3D 沙盒游戏之地面网格设计
作者:互联网
背景
最近小组在探索研发一个 3D 的沙盒小游戏 demo。对于沙盒游戏来说,地面是必不可少的元素。为了降低难度,在这个 demo 中,地面将不涉及 y 轴坐标的变化,也就是使用一个与 xOz 平面平行的平面,对应到现实世界中,就是一块不带任何起伏的平地。本篇文章以 babylon.js 作为框架进行说明。期望的效果类似下图(截图来自于手游部落冲突):
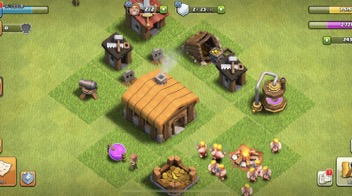
目标
首先我们需要在 xOz 平面上创建一块矩形作为地面。为了不让地面看起来过于单调,需要给地面贴上一些纹理,比如草地、鹅卵石路等等;在此基础上,纹理还需要可以局部替换,比如可以实现一条在草地中央的鹅卵石小路。同时,在地面上,需要放置其他模型(比如人物、建筑等),为了避免模型在移动或者新增的时候,出现重叠的情况,还得知道当前地面上对应的位置的状态(是否已被模型占用),因此在新增或移动模型的时候,需要获取当前模型在地面上的具体位置信息。基于以上需求,可以梳理为以下两个大目标:
- 完成地面初始化,且可以改变特定位置的纹理
- 获取模型在地面上的位置信息
围绕这两个目标,下面通过两个实现篇,给大家展示下如何一步步实现~
实现之地面创建篇
首先要把思路捋一下:先是需要创建一个地面,其实地面的本质也是一个模型。其次要修改地面的部分纹理。有一个比较简单的方法,就是把地面给细分为一个个网格,每个网格可以单独的进行纹理贴图,每次更换纹理的时候,也不会影响其他格子。
定义好一些常量,以便后面的讲解。这些常量只需要先看一下,有个基本的印象即可,后面用到的时候,会具体解释。
//地面的长度(x方向)
const GROUND_WIDTH = 64
//地面的宽度(z方向
const GROUND_HEIGHT = 64
//地面纹理的宽度
const TEXTURE_WIDTH = 1024
//地面纹理的高度
const TEXTURE_HEIGHT = 1024
//一个方向上(s和t坐标方向),把地面分为多少个小块
const GROUND_SUBDIVISION = 32
下面是具体的步骤。
1. 建立一块平地
查阅 babylon.js 的相关文档,直接调用api即可创建,代码比较简单,直接贴到下面:
const ground = MeshBuilder.CreateGround(
name,
{ width: GROUND_WIDTH, height: GROUND_HEIGHT, subdivisions: GROUND_SUBDIVISION },
scene,
)
上面代码中,用到了三个在这一篇刚开始就已经定义好的常量 GROUND_WIDTH、GROUND_HEIGHT 和 GROUND_SUBDIVISION。前两个常量分别代表的是要创建的地面的宽高,都是 64。它们所属的坐标系是裁剪坐标系。由于 WebGL 中应用了很多坐标系,可能有些同学还不是很了解,推荐去看看这篇文章WebGL坐标系基础。 至于 GROUND_SUBDIVISION 这个常量,指的是要把矩形的一条边,分为多少段,这一篇是把地面的 x、z 方向都分成了 32 段。
简单的一行代码,就可以创建出一块平地了,看看效果:

2. 给“大地”贴上纹理
复杂的功能总是由一个个简单的功能演变来的。首先先做最简单的一步,先给我们刚刚创建好的这块大地,贴上纹理,随便找一张草地的图片,查看babylon.js材质与纹理这一部分文档,先给地面一个材质,然后在材质上进行贴图,代码如下:
//创建一个标准材质
const groundMaterial = new StandardMaterial('groundMaterial', scene);
//创建一个纹理
const groundTexture = new Texture('//storage.360buyimg.com/model-rendering-tool/files/jdLife/grass.jpg', scene)
//把纹理赋值给材质的漫反射纹理(这里也可以是其他类型的纹理)
groundMaterial.diffuseTexture = groundTexture
//把材质赋值给地面的材质属性
ground.material = groundMaterial
现在地面已经有了纹理贴图了:

3. 分割地面为一个个格子
在上一步,虽然已经实现了给地面贴纹理,但是效果肯定是不能满足预定的需求的。如果对WebGL有相关了解的同学,应该会知道,如果要给材质的特定位置,贴上特定的纹理,就需要获取材质上顶点数据,然后打上图钉,再在纹理贴图中,根据顶点对应的图钉点,来获取需要的图片的位置。这应该是一步比较复杂的操作,而且 babylon.js 封装的比较深,如果直接暴力的去实现起来,会是比较大的工程。
于是,本着 babylon.js 应该有封装好的类,可以实现(或者经过简单的改动后可以实现)这个需求的猜测,再次翻阅它的文档,终于找到一个类似的例子。为了方便阅读,直接截取效果图展示出来:

看了一下这个例子的代码,可以总结为:
- 使用了 babylon.js 的
