BFS 算法解题套路框架
作者:互联网
BFS 算法解题套路框架
BFS 的核心思想应该不难理解的,就是把一些问题抽象成图,从一个点开始,向四周开始扩散。一般来说,我们写 BFS 算法都是用「队列」这种数据结构,每次将一个节点周围的所有节点加入队列。
特点:BFS 找到的路径一定是最短的,但代价就是空间复杂度可能比 DFS 大很多
一、算法框架
问题的本质就是让你在一幅「图」中找到从起点 start 到终点 target 的最近距离
框架:
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这里判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
/* 划重点:更新步数在这里 */
step++;
}
}
队列 q :BFS 的核心数据结构;cur.adj() 泛指 cur 相邻的节点,比如说二维数组中,cur 上下左右四面的位置就是相邻节点;visited 的主要作用是防止走回头路,大部分时候都是必须的,但是像一般的二叉树结构,没有子节点到父节点的指针,不会走回头路就不需要 visited。
二、二叉树的最小高度
力扣第 111 题「 二叉树的最小深度」
思路:简单,与框架差不多,也可以使用深度优先搜索。
class Solution {
public:
int minDepth(TreeNode* root) {
//最小深度 即第一次遍历到叶子结点的深度
//root为null
if(root==nullptr)return 0;
//BFS核心数据结构
queue<TreeNode*>q;
//深度 也就是步数
int depth=0;
//root不为null
q.push(root);
depth++;
//队列不为空时
while(!q.empty()){
int sz=q.size();//队列中元素数量
//对队列中元素的所有节点向下扩散(本题中就是扩散到下一行)
for(int i=0;i<sz;i++){
//走过的元素就出队列
TreeNode* cur=q.front();
q.pop();
//找到第一个叶子节点,即左右子树都没有
if(cur->left==nullptr&&cur->right==nullptr){
return depth;
}
//未找到 就将cur的子树加入队列
if(cur->left!=nullptr)q.push(cur->left);
if(cur->right!=nullptr)q.push(cur->right);
}
//查找过一行那么深度就+1
depth++;
}
return depth;
}
};
书中解析较为详细:
这里注意这个 while 循环和 for 循环的配合,while 循环控制一层一层往下走,for 循环利用 sz 变量控制从左到右遍历每一层二叉树节点:

对于两个问题的解答:
1、为什么 BFS 可以找到最短距离,DFS 不行吗?
首先,你看 BFS 的逻辑,depth 每增加一次,队列中的所有节点都向前迈一步,这保证了第一次到达终点的时候,走的步数是最少的。
DFS 不能找最短路径吗?其实也是可以的,但是时间复杂度相对高很多。你想啊,DFS 实际上是靠递归的堆栈记录走过的路径,你要找到最短路径,肯定得把二叉树中所有树杈都探索完才能对比出最短的路径有多长对不对?而 BFS 借助队列做到一次一步「齐头并进」,是可以在不遍历完整棵树的条件下找到最短距离的。
2、既然 BFS 那么好,为啥 DFS 还要存在?
