帮助CXO解惑上云成本的迷思,看这篇就够了
作者:互联网

- 实际支出成本
- 浪费的成本
- 隐性成本
- 机会成本
- 潜在风险带来的可能损失
- 潜在机会带来的可能收益
- 企业现金流
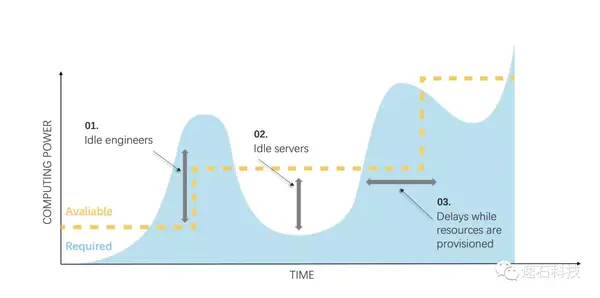 这张最初源自Cadence的图,几乎完美诠释了这种波动导致的浪费情况。
黄色表示本地资产规模,蓝色区域表示资源需求量。过相对长一段时间会追加一批机器,再过一段时间发现不够了会再追加一批。
在01和02两个时间段,不是研发人员因为没资源可用,只能排着队喝着咖啡苦苦等待。就是需求量下来了,大量资源被闲置。
虽然这张图是半导体行业大佬画的,但有非常广泛的适用场景,尤其是在HPC高性能计算领域,比如药物研发,CAE工业仿真,人工智能等等。
B.不同部门需求虚报,浪费机器
一方面,从申请资源到分配往往有一定时间差,另一方面还是因为需求测不准。部门向公司提出申请时往往倾向于多申请一些,或者干脆要求独占资源,以确保本部门在需要的时候有足够的资源。但实际利用率却未必高,造成浪费。
C.本地资源的利用效率和公司IT专业人员的技术水平也直接相关
云上的浪费
A.云的收费模式和本地完全不同,不同云厂商之间也有不少区别。相当一部分企业可能在还没搞懂规则的情况下,费用就上去了。
单说云端实例资源,常见计费模式分为三种:
预留实例:相当于批发,买定离手。主要针对中长期稳定需求,优点是价格整体比较低,缺点是资源必须长期持有,灵活性差。
按需实例 :相当于零售,即买即用。针对短期弹性需求,按小时计费,灵活精准,避免浪费,但价格比较高。
可被抢占实例 :又称竞价实例,相当于秒杀,手快有手慢无。作为云资源中的低成本战斗机,最低可达到按需实例价格的10%。随时可能被抢占,需要有一定的技术实力才能使用。怎么合理地用不同云的不同计费模式,确保成本最小化。这个工具包可以先了解一下。
这张最初源自Cadence的图,几乎完美诠释了这种波动导致的浪费情况。
黄色表示本地资产规模,蓝色区域表示资源需求量。过相对长一段时间会追加一批机器,再过一段时间发现不够了会再追加一批。
在01和02两个时间段,不是研发人员因为没资源可用,只能排着队喝着咖啡苦苦等待。就是需求量下来了,大量资源被闲置。
虽然这张图是半导体行业大佬画的,但有非常广泛的适用场景,尤其是在HPC高性能计算领域,比如药物研发,CAE工业仿真,人工智能等等。
B.不同部门需求虚报,浪费机器
一方面,从申请资源到分配往往有一定时间差,另一方面还是因为需求测不准。部门向公司提出申请时往往倾向于多申请一些,或者干脆要求独占资源,以确保本部门在需要的时候有足够的资源。但实际利用率却未必高,造成浪费。
C.本地资源的利用效率和公司IT专业人员的技术水平也直接相关
云上的浪费
A.云的收费模式和本地完全不同,不同云厂商之间也有不少区别。相当一部分企业可能在还没搞懂规则的情况下,费用就上去了。
单说云端实例资源,常见计费模式分为三种:
预留实例:相当于批发,买定离手。主要针对中长期稳定需求,优点是价格整体比较低,缺点是资源必须长期持有,灵活性差。
按需实例 :相当于零售,即买即用。针对短期弹性需求,按小时计费,灵活精准,避免浪费,但价格比较高。
可被抢占实例 :又称竞价实例,相当于秒杀,手快有手慢无。作为云资源中的低成本战斗机,最低可达到按需实例价格的10%。随时可能被抢占,需要有一定的技术实力才能使用。怎么合理地用不同云的不同计费模式,确保成本最小化。这个工具包可以先了解一下。
 B.手动模式,浪费是不可避免的
首先,上面说的竞价实例,手动模式就使用不了。这损失可不小,具体可参考:云资源中的低成本战斗机——竞价实例,AWS、阿里云等六家云厂商完全用户使用指南
