以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
作者:互联网
背景
字节跳动 Data Catalog 产品早期,是基于 LinkedIn Wherehows 进行二次改造,产品早期只支持 Hive 一种数据源。后续为了支持业务发展,做了很多修修补补的工作,系统的可维护性和扩展性变得不可忍受。比如为了支持数据血缘能力,引入了字节内部的图数据库 veGraph,写入时,需要业务层处理 MySQL、ElasticSearch 和 veGraph 三种存储,模型也需要同时理解关系型和图两种。更多的背景可以参照之前的文章。
新版本保留了原有版本全量的产品能力,将存储层替换成了 Apache Atlas。然而,当我们把存量数据导入到新系统时,许多接口的读写性能都有严重下降,服务器资源的使用也被拉伸到夸张的地步,比如:
- 写入一张超过 3000 列的 Hive 表元数据时,会持续将服务节点的 CPU 占用率提升到 100%,十几分钟后触发超时
- 一张几十列的埋点表,上下游很多,打开详情展示时需要等 1 分钟以上
为此,我们进行了一系列的性能调优,结合 Data Catlog 产品的特点,调整了 Apache Atlas 以及底层 Janusgraph 的实现或配置,并对优化性能的方法论做了一些总结。
业务系统优化的整体思路
在开始讨论更多细节之前,先概要介绍下我们做业务类系统优化的思路。本文中的业务系统,是相对于引擎系统的概念,特指解决某些业务场景,给用户直接暴露前端使用的 Web 类系统。
优化之前,首先应明确优化目标。
与引擎类系统不同,业务类系统不会追求极致的性能体验,更多是以解决实际的业务场景和问题出发,做针对性的调优,需要格外注意避免过早优化与过度优化。
准确定位到瓶颈,才能事半功倍。
一套业务系统中,可以优化的点通常有很多,从业务流程梳理到底层组件的性能提升,但是对瓶颈处优化,才是 ROI 最高的。
根据问题类型,挑性价比最高的解决方案。
解决一个问题,通常会有很多种不同的方案,就像条条大路通罗马,但在实际工作中,我们通常不会追求最完美的方案,而是选用性价比最高的。
优化的效果得能快速得到验证。
性能调优具有一定的不确定性,当我们做了某种优化策略后,通常不能上线观察效果,需要一种更敏捷的验证方式,才能确保及时发现策略的有效性,并及时做相应的调整。
业务系统优化的细节
优化目标的确定
在业务系统中做优化时,比较忌讳两件事情:
- 过早优化:在一些功能、实现、依赖系统、部署环境还没有稳定时,过早的投入优化代码或者设计,在后续系统发生变更时,可能会造成精力浪费。
- 过度优化:与引擎类系统不同,业务系统通常不需要跑分或者与其他系统产出性能对比报表,实际工作中更多的是贴合业务场景做优化。比如用户直接访问前端界面的系统,通常不需要将响应时间优化到 ms 以下,几十毫秒和几百毫秒,已经是满足要求的了。
优化范围选择
对于一个业务类 Web 服务来说,特别是重构阶段,优化范围比较容易圈定,主要是找出与之前系统相比,明显变慢的那部分 API,比如可以通过以下方式收集需要优化的部分:
• 通过前端的慢查询捕捉工具或者后端的监控系统,筛选出 P90 大于 2s 的 API
• 页面测试过程中,研发和测试同学陆续反馈的 API
• 数据导入过程中,研发发现的写入慢的 API 等
优化目标确立
针对不同的业务功能和场景,定义尽可能细致的优化目标,以 Data Catalog 系统为例:
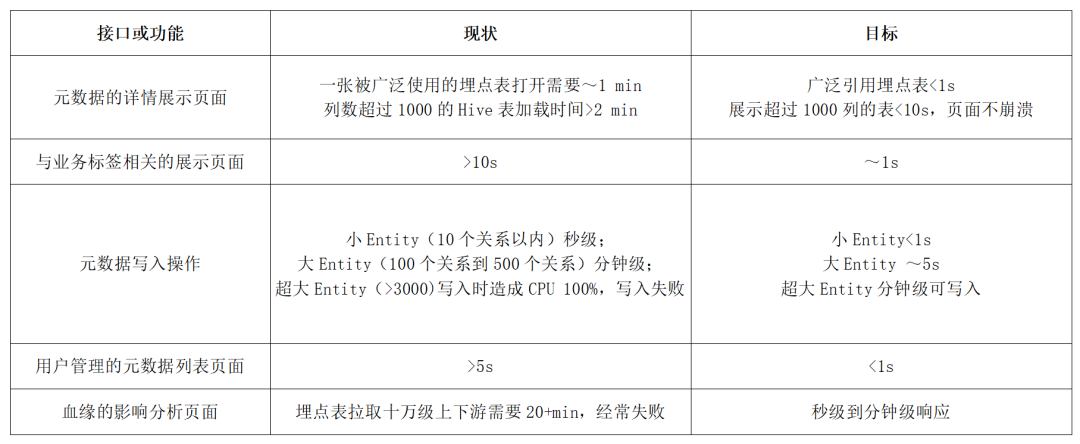
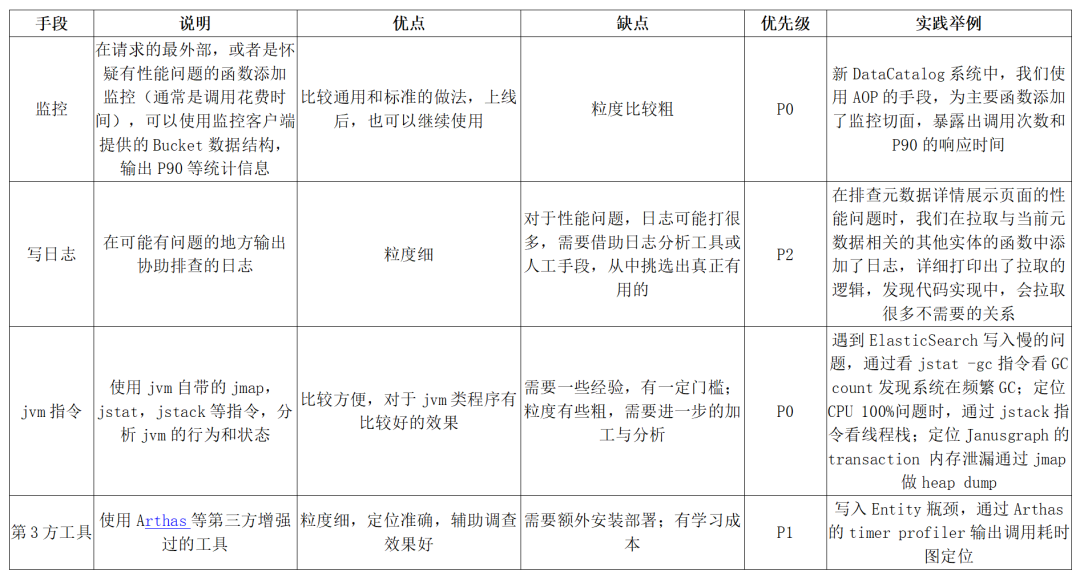
定位性能瓶颈手段
系统复杂到一定程度时,一次简单的接口调用,都可能牵扯出底层广泛的调用,在优化某个具体的 API 时,如何准确找出造成性能问题的瓶颈,是后续其他步骤的关键。下面的表格是我们总结的常用瓶颈排查手段。
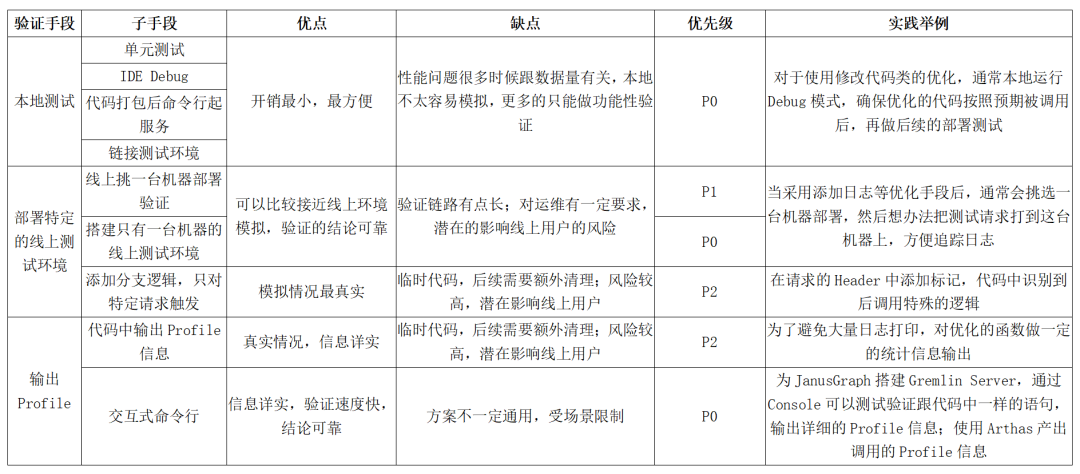
优化策略
在找到某个接口的性能瓶颈后,下一步是着手处理。同一个问题,修复的手段可能有多种,实际工作中,我们优先考虑性价比高的,也就是实现简单且有明确效果。

快速验证
优化的过程通常需要不断的尝试,所以快速验证特别关键,直接影响优化的效率。
Data Catalog 系统优化举例
在我们升级字节 Data Catalog 系统的过程中,广泛使用了上文中介绍的各种技巧。本章节,我们挑选一些较典型的案例,详细介绍优化的过程。
调节 JanusGraph 配置
实践中,我们发现以下两个参数对于 JanusGraph 的查询性能有比较大的影响:
- query.batch = ture
- query.batch-property-prefetch=true
其中,关于第二个配置项的细节,可以参照我们之前发布的文章。这里重点讲一下第一个配置。
JanusGraph 做查询的行为,有两种方式:

针对字节内部的应用场景,元数据间的关系较多,且元数据结构复杂,大部分查询都会触发较多的节点访问,我们将 query.batch 设置成 true 时,整体的效果更好。
