使用GPU Instancing屏幕花屏问题
作者:互联网
1)使用GPU Instancing屏幕花屏问题
2)如何优化AssetBundle大小
3)如何使用GPU Skinning提升性能
4)iOS上Shader里tex2D采样偏移的问题
5)如何管理销毁拍摄的内置深度图
GPU Instancing
Q:机器:魅族MX5
Unity版本:2019.1.5f1
渲染设置:OpenGL ES3,Dynamic Batching,GPU Instancing
问题表现:场景有时候会突然花屏随机闪烁, 通过排除法发现是在渲染其中一个树的时候导致的(树的材质勾选了GPU Instancing,只要不渲染这个树就不闪烁)。

尝试改变渲染设置:仅关闭动态批处理或者GPU Instancing就都不花屏了, 两者同时存在就会花屏。
不知道这是Unity的Bug还是魅族机器有问题。
A:根据题主提供的信息,我们做了以下尝试。
测试机:魅族5;对比测试机:小米6
测试场景:客户提供测试现象:
魅族5开启了Dynamic和Instancing,会花屏,UBO数组长度为2,有Log报错。小米6和OPPO K1均不花屏,UBO数组长度均为128,无Log报错。
魅族5在RenderDoc的数据:
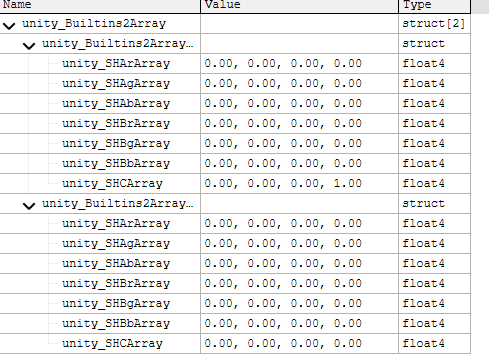
当开启GPU Instancing的时候,在Vertex Shader里面会有2个UBO(Uniform Buffer Object)。
它们的内容分别如下:
第一个记录的是SH函数的系数,第二个是每个Instance的变换矩阵。
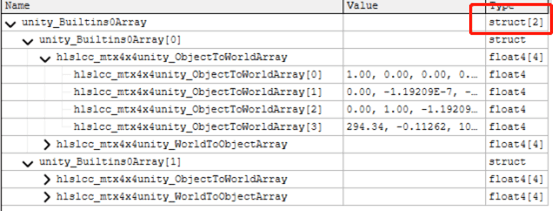
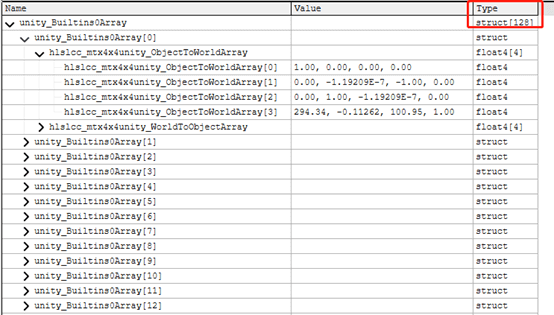
在魅族5上面数组长度为2,可以理解为魅族5不支持Instance。而在小米6和OPPO K1,是支持128个Instance的,如下图所示:
说明它们是支持Instancing的。
在移动平台上,一个Buffer的大小上限是16KB,一个Instance需要记录ObjectToWorld和WorldToObject的矩阵,总共是16x4x2=128 Byte,所以总的Instance上限数量是16x1024 Byte/128 Byte = 128。
从RenderDoc上的信息里面可以看到确实是长度为128的数组,而在魅族5上面只有2。
而且在魅族5上面运行测试场景的时候,通过Logcat可以看到会有报错的Log:
GLSL: unexpected struct parameter 'unity_Builtins2Array1.unity_SHCArray’
GLSL:unexpected struct parameter 'unity_Builtins0Array1.hlslcc_mtx4x4unity_WorldToObjectArray[这两个正是Instancing需要的UBO里面的数据。