然后,手动模式在云上开关机,经常会发生机器没有及时关闭导致的浪费,别小看这一点,浪费真的很严重。24小时盯着?真不是人该干的事。
手动模式已经不能满足企业优化云支出的诉求,自动模式可以快速适应环境变化并不断优化使用过程。预告一下:我们有个优秀的Auto-Scale功能,能基于多云环境,使集群规模根据用户计算任务的算力需求,自动增加或减少,以后开单篇仔细讲。
C.实际业务需求与使用资源不匹配导致的浪费
比如可能申请了超出实际需求的内存过大或CPU过多的资源(大和多,就意味着贵)。
D. 不同云厂商各自优势合理配置,减少浪费
隐性成本
隐性成本:经常被忽略,但支出也不小
本地的隐性成本
A.本地数据中心建设与升级的一系列问题:规划、建筑、施工、培训,是一个非常复杂的过程,每一个环节都不能出问题。同时,必须与内部客户合作以确保服务的连续性。
B.不同业务部门资源的抢夺
C.业务部门和IT部门的沟通成本
用云的隐性成本
A.云本身使用难度和门槛
目前主流云厂商所提供的产品线已经相当完善,有不少面向行业的解决方案。但产品和服务数量实在是过于庞大,入口也很多,最终导致操作层面的复杂性。
再考虑到不同云厂商的使用方式还不一样,学习成本挺高的。
B. 云上超大规模集群的调度能力
这一条主要是考虑到云上近乎无限的资源池总量。超大规模集群调度的要求自然比普通集群高,就像做一桌满汉全席和家常小宴自然要求不一样。
超大规模集群,我们先问买不买得起,再问买不买得到,然后才是怎么管理,怎么调度,怎么考虑网络,怎么安排存储。
参考:花费4小时5500美元,速石科技跻身全球超算TOP500
C.如果考虑混合云场景IT自动化管理,或者,多本地+多云场景IT自动化管理,这些都是难点。
B.手动模式,浪费是不可避免的
首先,上面说的竞价实例,手动模式就使用不了。这损失可不小,具体可参考:云资源中的低成本战斗机——竞价实例,AWS、阿里云等六家云厂商完全用户使用指南
然后,手动模式在云上开关机,经常会发生机器没有及时关闭导致的浪费,别小看这一点,浪费真的很严重。24小时盯着?真不是人该干的事。
手动模式已经不能满足企业优化云支出的诉求,自动模式可以快速适应环境变化并不断优化使用过程。预告一下:我们有个优秀的Auto-Scale功能,能基于多云环境,使集群规模根据用户计算任务的算力需求,自动增加或减少,以后开单篇仔细讲。
C.实际业务需求与使用资源不匹配导致的浪费
比如可能申请了超出实际需求的内存过大或CPU过多的资源(大和多,就意味着贵)。
D. 不同云厂商各自优势合理配置,减少浪费
隐性成本
隐性成本:经常被忽略,但支出也不小
本地的隐性成本
A.本地数据中心建设与升级的一系列问题:规划、建筑、施工、培训,是一个非常复杂的过程,每一个环节都不能出问题。同时,必须与内部客户合作以确保服务的连续性。
B.不同业务部门资源的抢夺
C.业务部门和IT部门的沟通成本
用云的隐性成本
A.云本身使用难度和门槛
目前主流云厂商所提供的产品线已经相当完善,有不少面向行业的解决方案。但产品和服务数量实在是过于庞大,入口也很多,最终导致操作层面的复杂性。
再考虑到不同云厂商的使用方式还不一样,学习成本挺高的。
B. 云上超大规模集群的调度能力
这一条主要是考虑到云上近乎无限的资源池总量。超大规模集群调度的要求自然比普通集群高,就像做一桌满汉全席和家常小宴自然要求不一样。
超大规模集群,我们先问买不买得起,再问买不买得到,然后才是怎么管理,怎么调度,怎么考虑网络,怎么安排存储。
参考:花费4小时5500美元,速石科技跻身全球超算TOP500
C.如果考虑混合云场景IT自动化管理,或者,多本地+多云场景IT自动化管理,这些都是难点。
 D.迁移成本??
