N-BEATS:神经网络底层扩展分析,用于可解释的时间序列预测
作者:互联网
[2020.08.05]深度学习与气象时序预测_张琦
|
有什么好的模型可以做高精度的时间序列预测呢?
R语言里的 auto.arima, 有 Python版 https://github.com/alkaline-ml/pmdarima , arima 模型是baseline, 大部分论文都会首先跟它对比效果 Facebook Prophet,工程化很好,很好用 2018年Uber出品的 ES-RNN ,是M4比赛的冠军 2020年 Yoshua Bengio 团队出品的 N-BEATS, 打败了 ES-RNN
快速ES-RNN: ES-RNN算法的GPU实现 - 人工智能学术前沿的文章 - 知乎 https://zhuanlan.zhihu.com/p/74573311 https://github.com/awslabs/gluon-ts
CNN和RNN混血儿:序列建模新架构TrellisNet - 论智的文章 - 知乎 https://zhuanlan.zhihu.com/p/47339572
DARNN:一种新的时间序列预测方法——基于双阶段注意力机制的循环神经网络 - 罗未萌的文章 - 知乎 https://zhuanlan.zhihu.com/p/36440240 作为一个非常新的时间序列模型,作者在Nasdaq100数据集上实现了很好的预测效果 我在网上找到了该篇论文的PyTorch实现,准备试着跑一下http://chandlerzuo.github.io/blog/2017/11/darnn
|
|
首发于人工智能学术前沿
N-BEATS:神经网络底层扩展分析,用于可解释的时间序列预测
N-BEATS:神经网络底层扩展分析,用于可解释的时间序列预测
题目:
N-BEATS: Neural basis expansion analysis for interpretable time series forecasting
作者:
Boris N. Oreshkin, Dmitri Carpov, Nicolas Chapados, Yoshua Bengio
来源:
Computer Vision and Pattern Recognition (cs.CV)
ICLR 2020
Submitted on 25 Jul 2019 (v1), last revised 8 Apr 2020 (this version, v4)
文档链接:
https://openreview.net/pdf?id=r1ecqn4YwB
代码链接:
https://github.com/amitesh863/nbeats_forecast
摘要
我们专注于使用深度学习来解决单变量时间序列点预测问题。我们提出了一种基于神经网络的深层神经结构,该结构基于向前和向后的残差链接以及非常深的全连接层堆栈。该体系结构具有许多理想的属性,这些属性可以解释,可以在不修改大量目标域的情况下适用,并且训练迅速。我们在几个著名的数据集上测试了提议的体系结构,包括M3,M4和TOURISM竞赛数据集,其中包含来自不同领域的时间序列。我们展示了针对所有数据集的两种N-BEATS配置的最新性能,与统计基准相比,预测准确性提高了11%,与去年M4竞赛的获胜者相比,提高了3%,在神经网络和统计时间序列模型之间进行领域调整的手工混合。我们模型的第一个配置未使用任何特定于时间序列的组件,并且其在异构数据集上的性能强烈表明,与公认的知识相反,深度学习原语(例如残差块)本身足以解决各种预测问题。最后,我们演示了如何扩展所建议的体系结构以提供可解释的输出,而不会造成准确性的重大损失。诸如残差块之类的深度学习原语本身就足以解决各种预测问题。最后,我们演示了如何扩展所建议的体系结构以提供可解释的输出,而不会造成准确性的重大损失。诸如残差块之类的深度学习原语本身就足以解决各种预测问题。最后,我们演示了如何扩展所建议的体系结构以提供可解释的输出,而不会造成准确性的重大损失。
英文原文
We focus on solving the univariate times series point forecasting problem using deep learning. We propose a deep neural architecture based on backward and forward residual links and a very deep stack of fully-connected layers. The architecture has a number of desirable properties, being interpretable, applicable without modification to a wide array of target domains, and fast to train. We test the proposed architecture on several well-known datasets, including M3, M4 and TOURISM competition datasets containing time series from diverse domains. We demonstrate state-of-the-art performance for two configurations of N-BEATS for all the datasets, improving forecast accuracy by 11% over a statistical benchmark and by 3% over last year's winner of the M4 competition, a domain-adjusted hand-crafted hybrid between neural network and statistical time series models. The first configuration of our model does not employ any time-series-specific components and its performance on heterogeneous datasets strongly suggests that, contrarily to received wisdom, deep learning primitives such as residual blocks are by themselves sufficient to solve a wide range of forecasting problems. Finally, we demonstrate how the proposed architecture can be augmented to provide outputs that are interpretable without considerable loss in accuracy.
