雷丰阳springboot之数据访问JDBC
作者:互联网
雷丰阳课件



视频跟学
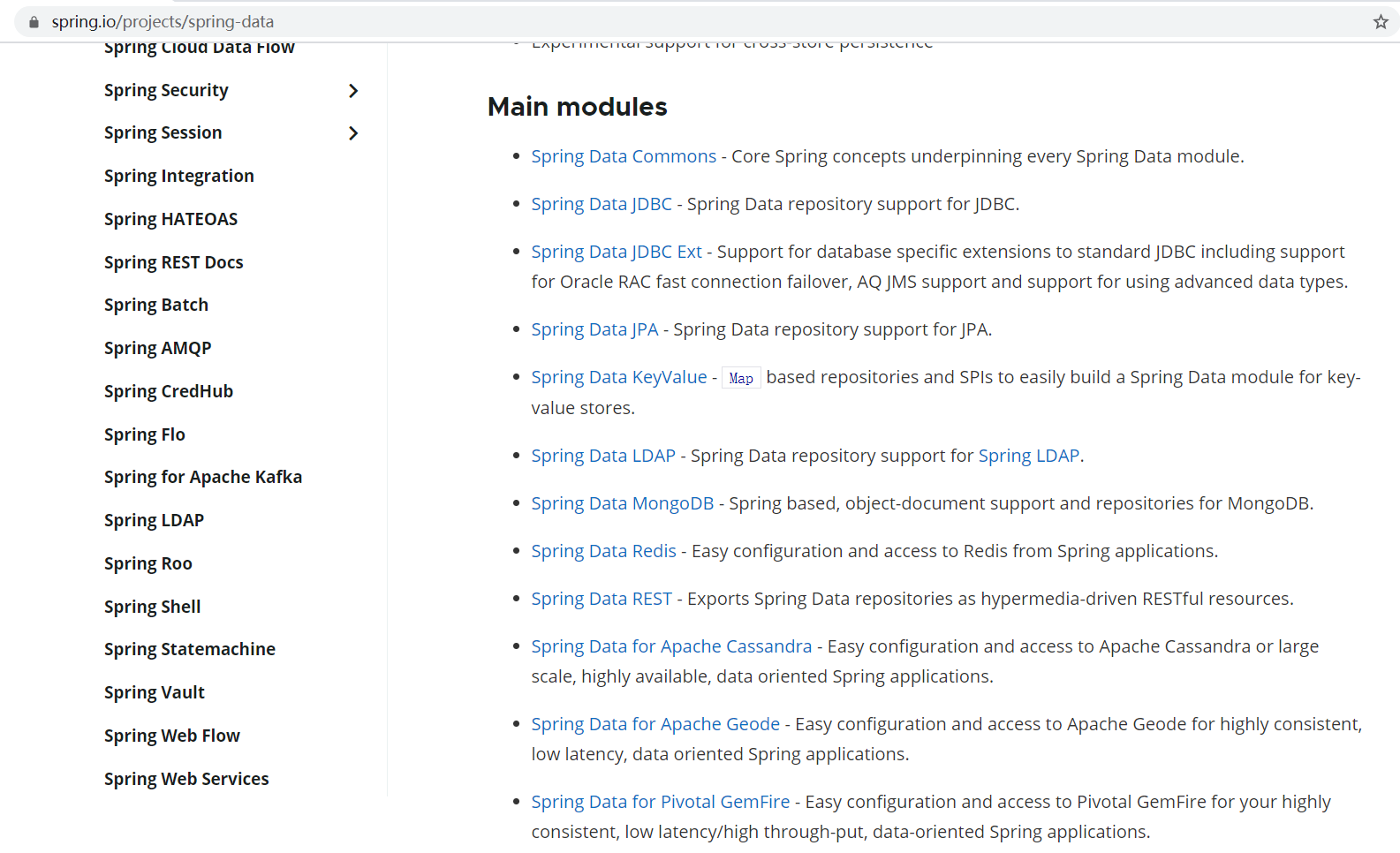
spring boot底层使用spring data作为数据访问的默认处理方式。
要使用数据访问的功能,就需要导入相应的starters,就是场景启动器。
参考:https://docs.spring.io/spring-boot/docs/1.5.10.RELEASE/reference/htmlsingle/#using-boot-starter
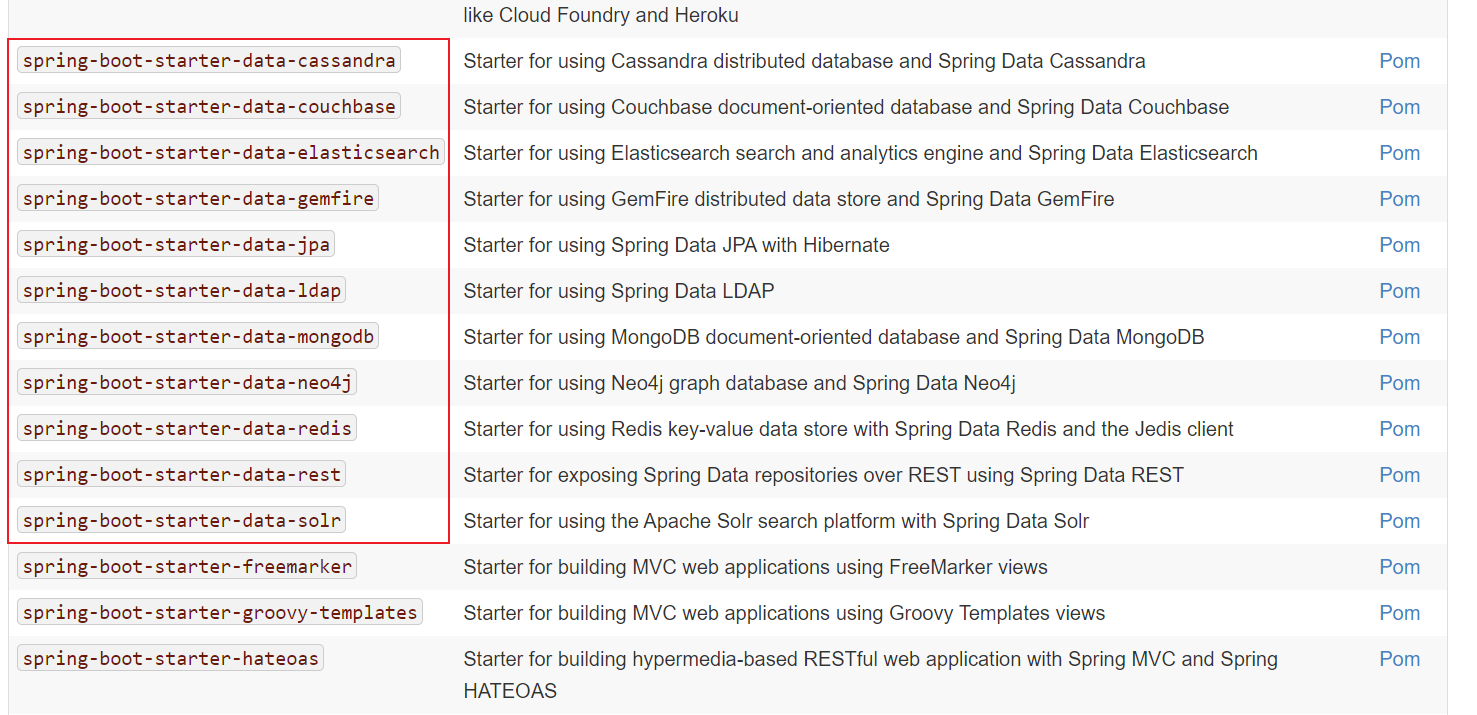
官方并没有提供spring-boot-starter-mybatis相关场景的整合。
整合基本JDBC与数据源
第一步:创建项目
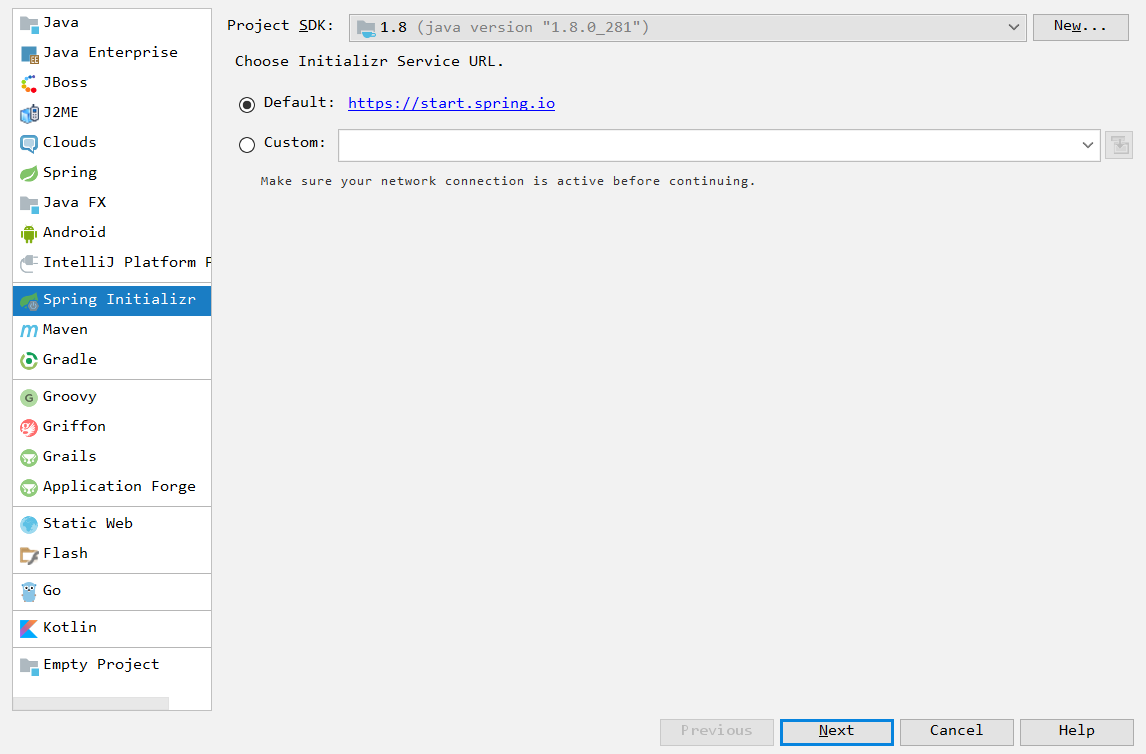
