调研报告|在线语音识别改进之 RNN-T 训练
作者:互联网
调研报告|在线语音识别改进之 RNN-T 训练
这篇文章主要调研的是另外一种改进在线语音识别的方法:基于 RNN Transducer 方法。当然最近强势的基于 Transformer 的 Encoder-Decoder 在线方法(MoChA-type/local window /triggered attention/Scout Network/Chunk-aware)也是我比较感兴趣的方向,后面会单独拎出来讨论。
这篇文章可能文字讲解的地方会比较少,因为图片的内容信息量已经很大了,同时论文的出处我会一并放出,有兴趣的朋友可以阅读下原文。因为我本人是基于 TensorFlow 进行实验的,所以文末会给出有助于我们搭建基于 TensorFlow 的 RNN-T 训练框架的 Repo。
实时系统的训练准则对⽐
Frame-Level Criterion
Cross Entropy:
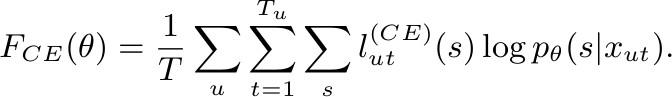 CE Loss 公式
CE Loss 公式
Sequence-Level Criteria
- Maximum Mutual Information:
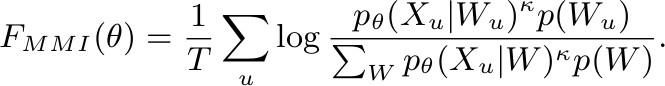 MMI Loss 公式
MMI Loss 公式
该 loss 出了对带浅层语言声学模型做基于词序列的标准解优化之外,还对竞争路径做了区分优化。
Ref:Sequence-discriminative training of deep neural networks
- Minimum Phone Error or state-level Minimum Bayes Risk:
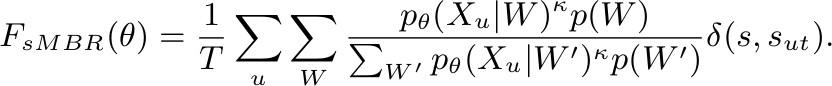 sMBR Loss 公式
sMBR Loss 公式
基于MMI的进一步优化是,对标准路径做了相似路径优化扩充,引入了序列相似度打分,旨在缩小类内距离同时放大类外距离。