BFS 可以找到最短距离,但是空间复杂度高,而 DFS 的空间复杂度较低。
还是拿刚才我们处理二叉树问题的例子,假设给你的这个二叉树是满二叉树,节点数为 N,对于 DFS 算法来说,空间复杂度无非就是递归堆栈,最坏情况下顶多就是树的高度,也就是 O(logN)。
但是你想想 BFS 算法,队列中每次都会储存着二叉树一层的节点,这样的话最坏情况下空间复杂度应该是树的最底层节点的数量,也就是 N/2,用 Big O 表示的话也就是 O(N)。
由此观之,BFS 还是有代价的,一般来说在找最短路径的时候使用 BFS,其他时候还是 DFS 使用得多一些(主要是递归代码好写)。
三、解开密码锁的最少次数
这是力扣第 752 题「 打开转盘锁」,比较有意思:
代码:作者给出的是java类型,这是我的C++代码
class Solution {
public:
int openLock(vector<string>& deadends, string target) {
//查找最小旋转次数 优先考虑BFS
//每次只能转一个数字
queue<string>q;//BFS核心数据结构
set<string>visited;//记录转到过的密码,减少重复
//初始化锁
q.push("0000");
visited.insert("0000");
//记录最小旋转次数
int step=0;
while(!q.empty()){
int sz=q.size();//记录队列中的元素数量
for(int i=0;i<sz;i++){//遍历旋转一个数的所有可能性
string cur=q.front();
q.pop();
if(cur==target)return step;//如果搜索到target返回
//如果cur在deadends中,放弃此种状况
if(find(deadends.begin(),deadends.end(),cur)!=deadends.end()){
continue;
}
//每次转要么是一个数+1,要么是一个数-1
for(int j=0;j<4;j++){
string a=cur;
sPlus(a,j);//+1
//如果a未记录过
if(visited.find(a)==visited.end()){
q.push(a);
visited.insert(a);
}
}
for(int j=0;j<4;j++){
string a=cur;
sMinus(a,j);//-1
//如果a未记录过
if(visited.find(a)==visited.end()){
q.push(a);
visited.insert(a);
}
}
}
step++;
}
return -1;//穷举完仍然没有找到密码,就是找不到
}
void sPlus(string &cur,int num){//对特定位置+1