传统场景下,如果企业具备一定本地集群,上云确实需要一定工作量和迁移成本,这包括网络打通、数据、作业、应用迁移和测试等。规模越大,工作量就越大。
但对我们来说,迁移成本极低。我们是原生在云上的,在用户的本地和云上建了一层,只需要考虑数据的流动,不需要考虑整体迁移,成本极低。
机会成本
机会成本:被放弃的选择中的最高价值
资金机会成本
这个钱如果不用在本地建设,花在别的地方能带来什么?
A.云上用最新型机器带来的效率提升,时间周期缩短
本地机器更新周期一般以年为单位,特殊需求可能申请特别审批,时间流程也短不了。像“财大气粗”的云厂商一样,最新型的机器那边上市,这边就上架。基本是不可能的。
最新型机器的好处,不用说大家都懂。
B.云上资源池的超大规模
前面TOP500我们用的是CPU,再来看看比较难获取的GPU。
2019年11月,SDSC圣地亚哥超级计算中心联合威斯康星州冰立方粒子天体物理中心在AWS,Azure和Google云上一共调度了超过5万GPU完成一次仿真模拟计算试验。
D.迁移成本??
传统场景下,如果企业具备一定本地集群,上云确实需要一定工作量和迁移成本,这包括网络打通、数据、作业、应用迁移和测试等。规模越大,工作量就越大。
但对我们来说,迁移成本极低。我们是原生在云上的,在用户的本地和云上建了一层,只需要考虑数据的流动,不需要考虑整体迁移,成本极低。
机会成本
机会成本:被放弃的选择中的最高价值
资金机会成本
这个钱如果不用在本地建设,花在别的地方能带来什么?
A.云上用最新型机器带来的效率提升,时间周期缩短
本地机器更新周期一般以年为单位,特殊需求可能申请特别审批,时间流程也短不了。像“财大气粗”的云厂商一样,最新型的机器那边上市,这边就上架。基本是不可能的。
最新型机器的好处,不用说大家都懂。
B.云上资源池的超大规模
前面TOP500我们用的是CPU,再来看看比较难获取的GPU。
2019年11月,SDSC圣地亚哥超级计算中心联合威斯康星州冰立方粒子天体物理中心在AWS,Azure和Google云上一共调度了超过5万GPU完成一次仿真模拟计算试验。
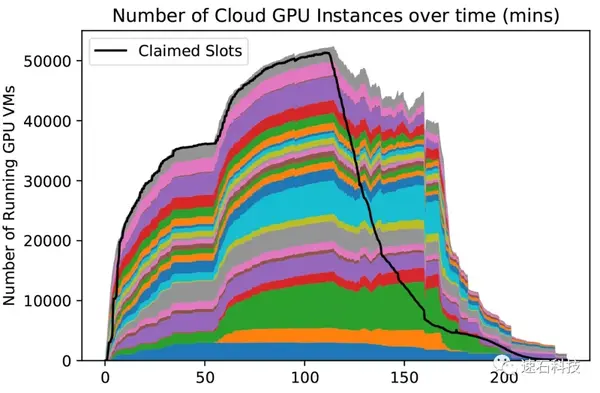 图片来源:Igor Sfiligoi, SDSC/加州大学圣地亚哥分校
这次计算,基于云的集群提供了全球排名第一超算中心峰值90%的性能。
详情看2019-2020春江云暖你先知,CAE/EDA/高校等CloudHPC领域年均复合增长率超21%
C.云上资源类型的多样性,如下图:
图片来源:Igor Sfiligoi, SDSC/加州大学圣地亚哥分校
这次计算,基于云的集群提供了全球排名第一超算中心峰值90%的性能。
详情看2019-2020春江云暖你先知,CAE/EDA/高校等CloudHPC领域年均复合增长率超21%
C.云上资源类型的多样性,如下图:
 时间机会成本
时间机会成本:时间如果省下来,能带来什么?