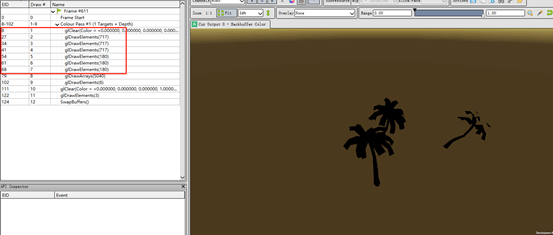
还有一点需要说明的是,在测试场景中,使用的是239个三角形的那个Mesh,在魅族5上面同样会花屏。不论有没有开启Dynamic Batching,都会有上面的报错,所以本质上是魅族5不支持Instancing导致的。
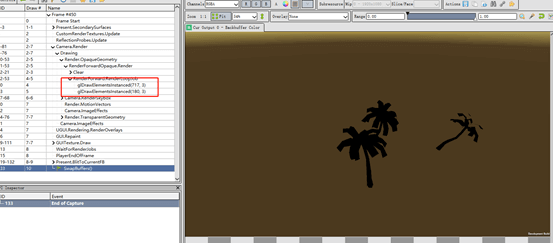
创建了一个场景,场景中有3棵相同的树,而且开始了Instancing,可以看到OpenGL使用的接口是glDrawElements。
在小米6上调用的接口是glDrawElementsInstannced,如下图:
没有对模拟器进行测试,理论上是一样的情况。



该回答由UWA提供
Asset
Q:我们AssetBundle超过3.8G了,也做了分类,但是资源太多导致总大小超过3.8G,很多玩家安装不上。有没有相关解决思路?
A1:随着硬件的发展,玩家对画质要求的提高,基本上包体越来越大是必然的,关键还是看大的是否合理,基本上可以顺着几个点去检查下。
(1)首先使用UWA的资源检测工具看下是否AssetBundle内重复资源过多,如果有,可以根据检测结果调整,并定期提交UWA测试。
(2)配合一些资源分析的工具在编辑器内人工的工程内部资源大致过一遍,看看是否有冗余的资源。这点还是很常见的,随着游戏开发版本不断迭代,经常会出现之前做的一些东西被推翻了或者大改了(策划或美术需要),这时候就会产生一些资源可能没有被用到但是仍然留在工程中,如果打包时没有相应地去掉,就会有无用的资源进版。
(3)检查资源导入是否合理。比如:贴图是否使用了正确的压缩格式,动画文件是否进行了合理的压缩,打图集是否合理,图集里是否有大量的浪费等等。
(4)如果经过检查仍然没有什么进展,那只能说你们的项目真的需要这么大的资源包,为了让用户能有较好的游戏体验,可以根据伟昊说的,规划一部分资源在启动后下载。这块可以结合产品需要,做成启动后一次性下载完或者根据游戏进程一部分一部分下载。
感谢范君@UWA问答社区提供了回答
A2:说一个资源重复可能有些人没注意到的点,就是同一份资源经常被改名放到不同的地方被不同的资源引用,经过实际检测,这个重复量大过了我的预测,大家可以自测一下自己的项目。
感谢noah@UWA问答社区提供了回答
动画
Q:我们的游戏参考了UWA Blog上的那篇《GPU Skinning加速骨骼动画》,发现真机环境帧数提升不是很明显,连上Profiler发现开启/关闭GPU Skinning总批次居然没啥变化,SetPass Calls倒是变化明显,在编辑器切到Android平台我测试过总批次会提升100+,有点奇怪为什么到了Android真机里没什么变化?
