数据中心网络:Spine-Leaf 架构设计综述(2016)
作者:互联网
译者序
本文内容翻译自 Cisco 的白皮书 Cisco Data Center Spine-and-Leaf Architecture: Design Overview (2016),翻译非逐字逐句,请酌情参考。
搜索 spine-leaf 资料时看到这篇非常棒的文档,故通过翻译的方式做个笔 记顺便加深理解(不知是否有没有中文版)。本文翻译仅供个人学习交流,无任何商业目 的,如有侵权将及时删除。
另外,发现思科、华为、华三等厂商的官网上都有大量的优秀文档,其最终目的虽然是推介 产品,但其中关于基础设施的内容大部分都是厂商无关的,可以作为很好的学习材料 。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。 优秀的英文技术文档用词都比较简单直接,推荐有需要的读者阅读原文。
以下是译文。
1 数据中心演进
数据中心是现代软件技术的基石,在扩展企业能力的过程中扮演着关键角色。传统的数据中 心使用三层架构(three-tier architecture),根据物理位置将服务器划分为不同 pod, 如图 1 所示。
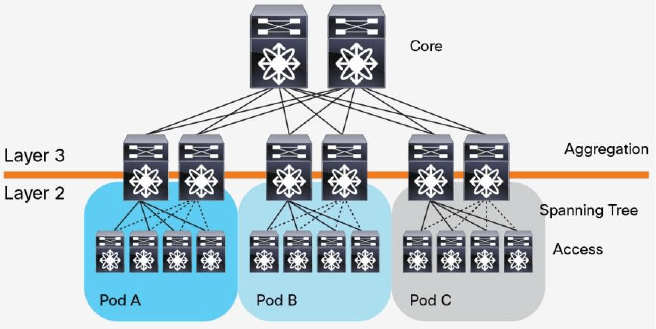
图 1 传统三层(Three-Tier)数据中心设计
这种架构由核心路由器、聚合路由器(有时叫分发路由器,distribution routers )和接入交换机组成。在接入交换机和聚合路由器之间运行生成树协议(Spanning Tree Protocol,STP),以保证网络的二层部分(L2)没有环路。STP 有许多好处:简单, 即插即用(plug-and-play),只需很少配置。每个 pod 内的机器都属于同一个 VLAN, 因此服务器无需修改 IP 地址和网关就可以在 pod 内部任意迁移位置。但是,STP 无法 使用并行转发路径(parallel forwarding path),它永远会禁用 VLAN 内的冗余路径。
2010 年,Cisco 提出了 virtual-port-channel (vPC) 技术来解决 STP 的限制。 vPC 解放了被 STP 禁用的端口,提供接入交换机到汇聚路由器之间的 active-active 上行链路, 充分利用可用的带宽,如图 2 所示。使用 vPC 技术时,STP 会作为备用机制( fail-safe mechanism)。
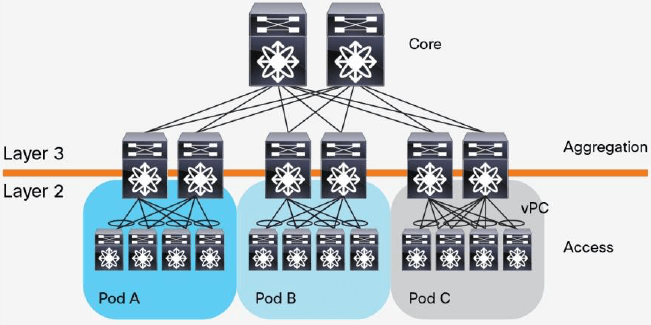
图 2 使用 vPC 技术的数据中心设计
从 2003 年开始,随着虚拟化技术的引入,原来三层(three-tier)数据中心中,在二层( L2)以 pod 形式做了隔离的计算、网络和存储资源,现在都可以被池化(pooled)。这 种革命性的技术产生了从接入层到核心层的大二层域(larger L2 domain)的需求,如 图 3 所示 。
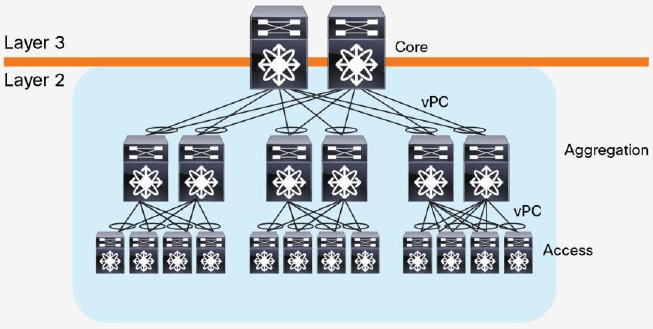
图 3 扩展的 L3 域的数据中心设计
随着 L2 segment(二层网络段,例如 VLAN 划分的二层网络,译者注)被扩展到所有 pod ,数据中心的管理员可以创建一个集中式的、更加灵活的、能够按需分配的资源池。物理服 务器被虚拟化为许多虚拟服务器(VM),无需修改运维参数就可以在物理服务器之间自由漂 移。