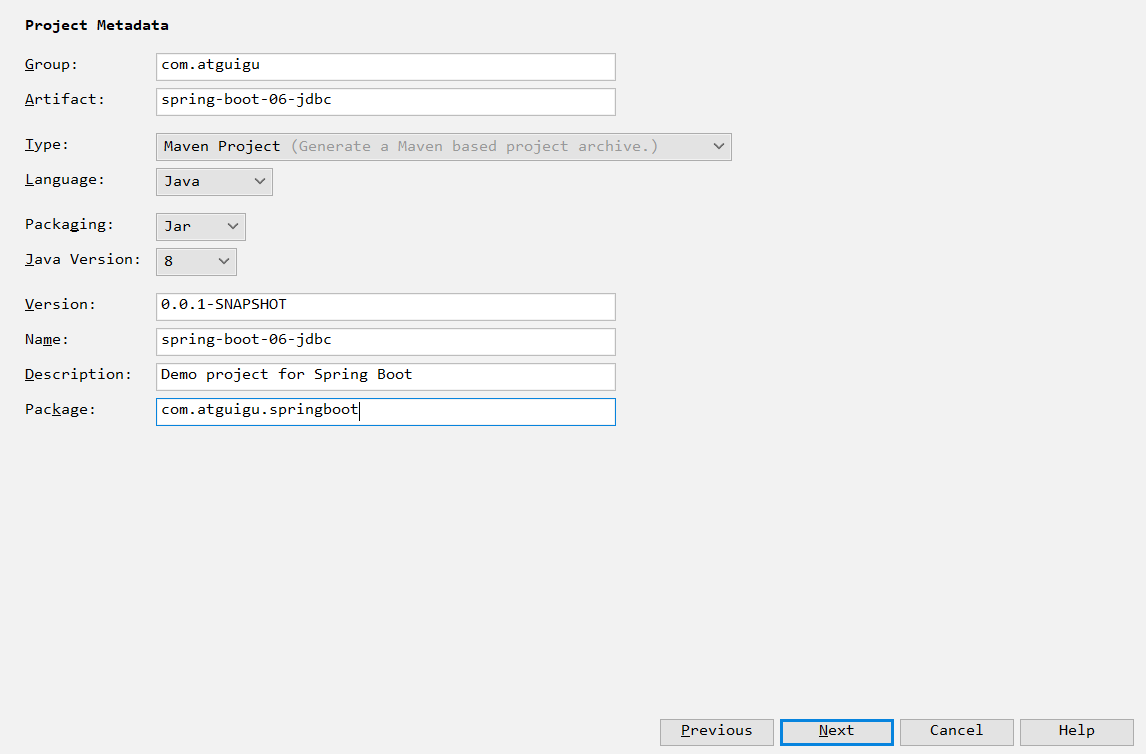

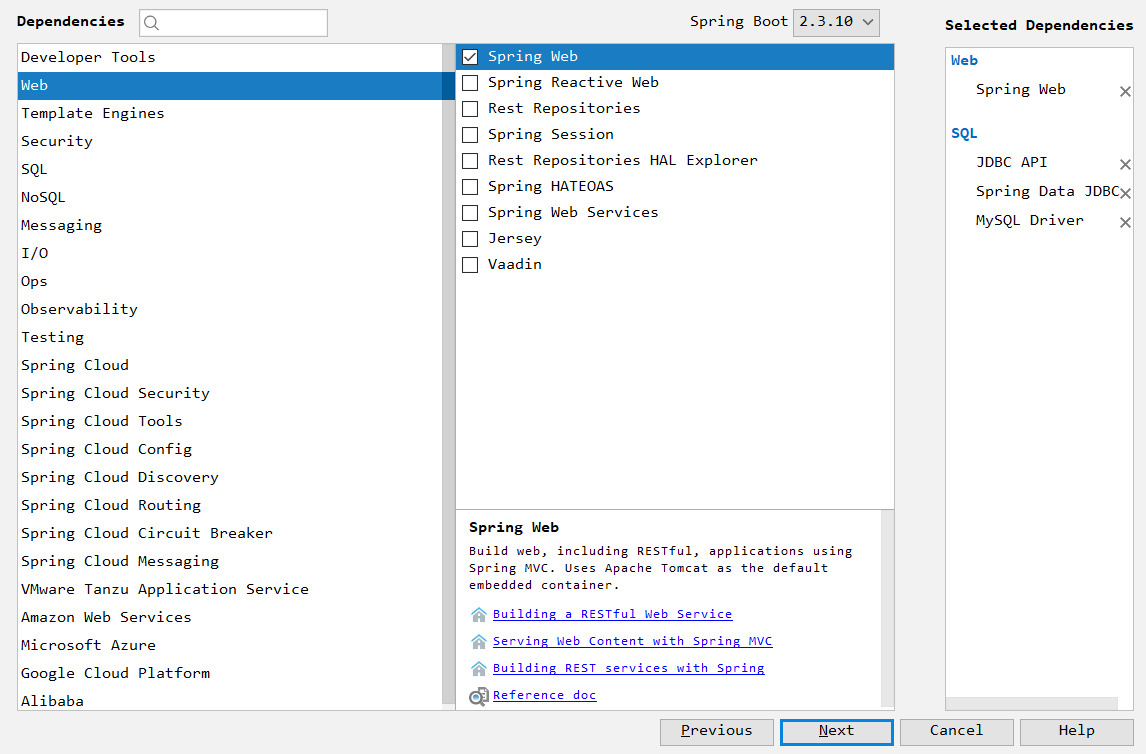
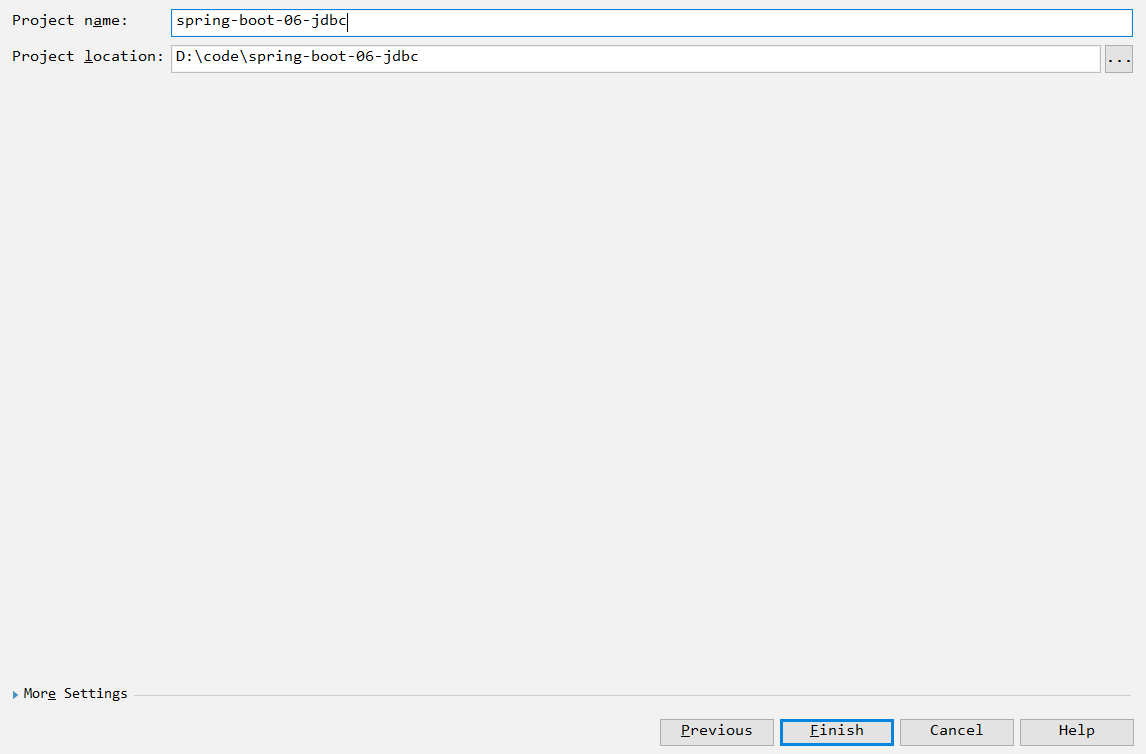
为了和雷丰阳保持一致,我把springboot的版本,修改为1.5.10。
点击自动导入
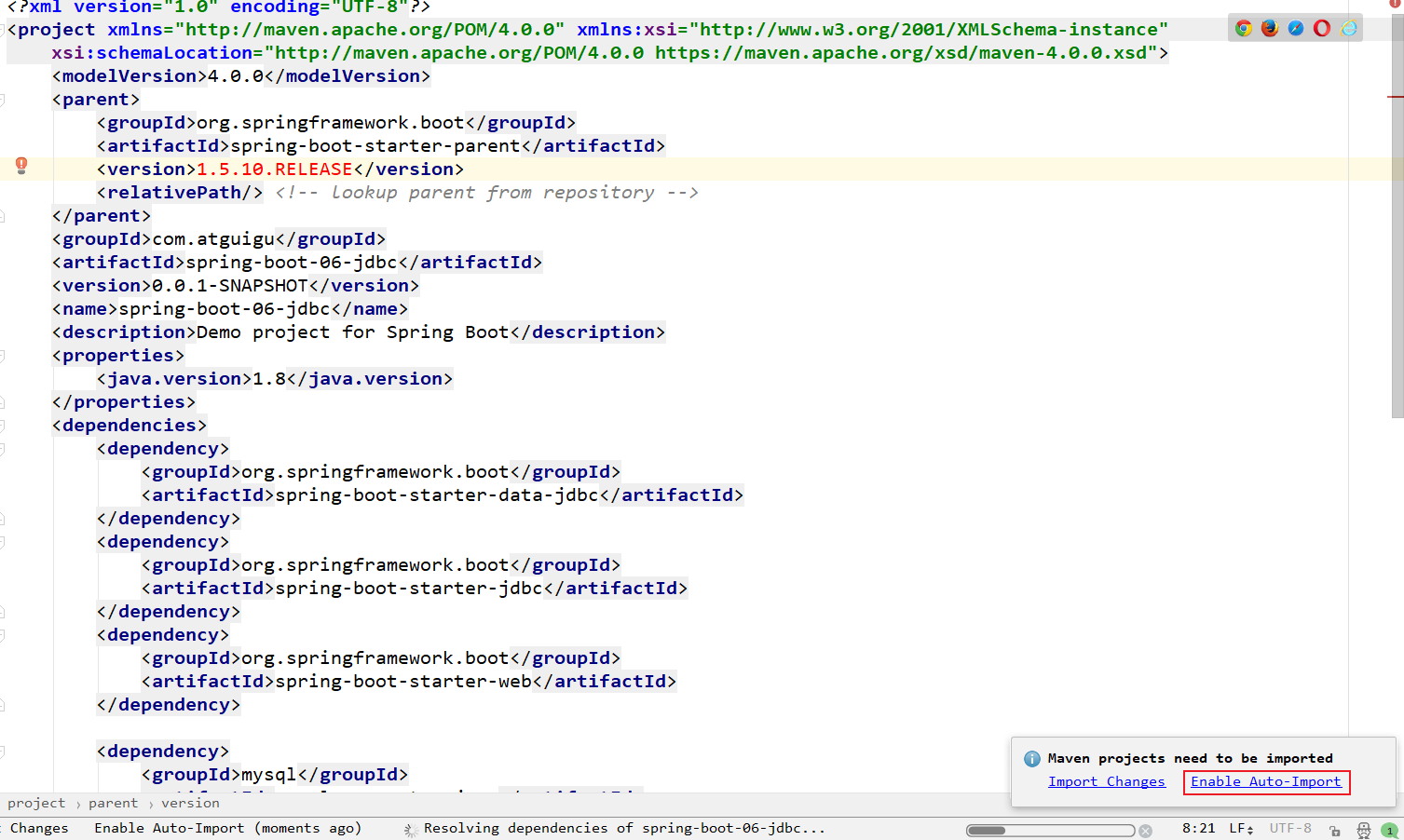
最终,创建好了项目之后,pom文件当中的依赖,是下面的样子的。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
第二步:连上虚拟机的数据库。
在这里出现了一个问题。
之前我是用韫秋的热点连接的电脑。现在我是用wifi连接的电脑。
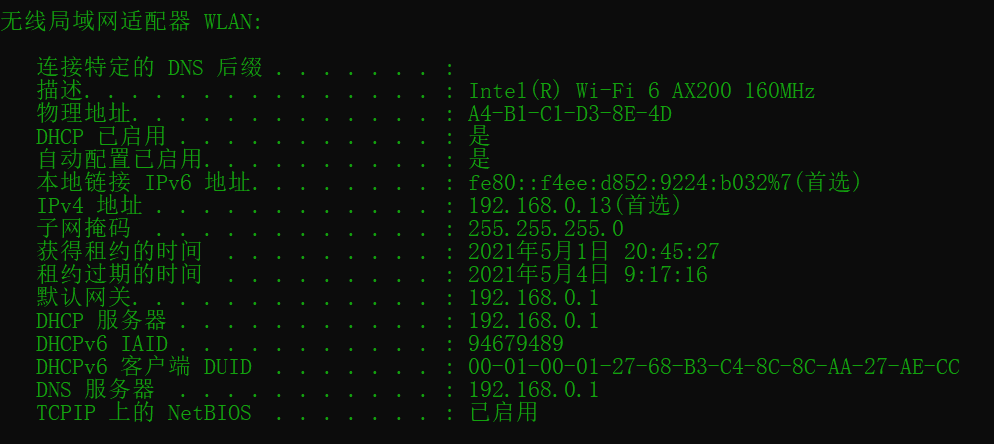
现在主机的ip是:192.168.0.13.