我们说过,云有一个奇妙的特性:花同样的钱,你可以让100台机器跑1个小时,也可以让1台机器跑100个小时。然后呢?
后半句我们上次没讲。节约的99个小时,你可以做些什么?
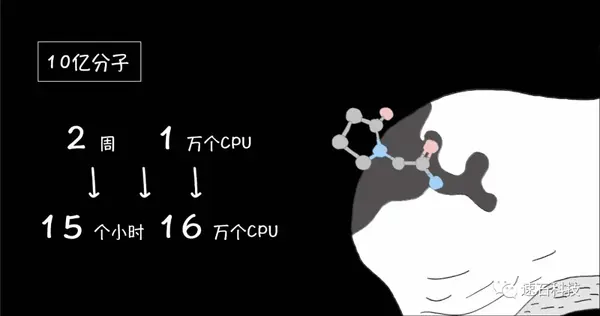
哈佛大学医学院利用云平台,调用16万个CPU对接10亿分子仅耗时15个小时,如果只有1万个CPU则需要两周。具体参考15小时虚拟筛选10亿分子,《Nature》+HMS验证云端新药研发未来
时间机会成本
时间机会成本:时间如果省下来,能带来什么?
我们说过,云有一个奇妙的特性:花同样的钱,你可以让100台机器跑1个小时,也可以让1台机器跑100个小时。然后呢?
后半句我们上次没讲。节约的99个小时,你可以做些什么?
哈佛大学医学院利用云平台,调用16万个CPU对接10亿分子仅耗时15个小时,如果只有1万个CPU则需要两周。具体参考15小时虚拟筛选10亿分子,《Nature》+HMS验证云端新药研发未来
 新药研发耗时长,成本高,一直是行业内公认的。
时间值多少钱,各家药企应该心里有数。
换一个场景,半导体怎么样?
芯片设计越来越复杂,周期和人数都在增加。过去1000人干一年,现在2000人干两年。华为曾向媒体透露7nm的麒麟980研发费用远超业界预估的5亿美元。
而流片出了名的烧钱,越先进工艺流片的风险和费用越高。台积电第二代7nm EUV工艺的流片费用已经是创记录的3000万美元、大概2亿人民币左右。而5nm全光罩流片费用又上涨50%,大概要3亿人民币,而且还不包含IP授权费。
在这里,时间又值多少钱?
预告一下我们即将推出的EDA上云实证:HSPICE仿真任务,如何用云实现周期提升42倍,从1个月缩短至17小时?
新药研发耗时长,成本高,一直是行业内公认的。
时间值多少钱,各家药企应该心里有数。
换一个场景,半导体怎么样?
芯片设计越来越复杂,周期和人数都在增加。过去1000人干一年,现在2000人干两年。华为曾向媒体透露7nm的麒麟980研发费用远超业界预估的5亿美元。
而流片出了名的烧钱,越先进工艺流片的风险和费用越高。台积电第二代7nm EUV工艺的流片费用已经是创记录的3000万美元、大概2亿人民币左右。而5nm全光罩流片费用又上涨50%,大概要3亿人民币,而且还不包含IP授权费。
在这里,时间又值多少钱?
预告一下我们即将推出的EDA上云实证:HSPICE仿真任务,如何用云实现周期提升42倍,从1个月缩短至17小时?
