Apache Druid 简介
作者:互联网
Apache Druid 是一个高性能的实时分析型数据库。 Druid 的主要价值是能够减少检查和查找的时间。
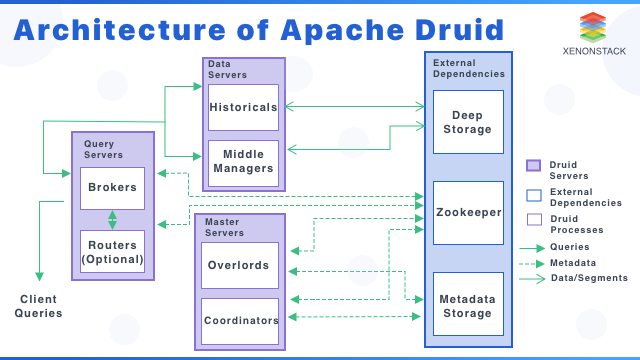
Druid 的工作流被设计为能够快速进行查询并且能够对实时的情况进行分析。
Druid 具有非常强大的 UI 界面,能够让用户进行 即席查询(Ad-Hoc Query),或者能够处理高并发。
针对数据库仓库或一系列的用户使用案例,可以将 Druid 考虑为这些使用场景的开源解决方案。
Ad-Hoc Query
如果你对 Ad-Hoc Query (即席查询)的概念和使用不是是否清楚的话,请自行搜索相关的技术文档。
简单来说:即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。
即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
即席查询是指那些用户在使用系统时,根据自己当时的需求定义的查询。
对即席查询来说,用户需要查询的内容在开始的时候是不知道的,因此查询需要更多的维度,查询很多时候都是在运行的时候再构建的。
Druid 的查询能够很好的支持即席查询,但同时也带来一些复杂性和学习曲线。
云原生、流原生的分析型数据库
Druid专为需要快速数据查询与摄入的工作流程而设计,在即时数据可见性、即席查询、运营分析以及高并发等方面表现非常出色。
在实际中的众多场景下数据仓库解决方案,都可以考虑将 Druid 作为一种开源的替代解决方案。
请访问 Druid 资源快速导航 页面来简要查看我们收集的相关技术文档和使用案例。
轻松与现有的数据源
Druid 原生支持从 Kafka ,Amazon Kinesis 等消息总线中流式的消费数据, 也同时支持从 HDFS , Amazon S3 等存储服务中批量加载数据。
较传统方案提升近百倍的效率
Druid 创新地在架构设计上吸收和结合了数据仓库, 时序数据库 以及 检索系统 的优势。
在已完成的 基准测试 中针对传统数据输入和查询的解决方案展现强大的性能。
解锁了一种新型的工作流程
Druid 为点击流、APM、供应链、网络监测、市场营销以及其他事件驱动类型的数据分析解锁了一种新型的查询与工作流程, 它专为实时和历史数据高效快速的即席查询而设计。
强大部署能力
Druid 可部署在 AWS/GCP/Azure, 混合云, Kubernetes, 以及裸机上,针对中文环境阿里的云计算平台也提供了无缝集成。 无论在云上还是本地,Druid 都可以轻松部署在基于 *NIX 环境的任何商用硬件上。部署 Druid 是非常简单的,包括集群的扩容或者下线都也同样很简单。
https://www.ossez.com/t/apache-druid/13602
标签:Hoc,用户,简介,Druid,查询,即席,Apache,Ad 来源: https://www.cnblogs.com/huyuchengus/p/15054184.html