执行,能执行或者能执行一部分则在该级执行,然后将指令传递给下一级,直到指令全部执行完毕。有些指令可能需要对下级执行的结果进行汇总和处理。在指令传递链中靠上层的对象要做的就是将指令传递给下级并对下级反馈的结果进行汇总和处理,靠下层的对象要做的就是执行指令并将结果返回给上级。
这样处理的一个好处是将工作职责明确化,在debug时很容易通过输出结果直接定位bug出现的地方。并且指令的传递基本上依靠一个方法调用语句即可实现,在上层出现bug的概率极低,所以出现bug时可以直接从bug指令的传递链的最底层向上查起。这一点在我修bug时帮我节省了不少的时间。
本章需要实现的指令难度并不算大,这里挑两个进行算法的说明,顺带说明上述的指令传递是如何起作用的。
-
指令 6:类的属性的耦合度
其指令传递链如下所示。
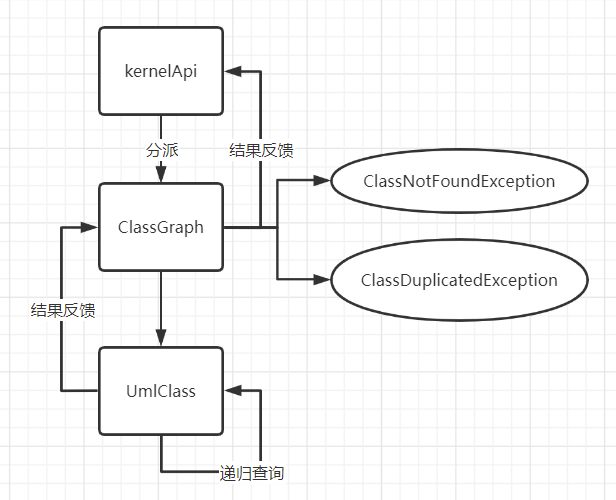
KernelApi收到指令后自动调用对应方法,该方法会调用
ClassGraph内的指令6对应方法。ClassGraph这一级会对指令做部分操作,即对类进行判断并决定是否抛出异常,显然我们需要找到对应的类后才能继续将指令传递下去。传递给下一级UmlClass后指令才被真正地执行,找出所有的属性并计算复杂度,然后将结果一层层返回给上级输出。 UmlClass层的指令6实现代码如下,由代码可以看出,实际上这里通过类似DFS的递归方式来计算复杂度,并且利用集合的特性自动实现去重,通过提前将本类的ID存入集合的方式来防止将自己计入复杂度中。
//ClassGraph public int getClassAttributeCouplingDegree(String classId) { HashSet<String> referenceTypeIdSet = new HashSet<>(); referenceTypeIdSet.add(classId); getAttributeSet(referenceTypeIdSet); return referenceTypeIdSet.size() - 1; } //UmlClass private void getAttributeSet(HashSet<String> referenceTypeIdSet) { //考虑继承,不考虑实现 //不考虑重名问题 //自己该类不计入耦合度 //只考虑referenceType,同类只需计算一次 //计算自己有的属性的耦合度 for (UmlAttribute attribute: attributeIdMap.values()) { if (attribute.getType() instanceof ReferenceType) { ReferenceType referenceType = (ReferenceType) attribute.getType(); referenceTypeIdSet.add(referenceType.getReferenceId()); } } //递归计算其父类的耦合度 for (AbstractUmlClassInterface umlClassInterface: generalizationClassInterfaces) { if (umlClassInterface instanceof KernelUmlClass) { umlClassInterface.getAttributeSet(referenceTypeIdSet); } } } -
规则检查R003:不能有循环继承。
本部分指令传递链与上述指令基本一致,只是
ClassGraph这一级抛出的异常改成了UmlRule003Exception。并且该规则检查需要遍历所有的类,去查找有没有循环继承的类,所以ClassGraph这一级也兼顾了整合下级UmlClass返回的结果的工作。 同样地,这里的算法实现也是使用类似DFS的方式进行递归,把每一条继承链找出来并判断是否有成环的链。这里我的处理比较简单,就是对每个类都做一遍检查,每次只检查自己是否重复出现在了继承链中,出现了就把自己的ID返回给
ClassGraph,ClassGraph将这些ID收集到后在HashMap里查找到对应的UmlClass/UmlInterface对应的KernelUmlClass/KernelUmlInterface,然后通过get方法得到被封装的UmlClass/UmlInterface并返回。 代码如下,可以发现其实这里装饰者模式我没有做全,做全的话装饰类