Ref:Sequence-discriminative training of deep neural networks
End-to-End Criteria
- Connectionist Temporal Classification:
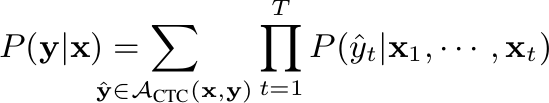 CTC Loss 公式
CTC Loss 公式
相信会有部分人认为 CTC 方法端到端框架下有点牵强,我觉得这很大可能是因为后期出了 RNN-T、Seq2Seq、Encoder-Decoder 框架。可在 CTC 方法刚提出的时候大家普遍都认为这就是一种端到端的方法,该方法极大的简化了此前基于 GMM-HMM alignment 的数据准备流程,英文可以基于 BPE 等方法直接制作 word-piece 就可以训练,中文,建立发音映射表或者基于常用字替换表就可以直接训练。当然后期还是会依赖发音词典和语言模型。
- RNN-T:
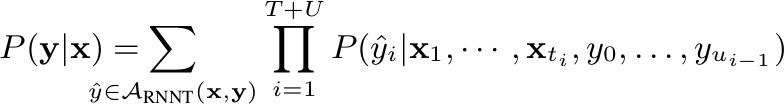 RNN-T Loss 公式
RNN-T Loss 公式
RNN-T 是基于 CTC 的一个改进,详细内容可以参考两篇经典文章Sequence Transduction with Recurrent Neural Networks 和 Sequence to Sequence Learning with Neural Networks。具体优化如CTC、Prediction初始化,LayerNorm和学习率等会在后面论文实验部分来分享。似乎 RNN-T 在数据规模不是特别大(7~8万小时)的情况下,还是很需要工匠精神的。
论⽂中的实验对⽐
Model Units
以下是来自京东的一组训练框架的 setup
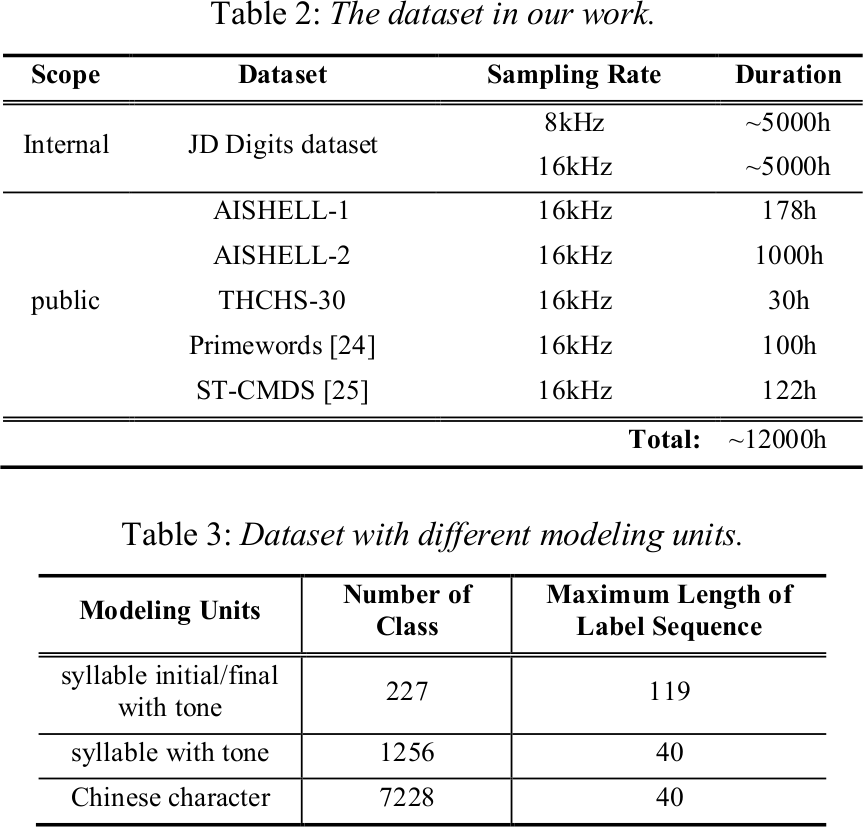 京东的实验准备
京东的实验准备
中文识别单元的实验对比如下:
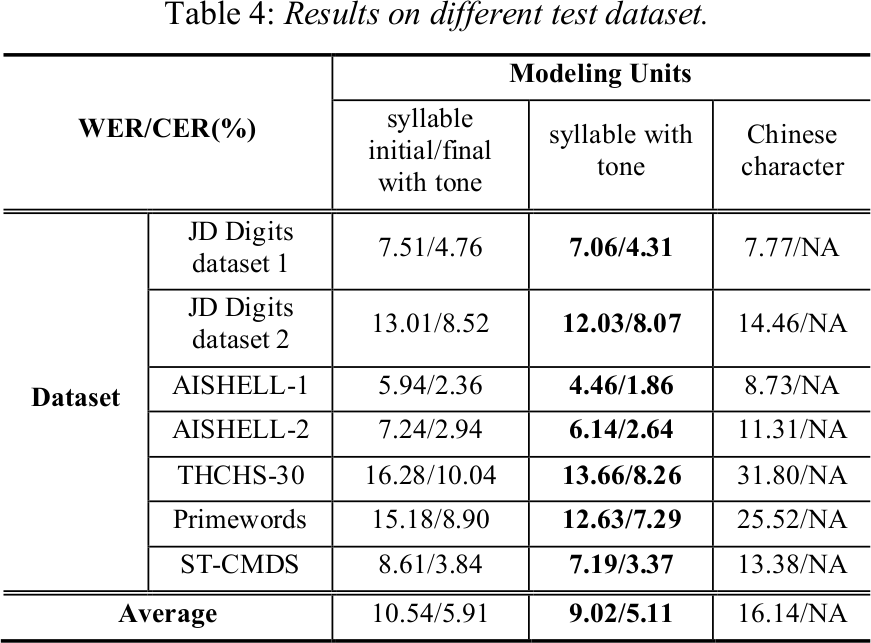 不同识别单元对 Transducer 的影响
不同识别单元对 Transducer 的影响