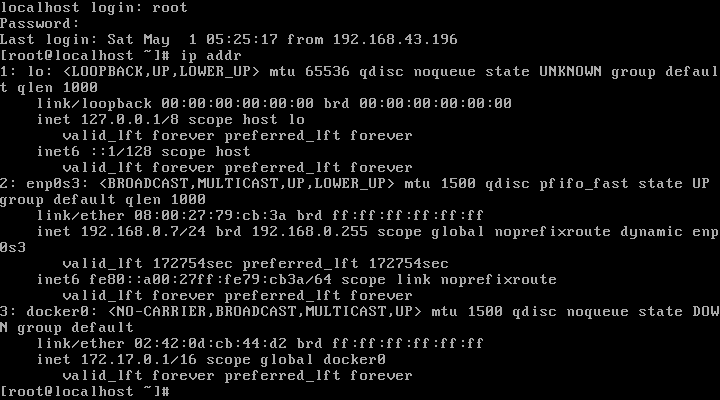
虚拟机的ip是:192.168.0.7
确定了这两个ip之后,再使用smartty进行连接。
在虚拟机当中使用docker ps -a找到昨天韫秋启动的mysql容器。
然后docker start [container id]启动相应的mysql容器。
然后使用navicat连接数据库,如下图所示:
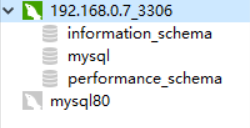
连接成功了。
下一步,就是要思考,如何在程序当中连接数据库了。
第三步:如何在程序当中连接数据库

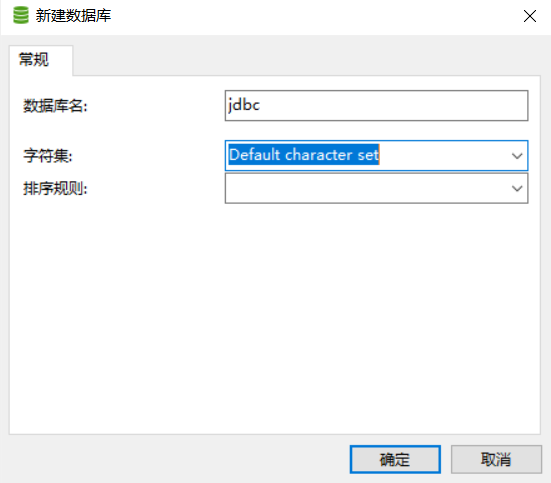
然后进行测试。
在打开了下面的界面的时候,出现了包报错的问题:
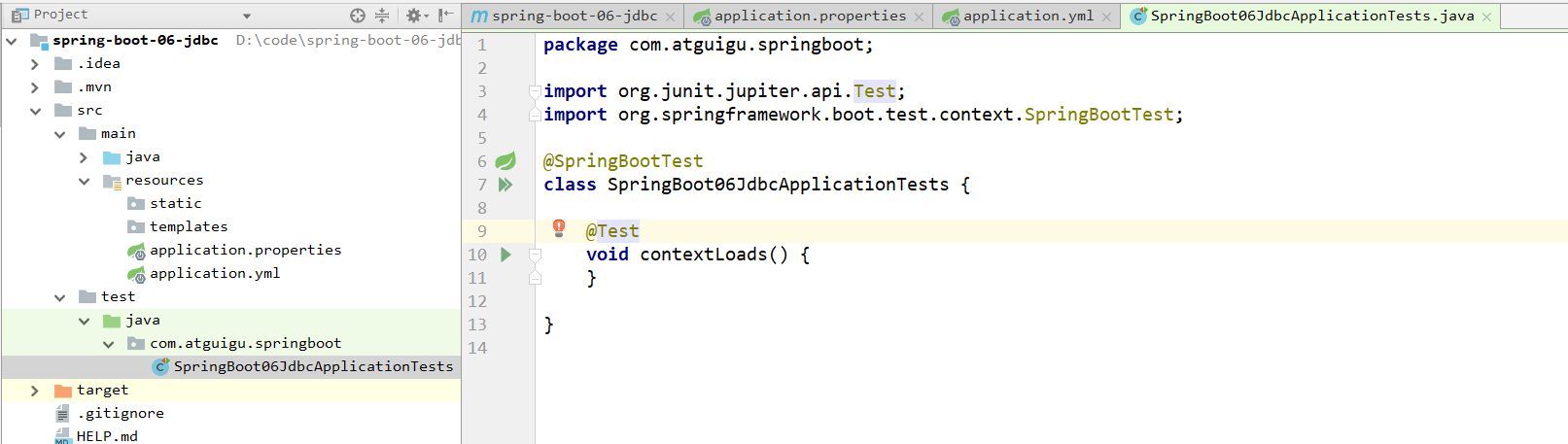
原来这里有一个:import org.junit.jupiter.api.Test;包报错的问题。
我是搜索参考了:https://blog.csdn.net/li1325169021/article/details/103511043,这篇文章,然后解决了这个问题。
小问题
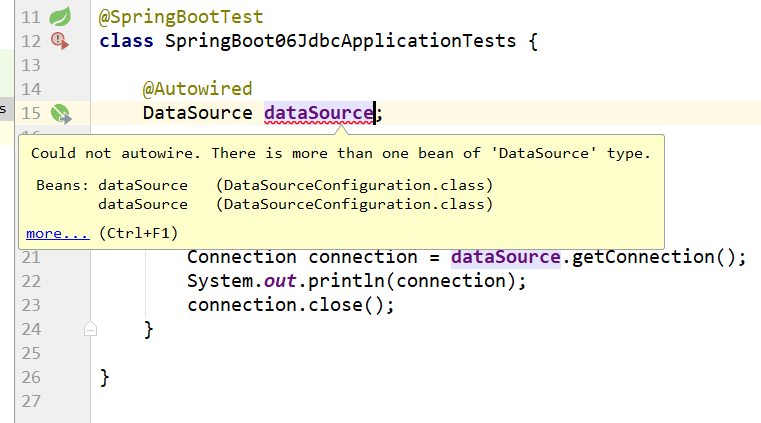
参考https://blog.csdn.net/jianxin1021/article/details/104845243/

解决了,是不报错了。

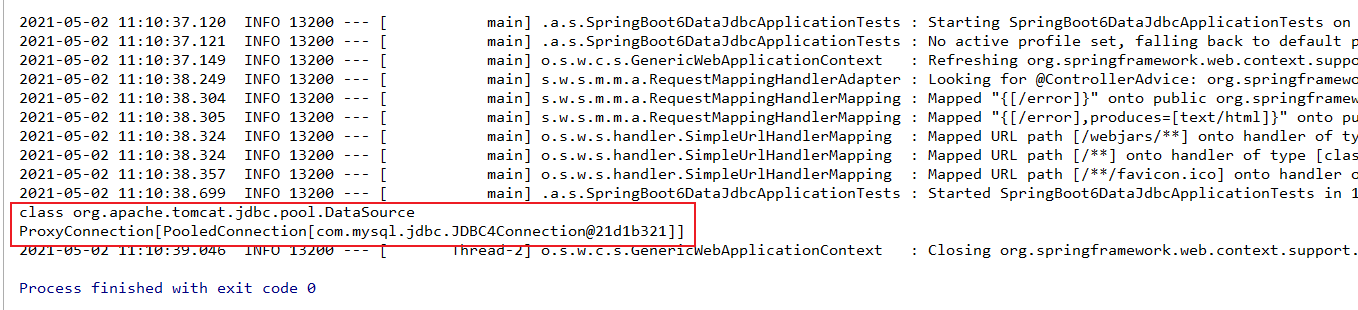
class org.apache.tomcat.jdbc.pool.DataSource
ProxyConnection[PooledConnection[com.mysql.jdbc.JDBC4Connection@21d1b321]]
表示访问成功。
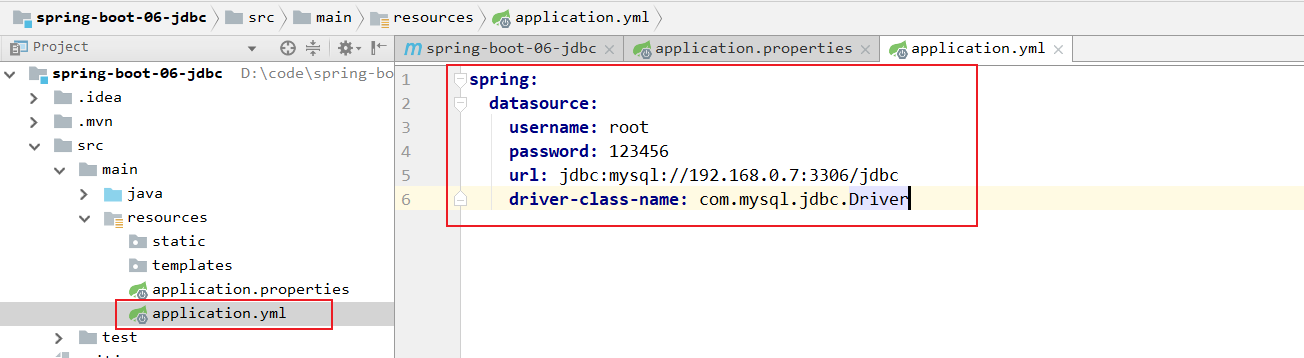
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://192.168.0.7:3306/jdbc
driver-class-name: com.mysql.jdbc.Driver
上面的配置,默认使用的是org.apache.tomcat.jdbc.pool.DataSource数据源的。
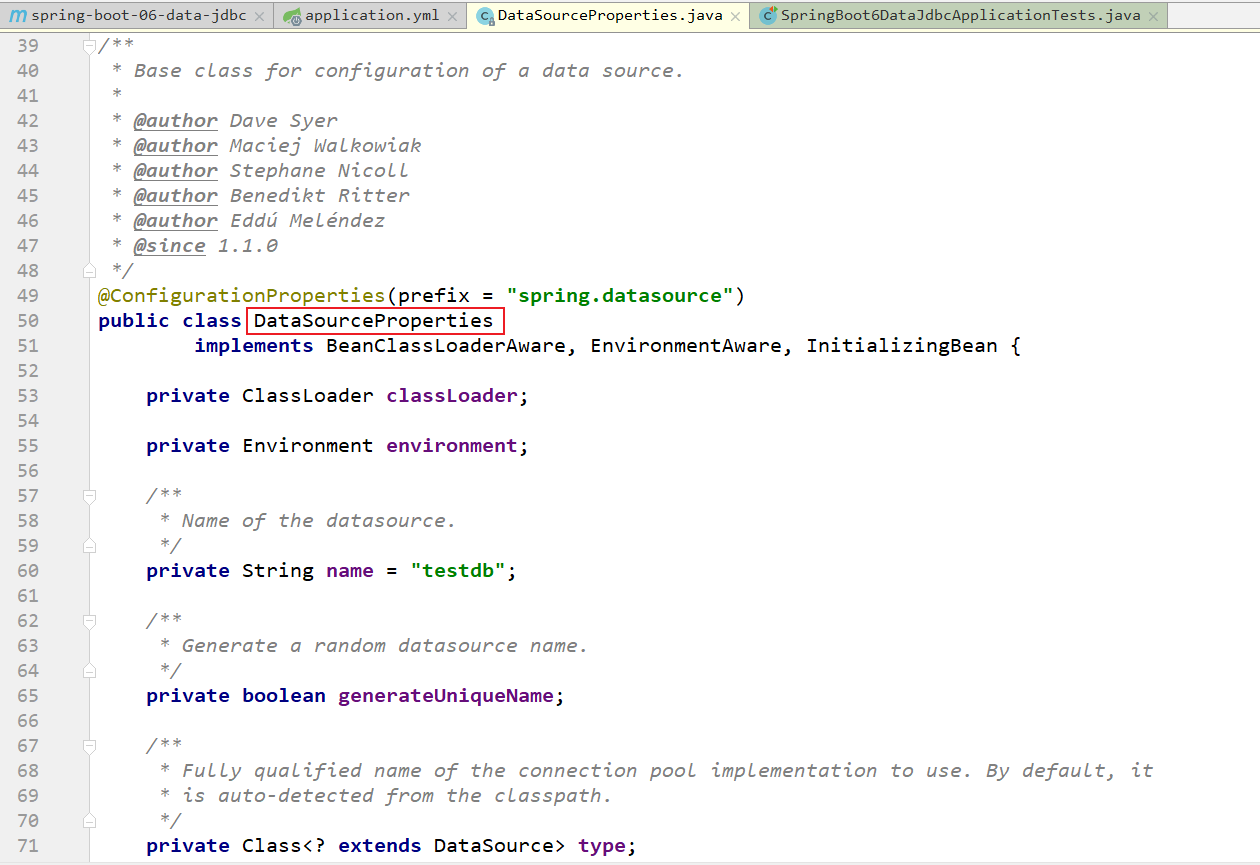
数据源的相关配置,默认都是在DataSourceProperties里面的。
第四步:探究一下springboot datasource的自动配置原理