虚拟机的引入,使得应用的部署方式越来越分布式,导致东西向流量( east-west-traffic)越来越大。这些流量需要被高效地处理,并且还要保证低的、可预测的延迟。 然而,vPC 只能提供两个并行上行链路,因此三层数据中心架构中的带宽成为了瓶颈。 三层架构的另一个问题是服务器到服务器延迟(server-to-server latency)随着流量路 径的不同而不同。
针对以上问题,提出了一种新的数据中心设计,称作基于 Clos 网络的 Spine-and-Leaf 架 构(Clos network-based Spine-and-Leaf architecture)。事实已经证明,这种架构可 以提供高带宽、低延迟、非阻塞的服务器到服务器连接。
2 Spine-Leaf 架构
图 4 是一个典型的两级 Spine-and-Leaf 拓扑。
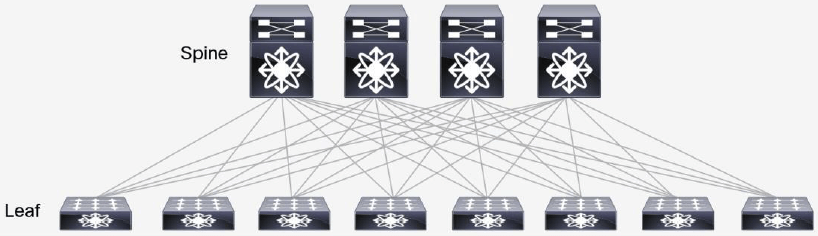
图 4 典型的 Spine-and-Leaf 拓扑
在以上两级 Clos 架构中,每个低层级的交换机(leaf)都会连接到每个高层级的交换机 (spine),形成一个 full-mesh 拓扑。leaf 层由接入交换机组成,用于连接服务器等 设备。spine 层是网络的骨干(backbone),负责将所有的 leaf 连接起来。 fabric 中的每个 leaf 都会连接到每个 spine,如果一个 spine 挂了,数据中心的吞吐性 能只会有轻微的下降(slightly degrade)。
如果某个链路被打满了,扩容过程也很直接:添加一个 spine 交换机就可以扩展每个 leaf 的上行链路,增大了 leaf 和 spine 之间的带宽,缓解了链路被打爆的问题。如果接入层 的端口数量成为了瓶颈,那就直接添加一个新的 leaf,然后将其连接到每个 spine 并做相 应的配置即可。这种易于扩展(ease of expansion)的特性优化了 IT 部门扩展网络的过 程。leaf 层的接入端口和上行链路都没有瓶颈时,这个架构就实现了无阻塞(nonblocking)。
在 Spine-and-Leaf 架构中,任意一个服务器到另一个服务器的连接,都会经过相同数量 的设备(除非这两个服务器在同一 leaf 下面),这保证了延迟是可预测的,因为一个包 只需要经过一个 spine 和另一个 leaf 就可以到达目的端。
3 Overlay 网络
现代虚拟化数据中心的网络要加速应用部署和支持 DevOps,必须满足特定的前提 条件。例如,需要支持扩展转发表、扩展网段、L2 segment extension、虚拟设备漂移(mobility)、转发路径优化、共享物理基础设施上的网络虚拟 化和多租户等等。
虽然 overlay 的概念并不是最近才提出的,但因为它可以解决以上提到的问题,因此近几 年这个概念又火了起来。最近专门针对数据中心提出的新的帧封装格式(encapsulation frame format)更是为这个势头添了一把火。这些格式包括:
- VXLAN:Virtual Extensible LAN
- NVGRE: Network Virtualization Using Generic Routing Encapsulation
- TRILL: Transparent Interconnection of Lots of Links
- LISP: Location/Identifier Separation Protocol
overlay 网络是共享底层网络(underlay network)的节点之间互连形成的虚拟网络,这使 得在不修改底层(underlay)网络的情况下,可以部署对网络拓扑有特定要求的应用,如图 5 所示。