调整 Gremlin 语句减少计算和 IO
一个比较典型的应用场景,是对通过关系拉取的其他节点,根据某种属性做 Count。在我们的系统中,有一个叫“BusinessDomain”的标签类型,产品上,需要获取与某个此类标签相关联的元数据类型,以及每种类型的数量,返回类似下面的结构体:
{ "guid": "XXXXXX", "typeName": "BusinessDomain", "attributes": { "nameCN": "直播", "nameEN": null, "creator": "XXXX", "department": "XXXX", "description": "直播业务标签" }, "statistics": [ { "typeName": "ClickhouseTable", "count": 68 }, { "typeName": "HiveTable", "count": 601 } ] }
我们的初始实现转化为 Gremlin 语句后,如下所示,耗时 2~3s:
g.V().has('__typeName', 'BusinessDomain') .has('__qualifiedName', eq('XXXX')) .out('r:DataStoreBusinessDomainRelationship') .groupCount().by('__typeName') .profile();
优化后的 Gremlin 如下,耗时~50ms:
g.V().has('__typeName', 'BusinessDomain') .has('__qualifiedName', eq('XXXX')) .out('r:DataStoreBusinessDomainRelationship') .values('__typeName').groupCount().by() .profile();
Atlas 中根据 Guid 拉取数据计算逻辑调整
对于详情展示等场景,会根据 Guid 拉取与实体相关的数据。我们优化了部分 EntityGraphRetriever 中的实现,比如:
- mapVertexToAtlasEntity 中,修改边遍历的读数据方式,调整为以点以及点上的属性过滤拉取,触发 multiPreFetch 优化。
- 支持根据边类型拉取数据,在应用层根据不同的场景,指定不同的边类型集合,做数据的裁剪。最典型的应用是,在详情展示页面,去掉对血缘关系的拉取。