 再算算本地资源采购和建设周期所耗时间,资源不足时,项目进度被延迟的时间,是不是有点心痛。
用这些时间可以换取效率提升,周期缩短,业务扩张,市场领先,技术能力提升。
潜在风险带来的可能损失
云上的安全风险一直是大家最担心问题,没有之一。
安全其实是一个相对概念,边界会随着时间推进而发生变化。就像支付宝刚出现的时候,大家还是只敢把钱放在银行一样。
A.本地的风险和云上的风险,互为半斤八两。
引用一下之前的全球半导体行业上云格局一览和十个上云实践问题的过来人解答,QST和AFRL针对这一问题的回应:
QST:你不可能确保拥有最优秀的IT和最好的安全人员。如果你在本地搭建你的整个设计系统和环境,服务器都在本地,我可以跟你保证你的安全措施肯定是很差的,很容易被外部破解。如果你的IP在云上开发和存储,比如AWS,比如cadence,你知道AWS在云上遵循的安全准则,肯定比在本地要安全多了。
AFRL:尽管我们是云怀疑论者。但大的云厂商在云安全上的控制是对外公开的,每个人都知道你能得到什么,你能够审计一切安全文件。而像跨区域的项目,不同的研究人员分散在不同的地方,还有外包商等等,你很难知道大家各自的IT情况怎么样。而把大家拉到一起,能确保大家在同一个系统里,遵守了同一套准则。而不是制定一套准则,寄希望于他们能按这个标准实施。
B.企业的自建数据中心很难做跨大区域的异地备份,容灾能力有天然瓶颈
C.针对云上安全问题,云安全责任共担模式已在业界达成共识,亚马逊AWS、微软Azure、阿里云,腾讯云等企业均采用了与用户共担风险的安全策略。
云服务提供商负责组建专门团队保护其服务的底层基础设施不受威胁、漏洞、滥用和欺诈的侵害,用户负责安全功能的恰当配置,安装更新和确保雇员不把敏感数据泄露给未授权方等。
潜在机会带来的可能收益
和现在的互联网行业极其相似,云天然具有规模效应和网络效应。
A.规模效应。
规模越大,适配的业务场景越多越深,能提供给用户的福利越丰厚,产品成熟度也越高。
各大云厂商集结了业界顶尖的技术大牛,技术迭代速度非常快,在绝大多数情况下,先进技术转化为产品的效率,要远远高于我们自己研发。
另一方面,产品价格也会越来越便宜。
B.网络效应。
就像微信一样,用的人越多,大家越能从合作中获得更多的便利和好处。比如,机器学习算法相关的非敏感数据共享。
当然,这需要一个过程。
企业现金流
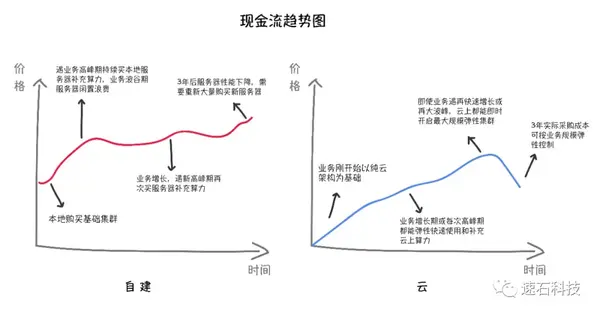
现金流反应了企业经营的健康程度。
本地自建初期需要一次性支出,中间因业务增长需要再补充,然后是硬件整体升级。
云上初期投入小,按使用量付费,整体规模可控。
自建和用云的现金流趋势图如下:
再算算本地资源采购和建设周期所耗时间,资源不足时,项目进度被延迟的时间,是不是有点心痛。
用这些时间可以换取效率提升,周期缩短,业务扩张,市场领先,技术能力提升。
潜在风险带来的可能损失
云上的安全风险一直是大家最担心问题,没有之一。
安全其实是一个相对概念,边界会随着时间推进而发生变化。就像支付宝刚出现的时候,大家还是只敢把钱放在银行一样。
A.本地的风险和云上的风险,互为半斤八两。
引用一下之前的全球半导体行业上云格局一览和十个上云实践问题的过来人解答,QST和AFRL针对这一问题的回应:
QST:你不可能确保拥有最优秀的IT和最好的安全人员。如果你在本地搭建你的整个设计系统和环境,服务器都在本地,我可以跟你保证你的安全措施肯定是很差的,很容易被外部破解。如果你的IP在云上开发和存储,比如AWS,比如cadence,你知道AWS在云上遵循的安全准则,肯定比在本地要安全多了。
AFRL:尽管我们是云怀疑论者。但大的云厂商在云安全上的控制是对外公开的,每个人都知道你能得到什么,你能够审计一切安全文件。而像跨区域的项目,不同的研究人员分散在不同的地方,还有外包商等等,你很难知道大家各自的IT情况怎么样。而把大家拉到一起,能确保大家在同一个系统里,遵守了同一套准则。而不是制定一套准则,寄希望于他们能按这个标准实施。