KernelUmlClass/KernelUmlInterface应该继承UmlClass/UmlInterface。这样可以直接返回装饰类,不用去访问内部被装饰的类。//ClassGraph public void checkCircleGeneralization() throws UmlRule003Exception { HashSet<UmlClassOrInterface> classOrInterfaces = new HashSet<>(); for (KernelUmlClass kernelUmlClass: classIdMap.values()) { if (kernelUmlClass.isSelfInCircleGeneralization()) { classOrInterfaces.add(kernelUmlClass.getUmlClass()); } } for (KernelUmlInterface kernelUmlInterface: interfaceIdMap.values()) { if (kernelUmlInterface.isSelfInCircleGeneralization()) { classOrInterfaces.add(kernelUmlInterface.getUmlInterface()); } } if (!classOrInterfaces.isEmpty()) { throw new UmlRule003Exception(classOrInterfaces); } } //AbstractUmlClassInterface public boolean isSelfInCircleGeneralization() { return isInCircleGeneralization(id, new HashSet<>()); } private boolean isInCircleGeneralization(String classId, HashSet<String> idSet) { for (AbstractUmlClassInterface umlClassInterface: generalizationClassInterfaces) { if (umlClassInterface.getId().equals(classId)) { return true; } else if (!idSet.contains(umlClassInterface.getId())) { idSet.add(umlClassInterface.getId()); if (umlClassInterface.isInCircleGeneralization(classId, idSet)) { return true; } idSet.remove(umlClassInterface.getId()); } } return false; }
bug情况
第十三次作业
强测出现了一个bug,就是在getClassAttributeCouplingDegree方法中,我原来的实现没有将属性中referenceTypeId的集合传递下去,而是每次新建了一个集合,并且通过递归的方式将在继承链上每个类计算出来的耦合度相加得到最终的耦合度。这种做法导致如果referenceType相同的属性分别在继承链上不同的类中时,他的耦合度就会被计算多次,导致出错。最终的改进就是变成前面算法部分展示的那样,提前设置好一个集合,将这个集合在递归中维护并传递下去。利用集合的去重功能便能解决上述问题。
第十四次作业
强测未出现bug。
第十五次作业
强测出现一个bug,在判断R007时,我用一个ArrayList存储了所有与该lifeline相关的信息,但是由于疏忽,在判断接收消息是否为DELETE_MESSAGE的地方忘了判断该消息的接收方是否为该lifeline导致其会将由该lifeline发出的DELETE_MESSAGE认为是删除自己的消息,导致出错。修复的话只需要在分支条件处加上对message.target的判断即可。
架构设计思维与OO方法演进
四个单元分别利用四种不同的例子,从四个角度对面向对象进行了阐述。显然,这四个单元是循序渐进的。实际上在做某个单元时,我们都是在结合前面所有单元已有经验的基础上再结合指导书进行该单元作业的架构构建与编写。除了面向对象之外,个人感觉我们的课程也教授了一些软件开发与测试的基本方法和技巧。这一路过来,我对面向对象的理解也从一窍不通到现在有了一个大致的轮廓。
第一单元:以表达式为载体介绍基本的面向对象