N-BEATS结构
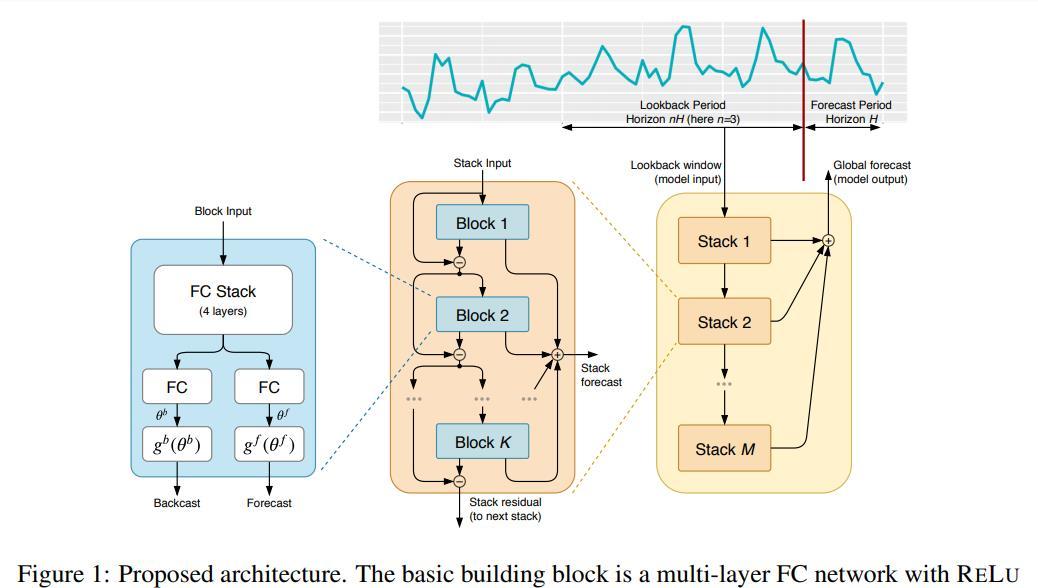
所提议的基本构建块具有一个分支架构,如图1(左)所示。在本节中,我们着重详细描述第t个块的操作(为简便起见,在图1中删除了块索引`)。第t个块接受其各自的输入x,并输出两个向量bx和by。对于模型中的第一个块,其相应的x`是整体模型输入的一定长度的历史回溯窗口,以最后一次测量的观测值结束
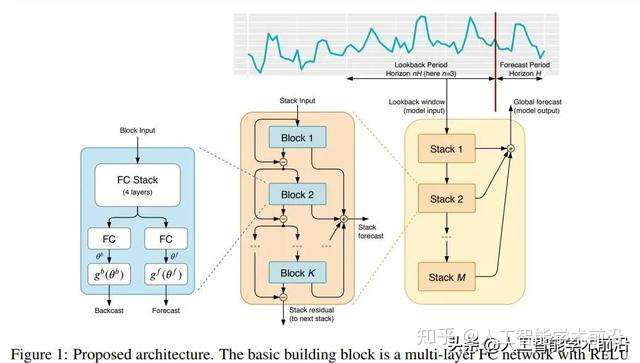
图1:提议的架构。其基本构件是具有相关非线性的多层FC网络。它预测基础上扩张系数都向前,θ^f(预测)和落后,θ^b(展望)。块被组织成堆叠使用双重剩余堆积原则。堆栈可以有共享的g^b和g^f层。预测以分级方式汇总。这使得构建一个具有可解释输出的深度神经网络成为可能。
实验结果
表1:在M4、M3、旅游测试集上的性能,聚合在每个数据集上。为每个数据集指定评估指标;数值越低越好。括号中提供了每个数据集中的时间序列数量。
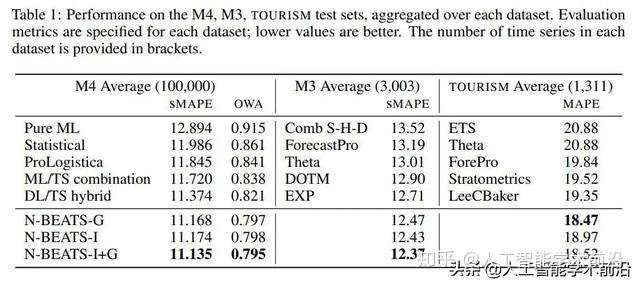
根据表1,N-BEATS在三个具有挑战性的非重叠数据集上展示了最先进的性能,这些数据集包含来自非常不同领域的时间序列、采样频率和季节性。通用的N-BEATS模型使用尽可能少的先验知识,没有特征工程,没有缩放,也没有内部的体系结构组件,这些组件可能被认为是特定于时间序列的。
因此,表1中的结果使我们得出这样的结论:DL不需要统计方法或手工特征工程和领域知识的支持,就可以在大量的TS预测任务中表现得非常好。
讨论:N-BEATS与元学习的联系
元学习Meta-learning
元学习定义了一个内在的学习过程和一个外在的学习过程。内部学习过程是参数化、条件化或受外部学习过程影响的(Bengio et al., 1991)。
典型的内学习和外学习是个体在动物的一生中学习,而内学习过程则是个体在几代人的时间里不断进化。要了解这两个层次,通常需要参考两组参数,即在内部学习过程中修改的内部参数(如突触权重),及外部参数或元参数(如基因)只在外部学习过程中被修改。