AdvancedDynamicTexture.CreateForMesh高级动态纹理为地面创建纹理。 - 高级动态纹理提供了 addControl 方法,可以往纹理上添加各种“容器”。
- “容器”是 Babylon.js 的一个类 Container。
- “容器”也有 addControl 方法,可以在“容器”里面继续添加“容器”,即可以“套娃”。
babylon.js 的 AdvancedDynamicTexture 的实现原理,在这里先不讨论,但是现在有了上面这些知识点,结合 demo,就能对地面进行分格了。直接上代码,把步骤写在了注释里:
//首先调用AdvancedDynamicTexture的api,创建纹理
const groundTexture = GUI.AdvancedDynamicTexture.CreateForMesh(ground, TEXTURE_WIDTH, TEXTURE_HEIGHT, false)
//创建最外层的Container -- panel,它的宽高和纹理的一致
const panel = new GUI.StackPanel()
panel.height = TEXTURE_HEIGHT + 'px'
panel.width = TEXTURE_WIDTH + 'px'
//把panel添加到纹理上
groundTexture.addControl(panel)
//循环的建立一列列Row,并且加到panel上面
for (let i = 0; i < GROUND_SUBDIVISION; i++) {
const row = new GUI.StackPanel()
row.height = TEXTURE_HEIGHT / GROUND_SUBDIVISION + 'px'
//把row添加到panel上
panel.addControl(row)
row.isVertical = false
//在循环的,在每一行里面建立一个个格子
for (let j = 0; j < GROUND_SUBDIVISION; j++) {
const block = new GUI.Rectangle()
block.width = TEXTURE_WIDTH / GROUND_SUBDIVISION + 'px'
row.addControl(block)
}
}
代码里用到了 TEXTURE_WIDTH 和 TEXTURE_HEIGHT 两个常量,它们分别代表的是纹理的宽高。相对纹理的尺寸有更多了解的同学,可以参考下 WebGL纹理详解之三:纹理尺寸与Mipmapping 这篇文章的解释,这里不展开细谈。
看看这时候的效果:

4. 给每个格子单独贴图,并且存储纹理 Image 对象
这里的 Image 指的是 Babylon.js 里面的一个类,为了方便下文直接称它 Image。
为什么要给每个格子单独贴图,这个无需解释了。至于为什么要存储每个格子的纹理Image对象,是为了方便后面去修改贴图。由于在创建这些格子的时候,是通过循环创建的,所以它们本身已经具备一定的顺序了,因此只要把它们在创建的时候,都push到一个数组里面(blockImageArray),读的时候按照创建的顺序传入索引就可以了。
实现的时候,还是先实现最简单的,让每个格子的纹理都一样就好了。在上一步的代码基础上添加,代码如下:
...
//在循环的,在每一行里面建立一个个格子
for (let j = 0; j < GROUND_SUBDIVISION; j++) {
const block = new GUI.Rectangle()
block.width = TEXTURE_WIDTH / GROUND_SUBDIVISION + 'px'
row.addControl(block)
//隐藏格子的边框
block.thickness = 0
//创建Image对象
const blockImage = new GUI.Image('blockTexture','//storage.360buyimg.com/model-rendering-tool/files/jdLife/grass.jpg')
//把图片添加到block上
block.addControl(blockImage)
//在外面的定义域里面先创建好blockImageArray
blockImageArray.push(blockImage)
}
值得注意的是,上述代码在创建 Image 对象的时候,是直接通过url进行动态导入的,这会造成,每次创建一个Image,就去发一个请求,显然是存在性能问题的。
于是,再一次翻查babylon.js的文档,寻求优化方案。Image 有一个 domImage 属性,值的类型为 HTMLImageElement,可以通过修改这个属性,来修改图片内容。所以只要事先加载图片生成 HTMLImageElement 并且存储在 imageSource ,在创建Image的时候,对它的 domImage 属性进行赋值即可。优化后的代码:
//把需要的图片导入好,放到imageSource里面
const imageSource : { [key: string]: HTMLImageElement } = { grass: img, stone: img }
...