第一单元,我们实现了一个支持幂函数、三角函数、求和函数和自定义函数的单变量表达式化简程序。介绍了面向对象的三大特性:封装、继承和多态。在这个例子中,通过对表达式的三层结构Expr, Term, Factor的抽象能够很好地理解上面三大特性。
但很可惜的是,当时我的思想转变非常缓慢。从之前的博客中可以了解到,我在第三次作业时才真正理解了第一次作业中提到的表达式三层结构之间的类似”循环嵌套“的关系以及递归下降的使用,但显然这个速度是没办法支撑我按时写完作业的。所以这三次作业我用的是非常朴素的字符串处理加上栈来进行代码编写,而表达式的结构我是按照运算符和运算”数“进行的划分,没有按照上面的三层结构,这主要是为了适配我的字符串处理加栈的化简策略。除了这部分对表达式结构的划分和封装外,代码中透露出的面向对象不多,你可以从中感受到的是一种非常混沌的思想,里面夹杂着”switch case“的运算符判断和工具类的”面向过程式滥用“,总体而言,这份代码写得并不理想。
关于测试,本单元测试方法主要靠自行探索。由于本章作业的输出不唯一但是具有等价性,因此可以采用一个大家公认的第三方程序进行判定。我采用的测试方法和大多数人一样,就是利用python自带的库编写测试程序,在只有幂函数的情况下,python可以轻松判断两个式子的等价性,但当表达式复杂起来后就不行了,需要用多组数据代入的方式来判断式子的等价性。当然,除了自动测试外,自己构造一些边界数据和容易被遗漏的类型的数据也是很重要的,因为评测机在随机生成时很难做到全覆盖。这单元作业中,我就因为数据覆盖不完全而在sin(-1)上栽了跟头。这也让我对覆盖性测试有了更加深刻的印象。
第二单元:从电梯运作理解多线程下的面向对象
第二单元是我个人认为最有意思的一个单元。我们实现了一个多电梯系统调度的模拟。介绍了java中线程作为一个类是如何工作的,从多线程间相互协调的角度来理解面向对象。从这个单元开始,我才算是完全从面向对象的角度去审视和理解我的需求,并且和第一单元的手忙脚乱,走一步算一步不同,这次我有适当地预测一下需求(虽然几乎都扑空了),并在开始做架构设计时尽量地为未来开发预留一部分空间。同时,我也建立起一套自己做架构设计的标准。
对于某个新需求,架构对需求的适应程度我分为四个等级。
- 第一级:已有架构已经实现或几乎实现了新需求,此时只需要对程序进行非常少的改动即可实现新需求。
- 第二级:已有架构没有实现新需求,但是可以只通过添加类的方式(允许很小的修改)来实现新需求。
- 第三级:已有架构没有实现新需求,且需要通过修改原代码中相当一部分来实现新需求。
- 第四级:已有架构无法适配新的需求,需要重构。
第一级基本很难次次都实现,因为这除了代码功底外还需要对需求的准确预测。所以我从这次作业开始会使我的结构尽量保持在第二级的水平。而这种划分也很好地符合面向对象的开闭原则。而这次作业我也很好地贯彻了这一点,从第二单元博客中类图的演进可以看出来,每次需求的变化我基本只依靠添加新的类就可以完成,不需要改动原有代码。上述的架构设计标准也成功让我失去了”重构“的经验。
对于面向对象的抽象上,这次我理解得比较透彻,尝试利用接口和抽象类对一些具有共同特性的类进行抽象,并且第一次尝试使用设计模式,显然这二者之间是相辅相成的。并且从线程类(继承了Thread类或实现了Runnable接口的类,下同)中也可以看出类作为面向对象语言的基本单元,其实质上就是对变量和函数(方法)的一个整合,我对类的实质有了更加深层次的认识,并且体会到面向对象的封装对多线程而言是有多方便,如果用C语言写的话,几个线程的代码很可能是混杂在一起的难以区分。
测试方面,我学习了一些多线程程序测试的方法。对于多线程程序,由于线程调度的不确定性,针对同一个测试点,却会有不同的输出结果。此时就凸现出了白盒测试的重要性。因为前面的作业,甚至是大一时候写的程序都是单线程的,同一输入必定对应同一输出,通过黑盒+断点测试完全足够测出bug所在的位置。但是在这个单元,黑盒和断点测试全部失效,我必须得利用我不熟悉的白盒测试来检查我的程序。由此我也提高了我的白盒测试能力,同时还推动我发现了jconsole这一java专属的调试工具,其可以类比原断点测试中的控制台(但是只能看),并且自带检测死锁功能。
总之,这一单元是我OO思想变化最大的一个单元(篇幅上也可以看出我写了很多),在架构设计上有了自己的体会,同时也扩充了我的测试方法库。
第三单元:从JML规格理解规范化下的面向对象