N-BEATS可以通过以下类比作为元学习的一个实例。外部学习过程被封装在整个网络的参数中,通过梯度下降学习。内部学习过程封装在一组基本构建模块中,并进行修改底层 g f作为输入的扩张系数θ f
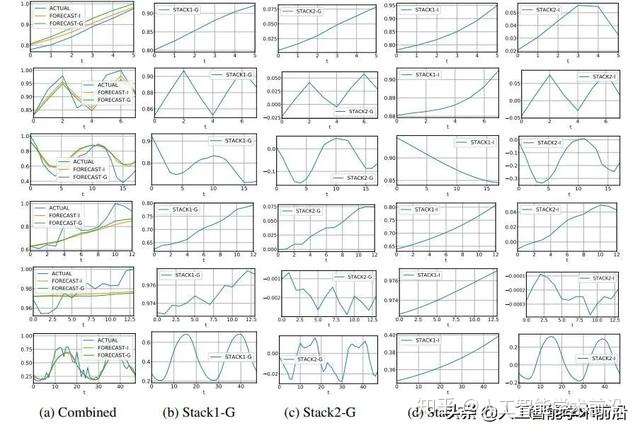
图2:通用配置和可解释配置的输出,M4数据集。每行是每个数据频率的一个时间序列例子,从上到下(年:id Y3974,季度:id Q11588,月:id M19006,周:id W246,日:id D404,小时:id H344)。
为了方便起见,将行中的大小按实际时间序列的最大值进行标准化。(a)列显示实际值(ACTUAL)、一般模型预测(FORECAST-G)和解释模型预测(FORECAST-I)。列(b)和(c)分别显示了通用模型的栈1和栈2的输出;FORECAST-G是它们的总和。列(d)和(e)分别显示可解释模型的趋势和季节性堆栈的输出;FORECAST-I是它们的总和。
结论
我们提出并实证验证了一种新的单变量TS预测体系结构。结果表明,该体系结构具有通用性、灵活性和良好的预测性能。我们将其应用于三个不重叠的挑战性竞争数据集:M4、M3和旅游业,并在两种配置下展示了最先进的性能:通用和可解释。这使我们能够验证两个重要的假设:(i)一般的DL方法在不使用TS领域知识的异构单变量TS预测问题上表现得非常好,(ii)另外约束DL模型迫使其将预测分解为不同的人类可解释输出是可行的。我们还证明了DL模型可以以多任务的方式在多个时间序列上进行训练,成功地传递和共享个体的学习。我们推测,N-BEATS的表现在一定程度上可以归因于它进行了一种元学习的形式,对它进行更深入的研究应该是未来工作的主题。
发布于 04-25 神经网络 时间序列分析 预测
文章被以下专栏收录
推荐阅读
用于可解释的多水平时间序列预测的时间融合Transformers
人工智能学...发表于人工智能学...