京东的实验结果关于中文字的实验结果似乎和阿里 Zhang Shiliang 论文中的 Investigation of Modeling Units for Mandarin Speech Recognition Using Dfsmn-ctc-smbr 结果有些出入。我的理解是两个框架下中文字的建模有比较大的区别,一个基于7228字作为完整映射,一个基于2000/3000/4000中文字加拼音(或常用字替换)后期还是要基于发音词典(或常用字映射)来解码。后者对于语言层面的解码有很大的优化空间。
Ref: Research on Modeling Units of Transformer Transducer for Mandarin Speech Recognition
Different Criterion
Datsebase is 1000 hours Sogou dataset. model units is Chinese character:
- 26 English characters
- 6784 frequently-used Chinese characters an unknown token (UNK)
- a blank token
 1000小时下不同的 RNN-T 优化方法对于识别率的影响
1000小时下不同的 RNN-T 优化方法对于识别率的影响
Ref: Exploring RNN-Transducer for Chinese Speech Recognition
Dataset
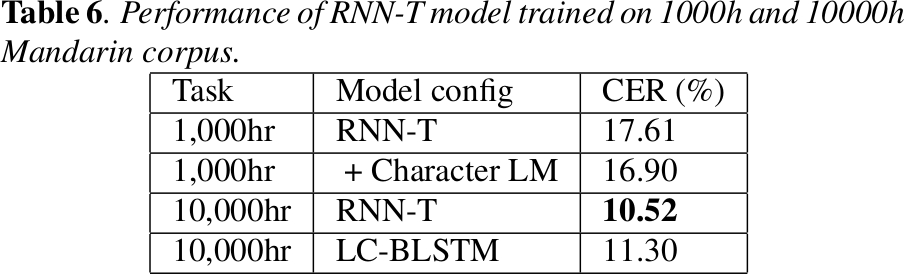 不同数据量对于 RNN-T 的影响
不同数据量对于 RNN-T 的影响
Ref: Exploring RNN-Transducer for Chinese Speech Recognition
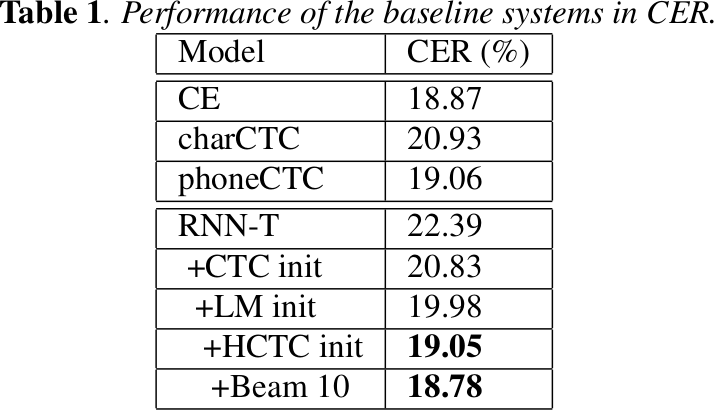
Quality Improvements
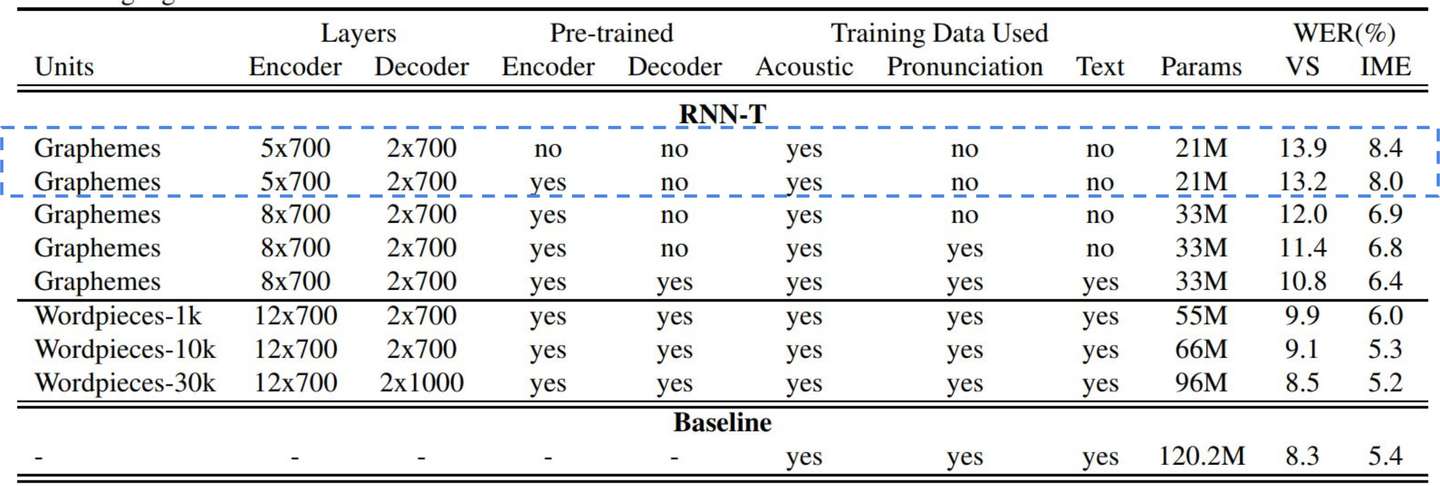 RNN-T 初始化的影响