第三单元,我第一次接触到JML规格语言,个人感觉像是编程语言和数学逻辑语言的缝合体。本单元我们根据提供的JML规格,编写出一个模拟社交网络运行的程序。这个单元由于规格的存在,所以基本方向已经定好,整体自由度比较低,难度也随之下降。但是可以确定的是,正如“一千个读者就有一千个哈姆雷特“,一份规格对应的代码可以有非常多种。而JML规格中规定的主要是前置条件\require和后置条件ensure。细想一下这其实很像黑盒测试中的黑盒:我只负责保证输入合法性,你的输出需要符合我给出的条件。所以,JML规格个人对其的一个仅用于理解的解释是每个规格实际上都是规定了一个黑盒。而在这里每一个黑盒是一个方法或者一个类,类本身作为一个更大的黑盒存在。这种规格的描述很好地体现了面向对象中封装的意义——对私有数据的保护以及对实现细节的透明化。通过这次作业,我对面向对象这部分知识理解得更加透彻了。
这个单元我获得进步最大的地方是测试部分,这个单元我认识了JUnit,其作为一个单元测试工具可以很好地测试出方法实现的额正确性。而从这个单元开始,我逐步建立起一个自己的测试的流程。
- JUnit正确性测试(黑盒):使用JUnit工具,检查每个方法实现上的正确性。查出由于理解不到位或者细节未考虑而导致的基本正确性问题。
- 随机大量数据测试(黑盒):使用随机数据生成器,检查程序在大量数据轰炸下的正确性以及基本的鲁棒性。查出由于细节问题(一般是算法或者内存管理)导致的程序bug。
- 边界数据和极端数据测试(黑盒+白盒):根据需求以及自己编写的代码,构造对应的边界数据和极端数据进行测试,检查程序在这些比较刁钻的数据下的正确性和鲁棒性。查出那些因为未考虑到或者手误,甚至是算法使用不当导致的bug。
这一套下来,基本上可以查出绝大部分的程序bug,可能残存的一些奇怪的bug就需要经过白盒测试去查找程序逻辑本身的问题了。可以发现上述测试的逻辑是循序渐进的,测试使用的数据强度也在增加。而且在测试中我也发现一个规律,大部分的bug都可以在第一步被查出来,很少有bug会残存到第三步才会被发现,而第一步的测试实际上是最简单的,相当于是个事半功倍的过程。这套测试流程帮助我找出了许多的bug。另外,我对测试用的JUnit也提出了一些自己的看法,虽然上面的测试流程看上去很完备,但最后还是出现了一些bug。究其原因,在于测试流程的第一步中的”由于理解不到位或者细节未考虑而导致的基本正确性问题“有个前置条件,就是你对规格或者需求的理解必须是完全正确的,否则你根据错误的规格编写出来的JUnit测试自然也是错的。所以,JUnit并不是万能的,他必须建立在程序员对需求完全理解的基础上才能真正发挥作用。所以,整个测试流程前面还应该加一句”通读并理解背诵规格“。
第四单元:从UML建模可视化理解面向对象
这个单元我们实现了一个简易的UML解析器,可以对UML类图、顺序图、状态图进行分析并针对查询指令进行输出。UML自身也是采用了面向对象的模式,将UML模型的各个元素封装成对应类,在mdj文件中以json的形式展现。这样表示的一个好处就是它特别容易被软件进行解析,并且可以被不同的软件解析而不需要改变文件的格式。从UML对元素的处理中我也能收获一些面向对象的思想。除了UML本身之外,我实现的解析器的架构也尽量去适配UML图已经有的结构(见上),因为这样可以直接利用UML已有的封装好的类进行实现,并且其封装的属性和其UML结构有很大的关系。而后,我尝试使用装饰者模式为UML已经封好的类加上指令操作。这个建模过程中的架构设计思路还是遵从前面的”四级原则“,但是我学到了架构设计的一个小技巧,就是上面所言的利用已有的类“借势”,在这可以理解为我们在已有的UML架构上为其增加查询的功能,而这种“借势”不仅很好地发挥了类的可复用性,并且只需要添加代码即可实现新功能,无需改动原来的代码,符合开闭原则。这个技巧可以非常好地利用在对已有程序进行扩展的任务中。
该单元的测试步骤还是参照上面的几条,但是该单元一个比较重要的问题是数据制造的效率比较低。按照传统的方法,你只能去starUML一张一张画然后再一张一张转换成mdj进行测试,效率非常低,无法形成有规模数据集的测试。这时我意识到测试的另一个小方法——等价代换,既然画图很慢,并且我们程序最终接收到的输入也不是mdj文件里的,那我完全可以自己根据输入的格式造一个数据出来,并且输入的每一行都是一行json,可以直接利用java默认的toString或其他工具直接生成,只需要构建好对应的类和类里面属性的值即可,相较于直接画图而言高效而方便。所以完全根据这个写一个数据生成器,然后构造出一套评测系统来。不过这个方法的缺点就是生成的mdj文件没办法被识别,可能是因为id构成有一定规律,不能直接随机导致的(该数据生成器由于考期紧张等原因并未实现)。这种等价代换的小方法可以迁移应用到其他类似的地方来避免复杂而慢速的数据生成过程,但最好数据输入和你的程序是解耦的,否则这种处理很可能导致无法查出数据输入和程序对接时产生的bug。