Connecting the Dots: 基于图神经网络的多元时间序列预测
人工智能学...发表于人工智能学...
【时空序列预测第七篇】时空序列预测模型之GAN+LSTM
AI蜗牛车发表于时空序列预...
近期和远期的预测信息融合的预测提升方法
人工智能学...发表于人工智能学...1 条评论
写下你的评论...-
 ppy10-16
ppy10-16
多变量TS预测适用吗?
---
首发于人工智能学术前沿
快速ES-RNN: ES-RNN算法的GPU实现
快速ES-RNN: ES-RNN算法的GPU实现
题目:
Fast ES-RNN: A GPU Implementation of the ES-RNN Algorithm
作者:
Andrew Redd, Kaung Khin, Aldo Marini
来源:
Machine Learning (cs.LG)
Submitted on 7 Jul 2019
文档链接:
arXiv:1907.03329
代码链接:
https://github.com/awslabs/gluon-ts
摘要
由于它们的普遍存在,时间序列预测在多个领域都是至关重要的。我们力求使最先进的预测快速、简便、可推广。ES-RNN是经典状态空间预测模型与现代RNNs的结合,在M4竞争中取得了9.4%的sMAPE改进。关键是,ES-RNN的实现需要每次序列参数。通过对原始实现进行矢量化并将算法移植到GPU上,我们根据批处理大小实现了高达322x的训练加速,结果与原始提交中报告的结果类似。
英文原文
Due to their prevalence, time series forecasting is crucial in multiple domains. We seek to make state-of-the-art forecasting fast, accessible, and generalizable. ES-RNN is a