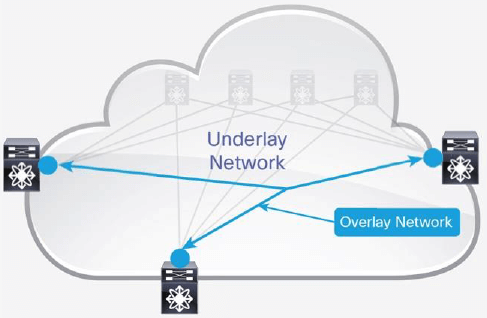
图 5 网络 Overlay 概念
overlay 虚拟化带来的好处包括:
- 优化的设备功能:overlay 网络使得可以根据设备在网络中的位置不同而对设备进行 分类(和定制)。edge 或 leaf 设备可以根据终端状态信息和规模优化它的功能和相关 的协议;core 或 spine 设备可以根据链路状态优化它的功能和协议,以及针对快速收敛 进行优化。
- fabric 的扩展性和灵活性:overlay 技术使得可以在 overlay 边界设备上进行网络 的扩展。当在 fabric 边界使用 overlay 时,spine 或 core 设备就无 需向自己的转发表中添加终端主机的信息(例如,如果在宿主机内进行 overlay 的封 装和解封装,那 overlay 边界就是在宿主机内部,译者注)。
- 可重叠的寻址:数据中心中使用的大部分 overlay 技术都支持虚拟网络 ID,用来唯 一地对每个私有网络进行范围限定和识别(scope and identify)。这种限定使得不同租 户的 MAC 和 IP 地址可以重叠(overlapping)。overlay 的封装使得租户地址空间和 underlay 地址空间的管理分开。
本文档将介绍 Cisco 过去几年和当前提供的、以及不远的将来应该会提供的几种 Spine-and-Leaf 架构设计,这些设计都是为了解决现代虚拟化数据中心中 fabric 面临的 需求:
- Cisco® FabricPath spine-and-leaf network
- Cisco VXLAN flood-and-learn spine-and-leaf network
- Cisco VXLAN Multiprotocol Border Gateway Protocol (MP-BGP) Ethernet Virtual Private Network (EVPN) spine-and-leaf network
- Cisco Massively Scalable Data Center (MSDC) Layer 3 spine-and-leaf network
下面的几章将围绕写作本文时的一些最重要技术组件、通用设计和设计考虑(例如 L3 网关)进行讨论。
最重要的技术组件包括:
- 封装
- end-host 检查和分发(end-host detection and distribution)
- 广播
- 未知单播(unknown unicast)
- 组播流量转发
- underlay 和 overlay 控制平面
- 多租户支持
4 Cicso FabricPath Spine-and-Leaf 网络
Cisco 在 2010 年推出了 FabricPath 技术。FabricPath 提供的新特性和设计选项使得网 络管理员可以创建以太网 fabrics,后者可以提高带宽可用性、提供设计灵活性,以及 简化和降低网络和应用的部署及运维成本。典型的 FabricPath 都是使用 Spine-and-Leaf 架构。
FabricPath 继承了很多传统 L2 和 L3 技术中的优良特性,它保留了 L2 环境易于配置和 即插即用的部署模型,并引入了一个称为 FabricPath IS-IS(Intermediate System to Intermediate System)的控制平面协议。在 FabricPath 网络中,给定任意一个 FabricPath 交换机作为目的端,最短路径优先(shortest path first, SPF)路由协 议将用于判断可达性以及寻找最优路径。
