05
作者:互联网
无约束优化-----共轭梯度法
1线性共轭梯度法
考虑求解以下线性方程组:
\[Ax = b\tag1 \]其中A是一个n×n矩阵,对称且正定。
该问题可以等效为以下最小化问题:
\[\begin{equation}min~~~ f \left( x \right) = \frac{1}{2} x^TA x - b^T x \tag{2} \end{equation} \]如果对该函数求导,并令导数为零,我们得到
\[\begin{equation} \nabla f \left( x \right) = A x - b = 0 \tag{3} \end{equation} \]于是我们得到,$f \left( x \right) $的极小值点( $A $是正定矩阵,意味着 $\phi \left( x \right) $有极小值)恰好是线性方程 \(Ax=b\) 的解。于是,我们可以把求解(1)的问题转化为求(2)极值的问题。
一组非零向量\(\{ d_{(0)},d_{(1)},\dots,d_{(n-1)}\}\)是共轭的要满足\(d_{(i)} A^Td_{(j)}=0\) ,其中$A $ 是对称正定矩阵
显然,任何共轭向量的集合也是线性无关的。
共轭梯度法:给定\(x_0\),一组共轭方向\(\{ d_{(0)},d_{(1)},\dots,d_{(n-1)}\}\),令
\[x_{(i+1)}=x_{(i)}+\alpha_{(i)}d_{(i)}\tag4 \]\(\alpha_{(i)}\)由最小化\(f(x_{i+1})\),即$min~f(x_{(i)}+\alpha_{(i)}d_{(i)}) $,由无约束优化-----最速下降法和二分线搜索方法中的分析,得出
\[\alpha_{(i)}=\frac{-\nabla f(x_{(i)})^Td_{(i)}}{d_{(i)}^TAd_{(i)}}\tag5 \]\(\large\color{#70f3ff}{\boxed{\color{brown}{定理1} }}\) 对于任何\(x_0∈R^n\),由共轭方向算法(4)(5)生成的序列收敛\(\{x_i\}\)到线性方程(1)的解\(x^∗\)
至多n步。
\(\large\color{#70f3ff}{\boxed{\color{brown}{定理2} }}\) (扩张子空间最小化)\(x_0∈R^n\)为任意起点,设序列\(\{x_k\}\)由共轭方向算法(4)(5)生成,然后
\[-\nabla f(x_{(k)})^Td_{(i)}=0,\qquad i = 0, · · · , k − 1. \]\(x_k\)是\(f(x)\)最小值在集合
\[\{x|x = x_0 + span\{ d_{(0)},d_{(1)},\dots,d_{(k-1)}\}\}. \]\(\large\color{#70f3ff}{\boxed{\color{brown}{定理3} }}\) 假设共轭梯度法生成的第k次迭代不是最小解值\(x^∗\)。具备以下四个特性:
\[\begin{align*} &r^T_k r_i = 0, i = 0, · · · , k − 1,\\ &span\{r_0, r_1, · · · , r_k\} = span\{r_0, Ar_0, · · · , A^kr_0\},\\ &span\{d_{(0)},d_{(1)},\dots,d_{(k-1)}\} = span\{r_0, Ar_0, · · · , A^kr_0\}, \\ &d^T_k Ad_i = 0, i = 0, 1, · · · , k − 1.\\ \end{align*} \]在n步迭代后,\(r_{(k)}\)和k个两两正交的向量\({ r_{(0)},r_{(1)},\dots,r_{(k-1)}}\)所张成的空间正交,而\({ r_{(0)},r_{(1)},\dots,r_{(k-1)}}\)这k个向量是\(R^k\)空间中的所有正交向量,由此\(r_{(k)}\)必须是零向量,是(1)的解。
因此,序列收敛\(\{x_i\}\)到线性方程(1)的解\(x^∗\)至多n步。
1.1共轭方向的方法