//创建image的时候不再传递url参数了
const blockImage = new GUI.Image()
//对domImage属性赋值
blockImage.domImage = imageSource.grass
现在来看一下效果:

5. 更改纹理
经过了上一步的操作,已经创建出来了一块有模有样的绿地了,接下来需要做的是纹理更换的功能。先实现个最简单的:在最外层的 panel 监听点击事件,通过点击的位置,判断当前点击的是地面的第几行第几列,然后找到 blockImageArray 对应的元素,对它的 domImage 进行再赋值就好了。代码如下:
panel.onPointerClickObservable.add(e => {
const { y, x } = e
const perBlockWidth = TEXTURE_WIDTH / GROUND_SUBDIVISION
const perBlockHeight = TEXTURE_HEIGHT / GROUND_SUBDIVISION
const row = Math.floor(y / perBlockHeight)
const col = Math.floor(x / perBlockWidth)
const index = row * GROUND_SUBDIVISION + col
blockObjArr[index].domImage = imageSource.stone
})
看看现在的效果:

到此为止,就已经实现了创建地面并且可以改变纹理这个目标了。
实现之模型占位计算篇
名词:
- 地面:案例中的平面
- 模型:案例中需要计算占位的物体
- 索引编号:二维数组的下标
- 网格坐标系:将地面分割为均等网格而形成的坐标系
- WebGL 坐标系:原始 WebGL 坐标系
- 模型基点:模型原点
- 转换:从一个值换算到另一个值
- 纠偏:把原有的坐标数值加上偏正值(这里是半个格子的长度或宽度)
- 包围盒:能把模型整个包起来的最小长方体 bounding
流程图:https://www.processon.com/view/link/6238a14007912906f50e1ed7
经过上一篇的实现,现在已经创建了一块地面,并将地面等分成了若干个网格。这时要获取模型在地面上的占位情况,就需要转换为获取模型在地面上所占格子的数据。下图展示了,一个模型(房子)在地面上所占的格子的情况(被占的格子边框显示为红色):

为了看起来直观一些,我们将在下面的说明中把地面分割成 8*8 的网格体系。
以下是涉及到的常量:
//重新定义一下,让地面分为 8 * 8 的网格
const GROUND_SUBDIVISION = 8
//每一个格子在相机裁剪坐标系中的宽度
const PER_BLOCK_VEC_X = GROUND_WIDTH / GROUND_SUBDIVISION
//每一个格子在相机裁剪坐标系中的高度
const PER_BLOCK_VEC_Z = GROUND_HEIGHT / GROUND_SUBDIVISION
//模型位置向量在x轴方向的偏移量
const CENTER_OFF_X = PER_BLOCK_VEC_X / 2
//模型位置向量在z轴方向的偏移量
const CENTER_OFF_Z = PER_BLOCK_VEC_Z / 2
//半个格子在相机裁剪坐标系中的宽度
const HALF_BLOCK_VEC_X = PER_BLOCK_VEC_X / 2
//半一个格子在相机裁剪坐标系中的高度
