分块入门&卡常小技巧
作者:互联网
分块
基本分块
分块是优美的暴力,就是把一个序列分成多块来处理,每次维护块,边缘不是整块的地方暴力处理
如果我们设块长为B,则有
维护复杂度为\(\frac{n}{B}+B\)
查询复杂度为\(\frac{n}{B}+B\)
结合数学知识,我们很容易发现\(B=\sqrt n\)时,效率最高,总复杂度为O(\((n+m)\sqrt n\)),这就比一般的暴力优美多了
普通分块的优化
我们容易发现,对于某些询问,我们都需要暴力处理超过\(\sqrt n\)的边缘区间,这意味着我们的常数大了2倍多,那么我们可以考虑卡块长
离线分块(也许比莫队难卡一点)
我们可以考虑将块长修改(自己把常数扩大你就卡不了我),那么修改为多少比较合适呢?
我们再来看看问题,对于如图的询问(红线是询问,绿线是\(\sqrt n\)的分界线):
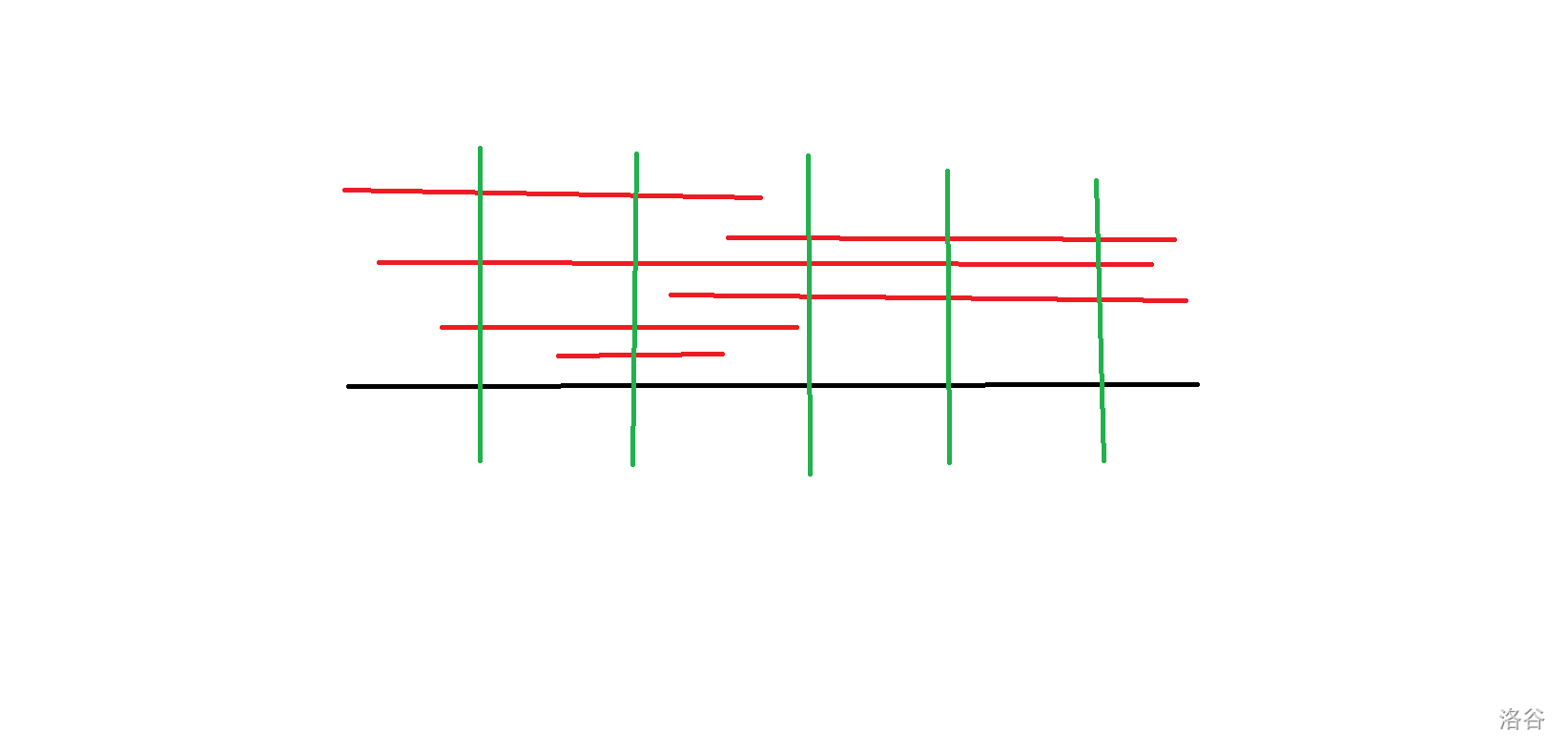
考虑优化常数,常数由两部分组成:左右的散块和中间的块数。
但如果我们修改块数的话我们的分块复杂度难以分析,可能会导致负优化,所以更普遍的,我们考虑减小散块的总长度。
于是,问题可以转化为在一个区间上打T(通常为\(\sqrt n\),不过是因题而异的)个标记,对于2M个有移动方向的pointer,最小化移动距离。
我们并不需要去完成这题的正解,对于卡常来说,极优解就够了,其实等长分块就是一种宽泛的极优解,是随机数据下的最优解。
不过如果题目支持离线,且查询答案与块长无关或关联度低(比如\(\log{n}\)等),我们可以考虑如下贪心:
1.如果一个区间中没有询问的端点,区间可以无限大(所有询问要么不经过它)
2.同一个块中所有询问的移动距离不能超过\(k\sqrt n\),把这个移动距离,其中k通常为(0.8,2)的常数
这样做,块数T不会超过\(\frac{n+m}{{(k\sqrt n)}^{\frac{1}{2}}}\)大概是\(n^{\frac{3}{4}}\)级别的,在极端情况下比普通分块劣,但大多数情况下比普通分块优
给出一组可以卡掉的数据:
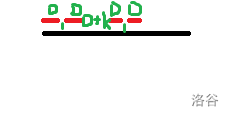
图中的'D'或'O'是指\(\frac{n+m}{{(k\sqrt n)}^{\frac{1}{2}}}\),图中的k是一个较小的随机数
暴力重构的分块
有的题目,我们需要维护区间的某些特征,在修改后需要暴力重构
记\(f(len)\)为重构一个长为len的块的复杂度,\(g(len)\)为查询一个长为len的块的答案的复杂度
显然,我们可以在询问是将区间写成开区间来微微剪枝,代码非常简单,改动之处可以手写:
ask(itn L=l-1,itn R=r+1)
{
int block_l=of[L],block_r=of[R];