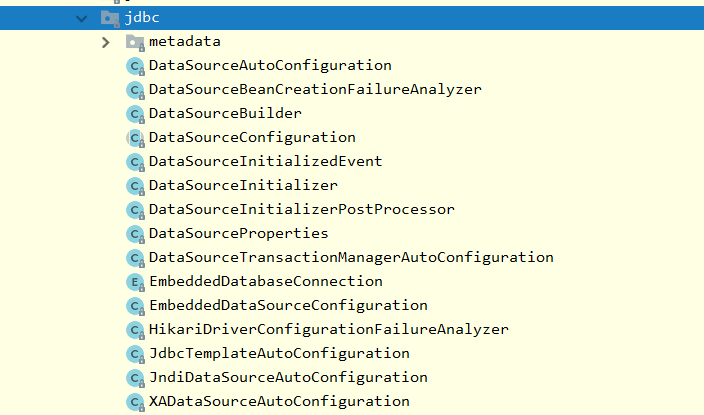
自动配置原理,就在这个包下:org.springframework.boot.autoconfigure.jdbc
数据源自动配置 - DataSourceConfiguration
这个类,就是根据你的各种配置,创建数据源,默认是使用tomcat连接池的。

可以使用spring.datasource.type指定自定义的数据源类型的。比如我们经常用的c3p0,或者是dbcp等等。
springboot默认支持的数据源有:org.apache.tomcat.jdbc.pool.DataSource,HikariDataSource,org.apache.commons.dbcp.BasicDataSource,org.apache.commons.dbcp2.BasicDataSource
在这个类中,下面的内容,表示的是,你可以自定义,数据源的类型。

/**
* Generic DataSource configuration.
*/
@ConditionalOnMissingBean(DataSource.class)
@ConditionalOnProperty(name = "spring.datasource.type")
static class Generic {
@Bean
public DataSource dataSource(DataSourceProperties properties) {
//如果你使用了自定义的数据源的话
//这个数据源是怎么创建出来的呢?
//是使用properties这个绑定了数据源属性的类。
//用properties调用了initializeDataSourceBuilder的build()
//利用反射创建相应type的数据源,并且绑定相关的属性
return properties.initializeDataSourceBuilder().build();
}
}
具体的过程如下:

数据源初始化自动配置 - DataSourceAutoConfiguration
在这个DataSourceAutoConfiguration当中,给IOC容器,添加了一个DataSourceInitializer。
在源码当中的位置,如图所示:
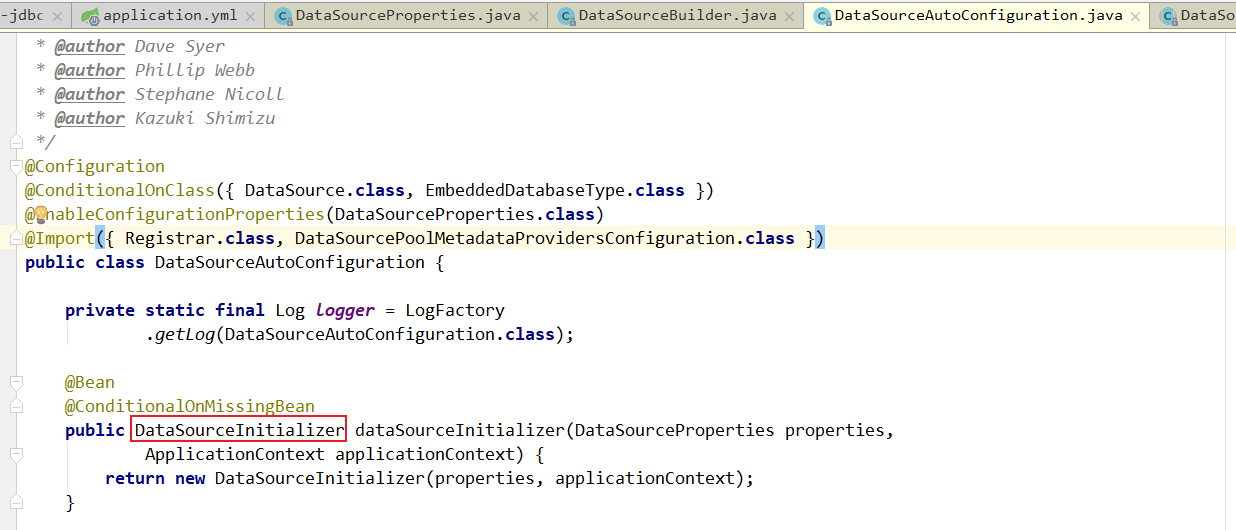
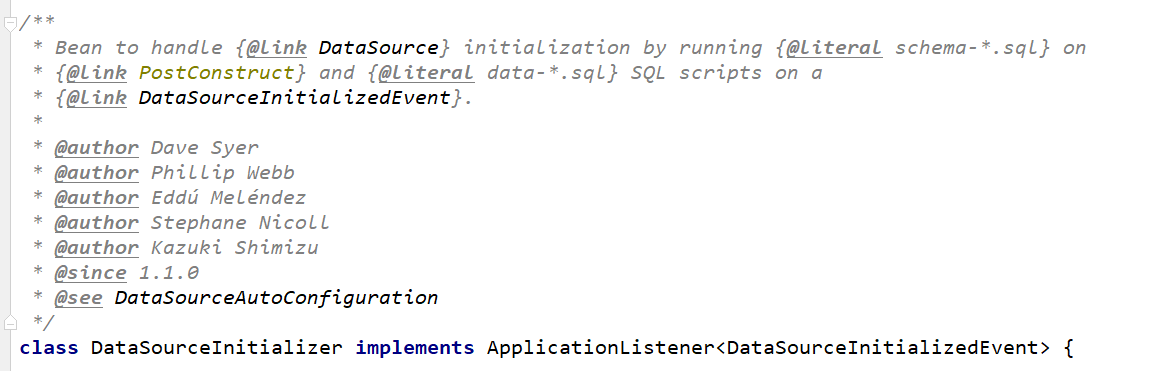
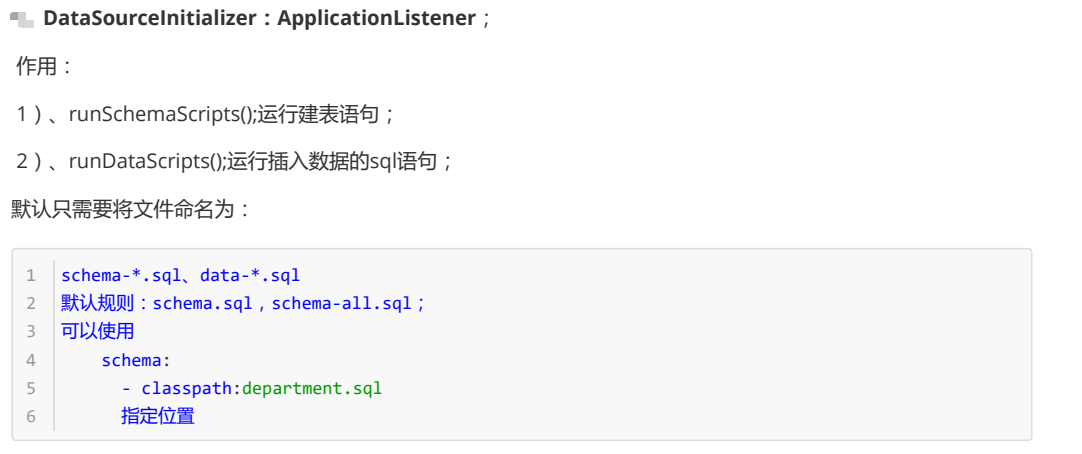
DataSourceInitializer的作用是什么呢?