B.企业的自建数据中心很难做跨大区域的异地备份,容灾能力有天然瓶颈
C.针对云上安全问题,云安全责任共担模式已在业界达成共识,亚马逊AWS、微软Azure、阿里云,腾讯云等企业均采用了与用户共担风险的安全策略。
云服务提供商负责组建专门团队保护其服务的底层基础设施不受威胁、漏洞、滥用和欺诈的侵害,用户负责安全功能的恰当配置,安装更新和确保雇员不把敏感数据泄露给未授权方等。
潜在机会带来的可能收益
和现在的互联网行业极其相似,云天然具有规模效应和网络效应。
A.规模效应。
规模越大,适配的业务场景越多越深,能提供给用户的福利越丰厚,产品成熟度也越高。
各大云厂商集结了业界顶尖的技术大牛,技术迭代速度非常快,在绝大多数情况下,先进技术转化为产品的效率,要远远高于我们自己研发。
另一方面,产品价格也会越来越便宜。
B.网络效应。
就像微信一样,用的人越多,大家越能从合作中获得更多的便利和好处。比如,机器学习算法相关的非敏感数据共享。
当然,这需要一个过程。
企业现金流
现金流反应了企业经营的健康程度。
本地自建初期需要一次性支出,中间因业务增长需要再补充,然后是硬件整体升级。
云上初期投入小,按使用量付费,整体规模可控。
自建和用云的现金流趋势图如下:
 最后,复习一下我们的结论:
1. 企业上云是否便宜取决于具体应用场景;
2. 算账并不是一场本地和云之间的battle,混合云是企业最常用的形态;
3. 云的成本结构高度依赖于自动化和智能化的运营能力;
4. 效率的提升带来TCO的降低才是计算云成本的正确思路。
- END -
2020年新版《六大云厂商资源价格对比工具包》,有兴趣可以扫码添加小F微信(ID: imfastone)获取。
你也许想再了解一下:
15小时虚拟筛选10亿分子,《Nature》+HMS验证云端新药研发未来
【2020新版】六家云厂商价格比较:AWS/阿里云/Azure/Google Cloud/华为云/腾讯云
2019-2020春江云暖你先知,CAE/EDA/高校等CloudHPC领域年均复合增长率超21%
灵魂画师,在线科普多云平台/CMP云管平台/中间件/虚拟化/容器是个啥
花费4小时5500美元,速石科技跻身全球超算TOP500
最后,复习一下我们的结论:
1. 企业上云是否便宜取决于具体应用场景;
2. 算账并不是一场本地和云之间的battle,混合云是企业最常用的形态;
3. 云的成本结构高度依赖于自动化和智能化的运营能力;
4. 效率的提升带来TCO的降低才是计算云成本的正确思路。
- END -
2020年新版《六大云厂商资源价格对比工具包》,有兴趣可以扫码添加小F微信(ID: imfastone)获取。
你也许想再了解一下:
15小时虚拟筛选10亿分子,《Nature》+HMS验证云端新药研发未来
【2020新版】六家云厂商价格比较:AWS/阿里云/Azure/Google Cloud/华为云/腾讯云
2019-2020春江云暖你先知,CAE/EDA/高校等CloudHPC领域年均复合增长率超21%
灵魂画师,在线科普多云平台/CMP云管平台/中间件/虚拟化/容器是个啥
花费4小时5500美元,速石科技跻身全球超算TOP500
速石科技(ID:Fastone_tech) 算力,是一种能力,也是一种资源。 我们为有高算力需求用户提供一站式算力运营解决方案,不局限于HPC,AI,大数据,互联网服务等。希望和你共同建立起不断迭代更新的多云世界观。 (你要是唠这个我就不困了。)
标签:浪费,上云,资源,本地,解惑,云上,成本,CXO 来源: https://www.cnblogs.com/fastone/p/13396096.html