if(cur[num]=='9'){
cur[num]='0';
return;
}
cur[num]+=1;
}
void sMinus(string &cur,int num){//对特定位置-1
if(cur[num]=='0'){
cur[num]='9';
return;
}
cur[num]-=1;
}
};
解析:
现在的难点就在于,不能出现 deadends,应该如何计算出最少的转动次数呢?
第一步,我们不管所有的限制条件,不管 deadends 和 target 的限制,就思考一个问题:如果让你设计一个算法,穷举所有可能的密码组合,你怎么做?
仔细想想,这就可以抽象成一幅图,每个节点有 8 个相邻的节点,又让你求最短距离,就是典型的 BFS
重复
要注意优化掉出现重复的现象,我这里选择set容器来记录是否访问过锁的组合
剩下的内容并未能理解,留作以后在做学习
四、双向 BFS 优化
你以为到这里 BFS 算法就结束了?恰恰相反。BFS 算法还有一种稍微高级一点的优化思路:双向 BFS,可以进一步提高算法的效率。
篇幅所限,这里就提一下区别:传统的 BFS 框架就是从起点开始向四周扩散,遇到终点时停止;而双向 BFS 则是从起点和终点同时开始扩散,当两边有交集的时候停止。
为什么这样能够能够提升效率呢?其实从 Big O 表示法分析算法复杂度的话,它俩的最坏复杂度都是 O(N),但是实际上双向 BFS 确实会快一些,我给你画两张图看一眼就明白了:
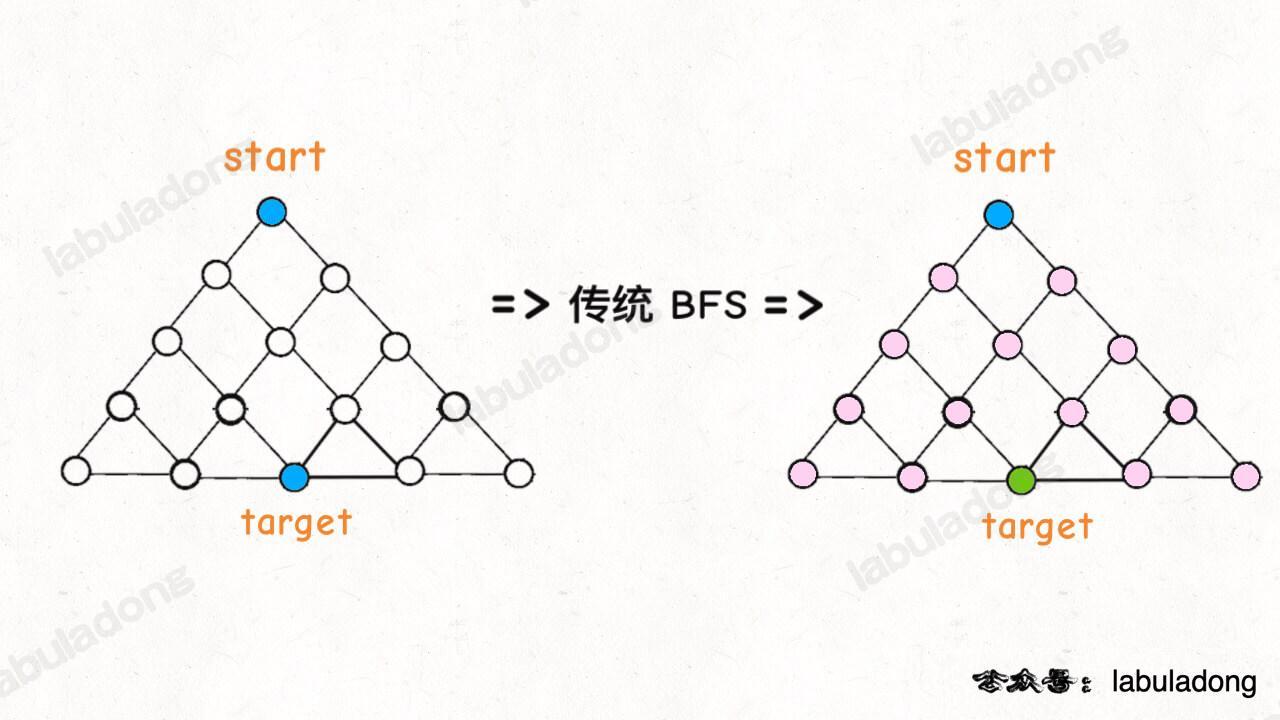
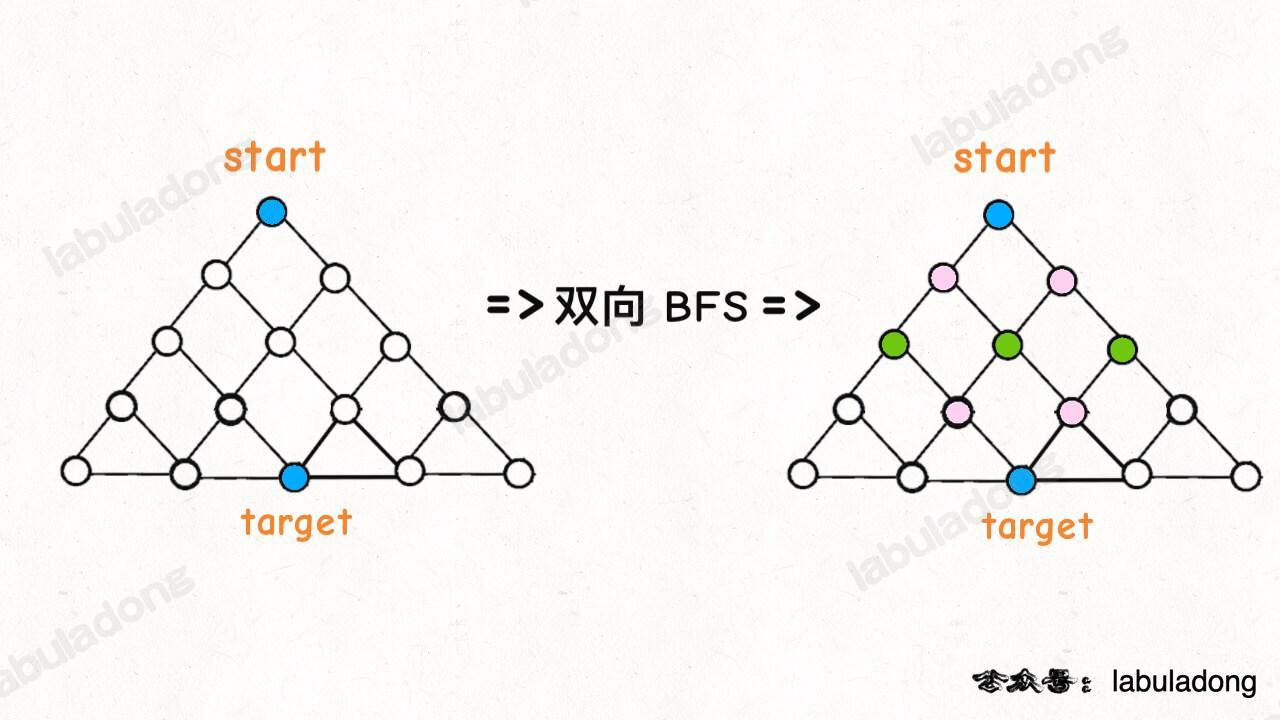
图示中的树形结构,如果终点在最底部,按照传统 BFS 算法的策略,会把整棵树的节点都搜索一遍,最后找到 target;而双向 BFS 其实只遍历了半棵树就出现了交集,也就是找到了最短距离。从这个例子可以直观地感受到,双向 BFS 是要比传统 BFS 高效的。
不过,双向 BFS 也有局限,因为你必须知道终点在哪里。比如我们刚才讨论的二叉树最小高度的问题,你一开始根本就不知道终点在哪里,也就无法使用双向 BFS;但是第二个密码锁的问题,是可以使用双向 BFS 算法来提高效率的,代码稍加修改即可:
int openLock(String[] deadends, String target) {
Set<String> deads = new HashSet<>();
for (String s : deadends) deads.add(s);
// 用集合不用队列,可以快速判断元素是否存在
Set<String> q1 = new HashSet<>();
Set<String> q2 = new HashSet<>();
Set<String> visited = new HashSet<>();
int step = 0;