//只写右边的情况
for(int i=block[block_r].L;i<R;++i)
;//统计/重构
}
特别的,如果不想改变码风,在\(f(len)\geq f(len-1)+f(1)\)并且\(g(len)\)很小时可以在每块首尾插入两个长为1的块(类比虚点),统计答案时一并统计就可以了
常数块长 or 随机块长
如果你常常对自己的常数没有信心,那么不妨写下:
block_len=1775;//看个人喜好
或者
block_len=sqrt(n)+k;//也许是别的,一定加k,否则会有负块长(真虚块)
blen=0;//防止UB
for(int i(1);i<=n;i+=blen)
{
block[++tot].L=i,
block[tot].R=min(i+(blen=block_len+randBewteen(-k,k))-1,n);//小心越界
for( block[tot].L -> block[tot].R ) ;//预处理
}
上面就是瞎搞了
卡常
读写
基本的读写
读入
scanf比cin快
getchar(),gets,getline差异不大
写出
printf比cout慢
endl会自动刷新缓存区,不要用
ios::sync_with_stdio(flase)有可能会报错,谨慎使用
cout效率其实很高,即使不关流同步
下面是一些数据:
putchar 951ms
puts 608ms
cout(字符串)483ms
cout(数字,字符强转为了int,可能不严谨)592ms
printf(字符串)18145ms
printf(值)18252ms
以上数据均为输出5e6个"n1\n"
更强的读写
普通读入优化
template<typename Tp_>
inline void read_(Tp_ &x)
{
x=0;
int fi(1);
op=getchar();
while((op<'0'||op>'9')&&op!='-') op=getchar();
if(op=='-') op=getchar(),fi==;
while(op>='0'&&op<='9') x=x*10+(op^48),op=getchar();
if(!fi) x=-x;
return;
}
关于应该写成\(x*10\)还是\((x<<3)+(x<<1)\),其实大致是没有影响的,至少影响小于评测姬波动
如果追求更小的常数,可以尝试使用fread
char B[MAXSIZE],*S=B,*T=B;
#define getchar() (S==T&&(T=(S=B)+fread(B,1,MAXSIZE,stdin),S==T)?EOF:*S++)
一般来说,MAXSIZE设成100000或(1<<15)可以在时间和空间间平衡,从趋势上讲,MAXSIZE越大,读入越快,但增加速度趋缓,大概开到(1<<21)之后的优化效果就小于评测姬波动了