这种设计的好处:
- 更稳定、更易扩展
- 快速收敛
- 像典型的 L3 路由环境一样使用多个并行路径(multiple parallel paths)的能力
4.1 封装格式和标准兼容
FabricPath spine-and-leaf 网络是 Cisco 的专利,但基于 TRILL 标准。它使用 FabricPath MAC-in-MAC 帧封装。
4.1.1 Underlay 网络
数据平面使用 L2 FabricPath MAC-in-MAC 封装,控制面在 underlay 网络中使用 FabricPath IS-IS。每个 FabricPath 交换机都有一个 FabricPath switch ID。Fabric IS-IS 控制平面构建可达性信息(reachability information),即 FabricPath 交换机 如何连接到其它 FabricPath 交换机。
4.1.2 Overlay 网络
FabricPath 没有 overlay 控制平面。overlay 网络中的 end-host 信息是通过带会话学 习功能的“泛洪-学习”机制学习的(flood-and-learn mechanism with conversational learning)。
4.2 广播和未知单播流量
4.3 主机检测和可达性
4.4 组播流量
4.5 L3 路由功能
4.5.1 在 Spine 层做内部和外部路由
4.5.2 在 Border Leaf 做内部和外部路由
4.6 多租户
4.7 总结
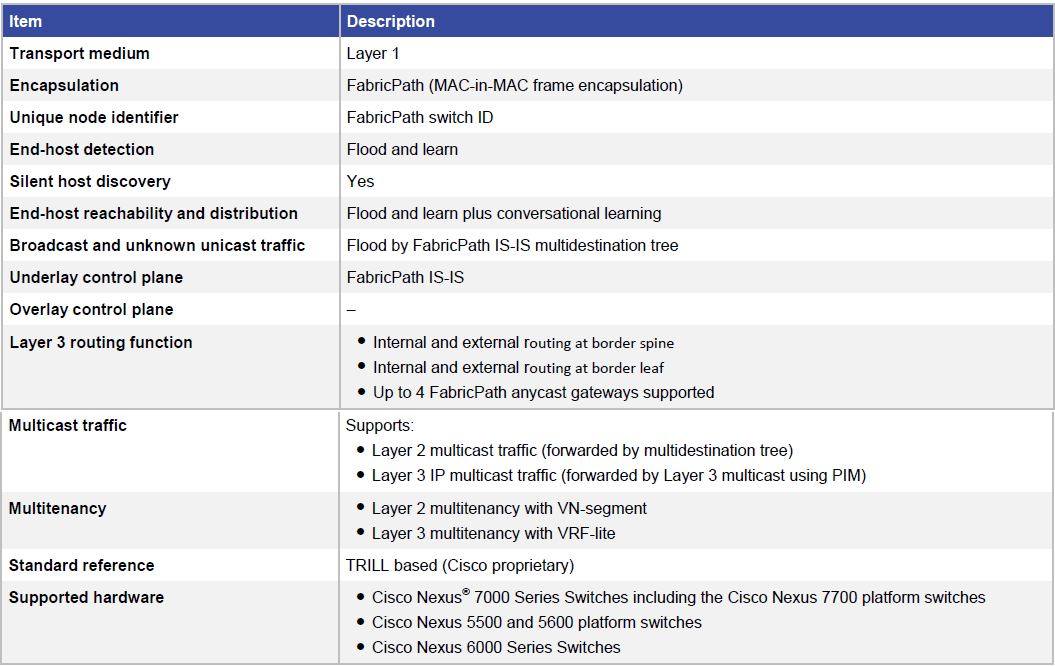
表 1 Cisco FabricPath 网络特性
5 Cicso VXLAN Flood-and-Learn Spine-Leaf 网络
VXLAN 是网络虚拟化 overlay 技术之一,有一些自己的优势。它是一个工业标准( industry-standard)协议,使用 underlay IP 网络。它将 L2 网络进行扩展,在 L3 基础设施之上构建出一个 L2 overlay 逻辑网络。它将以太帧封装到 UDP IP 包里面,通 过 underlay 网络以正常的 IP 路由和转发机制发送到对端 VTEP(VXLAN tunnel endpoint )。
Cisco 从 2014 年开始,陆续在多个 Nexus 系列(例如 Nexus 5600、7000、9000 系列)交 换机上支持 VXLAN flood-and-learn spine-and-leaf 技术。本节介绍这些硬件交换机 的 Cisco VXLAN flood-and-learn 特性。
5.1 封装格式和标准兼容
Cisco VXLAN flood-and-learn 技术兼容 IETF VXLAN 标准(RFC 7348),后者定义了无控 制平面的基于组播的泛洪-学习 VXLAN(multicast-based flood-and-learn VXLAN without a control plane)。原始的 L2 帧封装一个 VXLAN 头,然后放到 UDP IP 包通过 IP 网络 进行传输。
5.1.1 Underlay 网络
使用 L3 IP 网络作为 underlay 网络。
使用 underlay IP multicast 减少 VXLAN 网段的主机之间泛洪的范围。