q1.add("0000");
q2.add(target);
while (!q1.isEmpty() && !q2.isEmpty()) {
// 哈希集合在遍历的过程中不能修改,用 temp 存储扩散结果
Set<String> temp = new HashSet<>();
/* 将 q1 中的所有节点向周围扩散 */
for (String cur : q1) {
/* 判断是否到达终点 */
if (deads.contains(cur))
continue;
if (q2.contains(cur))
return step;
visited.add(cur);
/* 将一个节点的未遍历相邻节点加入集合 */
for (int j = 0; j < 4; j++) {
String up = plusOne(cur, j);
if (!visited.contains(up))
temp.add(up);
String down = minusOne(cur, j);
if (!visited.contains(down))
temp.add(down);
}
}
/* 在这里增加步数 */
step++;
// temp 相当于 q1
// 这里交换 q1 q2,下一轮 while 就是扩散 q2
q1 = q2;
q2 = temp;
}
return -1;
}
双向 BFS 还是遵循 BFS 算法框架的,只是不再使用队列,而是使用 HashSet 方便快速判断两个集合是否有交集。
另外的一个技巧点就是 while 循环的最后交换 q1 和 q2 的内容,所以只要默认扩散 q1 就相当于轮流扩散 q1 和 q2。
其实双向 BFS 还有一个优化,就是在 while 循环开始时做一个判断:
// ...
while (!q1.isEmpty() && !q2.isEmpty()) {
if (q1.size() > q2.size()) {
// 交换 q1 和 q2
temp = q1;
q1 = q2;
q2 = temp;
}
// ...
为什么这是一个优化呢?
因为按照 BFS 的逻辑,队列(集合)中的元素越多,扩散之后新的队列(集合)中的元素就越多;在双向 BFS 算法中,如果我们每次都选择一个较小的集合进行扩散,那么占用的空间增长速度就会慢一些,效率就会高一些。
不过话说回来,无论传统 BFS 还是双向 BFS,无论做不做优化,从 Big O 衡量标准来看,时间复杂度都是一样的,只能说双向 BFS 是一种 trick,算法运行的速度会相对快一点,掌握不掌握其实都无所谓。最关键的是把 BFS 通用框架记下来,反正所有 BFS 算法都可以用它套出解法。
标签:q1,q2,cur,套路,BFS,int,解题,节点 来源: https://www.cnblogs.com/BailanZ/p/16085360.html