DataSourceInitializer实际上就是一个ApplicationListener<DataSourceInitializedEvent>
关于ApplicationListener,雷丰阳在spring注解版当中讲解过的。
韫秋我还没有学过呢。这个要记下来。
到时候学习一下呢。
请参考下面的源码图:
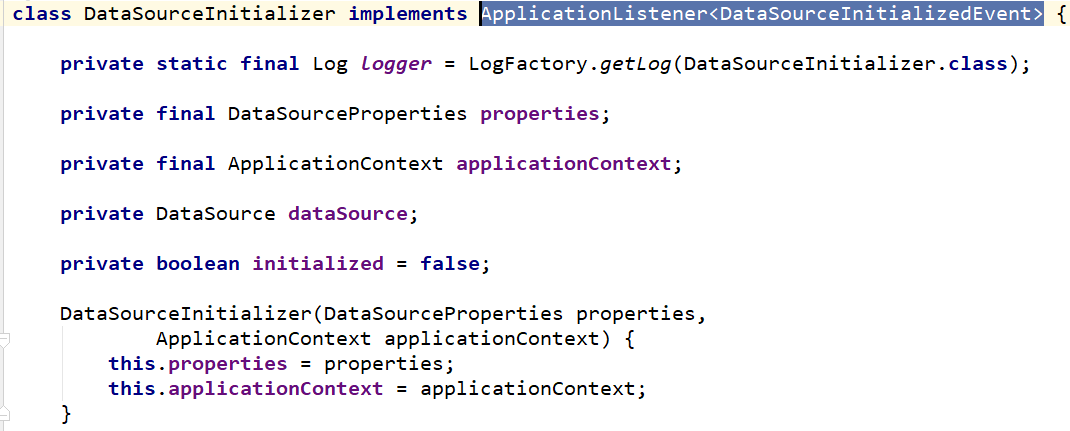
我们可以通过阅读源码的方式,慢慢摸清楚DataSourceInitializer到底有什么作用。

上面这张图表示了DataSourceInitializer的第一个作用,是runSchemaScripts()是运行建表语句。
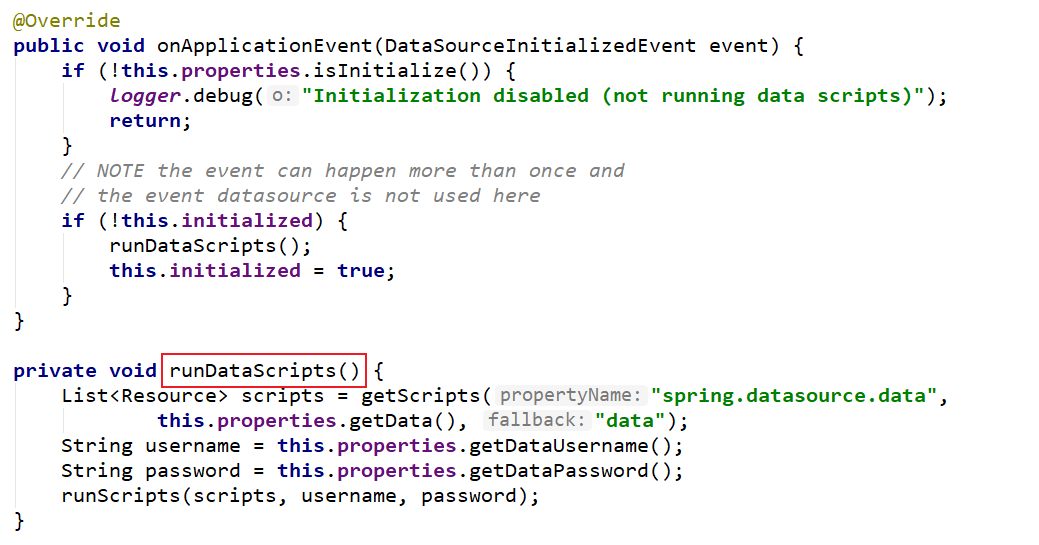
上面这张图表示了DataSourceInitializer的第二个作用,是runDataScripts(),是可以运行插入数据的sql语句。
默认只需要将文件命名为:schema-*.sql,或者data-*.sql这样的名字,如果是初始化的时候的建表语句,就是schema-*.sql,如果是初始化的时候的插入数据的语句,就是data-*.sql,就可以了。
测试一下启动创建sql表文件
导入一个写好的sql文件:department.sql

接下来,阅读一下源码当中关于初始化的时候,进行建表的处理的源码:
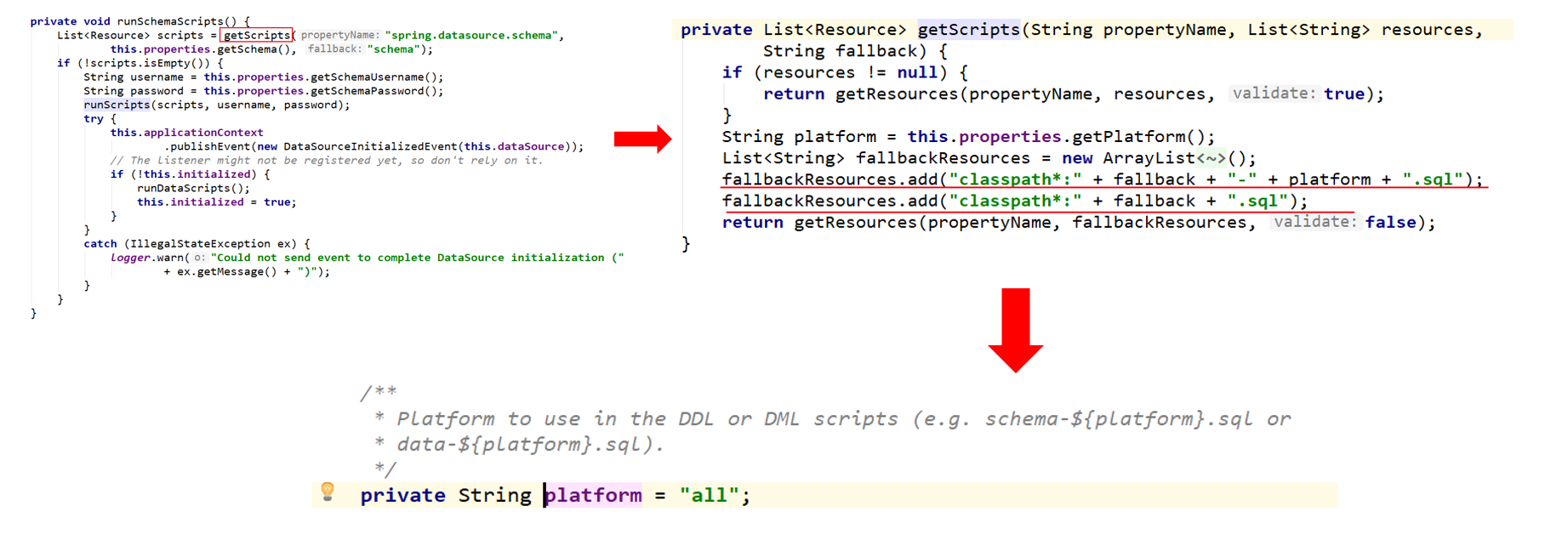
从上面的代码中,可以知道,如果想要在数据源初始化的时候,进行建表,必须把我们的sql文件命名为schema-all.sql或者是schema.sql。
启动一下主程序:
我们查看一下navicat:
看到已经执行成功了。
如果我们是按照自定义规则的名字,来命名我们的sql文件,行不行呢?
我们将我们的sql文件命名为department.sql,
在我们的配置文件当中,编写schema配置,如下图所示,然后删除数据库当中的表,再重新启动我们的主程序,如下图所示:
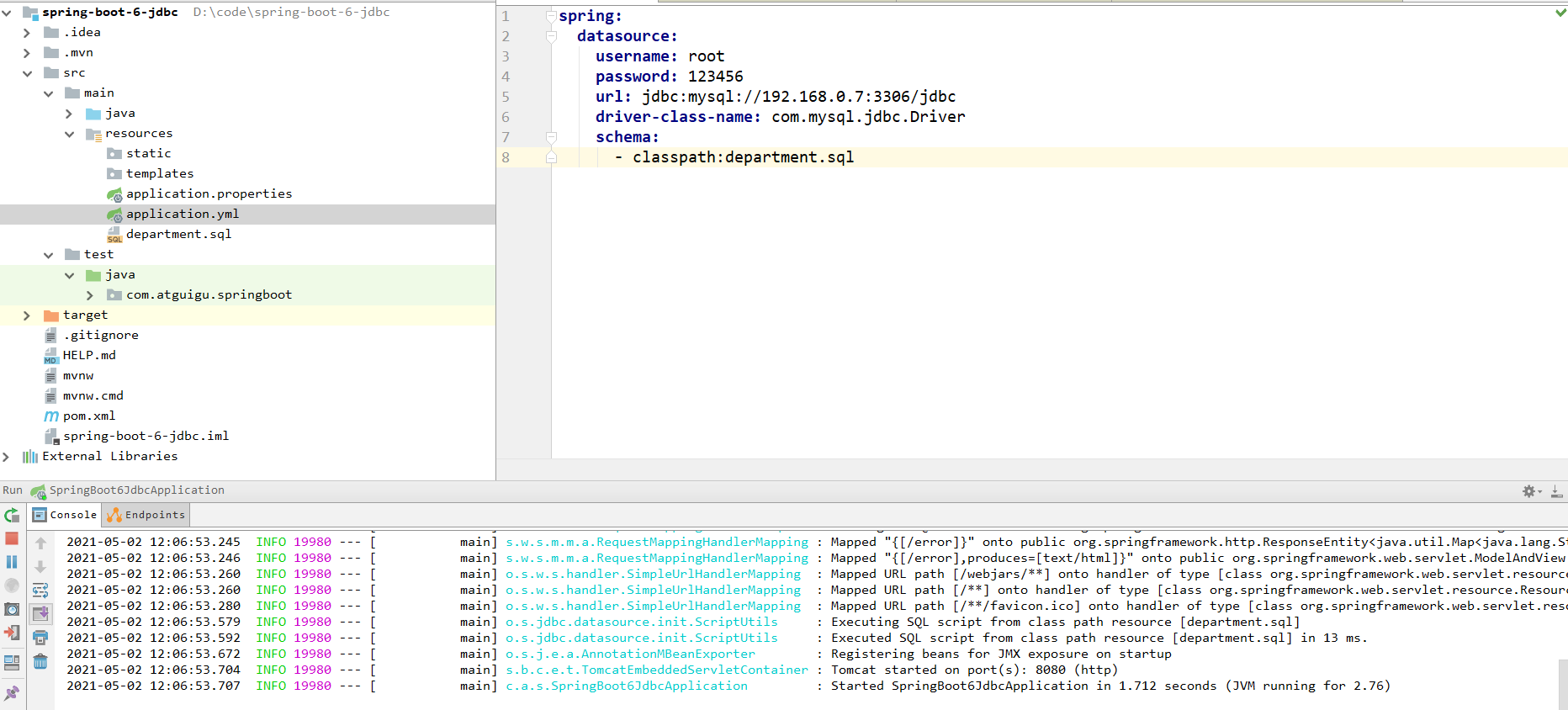