每个 VXLAN segment 都有一个 VNI(VXLAN network ID),VNI 会映射到传输网络中的一 个 IP 多播组。每个 VTEP 设备独立配置多播组,参与 PIM 路由。基于参与的 VTEP 的位 置,会在传输网络中形成这个组对应的多播分发树(multicast distribution tree)。
这种方案需要在 underlay 网络中开启多播功能,而一些企业可能 并不想在他们的数据中心或 WAN 中开启组播。
Cisco 9000 特色介绍:略(TODO)。
5.1.2 Overlay 网络
这种设计没有 overlay 网络的控制平面。
它在 L3 IP underlay 网络之上构建了一层 L2 overlay 网络,通过 VTEP 隧道机制传输 L2 包。overlay 网络使用 flood-and-learn 语义,如图 11 所示。
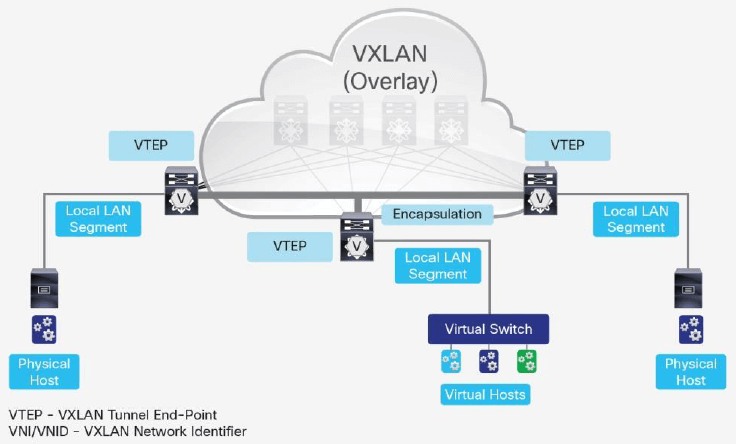
图 11 VXLAN overlay 网络
5.2 广播和未知单播流量
使用 underlay IP PIM 或 ingress replication 发送广播和未知的单播(unknown unicast)流量。注意 ingress replication 只有 Cisco Nexus 9000 系列交换机才支持。
5.3 主机检测和可达性
依赖初始的数据平面泛洪,每个 VXLAN segment 的 VTEP 能发现其他主机,学习远端主机 的 MAC 和 MAC-to-VTEP 映射。MAC-to-VTEP 映射完成后,VTEP 接下来就通过单播转发 VXLAN 流量。
5.4 组播流量
通过 underlay IP PIM 或 ingress replication 可以支持 overlay 租户的 L2 组播。
L3 组播流量通过 L3 基于 PIM 的组播路由(L3 PIM-based multicast routing)实现。
略。
5.5 L3 路由功能
在一个传统的 VLAN 环境中,很多情况下需要 VXLAN segment 和 VLAN segment 之间的路由。 典型的 VXLAN flood-and-learn spine-and-leaf 网络设计中,leaf ToR (top-of-rack) 交换机会作为 VTEP 设备,在机柜(rack)之间扩展 L2 segment。
VXLAN 和 VLAN 之间的 二层流量转发时,VTEP 作为 L2 VXLAN 网关;三层流量路 由时,还需要开启某些 VTEP 的 L3 VXLAN 网关功能。常见的设计有:内部和外部路由在 spine 层,或内部和外部路由在 leaf 层。这两种设计都是集中式路由(centralized routing),即:三层的内部和外部路由功能都集中在特定的交换机上做。
5.5.1 在 Spine 层做内部和外部路由
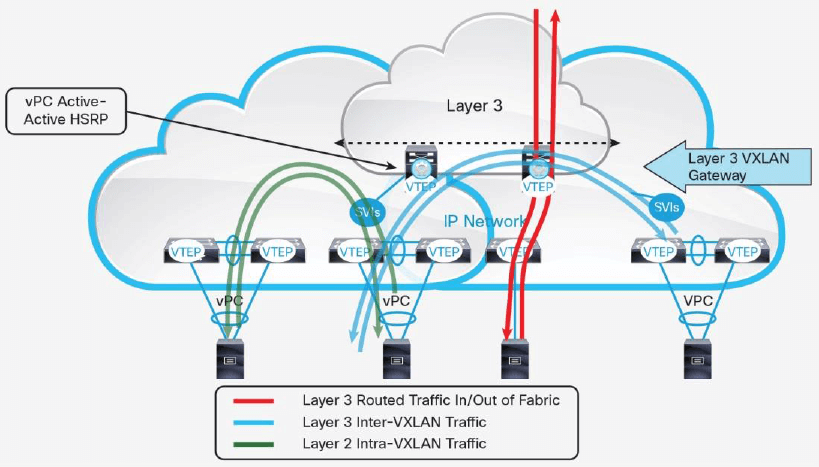
图 12 在 spine 上做内部和外部路由
图 12 是在 spine 层做内部和外部路由的示意图,leaf ToR VTEP 交换机作为 L2 VXLAN 网关,在 underlay 网络上传输 L2 segment。spine 有两功能:
- 作为 underlay 网络的一部分,传输 VXLAN 封装的包
- 做内部的 inter-VXLAN 路由,以及外部路由
内部和外部路由流量需要从 VTEP 经过 underlay 的一跳到达 spine,然后被 spine 路由。
注意,在使用 HSRP(Hot-Standby Router Protocol)和 vPC 的配置下,VXLAN 之间 active-active 网关的最大数量是两个。另外,spine L3 VXLAN 网关会学习主机 MAC 地址,所以需要考虑 MAC 地址的规模,以免超出硬件的限制。