- 限制关系拉取的深度,在我们的业务中,大部分关系只需要拉取一层,个别的需要一次性拉取两层,所以我们接口实现上,支持传入拉取关系的深度,默认一层。
配合其他的修改,对于被广泛引用的埋点表,读取的耗时从~1min 下降为 1s 以内。
对大量节点依次获取信息加并行处理
在血缘相关接口中,有个场景是需要根据血缘关系,拉取某个元数据的上下游 N 层元数据,新拉取出的元数据,需要额外再查询一次,做属性的扩充。
我们采用增加并行的方式优化,简单来说:
- 设置一个 Core 线程较少,但 Max 线程数较多的线程池:需要拉取全量上下游的情况是少数,大部分情况下几个 Core 线程就够用,对于少数情况,再启用额外的线程。
- 在批量拉取某一层的元数据后,将每个新拉取的元数据顶点加入到一个线程中,在线程中单独做属性扩充
- 等待所有的线程返回
对于关系较多的元数据,优化效果可以从分钟级到秒级。
对于写入瓶颈的优化
字节的数仓中有部分大宽表,列数超过 3000。对于这类元数据,初始的版本几乎没法成功写入,耗时也经常超过 15 min,CPU 的利用率会飙升到 100%。
定位写入的瓶颈
我们将线上的一台机器从 LoadBalance 中移除,并构造了一个拥有超过 3000 个列的元数据写入请求,使用 Arthas 的 itemer 做 Profile,得到下图:

从上图可知,总体 70%左右的时间,花费在 createOrUpdate 中引用的 addProperty 函数。
耗时分析
-
JanusGraph 在写入一个 property 的时候,会先找到跟这个 property 相关的组合索引,然后从中筛选出 Coordinality 为“Single”的索引
-
在写入之前,会 check 这些为 Single 的索引是否已经含有了当前要写入的 propertyValue
-
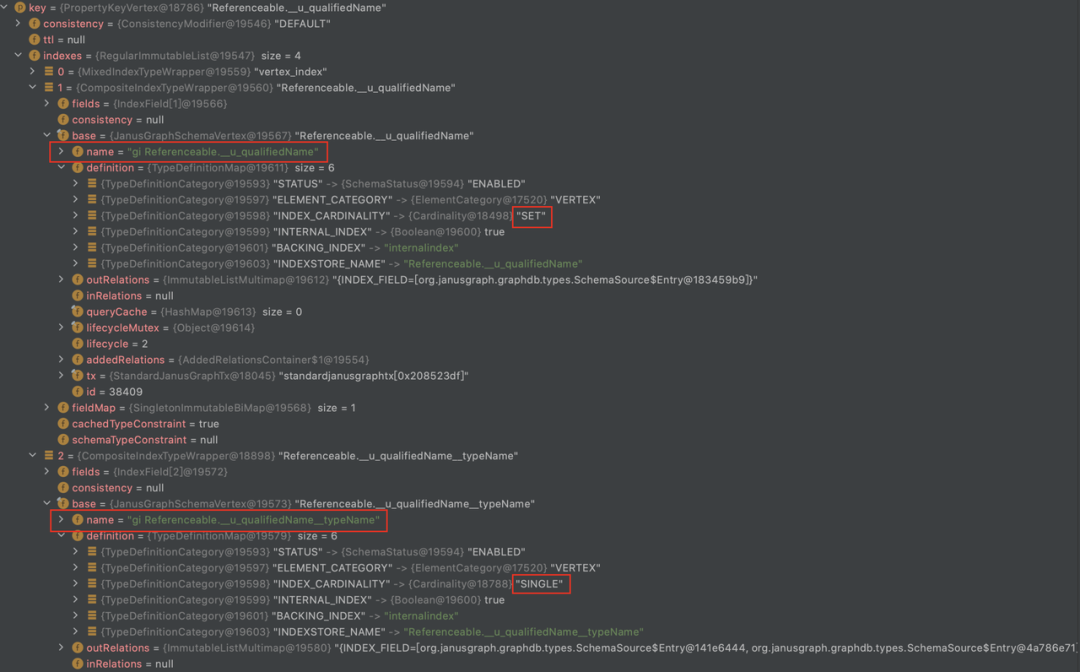
组合索引在 JanusGraph 中的存储格式为:

-
Atlas 默认创建的“guid”属性被标记为 globalUnique,他所对应的组合索引是__guid。
-
对于其他在类型定义文件中被声明为“Unique”的属性,比如我们业务语义上全局唯一的“qualifiedName”,Atlas 会理解为“perTypeUnique”,对于这个 Property 本身,如果也需要建索引,会建出一个 coordinity 是 set 的完全索引,为“propertyName+typeName”生成一个唯一的完全索引