然后,我们就看到数据库当中,已经创建成功了:
可以使用schema:- classpath:department.sql来自定义指定sql文件。
通过上面的演示,可以对DataSourceAutoConfiguration进行一个总结了:
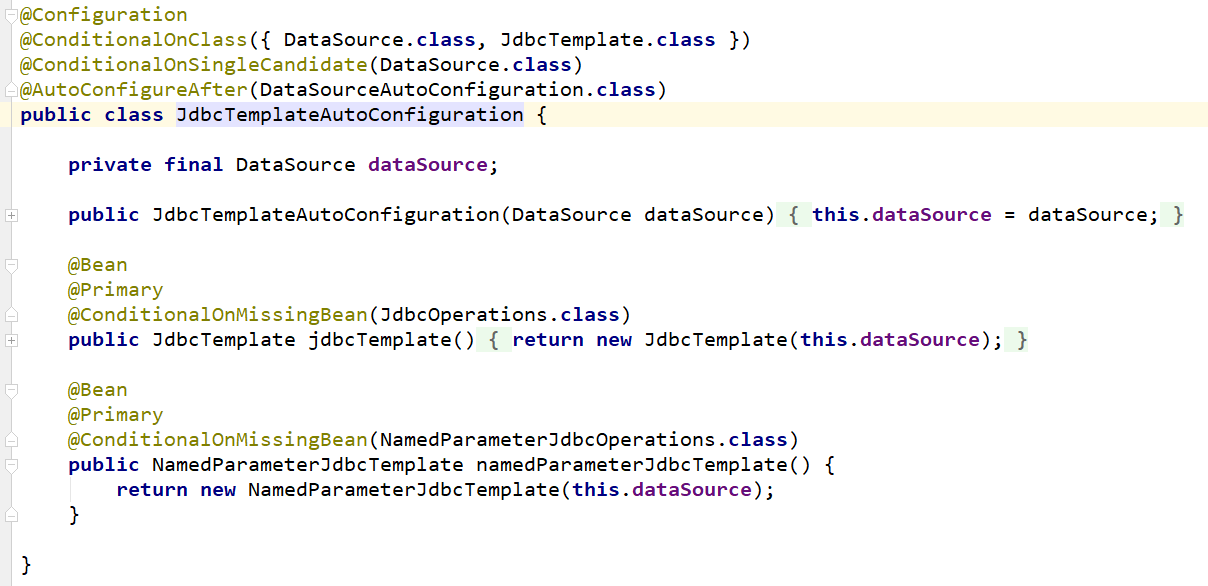
操作数据库 - JdbcTemplateAutoConfiguration
操作数据库的时候,默认有一个自动配置,
自动配置了JdbcTemplate来操作数据库:
写一个简单的方法,来演示一下:
写一个简单的controller,处理一个query请求,然后从数据库当中拿出来一条数据:
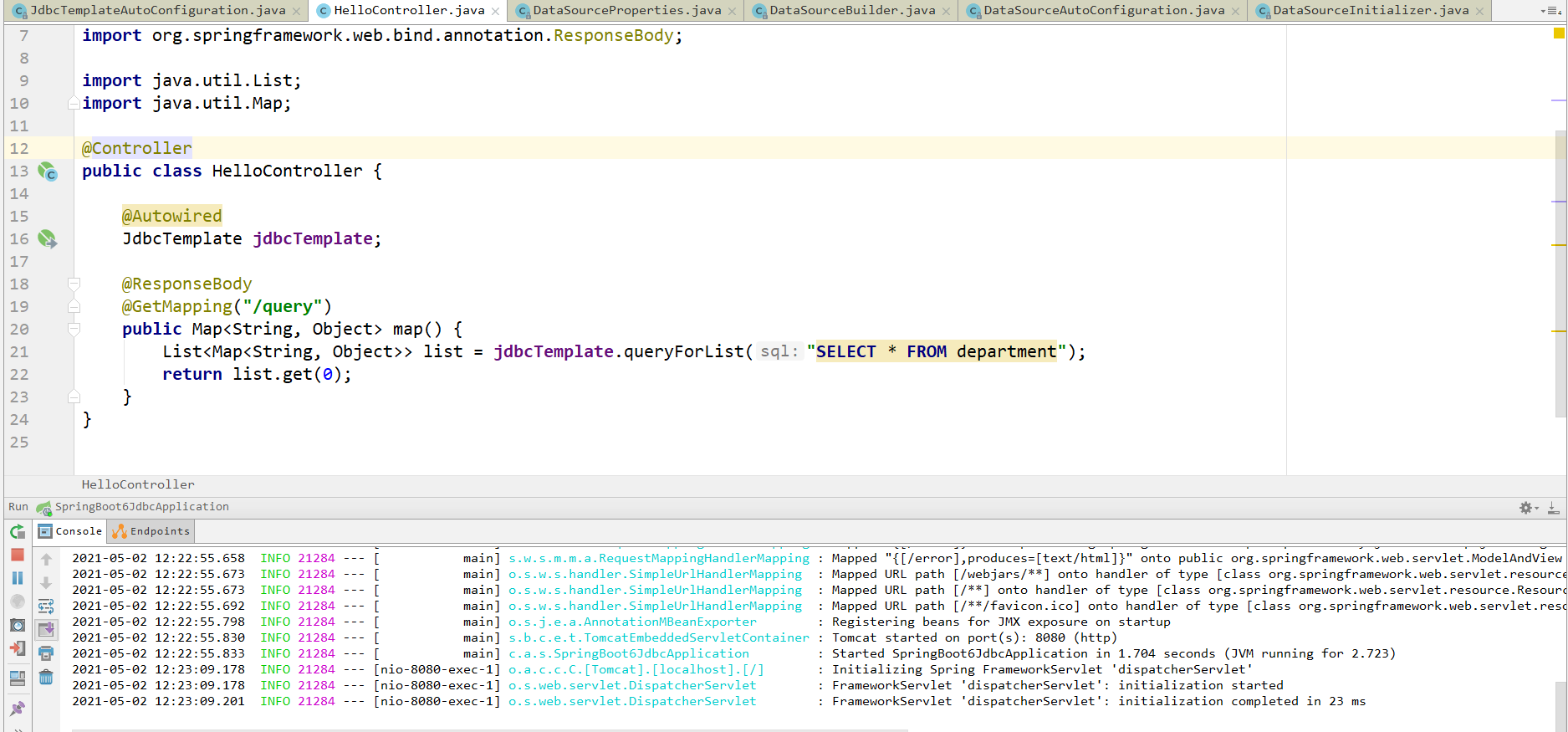
已经提前在数据库当中插入了一条数据:
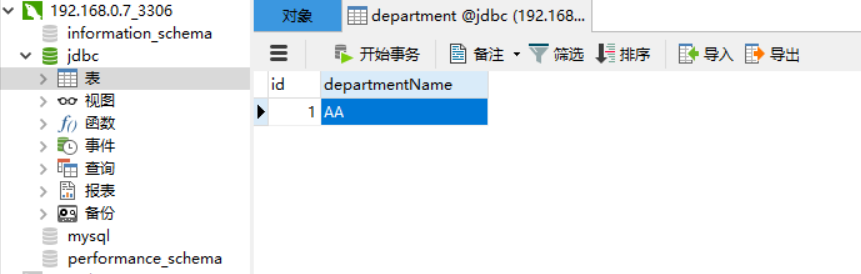
测试的结果是非常完美的,成功的:
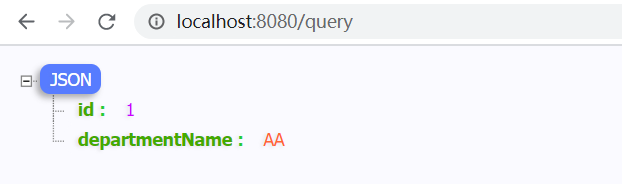
韫秋真的是好棒的哦!
第五步:整合Druid
前面我们测试了基本的JDBC,我们看到springboot底层默认是使用tomcat的数据源。
实际在开发的时候,我们很少会使用tomcat的这个数据源。
我们会使用c3p0,或者是druid,这是阿里的一个数据源产品。
虽然说Hikari数据源,在性能上,比我们的druid要好一点,但是因为druid拥有包含监控、安全全套的解决方案。
所以,我们开发过程中,使用druid是非常多的。
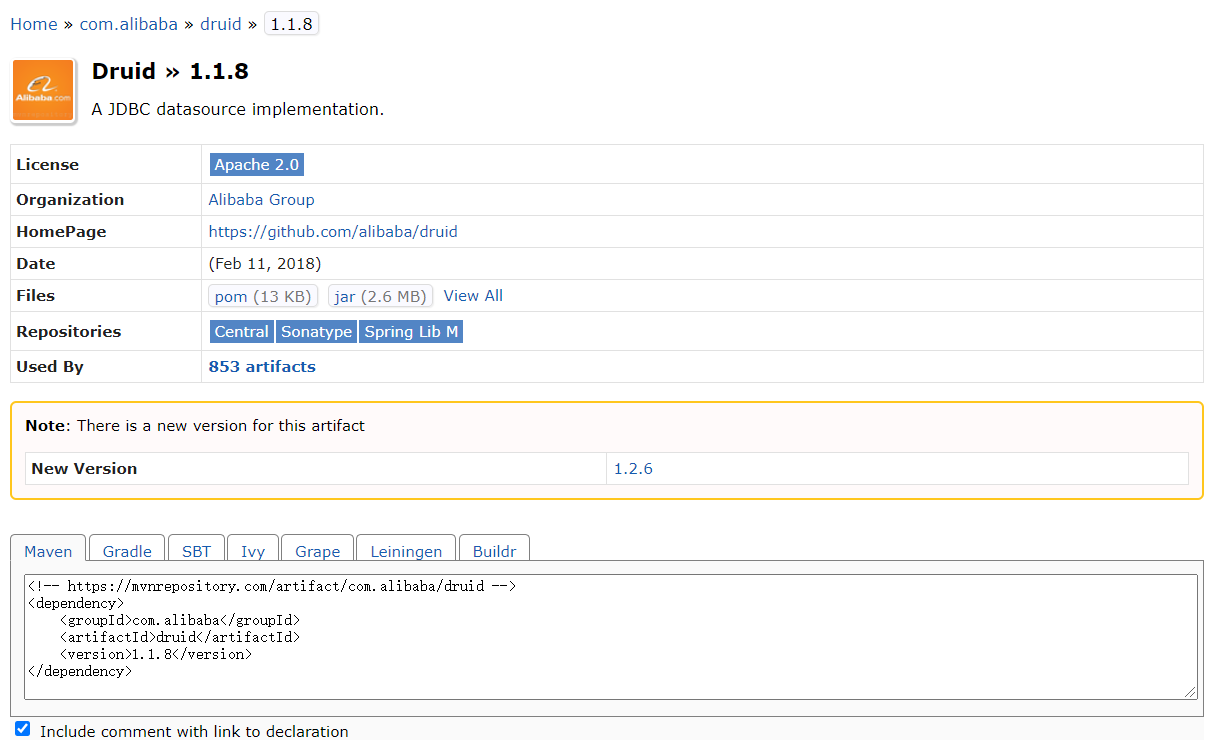
第一,我们应该引入druid数据源。
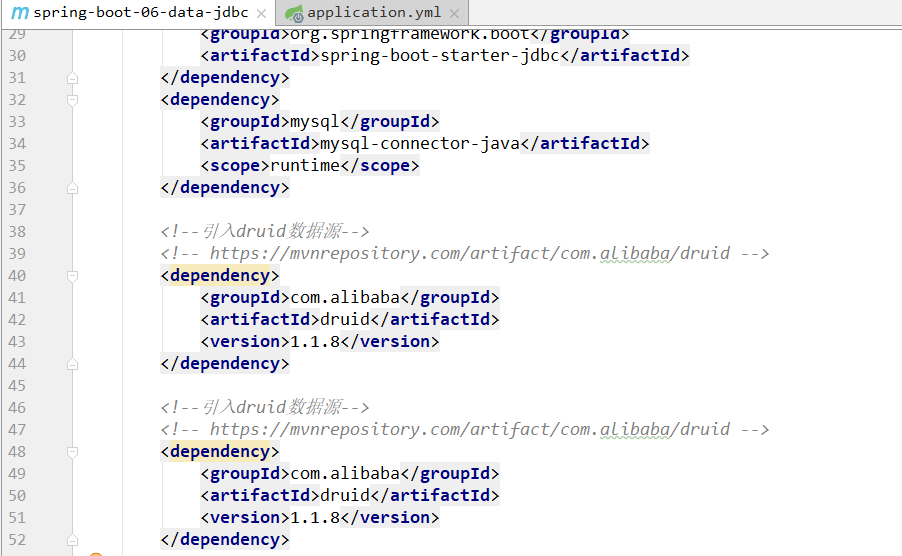
第二,配置文件配置
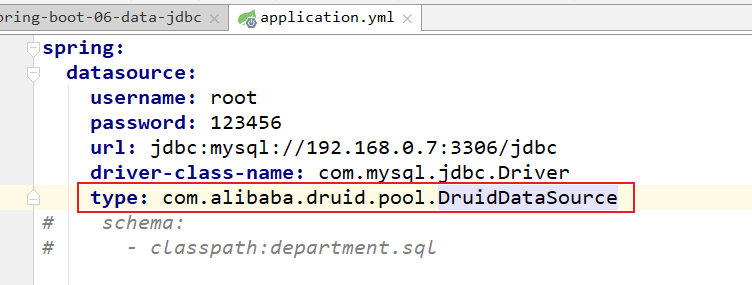
测试一下:
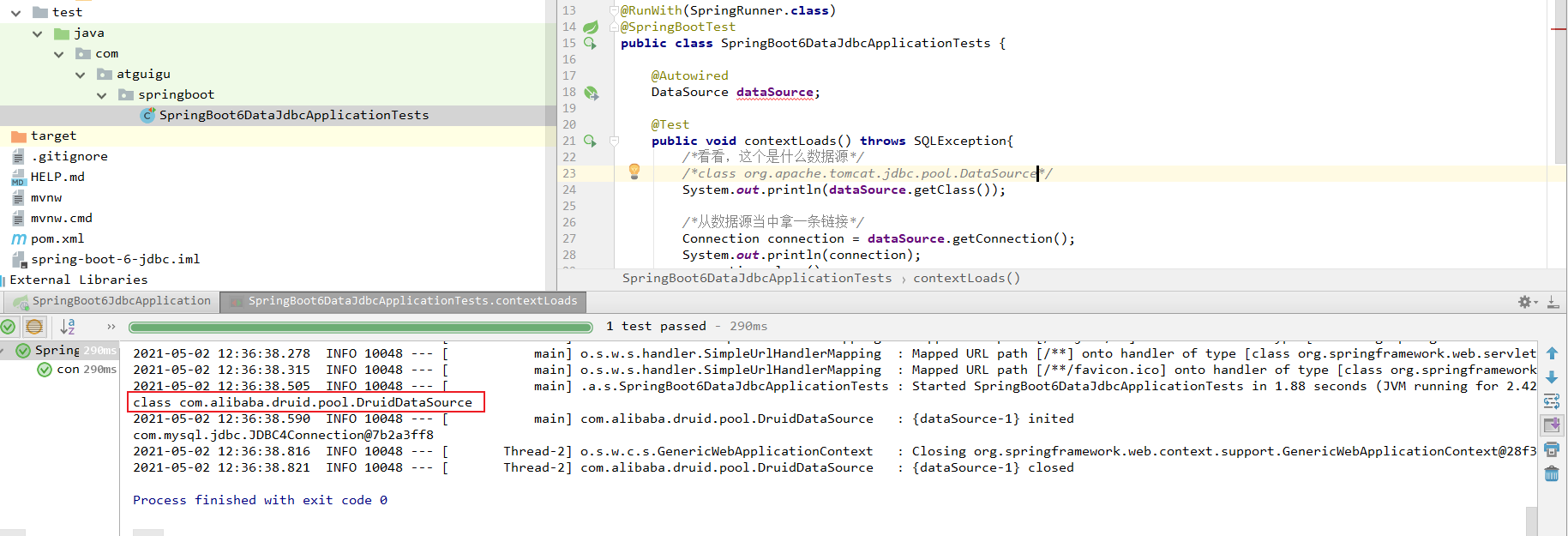
是没有问题的。
第三,数据源设置
druid数据源有很多相关的设置,设置监控,设置数据源连接池大小,等等。
这些东西配置在哪里呢?