5.5.2 在 Border Leaf 做内部和外部路由
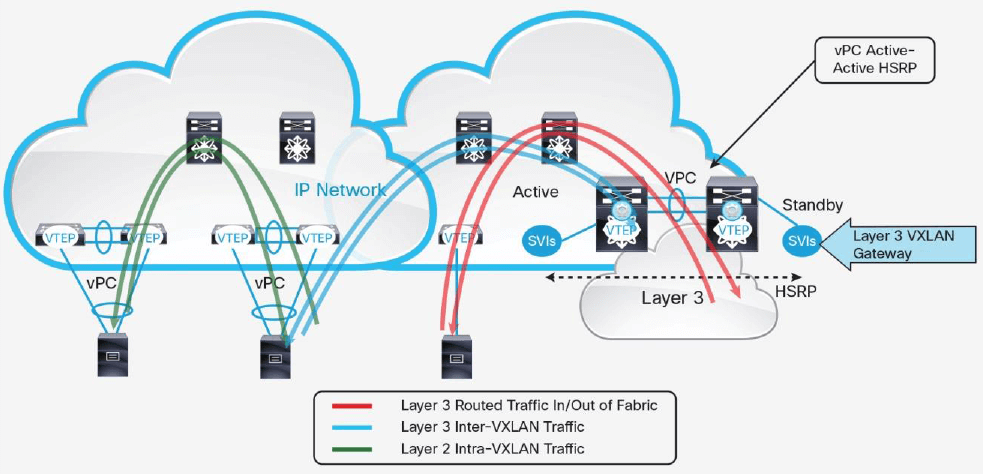
图 13 在 Border Leaf 上做内部和外部路由
在 Border Leaf 上做内部和外部路由如图 13。
leaf ToR VTEP 交换机作为 L2 VXLAN 网关,在 underlay 网络上传输 L2 segment。spine 是 underlay 网络的一部分,它并不学习 overlay 主机的 MAC 地址。border leaf 路由器 承担 L3 VXLAN 网关功能,负责 inter-VXLAN 路由和外部路由。
内部和外部路由流量需要从 VTEP 经过 underlay 的两跳(先到 spine 再到 border leaf)到达 border leaf,然后才能被路由到外部网络。
同样,在使用 HSRP 和 vPC 的配置下,inter-VXLAN active-active 网关的最大数量是两 个。另外,border leaf L3 VXLAN 网关会学习主机 MAC 地址,所以需要考虑 MAC 地 址的规模,以免超出硬件的限制。
5.6 多租户
5.7 总结
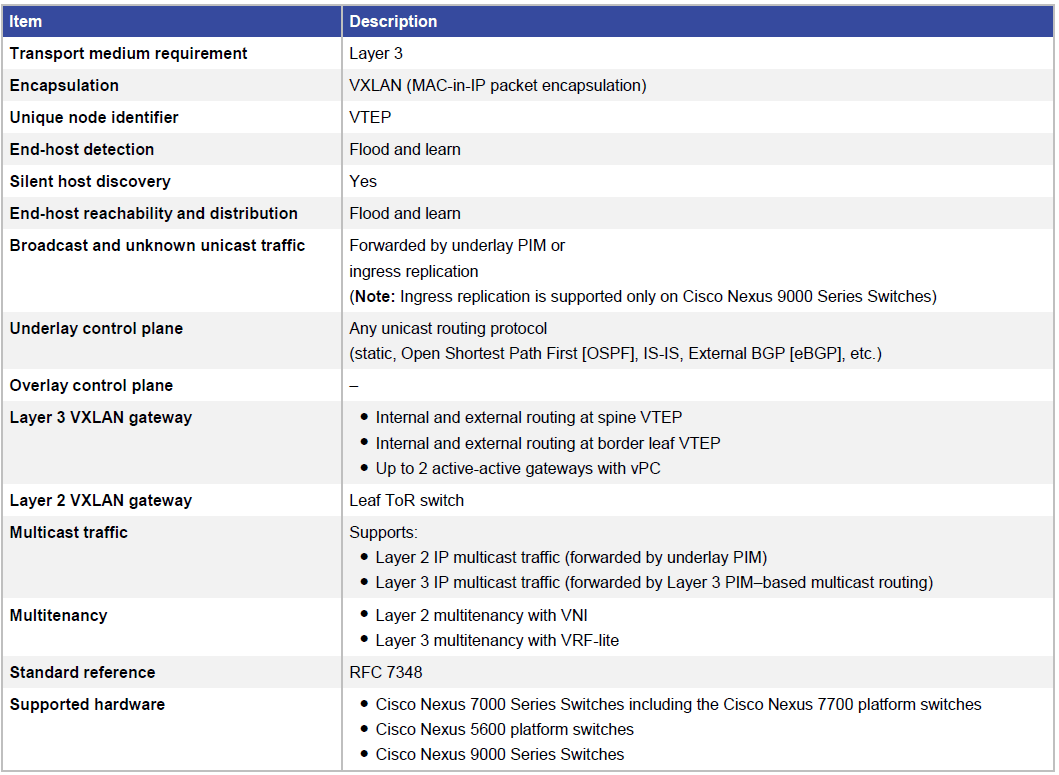
表 2 Cisco VXLAN flood-and-learn 网络特性
6 Cicso VXLAN MP-BGP EVPN Spine-Leaf 网络
RFC 7348 定义的 VXLAN flood-and-learn 模型中,end-host(终端主机)学习和 VTEP 发现都是基于数据平面,并没有控制平面来在 VTEP 之间分发 end-host 可达性 信息。为了克服这种方案的一些限制,Cisco VXLAN MP-BGP EVPN Spine-and-Leaf 架构使 用了 MP-BGP EVPN 作为 VXLAN 的控制平面。
这种设计使得控制平面和数据平面分离,并且为 overlay 网络的 L2/L3 转发提供了统 一的控制平面。本节介绍这种方案中 Cisco 硬件交换机(例如 Cisco Nexus 5600 、7000、9000 系列)上的应用。
6.1 封装格式和标准兼容
使用 VXLAN 封装,原始 L2 帧加一层 VXLAN 头然后封装到 UDP-IP 包进行传输。
与 IETF RFC 7348 和 draft-ietf-bess-evpn-overlay 标准是兼容的。
6.1.1 Underlay 网络
使用 L3 IP 网络作为 underlay 网络。
6.1.2 Overlay 网络
使用 MP-BGP EVPN 作为 VXLAN overlay 网络的控制平面协议。
6.2 广播和未知单播流量
使用 underlay IP PIM 或 ingress replication 特性发送广播和未知单播流量。
underlay 开启 IP 组播的情况下,每个 VXLAN segment,或者 VNI,都会映射到 underlay 的一个 IP 组播组(multicast group)。每个 VTEP 设备独立配置组播组,参与 PIM 路由 。基于参与的 VTEP 的位置,会在传输网络中形成这个组对应的多播分发树(multicast distribution tree)。