const HALF_BLOCK_VEC_Z = PER_BLOCK_VEC_Z / 2
要确切地知道地面上的模型占用了哪几个格子,首先得建立地面网格坐标系。还记得在上一篇中,生成这些格子的时候,是通过两个 for 循环生成的吗,其实在生成这些格子的时候,同时也产生了索引。为了阅读方便,我再贴一下生成网格的代码:
for (let i = 0; i < GROUND_SUBDIVISION; i++) {
const row = new GUI.StackPanel()
row.height = TEXTURE_HEIGHT / GROUND_SUBDIVISION + 'px'
//把row添加到panel上
panel.addControl(row)
row.isVertical = false
//在循环的,在每一行里面建立一个个格子
for (let j = 0; j < GROUND_SUBDIVISION; j++) {
const block = new GUI.Rectangle()
block.width = TEXTURE_WIDTH / GROUND_SUBDIVISION + 'px'
row.addControl(block)
//创建贴图
const blockImage = new GUI.Image()
//对domImage属性赋值
blockImage.domImage = imageSource.grass
block.addControl(blockImage)
blockImageArray.push(blockImage)
}
}
可以理解为,每个网格的 i 和 j 就对应着它们在 z 方向和 x 方向的坐标。
根据每个网格在网格坐标系的 x 和 z 坐标,设置索引编号(每个网格对应一个坐标),索引编号的数据结构为:
interface Coord {
x: number,
z: number
}
放到 8*8 网格坐标系中即为:
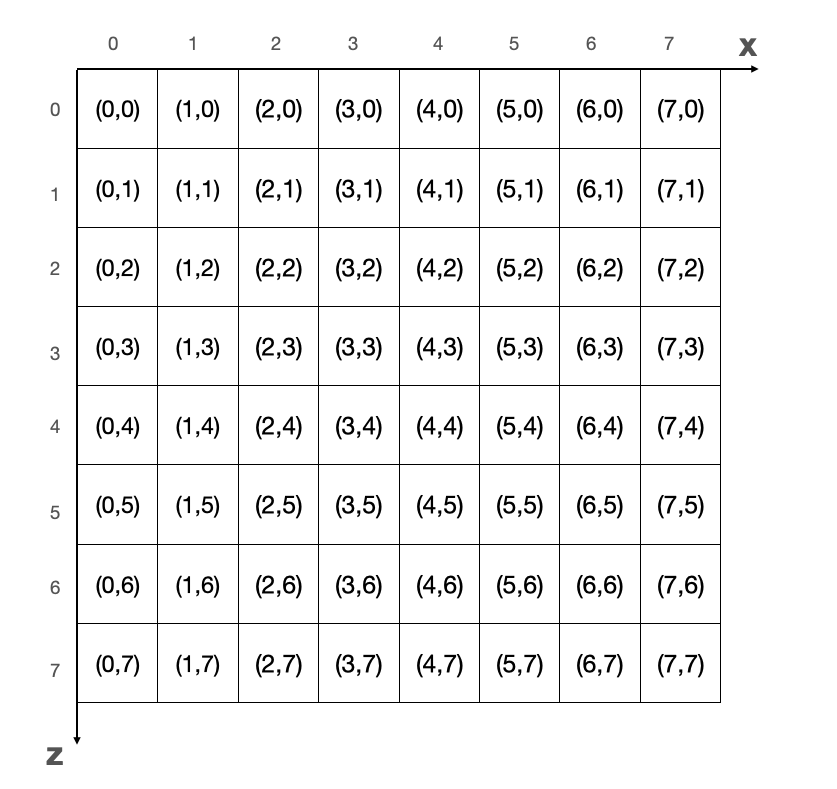
上面这张图是不是比较好理解了呢,看起来就像我们初中学习的平面直角坐标系,原点在左上角,x 轴为水平方向从左向右,z 轴是垂直方向从上到下。
对应到代码中,我们可以通过创建一个二维数组,来存储这个网格坐标系。这样就可以用地面网格的坐标作为索引,在二维数组中寻找对应的值,以判断该网格上是否有模型占位。
1. 创建网格坐标系坐标集合数组:groundStatus
网格坐标系坐标集合数组 groundStatus,我们把它定义为一个 number 二维数组。
groundStatus 数据结构如下:
type GroundStatus = number[][]
二维数组中的每个元素与网格坐标系中的坐标一一对应。每个坐标对应的初始值为 0,代表当前坐标没有被占位,当有模型放置在上面时,值 +1;当模型移开或删除时,值 -1。不使用 boolean 作为存储类型的原因,是因为 boolean 只有 true 和 false 两种状态,不能满足更为复杂的需求,比如在移动模型的时候,出现模型重叠的情况的时候,groundStatus 对应的格子上,就会有两个模型。如果用 boolean 来表示的话,是没办法表示出来的,因为它只有 true 和 false 两种值。但是如果使用 number 的话,就可以在该格子对应的元素,把值修改为 2,标识单前格子上有两个模型占位了。
在设计 groundStatus 索引时,以 x 还是 z 坐标为一维索引,在性能影响上区别不大。出于调试方面的考虑,建议以 z 坐标为一维索引,便于浏览器的控制台二维数组的展示与网格坐标系一一对应。

