详解大集群通信建模理论公式
作者:互联网
摘要:对扩容后集群的性能提升进行评估,首先需要对集群的通信过程进行建模。
本文分享自华为云社区《大集群通信代价公式》,作者: 向巴菲特学习。
为提升当前业务实时性,客户可以选择对业务集群进行扩容,预期会带来性能提升。但是,扩容后集群的性能提升能否达到预期,是否值得进行扩容?扩容比与性能提升有没有相关性?如果在扩容前能够准确回答这些问题,可以给客户决策提供依据,具有极其重要的实践意义。
对扩容后集群的性能提升进行评估,首先需要对集群的通信过程进行建模。在GaussDB的各种使用场景中,涉及数据重分布的查询场景对集群的通信能力要求最高,因此,这里主要对GaussDB各类查询场景的通信过程进行建模,并推导出理论公式。
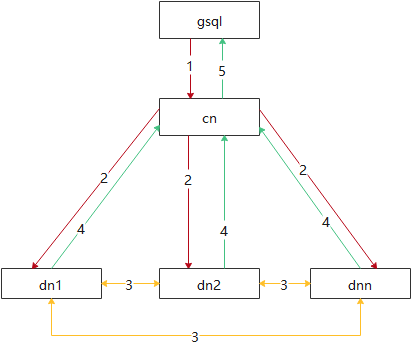
图:查询场景数据流图
查询场景数据流图如上所示,具体说明如下:
- gsql客户端向cn发送查询语句;
- cn根据接收到的查询语句,生成执行计划,下发到每个dn上;
- 每个dn根据收到的执行计划,按需进行数据重分布;数据重分布产生的通信流量占据了集群通信流量的90%以上;
- 每个dn将处理完成的结果返回给cn进行汇聚;
- cn将查询结果汇聚后,返回给gsql客户端。
可以看出,扩容对dn间数据重分布(上图流程4)性能的影响是最大的,直接关系到扩容后查询性能的提升。dn间数据重分布有两种方式:广播;rehash。
接下来我们对gaussdb查询场景的通信流程进行梳理,我们假设表数据在各个dn上均匀分布,并且每个dn处理数据耗时与数据量线性正相关。
1.无数据重分布的查询场景:
当从一张数据库表中查询全量数据,或者当两张数据库表的join列都是分布列时,查询过程不涉及DN间数据重分布。这种场景下,每个dn只需要处理各自存储的表数据,然后返回给cn。
定义:
r:扩容比
dbefore:扩容前表数据在每个dn上的存储量,我们假设表数据在各个dn上均匀分布
推导:
扩容后每个dn上表数据存储量dafter = dbefore / (1 + r);
结论:该场景下,扩容后查询性能提升上界为:1 / (1 + r);
2.rehash数据重分布查询场景:
当查询语句至少有一个join列不是分布列,且涉及数据库表的数据量相当时,DN间使用rehash数据重分布。
定义:
r:扩容比
dbefore:扩容前表数据在每个dn上的存储量,我们假设表数据在各个dn上均匀分布,重分布以后的表数据在各个dn上也是均匀分布;
推导:
扩容后每个dn上表数据存储量dafter = dbefore / (1 + r);
结论:该场景下,扩容后查询性能提升上界为:1 / (1 + r);
3.广播数据重分布查询场景:
当查询语句有一个join列不是分布列,且对应的数据库表的数据量相比之下很小时,DN间使用广播方式进行数据重分布,每个dn上存储全量的表数据。
定义:
r:扩容比
dbefore:扩容前表数据在每个dn上的存储量,我们假设表数据在各个dn上均匀分布,重分布以后的表数据在各个dn上也是均匀分布;
推导:
扩容后每个dn上表数据存储量dafter = dbefore / (1 + r);
结论:该场景下,扩容后查询性能提升上界为:1 / (1 + r);
以上公式推导出扩容后查询性能提升上界与扩容比的关系,后续会构建扩容场景,测试出各个扩容场景下的实际性能提升值,与理论值进行对比,确定一个通用的校正因子,即实际扩容性能提升为∂ / (1 + r),∂为校正因子。
华为伙伴暨开发者大会2022火热来袭,重磅内容不容错过!
【精彩活动】
勇往直前·做全能开发者→12场技术直播前瞻,8大技术宝典高能输出,还有代码密室、知识竞赛等多轮神秘任务等你来挑战。即刻闯关,开启终极大奖!点击踏上全能开发者晋级之路吧!
【技术专题】
未来已来,2022技术探秘→华为各领域的前沿技术、重磅开源项目、创新的应用实践,站在智能世界的入口,探索未来如何照进现实,干货满满点击了解
标签:dn,扩容,场景,建模,查询,详解,集群,数据 来源: https://www.cnblogs.com/huaweiyun/p/16351025.html