如果使用 ingress replication 特性,那 underlay 就无需组播了。VTEP 之间通过 VTEP 的 IP 地址发送广播和未知单播流量。这些 IP 地址是通过 BGP EVPN 控制平面在 VTEP 之 间交换的,或者通过静态配置。
6.3 主机检测和可达性
MP-BGP EVPN 控制平面提供内置的路由和转发(功能),它会对 VXLAN overlay 网络内的 end-host 的 L2/L3 可达性信息进行分发(distribution)。
每个 VTEP 从与它相连的主机中自动学习 MAC 地址(通过传统的 MAC 地址学习)和 IP 地址信息(基于 ARP snooping),然后通过控制平面进行分发,因此远端主机的信息是 控制平面同步过来的。这种方式避免了通过网络泛洪学习远端主机信息的问题,为 end-host 可达性信息的分发提供了更好的控制。
6.4 组播流量
使用 underlay IP 组播或 ingress replication 特性,可以支持 overlay 租户的 L2 组 播。
通过外部路由器上 L3 PIM-based multicast 路由,可以支持 overlay 租户的 L3 组播。
6.5 L3 路由功能
L3 路由需要解决两个问题:
- VXLAN 网络内部的路由:使用分布式任播网关(distributed anycast gateways)解决
- VXLAN 网络和外部网络(包括园区网、WAN 和互联网)的路由:在几个特定交换机上实现
6.5.1 分布式任播网关:解决 VXLAN 网络内部路由
在 MP-BGP EVPN 网络中,一个 VNI 内的任意一个 VTEP 都可以作为它所在子网的分布式 任播网关,对它们配置相同的虚拟网关 IP 和虚拟网关 MAC 即可,如图 16 所示。
EVPN 的这种任播网关功能,使得 VNI 内的主机可以将本地 VTEP 作为其网关,将跨网段的 流量发送到 VTEP 设备。这使得 VXLAN 网络中从主机出来的北向流量可以达到最优转发。 分布式任播网关还给 overlay 网络带来了透明主机漂移(transparent host mobility)的 好处。因为一个 VNI 的所有 VTEP 设备上的网关 IP 和 MAC 地址都是相同的,当一个主机 从一个 VTEP 移动到另一个 VTEP 后,它无需发送 ARP 请求来重新学习网关的 MAC 地址。
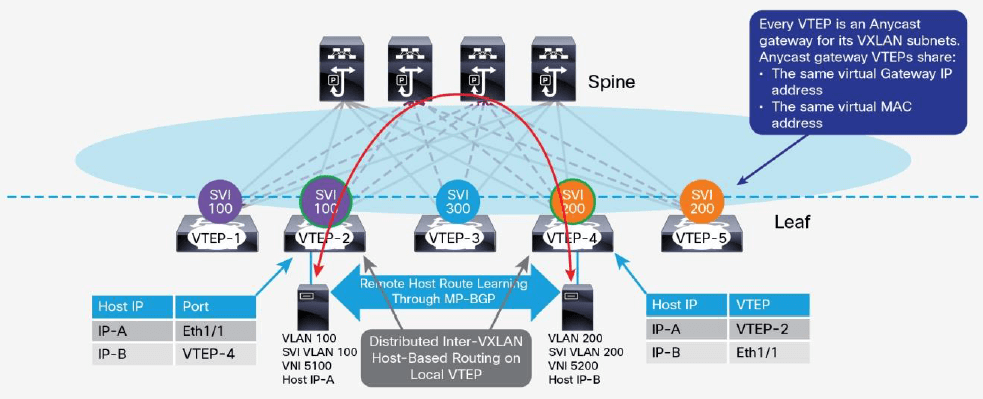
图 16 内部路由的分布式任播网关
6.5.2 在 Border Leaf 做外部路由
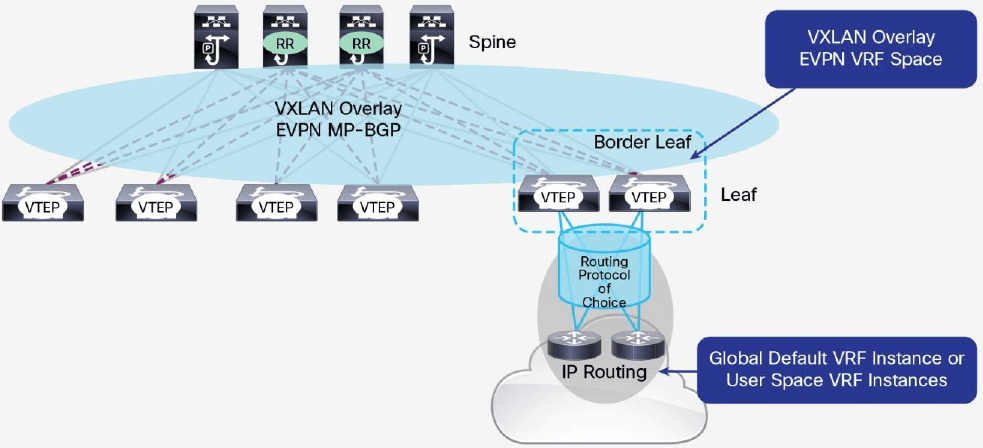
图 17 Border Leaf 做外部路由的设计
图 17 是典型的通过一对 border leaf 交换机连接到外部路由设备的设计。Border leaf 在 VXLAN 网络侧运行 MP-BGP EVPN,和网络内的 VTEP 交换 EVPN 路由。同时,它在租户 VRF 实例中运行普通的 IPv4 或 IPv6 单播路由协议和外部路由设备交换路由信息。路由协 议可以是常规 eBGP,或任何内部网关协议(IGP)。Border leaf 将学习来的外部路由 以 EVPN 路由的形式通告到 EVPN 域,因此 VTEP 就能学习到外部路由,然后就可以发送出 VXLAN 网络的流量。
也可以配置 border leaf 将学习到的 L2 VPN EVPN 地址族到 IPv4 或 IPv6 单播地址族的 路由,通告到外部路由。在这种设计中,租户流量需要经过 underlay 的两跳(VTEP 到 spine 到 border leaf)到达外部网络。然而,这种情况下 spine 只需要运行 BGP-EVPN 控 制平面和 IP 路由,无需支持 VXLAN VTEP 功能(即,无需支持 VXLAN 的封装和解封装, 译者注)。