快写优化
char outputChar[700000];//注意,应从0开始存
int outputLen=0;//定义
outputChar[outputLen++]=the_char_need_to_put_out;
int main()
{
...
fwrite(outputChar,1,outputLen,stdout);
return 0;
}
原理大约是模拟缓存区之类的,除此以外还有fputs的写法(据说更快?)
神秘优化
register
据说在c++11之后就没有用了,但实测还是快了,而且快了很多(2433ms->2074ms,对同一个值反复操作)
但不要滥用,在洛谷上测出来调用次数在1e4以下基本是负优化(如果要进行一些奇妙操作就说不准了,调用次数<10则几乎不影响常数)
优化const几乎肯定是负优化,手动把循环变量放到函数最前开register则可以略微加强效果
inline
对递归函数没有优化效果(可能是负优化)
对递推函数则可以略微优化1e6次-20ms
如果是在洛谷上卡常,可以禁赛三年优化:
#define inline __inline__ __attribute__((always_inline))
就是强制内联,优化效果是普通inline的两三倍
()
据说,赋初值时写()比写=要快,不过实测中不大看得出来,可以当做心理安慰
类型转换效率比用单位元去乘更慢一些,具体地
(ll)a*b%p
可以优化为
1ll*a*b%p
大概可以块5%-10%
其他优化
八聚氧,火车头
这个一查就有了,太长了,不放了
值得一提的是头文件vector中开启了O2优化
++,++
x++会先返回x加之前的值,在汇编中比++x多一句,所以会慢一点,不过不用刻意去追求就是了
连续访问内存
虽然我们认为对任意地址的访问耗时是相等的,但实际上不是,因为读取内存比读取cache慢,所以写代码时应当注意自己访问的内存尽量连续,跳跃距离尽可能小
比如在进行矩阵乘法时,我们可以朴素地写:
for(int i(1);i<=n;++i)
for(int j(1);j<=n;++j)
for(int k(1);k<=n;++k)
c[i][j]+=a[i][k]*b[k][j];
考虑优化常数(减小内存跳跃距离):
for(int i=1;i<=n;++i)
for(int k=1;k<=n;++k)
{
s=a[i][k];
for(int j=1;j<=n;++j)
c[i][j]+=s*b[k][j];
}
在计算500阶矩阵乘法时快了30-50ms,不过波动挺大的
标签:入门,分块,int,sqrt,len,卡常,优化,op 来源: https://www.cnblogs.com/efX-bk/p/15421705.html