RNN-T 初始化的影响
Configure:
- 8-layer encoder, 2048 unidirectional LSTM cells + 640 projection units.
- 2-layer prediction network, 2048 unidirectional LSTM cells + 640 projection units.
- Model output units: grapheme or word-piece.
- Total system size: ~120MB after quantization (more on this in a later slide).
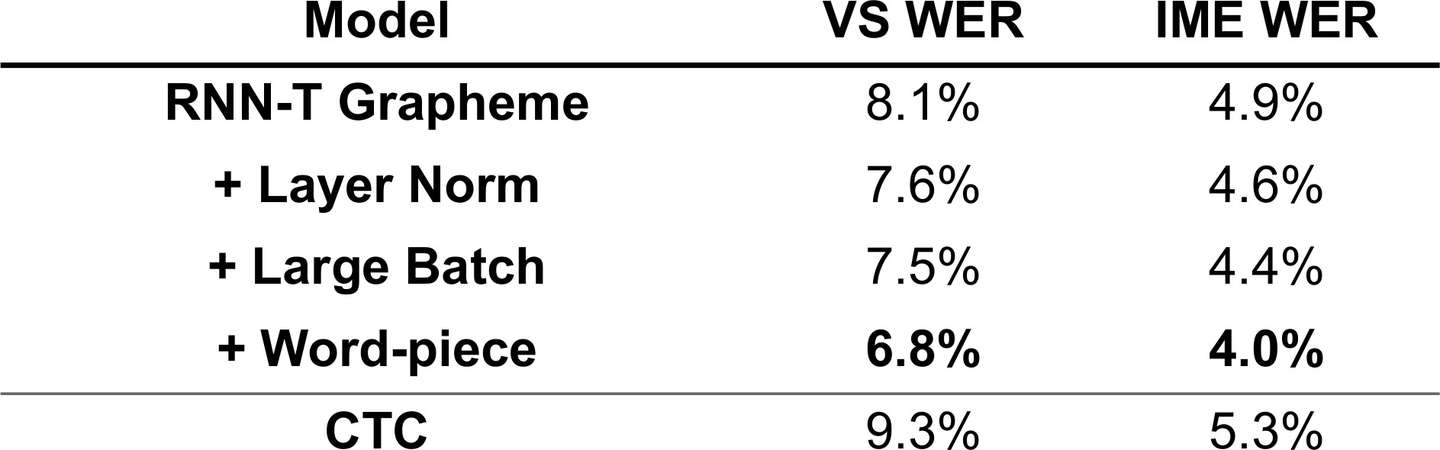 RNN-T 的几个优化方法对于识别的影响以及 CTC 的对比
RNN-T 的几个优化方法对于识别的影响以及 CTC 的对比
Ref: Towards End-to-End Speech Recognition - ISCSLP 2018
开源项⽬
warp-transducer
Mingkun Huang 参考 warp-ctc 实现的 GPU/CPU 版本的 RNN-T Loss,目前支持 PyTorch/Tensorflow binding。我目前也是用这个项目做 RNN-T 的实验,结果符合预期。以下是我针对1万多小时的 3000字+1000Subword 训练的模型,测试了80多小时的语料,Greedy search 的测试结果:
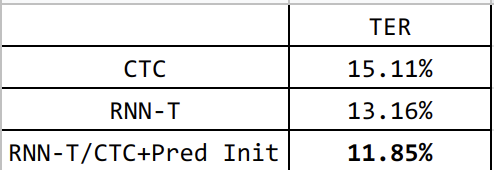 加入预训练后 RNN-T 的 Greedy Search 结果提升明显
加入预训练后 RNN-T 的 Greedy Search 结果提升明显
rnnt-speech-recognition