hybrid between classical state space forecasting models and modern RNNs that achieved a 9.4% sMAPE improvement in the M4 competition. Crucially, ES-RNN implementation requires per-time series parameters. By vectorizing the original implementation and porting the algorithm to a GPU, we achieve up to 322x training speedup depending on batch size with similar results as those reported in the original submission.
要点
我们的任务是使最先进的预测快速、简便、可推广。首先,我们通过将Smyl s的原始c++提交移植到Pytorch来实现快速培训。这种矢量化允许使用GPU,提供高达322x的训练加速。其次,Python代码使预测和机器学习社区更容易访问模型。1 .最后,Pytorch的使用使得模型的泛化更加容易,因为库中包含多个架构,可以补充ES-RNN在非m4时间序列中的应用。我们期望我们的贡献,以加快采用混合模型在时间序列预测。
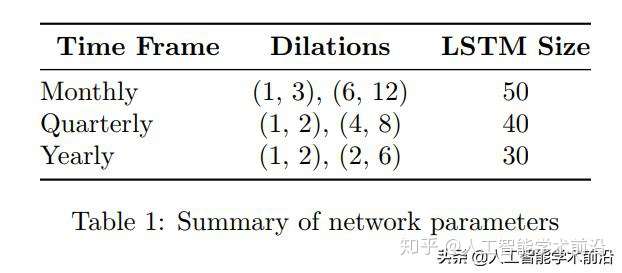
表1:网络中设置的参数总结
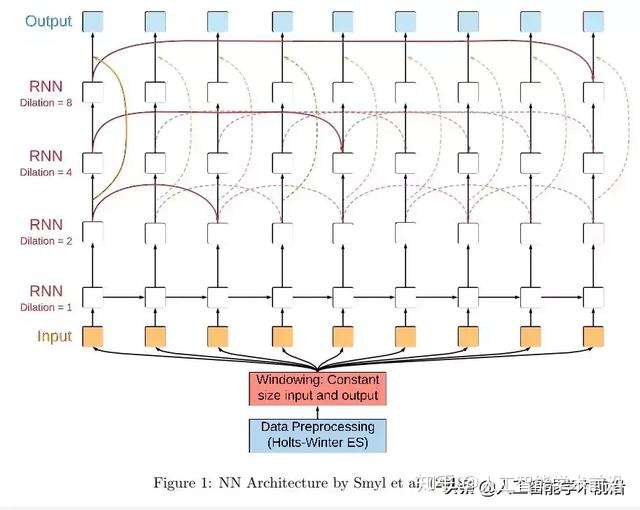
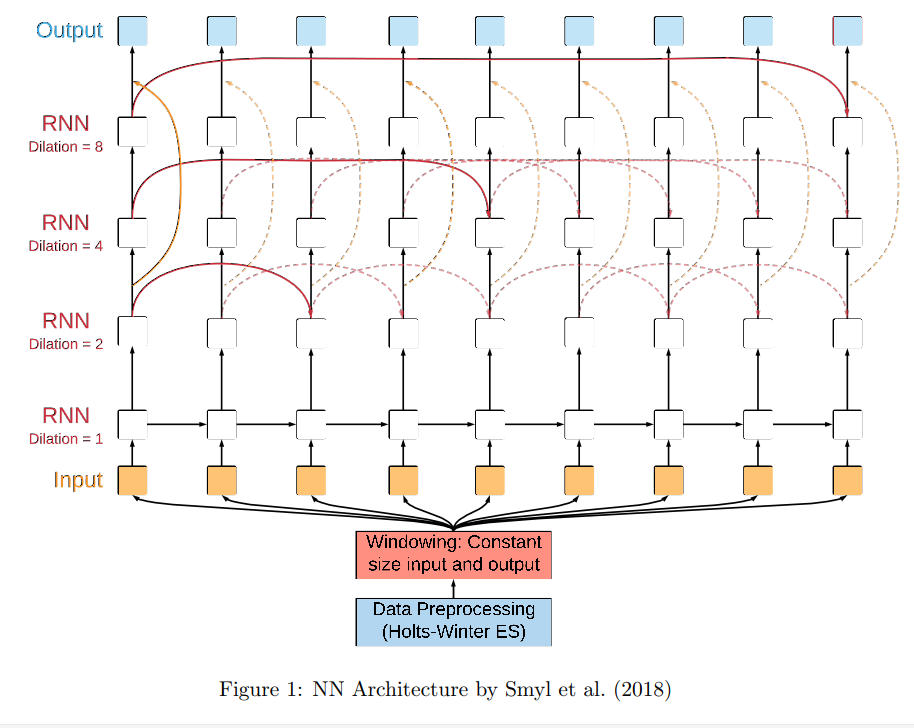
图1:Smyl等人(2018)的NN架构示意图
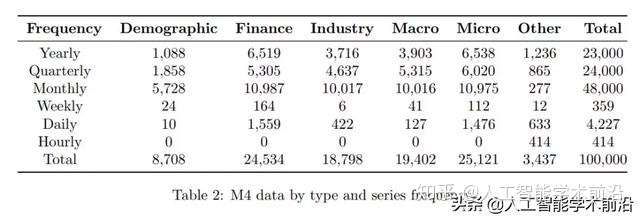
表2:M4按类型和系列频率排列的数据