还是配置在yaml当中。
spring:
datasource:
# 数据源基本配置
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ssm_crud
type: com.alibaba.druid.pool.DruidDataSource
# 数据源其他配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
我们把其他配置的内容复制,配置到yaml当中的时候,出现了,下面的问题:
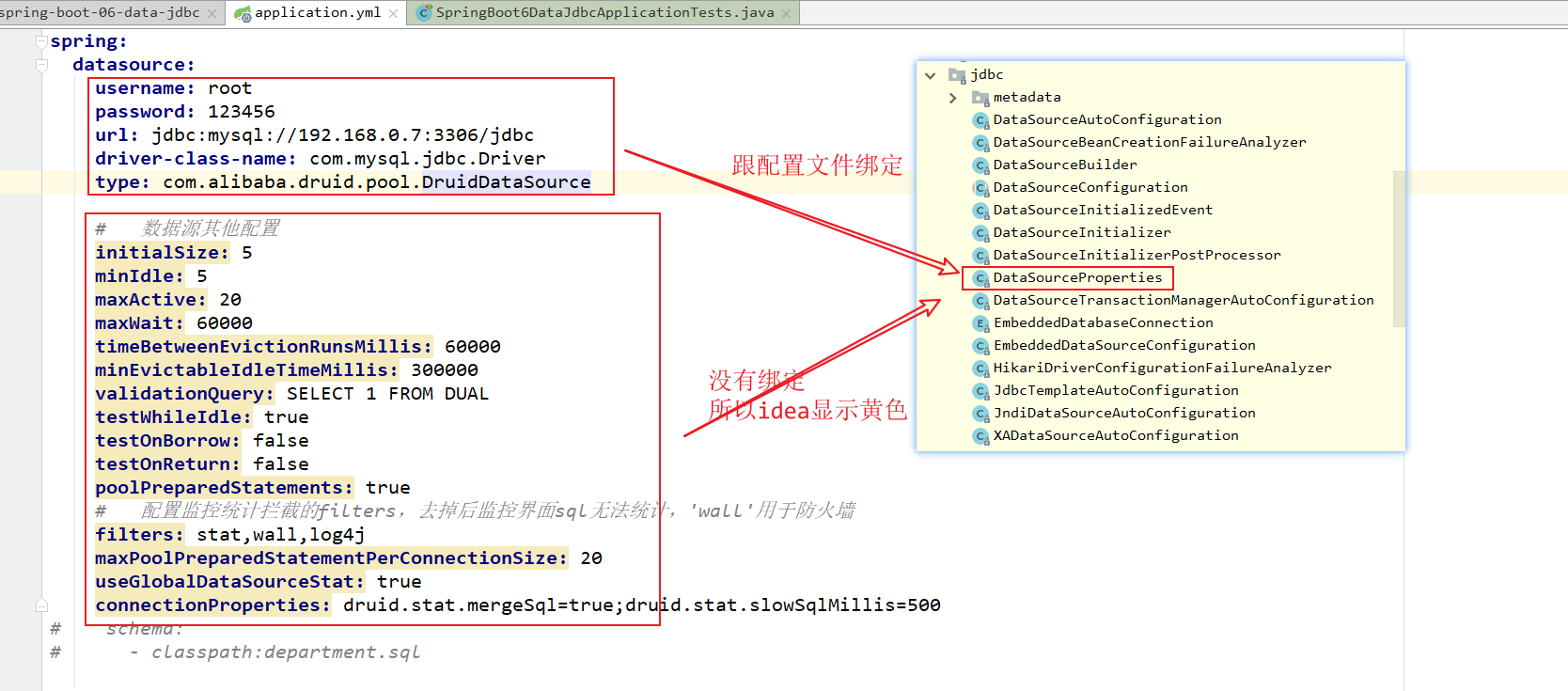
在这个时候,这些黄色的配置的部分,是没有作用的。
我们可以测试一下。
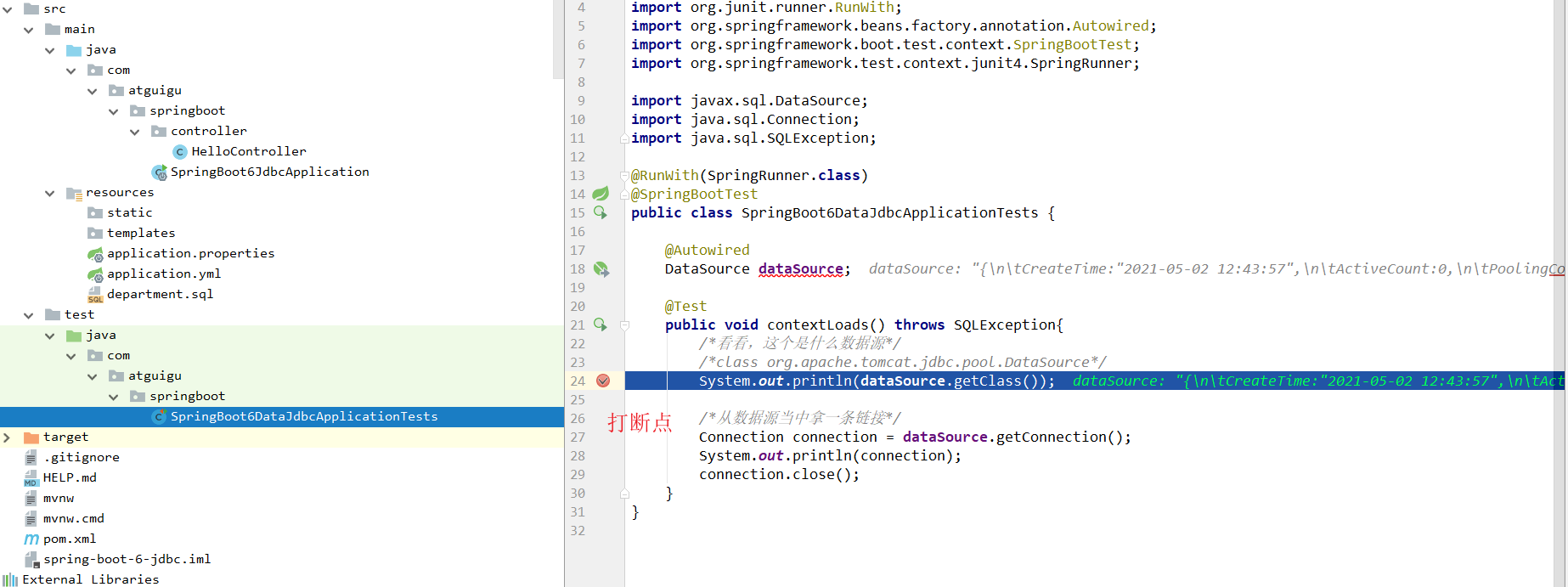
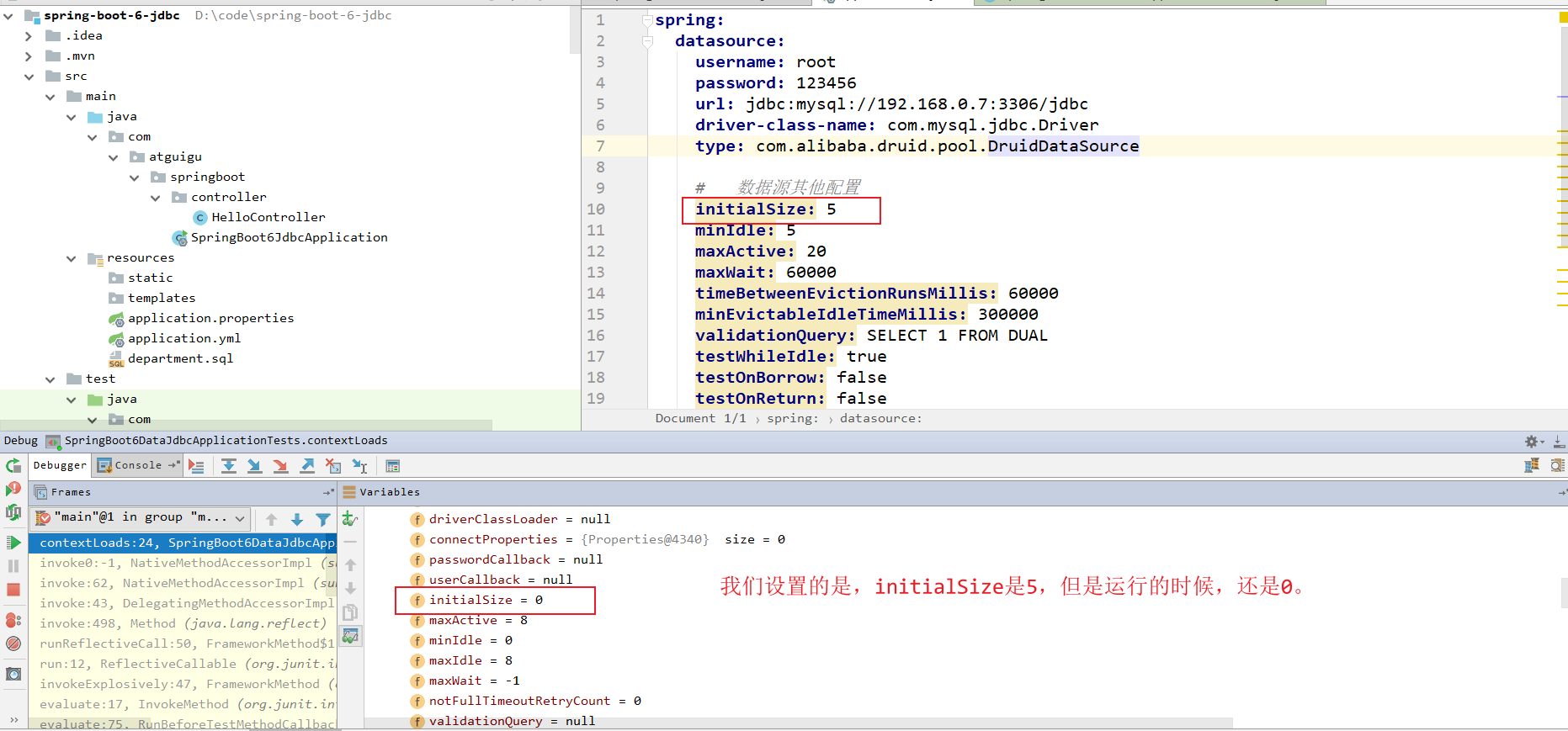
证明是没有生效的。我们的druid的自有配置。
第四,编写druid配置类
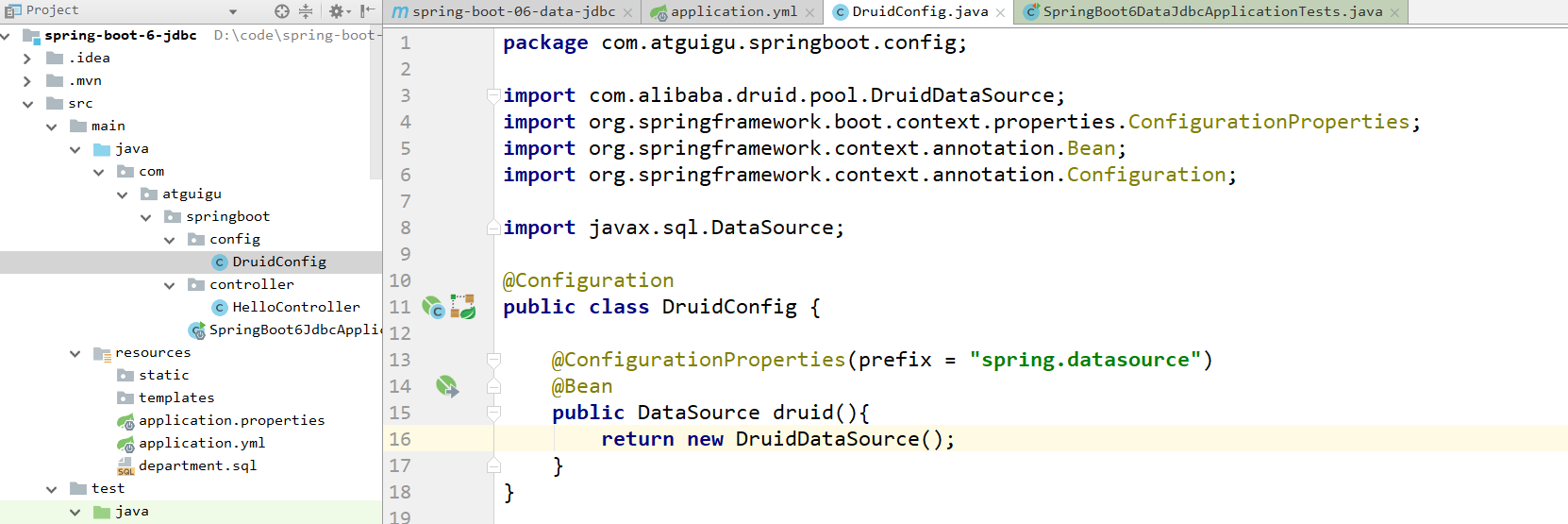
然后再次进行debug测试:
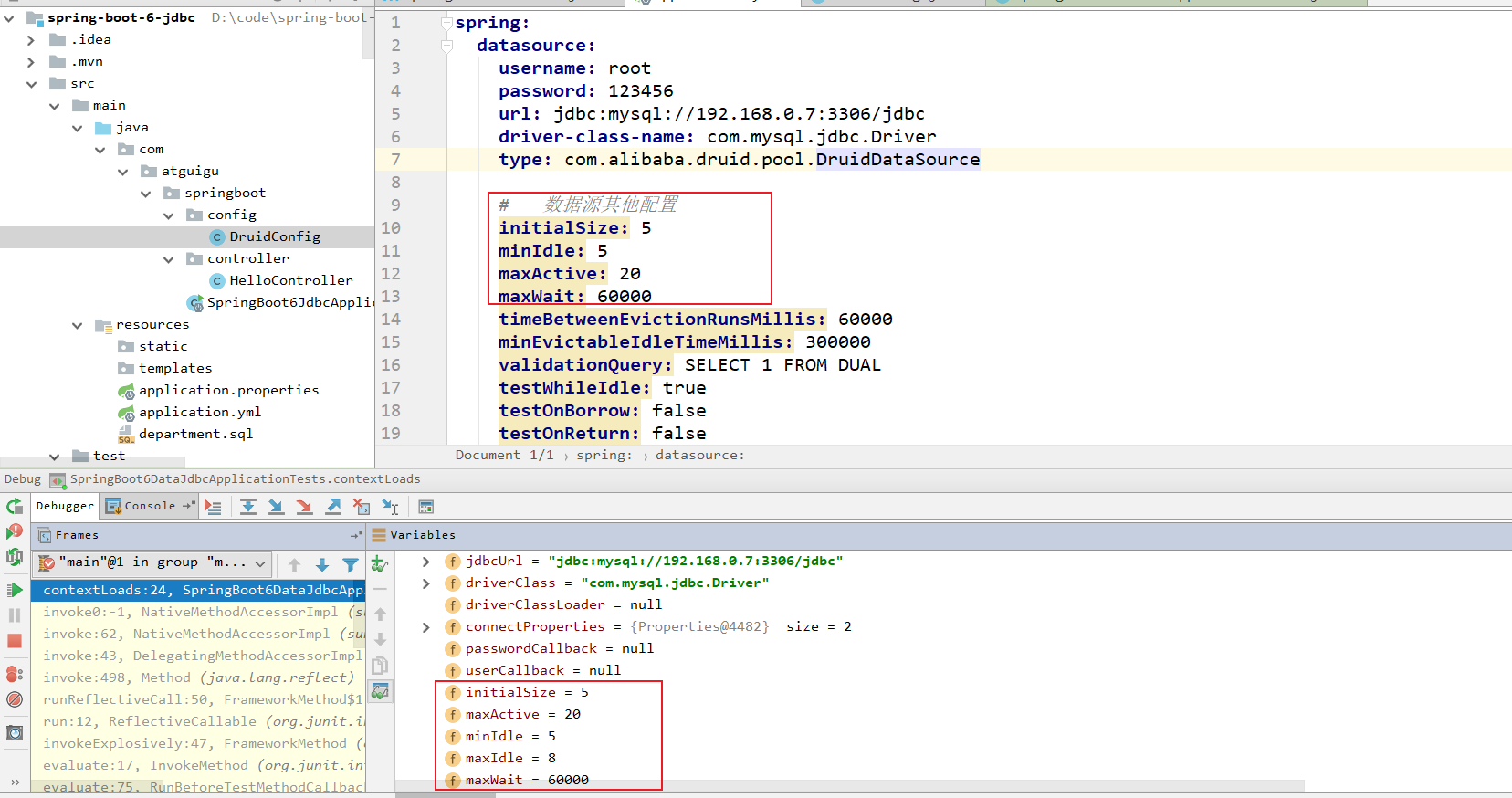
发现已经生效了。
配置druid的监控
那么我们如何配置druid的监控呢?
是需要两个部分的。一个是配置管理后台的servlet的。一个是配置监控的filter的。
package com.atguigu.springboot.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid(){
return new DruidDataSource();
}
//配置Druid监控
//1. 配置一个管理后台的servlet,用来处理进入管理后台的请求
//我们没有web.xml,我们想要注册servlet,我们使用ServletRegistrationBean