2. 模型基点向量与网格坐标系坐标的换算
模型基点向量指的是模型数据中的 position 属性,定义了模型在 WebGL 坐标系中的位置。position 是一个三维向量,遵守的是 WebGL 坐标系,比如当 position 值为 (0, 0, 0) 的时候,出现在地面的位置就是地面的中心点。为了方便,下文我都会把它叫做,模型的基点。

图片来源:在InfraWorks中编辑3D模型的基点或插入点
WebGL 坐标系的 (0, 0, 0) 换算成地面坐标系,就是网格坐标 (3, 3)、(3, 4)、(4, 3)、(4, 4) 这四个格子的交点。如下图所示:
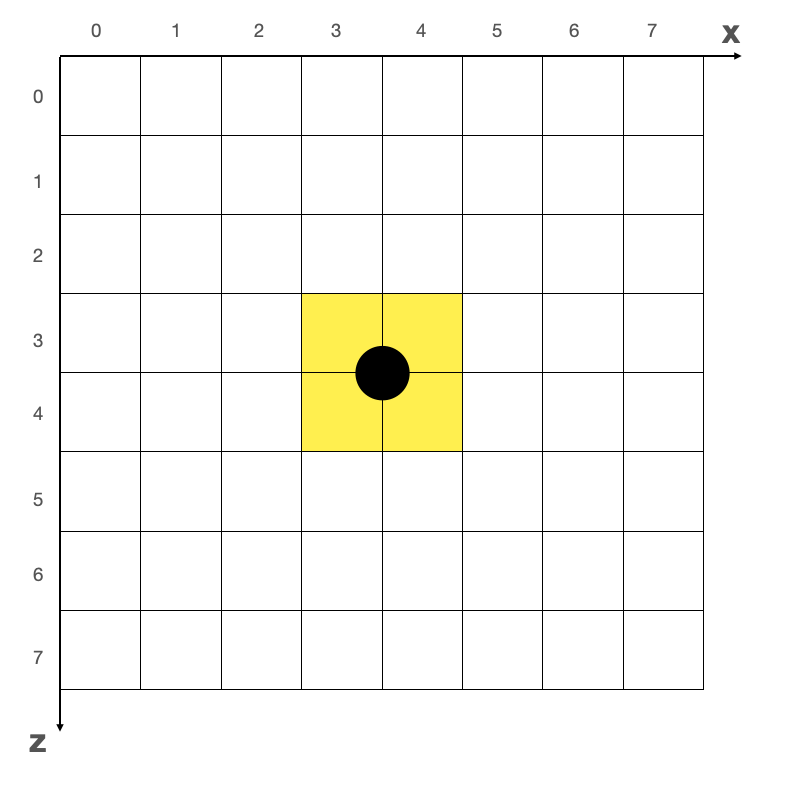
黄色的方块,代表圆点在地面上所占的格子。实际占位只有1格的模型,在这个位置向上取整的时候,最小的占位也是4个格子,一旦涉及到碰撞检测等功能,会出现模型占位过大的问题。所以我们需要对中心点进行偏移,使模型在网格坐标系中的占位尽量接近模型真实占位,往右下角——x、z 各偏移半个网格的单位即可,这时候 (0, 0, 0) 对应的基点坐标就是 (4, 4) 格子的中心点了。偏移的原则是保证模型的基点能落在网格坐标系的某个格子的中点,以便更为准确地进行模型占位的计算。如下图:
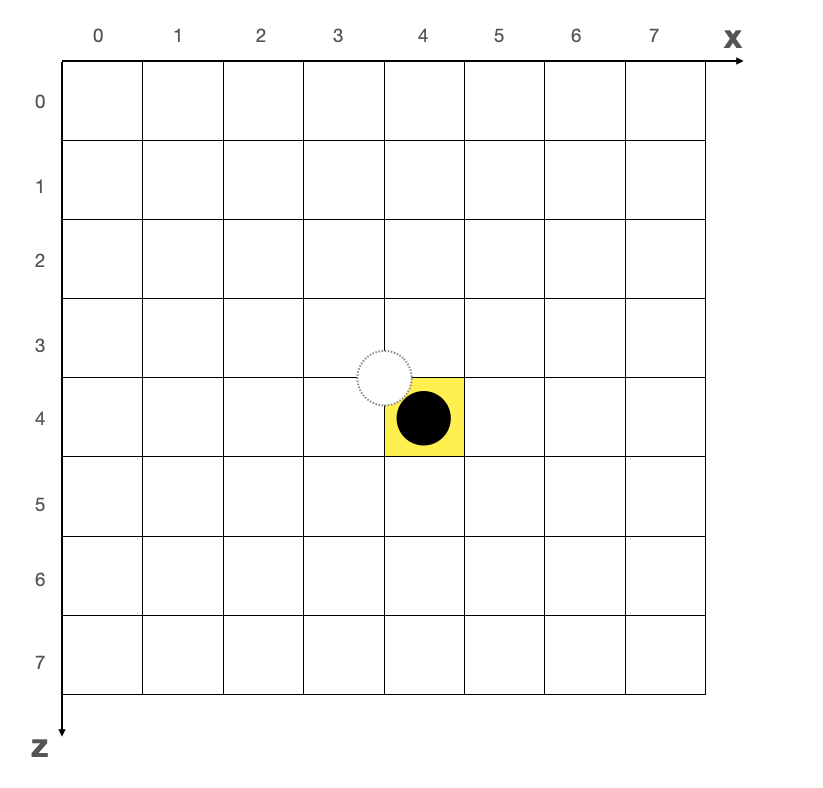
这里值得注意的是,当我们传入模型的位置向量为 (x, y, z) 的时候,我们会手动的把模型的位置改为 (x + CENTER_OFF_X, 0, z - CENTER_OFF_Z)(Y 轴向量本次不涉及计算,因此可以省略)。z 向量的计算为减法,因为 WebGL 坐标系的 z 轴向上为正的,而网格坐标系 z 轴向上为负。
这里我们封装一个传入模型的位置向量、返回该点的地面坐标的函数:
function getGroundCoordByModelPos(buildPosition: Vector3): Coord {
const { _x, _z } = buildPosition
const coordX = Math.floor(GROUND_WIDTH / 2 / PER_BLOCK_VEC_X + (_x + CENTER_OFF_X) / PER_BLOCK_VEC_X)
const coordZ = Math.floor((GROUND_HEIGHT / 2 - (_z - CENTER_OFF_Z)) / PER_BLOCK_VEC_Z)
return { x: coordX, y: coordZ }
}
3. 获取模型占位区在 WebGL 坐标系的关键数据
这一步是为了获取模型的实际占位相关数据,为后续的网格坐标系占位转换做准备。
模型存在最小包围盒的概念,也叫最小边界框,用于界定模型的几何图元。包围盒/边界框可以是矩形,也可以是更为复杂的形状,为方便描述,我们这里采用矩形包围盒/边界框的方式进行说明。下文中简称包围盒。

图片来源:3D 碰撞检测
当我们将 WebGL 坐标系的模型投射到网格坐标系上时,可以得到一片区域:
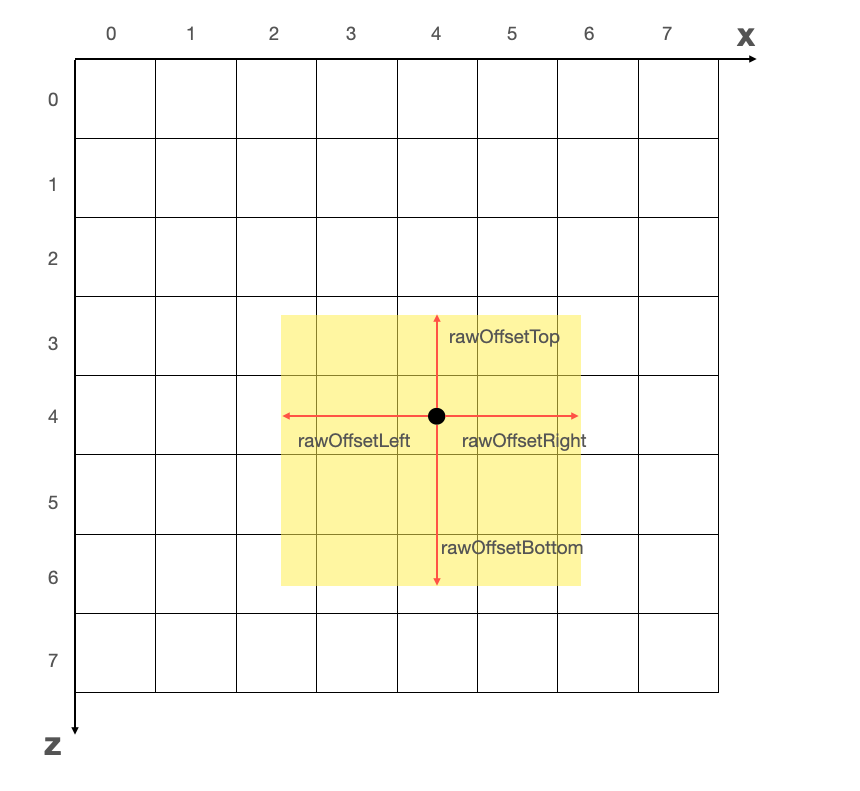
黄色区域代表的是模型占位区域,黑色点则是模型的基点。babylon.js 提供了相关的 api,可以计算出模型包围盒的边界与基点的距离,这里的值均基于 WebGL 坐标系。
我们将这些距离存储到 rawOffsetMap 的对象中,数据结构如下:
interface RawOffsetMap {
rawOffsetTop: number
rawOffsetBottom: number
rawOffsetLeft: number
rawOffsetRight: number
}
计算代码如下:
/*
@param { AbstractMesh[] } meshes 模型导入后返回的结果
@param { Vector3 } scale 模型的缩放倍数
*/
function getRawOffsetMap(meshes: AbstractMesh[], scale: Vector3 = new Vector3(1, 1, 1)): RawOffsetMap {
//声明最小的向量
let min = null
//声明最大的向量
let max = null
//对模型的meshes数组进行遍历
meshes.forEach(function (mesh) {
//babylon.js 提供的api,可以遍历该mesh的和mesh的所有子mesh,找到它们的边界
const boundingBox = mesh.getHierarchyBoundingVectors()
//如果当前的最小向量不存在,那么把当前的mesh的boundingBox的min属性赋值给它
if (min === null) {
min = new Vector3()
min.copyFrom(boundingBox.min)
}
//如果当前的最大向量不存在,那么把当前的mesh的boundingBox的max属性赋值给它
if (max === null) {
max = new Vector3()
max.copyFrom(boundingBox.max)
}
//对最小向量和当前的boundingBox的min属性,从x,y,z这三个分量进行比较与再赋值
min.x = boundingBox.min.x < min.x ? boundingBox.min.x : min.x
min.y = boundingBox.min.y < min.y ? boundingBox.min.y : min.y
min.z = boundingBox.min.z < min.z ? boundingBox.min.z : min.z
//对最大向量和当前的boundingBox的max属性,从x,y,z这三个分量进行比较与再赋值
max.x = boundingBox.max.x > max.x ? boundingBox.max.x : max.x
max.y = boundingBox.max.y > max.y ? boundingBox.max.y : max.y
max.z = boundingBox.max.z > max.z ? boundingBox.max.z : max.z
})
return {
rawOffsetRight: max.x * scale.x,
rawOffsetLeft: Math.abs(min.x * scale.x),
rawOffsetBottom: max.z * scale.z,
rawOffsetTop: Math.abs(min.z * scale.z)
}
}
4. 获取模型占位区在网格坐标系上的关键数据:offsetMap
这一步是将模型 WebGL 坐标系的占位关键数据转换为网格坐标系中的数据。
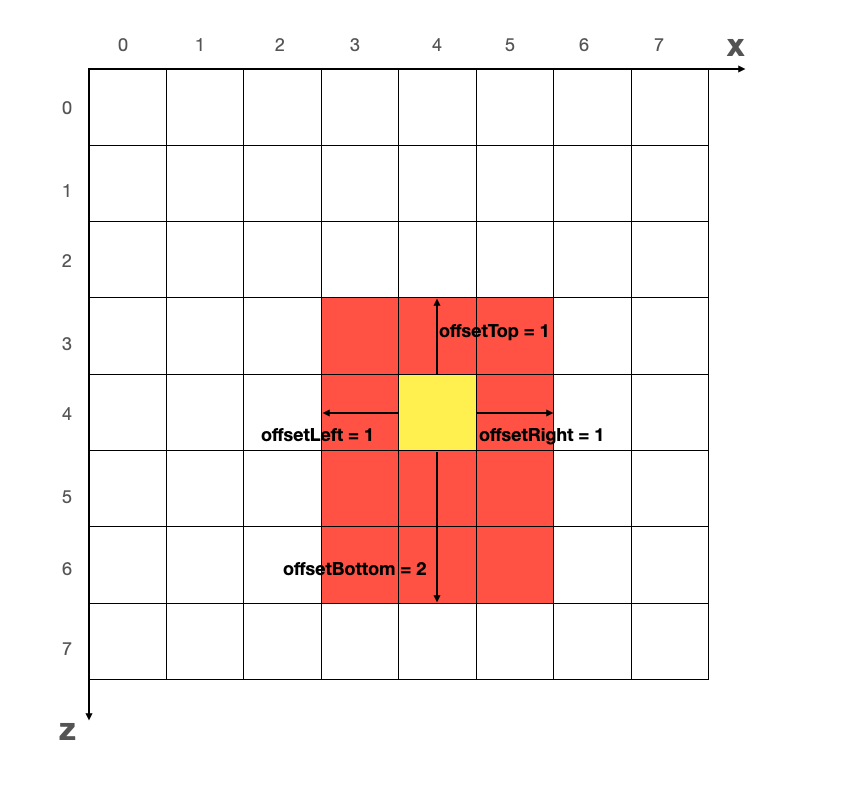