6.5.3 在 Border Spine 做外部路由
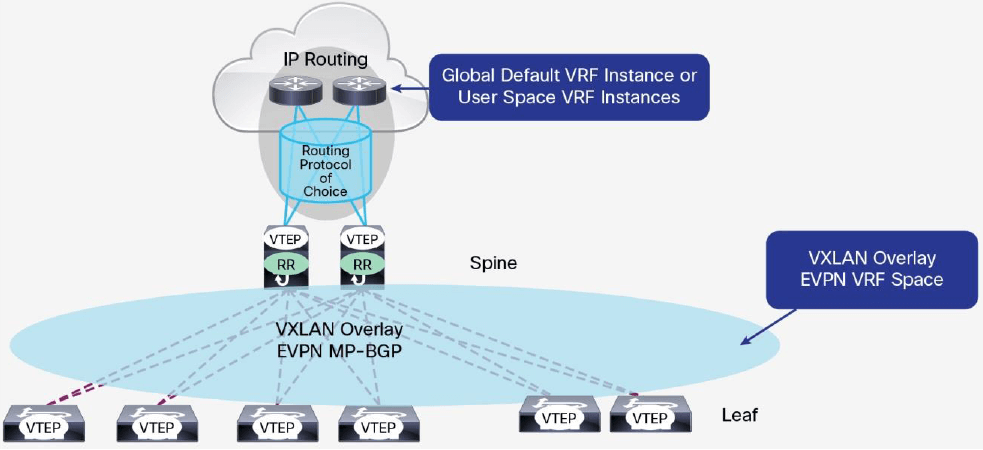
图 18 Border Spine 做外部路由的设计
图 18 是典型的通过一对 border spine 交换机连接到外部路由设备的设计。这种设计中, spine 需要支持 VXLAN 路由。spine 在 VXLAN 网络侧运行 MP-BGP EVPN,和 VTEP 交换 EVPN 路由信息。同时,它在租户 VRF 实例中运行普通的 IPv4 或 IPv6 单播路由协议和外部路由设备交换路由信息。路由协 议可以是常规 eBGP,或任何内部网关协议(IGP)协议。spine 将学习来的外部路由 以 EVPN 路由的形式通告到 EVPN 域,因此 VTEP 就能学习到外部路由,然后就可以发送出 VXLAN 网络的流量。
也可以配置 spine 将学习到的 L2 VPN EVPN 地址族到 IPv4 或 IPv6 单播地址族的 路由,通告到外部路由。在这种设计中,租户流量只需经过 underlay 的一跳(VTEP 到 spine)就可以到达外部网络。然而,这种情况下 spine 需要运行 BGP-EVPN 控制平面和 IP 路由,以及支持 VXLAN VTEP 功能。
6.6 多租户
作为 MP-BGP 的扩展,MP-BGP EVPN 继承了 VPN 通过 VRF 实现的对多租户的支持。
在 MP-BGP EVPN 中,多个租户可以共存,它们共享同一个 IP 传输网络(underlay),而 在 VXLAN overlay 网络中拥有独立的 VPN,入图 19 所示。
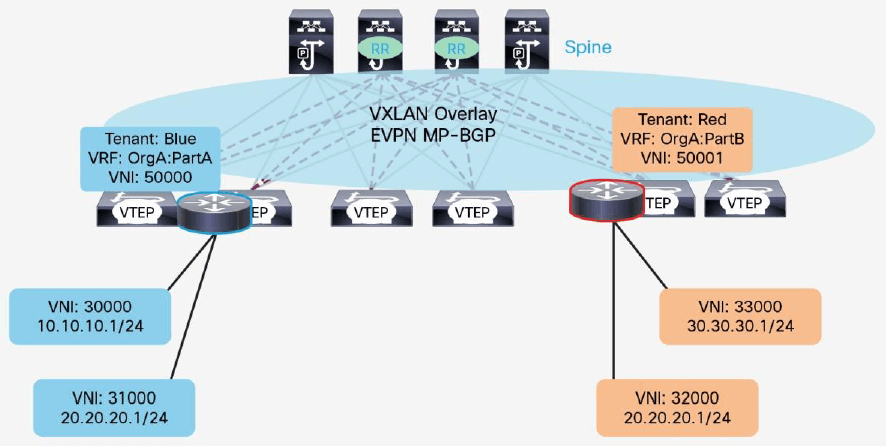
图 19 Cisco VXLAN MP-BGP EVPN Spine-and-Leaf 网络的多租户
在 VXLAN MP-BGP EVPN spine-and-leaf 网络中,VNI 定义了二层域,不允许 L2 流量跨越 VNI 边界。类似地,VXLAN 租户的三层 segment 是通过 VRF 技术隔离的,通过将不同 VNI 映射到不同的 VRF 实例来隔离租户的三层网络。每个租户都有自己的 VRF 路由实例。同一 租户的 VNI 的不同子网,都属于同一个 L3 VRF 实例,这个 VRF 将租户的三层路由与其他 租户的路由隔离开来。
6.7 总结
控制平面学习到 end-host 的 L2 和 L3 可达性信息(MAC 和 IP),然后通过 EVPN 地址 族分发这些信息,因此提供了 VXLAN overlay 网络的桥接和路由功能。这种方案减少了网 络泛洪,以及本地 VTEP 上的 ARP suppression。三层内部流量直接通过 ToR 上的分布式 网关路由,扩展性(scale-out)比较好。
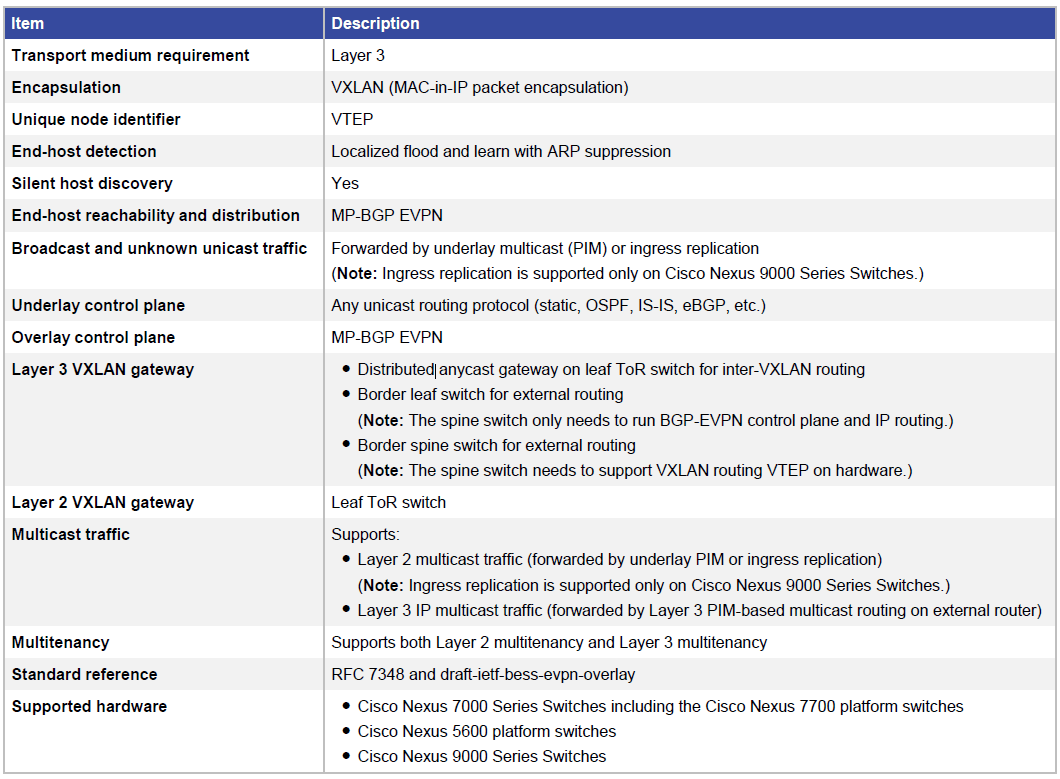
表 3 Cisco VXLAN MP BGP EVPN 网络特性
7 Cicso MSDC Layer 3 Spine-Leaf 网络
8 数据中心 Fabric 管理和自动化
9 总结
10 更多信息
标签:架构设计,Leaf,VTEP,Spine,网络,spine,路由,leaf,VXLAN 来源: https://www.cnblogs.com/heimafeitian/p/14679371.html