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
Map<String,String> initParams = new HashMap<>();
initParams.put("loginUsername","admin");
initParams.put("loginPassword","123456");
initParams.put("allow","localhost");//如果不写,默认就是允许所有进行访问
initParams.put("deny","192.168.15.21");
bean.setInitParameters(initParams);
return bean;
}
//2. 配置一个监控的filter
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String,String> initParams = new HashMap<>();
initParams.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
从上面的代码中,我们要学会,如何在springboot当中注册一个servlet和filter哦。
servlet当中可以配置的信息,都去源码当中找找看啦。


登录druid的后台
登录druid的后台:
后台登录成功后,是下面的样子:
测试一下,发送一个query的请求,去查询一下数据库:
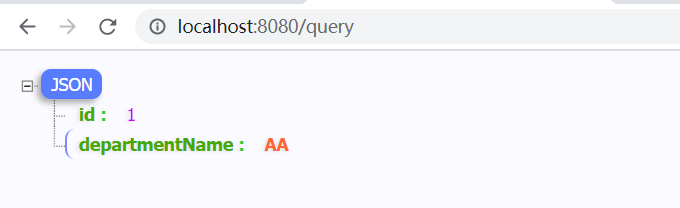
去后台查看一下,SQL监控:
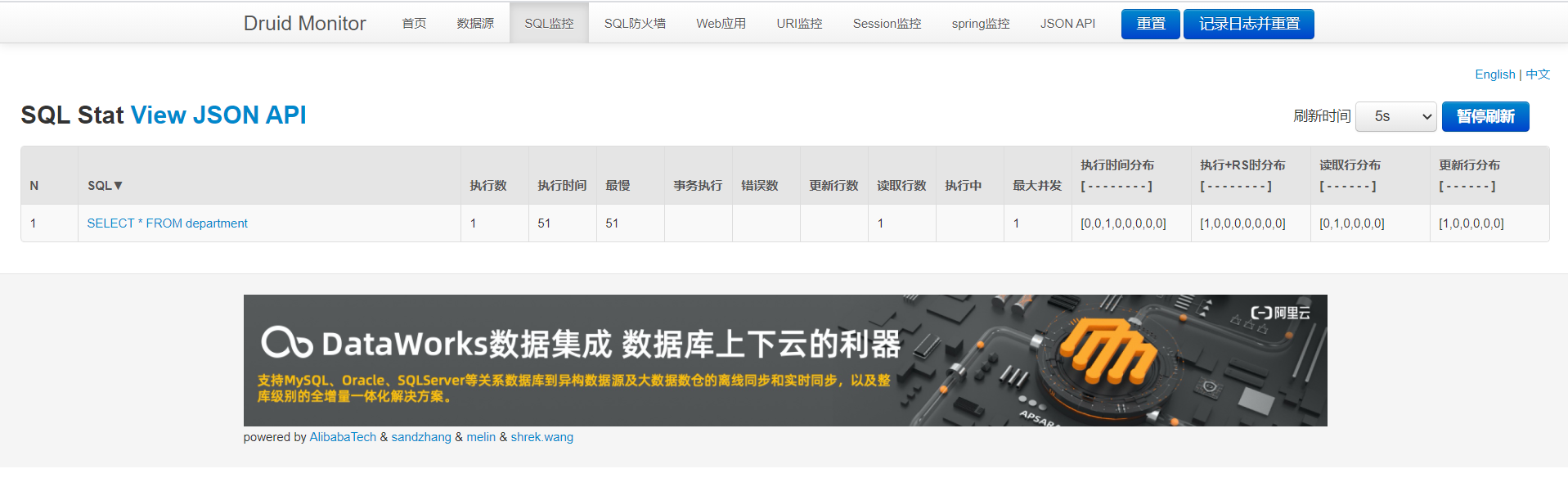
后台查看jdbc执行的次数是:

标签:JDBC,springboot,spring,数据源,配置,druid,雷丰阳,sql,org 来源: https://www.cnblogs.com/gnuzsx/p/14725635.html