如上图所示,黄色的格子,代表的是模型基点所在的格子。红色是模型在网格坐标系转化之后的占位——当模型边界占位不满一格的时候(比如只占了格子的一半),按占满一格来算。这四个数据,我们使用 offsetMap 对象来存储:
interface OffsetMap {
offsetLeft: number,
offsetRight: number,
offsetTop: number,
offsetBottom: number
}
在上一节中,已经计算出模型的 rawOffsetTop,rawOffsetBottom,rawOffsetLeft,rawOffsetRight。现在只要把这几个关键值一一转化为 offsetMap 对应的关键值即可。
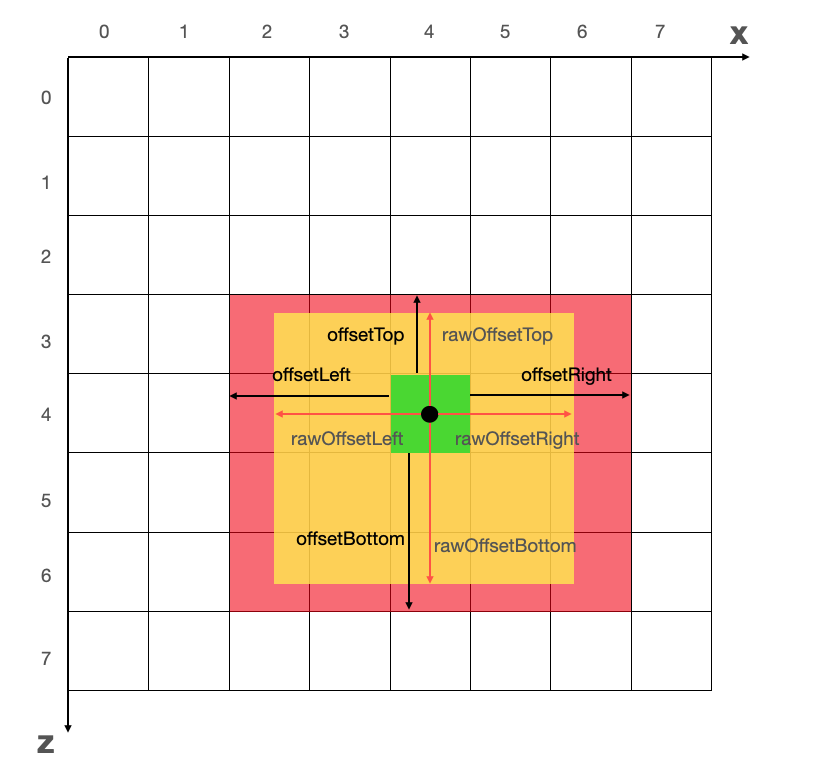
上图中黄色区域是模型在 WebGL 坐标系中的占位,红色区域是将模型占位向上取整后,在网格坐标系中所占网格的集合。rawOffsetMap 与 offsetMap 中字段的转化关系为:rawOffsetLeft 对应 offsetLeft;rawOffsetRight 对应 offsetRight;rawOffsetTop 对应 offsetTop;rawOffsetBottom 对应 offsetBottom。以 rawOffsetLeft 转化为 offsetLeft 为例,将 rawOffsetLeft 减去半个格子的宽度(HALF_BLOCK_VEC_X),然后除以一个格子的宽度(PER_BLOCK_VEC_X),再向上取整。下面为具体代码:
function getModelOffsetMap(rawOffsetMap: RawOffsetMap): OffsetMap {
const { rawOffsetMapLeft, rawOffsetRight, rawOffsetBottom, rawOffsetTop } = rawOffsetMap
const offsetLeft = Math.ceil((rawOffsetLeft - HALF_BLOCK_VEC_X) / PER_BLOCK_VEC_X)
const offsetRight = Math.ceil((rawOffsetRight - HALF_BLOCK_VEC_X) / PER_BLOCK_VEC_X)
const offsetTop = Math.ceil((rawOffsetTop - HALF_BLOCK_VEC_Z) / PER_BLOCK_VEC_Z)
const offsetBottom = Math.ceil((rawOffsetBottom - HALF_BLOCK_VEC_Z) / PER_BLOCK_VEC_Z)
return {
offsetBottom,
offsetLeft,
offsetRight,
offsetTop
}
}
5. 计算出模型在网格坐标系的包围盒索引:bounding
这一步我们将计算出模型包围盒在 groundStatus 中的索引下标,以便通过 groundStatus 来判断对应网格是否已被占位。bounding 即为占位模型在 groundStatus 数据中的几个边界索引值。
bounding 的数据结构如下:
interface Bounding {
minX: number,
maxX: number,
minZ: number,
maxZ: number
}
还是先通过一张图,解释一下 bounding 对象中的四个值指的什么:
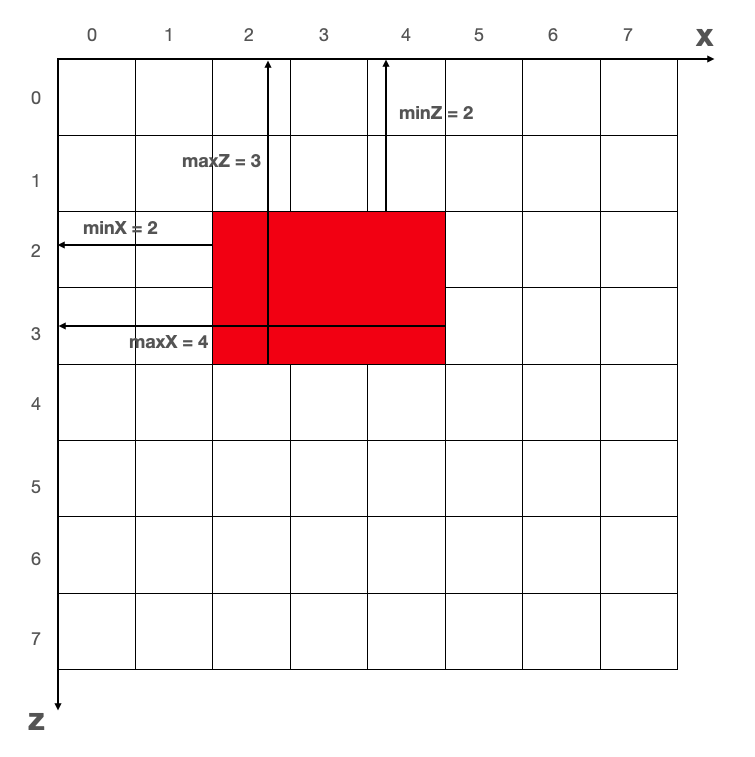