定义\(r_k =∇f(x_k)\)。利用\(r_k\)和\(d_{k−1}\)计算\(d_{k}\):
\[d_k = - r_k + \beta_k d_{k-1} ,~~~~ \beta_k = \frac{r_k^T A d_{k-1}}{d_{k-1}^T Ad_{k-1}} \tag6\\ \]在这里,标量\(\beta_k\)是由\(d_{k-1}\)和\(d_{k}\)必须与A共轭的要求决定的。
\(\large\color{#70f3ff}{\boxed{\color{brown}{(CG-初始版)} }}\)
给定\(x_0\);
设置\(r_{(0)}=Ax_{(0)}-b,d_{(0)}=-r_{(0)},i=0\);
\[% <![CDATA[ \begin{align*} \alpha_{(i)}&=\frac{- r_{i}^Td_{(i)}}{d_{(i)}^TAd_{(i)}}\\ x_{(i+1)}&=x_{(i)}+\alpha_{(i)}d_{(i)}\\ r_{(i+1)}&=Ax_{(i+1)}-b\\ \beta_{(i+1)} &= \frac{r_{(i+1)}^T A d_{(i)}}{d_{(i)}^T Ad_{(i)}}\\ d_{(i+1)}&=-r_{(i+1)}+\beta_{(i+1)}d_{(i)}\\ i&=i+1 \end{align*} %]]> \]当\(r_{(k)}=0\)时,迭代停止。
\(\large\color{#70f3ff}{\boxed{\color{brown}{(CG-实用版)} }}\)
给定\(x_0\);
设置\(r_{(0)}=Ax_{(0)}-b,d_{(0)}=-r_{(0)},i=0\);
\[% <![CDATA[ \begin{align*} \alpha_{(i)}&=\frac{- r_{i}^Td_{(i)}}{d_{(i)}^TAd_{(i)}}\\ x_{(i+1)}&=x_{(i)}+\alpha_{(i)}d_{(i)}\\ r_{(i+1)}&=r_{(i)}+\alpha_{(i)}Ad_{(i)}\\ \beta_{(i+1)}&=\frac{r_{(i+1)}^Tr_{(i+1)}}{r_{(i)}^Tr_{(i)}}\\ d_{(i+1)}&=-r_{(i+1)}+\beta_{(i+1)}d_{(i)}\\ i&=i+1 \end{align*} %]]> \]当\(r_{(k)}=0\)时,迭代停止。
收敛速度
\(\large\color{#70f3ff}{\boxed{\color{brown}{定理4} }}\)如果A只有r个不同的特征值,那么CG迭代最多会在r次迭代中终止于解处。
\(\large\color{#70f3ff}{\boxed{\color{brown}{定理5} }}\)如果A的特征值为:\(\lambda_1≤\lambda_2≤···≤\lambda_n\),则有
\[\left\|x_{k+1}-x^{*}\right\|_{A}^{2} \leq\left(\frac{\lambda_{n-k}-\lambda_{1}}{\lambda_{n-k}+\lambda_{1}}\right)^{2}\left\|x_{0}-x^{*}\right\|_{A}^{2} \tag{7} \\ \]在第 $k+1 $次迭代后,残差不大于 \(\left(\frac{\lambda_{n-k}-\lambda_{1}}{\lambda_{n-k}+\lambda_{1}}\right)^{2}\) 。这个结论也是很有价值的,这里的 \(\lambda_i\) 是从小到大排列的特征值, $\lambda_{n-k} $越小,残差就越小。对于同样的 $k+1 $次迭代,如果矩阵 $A $的第 \(k\) 大的特征值比矩阵 $B $的第 $k $大的特征值小,矩阵 $A $ 就会收敛得更快。另一方面,也可以理解为,整个收敛过程中的收敛速度是变化的,与特征值的大小分布有关。如果特征值的取值呈聚类状分布,比如有5个较大的特征值,还有几个接近于1的特征值,那么迭代过程很可能像下图这样