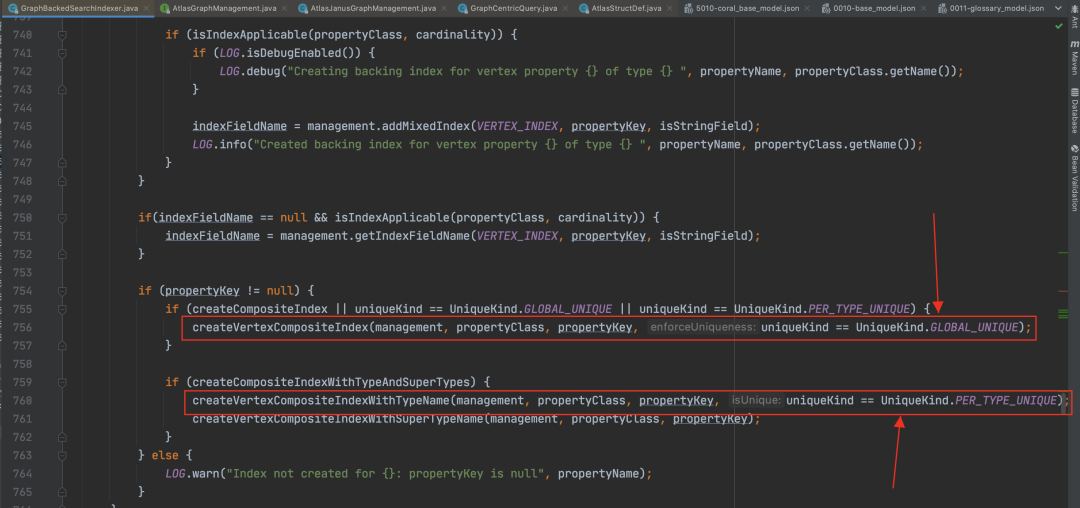
-
在调用“addProperty”时,会首先根据属性的类型定义,查找“Unique”的索引。针对“globalUnique”的属性,比如“guid”,返回的是“__guid”;针对“perTypeUnique”的属性,比如“qualifiedName”,返回的是“propertyName+typeName”的组合索引。
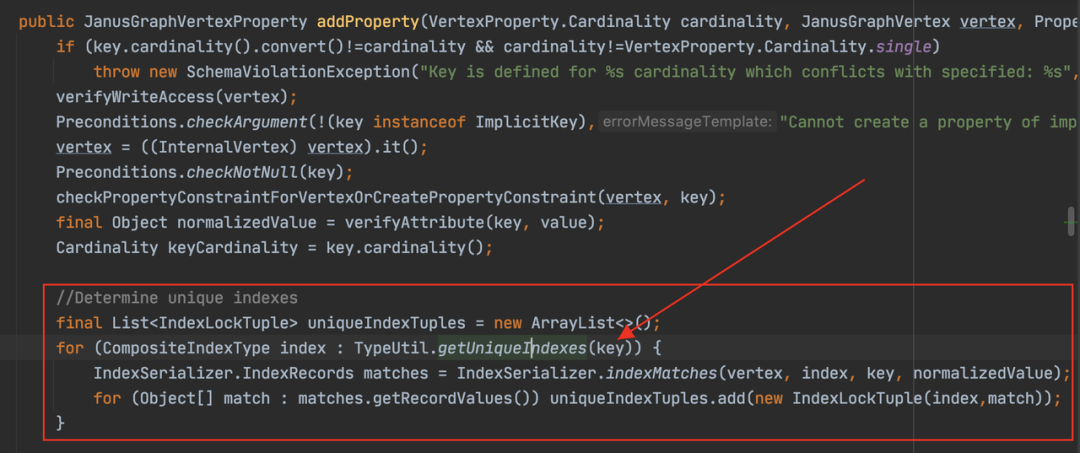
-
针对唯一索引,会尝试检查“Unique”属性是否已经存在了。方法是拼接一个查询语句,然后到图里查询

-
在我们的设计中,写入表的场景,每一列都有被标记为唯一的“guid”和“qualifiedName”,“guid”会作为全局唯一来查询对应的完全索引,“qualifiedName”会作为“perTypeUnique”的查询“propertyName+typeName”的组合完全索引,且整个过程是顺序的,因此当写入列很多、属性很多、关系很多时,总体上比较耗时。
优化思路
- 对于“guid”,其实在创建时已经根据“guid”的生成规则保证了全局唯一性,几乎不可能有冲突,所以我们可以考虑去掉写入时对“guid”的唯一性检查,节省了一半时间。
- 对于“qualifiedName”,根据业务的生成规则,也是“globalUnique”的,与“perTypeUnique”的性能差别几乎是一倍:
优化实现效果
- 去除 Atlas 中对于“guid”的唯一性的检查。
- 添加“Global_Unqiue”配置项,在类型定义时使用,在初始化时对“__qualifiedName”建立全局唯一索引。
- 配合其他优化手段,对于超多属性与关系的 Entity 写入,耗时可以降低为分钟级。
总结
- 业务类系统的性能优化,通常会以解决某个具体的业务场景为目标,从接口入手,逐层解决
- 性能优化基本遵循思路:发现问题->定位问题->解决问题->验证效果->总结提升
- 优先考虑“巧”办法,“土”办法,比如加机器改参数,不为了追求高大上而走弯路
立即跳转火山引擎大数据研发治理套件 DataLeap 官网了解详情!
欢迎关注字节跳动数据平台同名公众号
标签:Data,例聊,写入,拉取,索引,Catalog,typeName,guid,优化 来源: https://www.cnblogs.com/bytedata/p/16355319.html