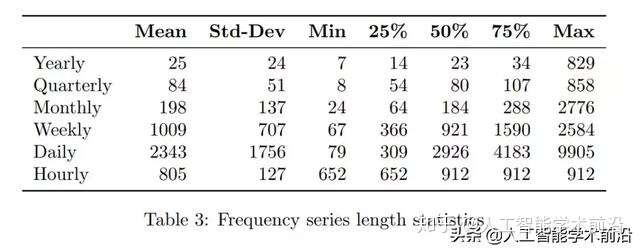
表3:频率序列长度统计
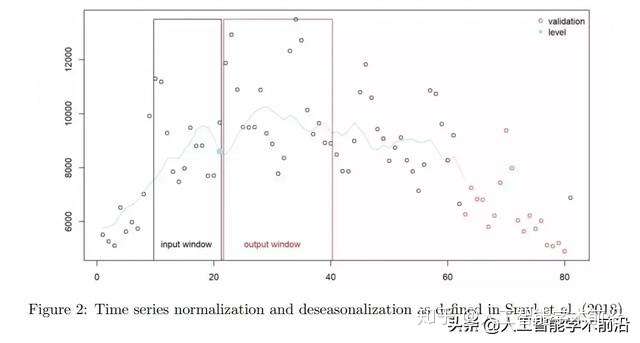
图2:Smyl等人(2018)定义的时间序列规范化和消除季节性因素处理
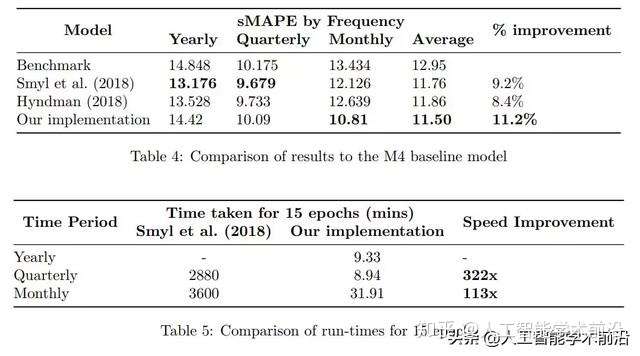
表4:结果与M4基线模型的比较
表5:15轮的运行时间迭代后结果比较
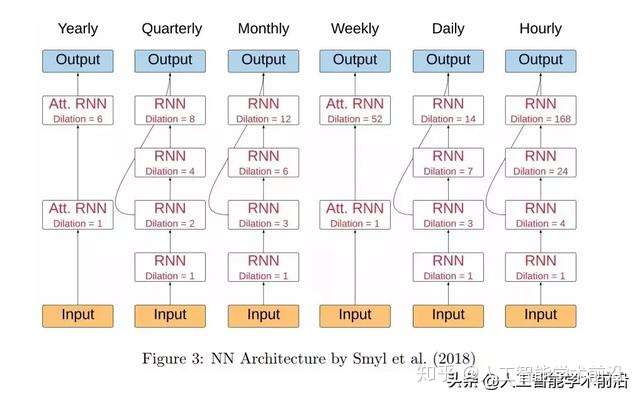
图3:Smyl等人(2018)的NN架构
在这个项目中,我们成功地将最先进的ES-RNN算法应用于一个快速、可访问、可推广的预测框架中。我们克服的主要挑战是每次序列参数的训练。由于直接在CPU上实现原始提交,这证明是困难的。我们的工作集中在每次序列参数的矢量化上,以使GPU计算在一个支持快速执行的框架中(如Pytorch)。我们得到了与原始提交的结果相似的结果,但是少了几个数量级的训练时间。
我们预计我们的贡献将使最先进的算法在单变量序列上得到强有力的采用,并有助于将模型推广到可使用协变量的特定问题。
发布于 2019-07-21 机器学习文章被以下专栏收录
推荐阅读
全面理解RNN及其不同架构
Evan发表于AI遇见机...
RNN Part1-RNN介绍
习翔宇![[AAAI18]面向序列建模的元多任务学习](https://pic2.zhimg.com/v2-ad7cdce815e7ac74092a6dcc676bb203_250x0.jpg?source=172ae18b)
[AAAI18]面向序列建模的元多任务学习
godweiyang
RNN基本模型汇总(deeplearning.ai)
Haishuo还没有评论
写下你的评论...标签:RNN,神经网络,学习,BEATS,序列,底层,ES,预测 来源: https://www.cnblogs.com/cx2016/p/13948007.html