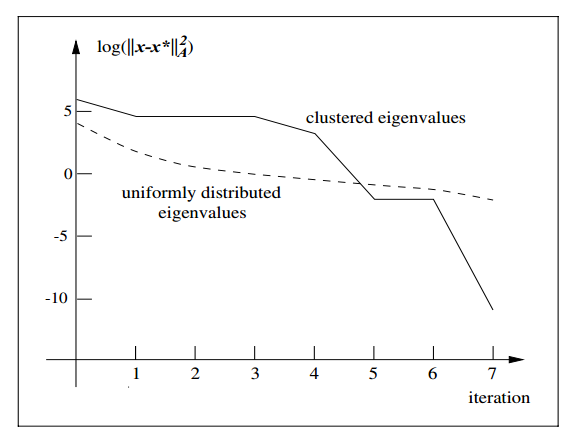
在7次迭代后就达到了比较小的值。这是因为除了5个较大的特征值,其它特征值都集中在一个聚类中。根据前面得出的结论,如果$ A$ 只有 $r \(个不同大小的特征值,次迭\)r $代后就能收敛。现在的情况与之类似,虽然聚类中的特征值并非完全一样,但我们仍然可以将其当做近似相等的特征值,所以优化在6次迭代后理论上就会接近于极值。当然,从图中可以看到,实际情况下,第7次迭代才接近极值,这也是合理的。
2非线性共轭梯度法
无约束最优化问题:
\[\begin{align*} (P) ~ ~ ~ \min &~ ~ ~ f(x)\\ \text{s.t.} &~ ~ ~x ∈ X ⊆ R^n \end{align*} \]\(\large\color{#70f3ff}{\boxed{\color{brown}{FR-CG} }}\)
给定\(x_0\);
设置\(f_0 = f(x_0),\nabla f_0 = \nabla f(x_0);d_{(0)}=-\nabla f_0 ,i=0\);
\[% <![CDATA[ \begin{align*} \alpha_{(i)}&=\frac{d_{(i)}^Td_{(i)}}{d_{(i)}^TAd_{(i)}}\\ x_{(i+1)}&=x_{(i)}+\alpha_{(i)}d_{(i)}\\ \beta_{(i+1)}^{FR}&=\frac{\nabla f_{(i+1)}^T\nabla f_{(i+1)}}{\nabla f_{(i)}^T\nabla f_{(i)}}\\ d_{(i+1)}&=-\nabla f_{(i+1)}+\beta_{(i+1)}^{FR}d_{(i)}\\ i&=i+1 \end{align*} %]]> \]当\(\nabla f_{(k)}=0\)时,迭代停止。
\(\large\color{#70f3ff}{\boxed{\color{brown}{PR-CG} }}\)
迭代公式和FR一样,只是
\[\beta_{(i+1)}^{PR}=\frac{\nabla f_{(i+1)}^T(\nabla f_{(i+1)}-\nabla f_{(i)})} {\|\nabla f_{(i)}\|^2} \]\(\large\color{#70f3ff}{\boxed{\color{brown}{PR+-CG} }}\)
迭代公式和FR一样,只是
\[\beta_{(i+1)}^{PR+}=max\{\beta_{(i+1)}^{PR},0\} \]\(\large\color{#70f3ff}{\boxed{\color{brown}{HS-CG} }}\)
迭代公式和FR一样,只是
\[\beta_{k + 1}^{HS} = \frac{\nabla f(x_{i+1})^T (\nabla f(x_{i + 1}) - \nabla f(x_i))}{(\nabla f(x_{i + 1}) - \nabla f(x_i))^T d_i} \]https://alkane0050.fun/2019/05/18/%E5%85%B1%E8%BD%AD%E6%A2%AF%E5%BA%A6%E6%B3%95%E5%88%9D%E6%AD%A5/
https://zhuanlan.zhihu.com/p/143103337
https://www.zhihu.com/question/277576767
https://zhuanlan.zhihu.com/p/103072012
https://www.zhihu.com/question/277576767/answer/1230863738
https://zhuanlan.zhihu.com/p/23804838
https://zhuanlan.zhihu.com/p/234950550
https://zhuanlan.zhihu.com/p/64227658
标签:特征值,迭代,05,color,brown,nabla,lambda 来源: https://www.cnblogs.com/liangjiangjun/p/14022641.html