上图中,红色区域是模型在网格坐标系中所占网格。bounding 数据中的四个值,代表了模型包围盒边界网格在 groundStatus 中的索引数组下标,作为更新 groundStatus 中的占位数值的依据。
基于第4步中得到的 offsetMap 数据,结合第2步中的基点坐标,即可算出最终的 bounding:
function getModelBounding(buildPosition: Vector3, offsetMap: OffsetMap): IBounding {
const modelGroundPosCoord = getGroundCoordByModelPos(buildPosition)
const { x, y } = modelGroundPosCoord
const { offsetBottom, offsetLeft, offsetRight, offsetTop } = offsetMap
const minX = x - offLeft
const maxX = x + offRight
const minZ = y - offTop
const maxZ = y + offBottom
return {
minX,
maxX,
minZ,
maxZ
}
}
至此,关于模型的 bounding 的计算就完成了。
6. 更新占位数据
在上一步,已经获取到了模型在地面坐标系的 bounding,这时候只需利用bounding的值,对 groundstatus 进行赋值就好了,代码如下:
//索引边界判断
function isValidIndex(x: number, z: number): boolean {
if (x >= 0 && x < GROUND_SUBDIVISION && z >= 0 && z < GROUND_SUBDIVISION) return true
return false
}
function setModlePosition(groundStatus: GroundStatus, bounding: Bounding) {
const { minX, maxX, minZ, maxZ } = bounding
for (let i = minZ; i <= maxZ; i++) {
for (let j = minX; j <= maxX; j++) {
if (isValidIndex(j, i))
groundStatus[i][j]++
}
}
}
后续的待优化项
该项目的地面时一块平地,没有考虑深度方面的信息。如果是在地面有起伏的场景下,现在的数据结构是不足以应付的。如果是那种阶梯式高度的场景(地面由n片高度不同的平地构成),那么至要把 groundStatus 数组的元素的数据结构进行改造,加入地面高度标识的属性即可以满足需求。但是如果是那种高低起伏并且带有坡度的地形,那么很难进行改造。
成品展示

参考链接
- WebGL纹理详解之三:纹理尺寸与Mipmapping -- http://www.jiazhengblog.com/blog/2016/01/05/2882/
- WebGL坐标系基础 -- https://juejin.cn/post/6890795086054260750
- babylon.js 官网 -- https://www.babylonjs.com/
标签:const,GROUND,模型,网格,纹理,沙盒,坐标系,3D 来源: https://www.cnblogs.com/o2team/p/16146007.html