总结
从以上论述可以看出,四个单元的作业让我的架构设计、面向对象思维和测试理解与实践都有了极大地提升,并且基本上都会在某个时间点后一下子理解得通透,然后在后续作业中对自己的理解进行补充和完善。
课程收获
知识上的收获基本上都列在上面。课程将我带入了面向对象的大门,促使着我初步建立起面向对象和架构设计的思维,并且在原来的基础上继续扩展测试的方法,我也对测试有了自己的一个见解,从中学到了许多工具的使用,在这不多赘述。
除了知识上的收获,这门课给我的另一个收获是:我理解了在软件设计中合理的计划与安排的重要性。以我们的作业为例,一次作业的开发时间只有一周(实际上不到一周,从具体时间上算只有五天左右),我需要在这段时间内完成设计、写代码、测试等一系列工作,并且期间还需要照顾到其他课程,此时做好整体的规划就显得尤其重要。比如我一般会把设计的ddl,尤其是第一次作业的设计时间尽量放长,以达到我前面所说的架构设计目的。这也导致我的每个单元第一次作业都做得相当“拖沓”,但是带来的好处正如上面已经提到的,四个单元中我没有做过一次重构。这种经验也非常适用于现实的软件开发中,设计部分做得好、做得充分的话,后续的开发和测试会节省相当多的精力,并且可以提前发现并排除一些bug,而显然,bug越早发现,对软件开发的损失越小。
这门课给我的另外一个收获则是:我又一次认识到了团队的力量。虽然大家的作业需要独自完成,不管是在讨论区还是在微信群,总能看到同学和助教们热火朝天的讨论。除此以外,线下和认识的几个同学一起讨论思路,互相理解和借鉴,取长补短。在思想的碰撞中,我和同时参与讨论的人的思路被打开了,衍生出其他一些有趣的想法,从而再一次推动谈话进程,形成一个良性的正反馈。而思路被打开本身也极大地提高了开发的效率和质量。在未来的软件开发中,更多的开发形式会是一个团队中每组人分别负责一个程序开发流程的不同部分,而不是像现在这样大家各自独立完成一整套开发流程。所以这份经验可以很好地迁移到未来的团队开发当中。
对课程的建议
以下是我根据课程学习的经验提出的三点建议,希望能给课程组提供一个参考。
- 部分指导书限制写得较为分散和模糊,可以对指导书中的所有限制在一个集中的地方进行一个统一的说明。这点在最后一个单元的指导书里体现得比较明显,从讨论区的活跃程度也可看出这章的指导书限制上有一些缺漏。你可以在指导书中的三、四、七、八部分找到和作业相关的限制,并且有些限制甚至是出现在前面作业的指导书和讨论区中,所以我的建议是将所有限制统一写在一个稍微集中的地方,查找限制时就不需要上下来回翻动指导书。
- 本次作业的bug修复和下一次作业的开放时间可以提前一些。现在实行的时间表是周天23:00互测结束,周一16:00开放bug修复,周一19:00开放下一次作业。对于那些bug比较少或者没有bug的同学,在周天23:00到周一19:00期间会形成大段的“OO真空期”。提早开放bug修复和下一次作业,对这部分同学而言可以更早地开始作业的编写,缓解ddl带来的压力,也能适当解决部分同学遇到的“完成作业时间不够”的问题。而对于那些bug较多的同学,由于最后ddl不变,所以对他们而言没有影响。综上,将时间提前对于整个学生群体而言是有益的。
- 可以将第四单元顺序稍微提前一点。显然,四个单元分别各自为阵,构成一个独立的模块,单纯从教学角度上讲四个单元的顺序不影响教学的效果。但是我们的OO课程大量引入UML图的表示方法以辅助学生理解,而UML本身却在最后一个单元才被学生完全地了解,使得大部分学生在看前面的UML图时只是知其然而不知其所以然。这点在第二单元体现得比较明显,第二单元要求做出电梯工作的时序图,但是时序图在那个课堂教学阶段还未被提及,学生只能自己找资料去绘图,结果就是画出来的图“八仙过海,各显神通”,起不到理想的效果。所以,这里建议可以将第四单元的顺序稍微提前,或者在前面穿插一些对UML的描述也是可行的。
最后的最后
在最后的一节课中,我们举行了颁奖仪式,说实话那个氛围处理得挺好,不知道的还以为我毕业了(乐)。
整个课程走下来,一句话总结就是:累但很充实。这期间非常感谢老师和助教的辛勤付出,也感谢他们在我困难的时候能够耐心地为我解决困难。这个课程或许将成为我大学印象最深刻的课之一。
虽然课结束了,但是我的旅途没有结束,OO课上学到的东西将会成为我未来的宝贵财富,陪伴我走完我的求学路。告别面向对象课程,继续踏上新的征程。希望有缘,我们江湖再见。
标签:作业,总结暨,private,面向对象,课程,UML,bug,单元 来源: https://www.cnblogs.com/fishlife/p/16418683.html