Noah Chalifour 大学生开发,一套基于 TensorFlow 2.0 的 RNN-T 训练框架,几乎从数据制作到训练、测试都是采用 TensorFlow,目前原作者似乎都没完整跑完一个 CommonVoice 训练。我目前跑了几个迭代,非常慢并且伴随 crash 的问题,猜测是因为训练过程中实时 Greedy Search 测试的缘故,所有只能从头完成了 RNN-T 的训练,后续考虑开源出来。说回来,rnnt-speech-recognition 这部分代码的条理很清晰,同时风格也比较精练,整套代码很值得参考。
TensorflowASR
涵盖比较全的训练框架,基于 TensorFlow 2.0. 目前还未详细看过,看文档和试验结果,应该还算蛮靠谱。有试过的朋友麻烦给个留言。
编辑于 10-12 语音识别 RNN 中文语音识别
文章被以下专栏收录
推荐阅读
调研报告|在线语音识别改进方法之序列区分性训练
走运黄发表于茶多酚老爹
语音识别中的End2End模型: CTC, RNN-T与LAS
川陀学者
使用RNN-Transducer进行语音识别建模【附PPT与视频资料】
马上科普详解CTC
本文主要参考自Hannun等人在distill.pub发表的文章( https://distill.pub/2017/ctc/),感谢Hunnun等人对CTC的梳理。简介在语音识别中,我们的数据集是音频文件和其对应的文本,不幸的是,…
大师兄18 条评论
写下你的评论...-
 wangyanquan06-15
wangyanquan06-15
我目前也是用这个项目做 RNN-T 的实验,结果非常符合预期。大神可否分享一下工程
-
 走运黄 (作者) 回复wangyanquan06-15
走运黄 (作者) 回复wangyanquan06-15
你也是 Tensorflow 2.0 以下的版本训练吗?
-
wangyanquan回复走运黄 (作者)06-15
tensorflow-gpu==1.10.1
-
wangyanquan06-15
另外问一句,大神用的lstm是双向的还是单向的
-
走运黄 (作者) 回复wangyanquan06-16
单向的 GRU。
标签:基于,RNN,训练,回复,语音,CTC,识别,在线 来源: https://www.cnblogs.com/cx2016/p/13851549.html