PS:原来角色动画Animator + SkinMeshRenderer,使用GPU Skinning后换成了MeshRenderer同时把Animator勾去掉的。
A:可汗文章中单纯的GPU Skinning并不是去降低渲染Draw Call的,只有结合GPU Instancing才会降低Draw Call。GPU Skinning最主要降低的是Animators.Update和MeshSkinning.Update的耗时,如果在使用后,你发现这两个值没有变化或者优化不大,那么十有八九是用法不对。
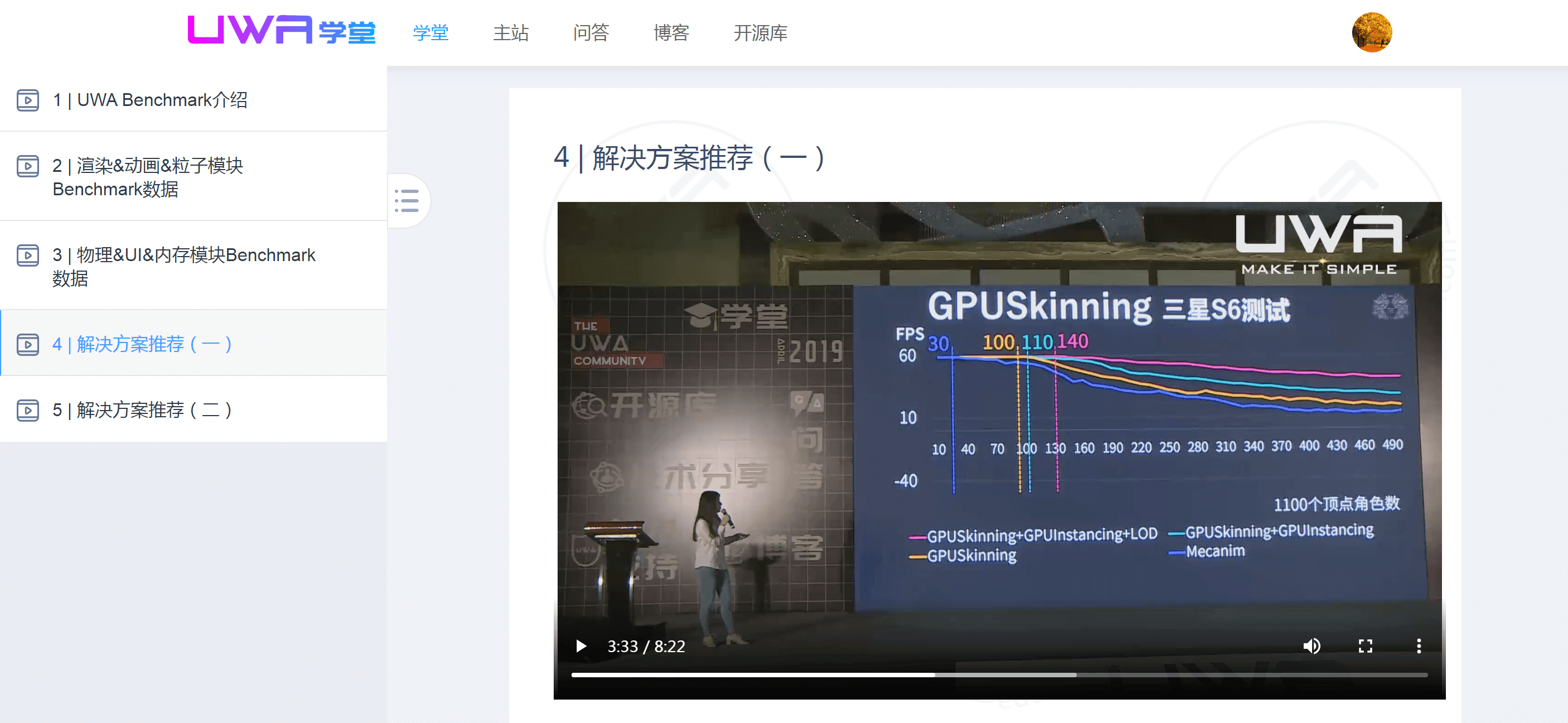
下图是我们在UWA DAY 2019《如何根据UWA制定技术选型》时做的具体的性能测试,里面讲解了多种不同方法所能达到的收益和限制,题主有兴趣可以详细查看。
同时,我们将之前做过的一些定量测试放在这里,希望大家对于GPU Skinning带来的性能改变有更为定量的理解。
通过GPU Skinning方式
该方法是完全摒弃Unity引擎的MeshSkinning和Animator模块,自行对蒙皮网格进行采样,将骨骼结点的矩阵信息以纹理的方式进行储存,然后在GPU中完成顶点计算并直接进行渲染。优点在于极大地降低SkinnedMesh.Update和Animator.Update的CPU占用。将骨骼结点信息通过纹理来进行储存,因而数据量较之方案儿会大为降低。
开源库下载链接:
https://lab.uwa4d.com/lab/5bc6f85504617c5805d4eb0a测试场景:
创建相同案例,场景模型数量分别为50和200,各自测试1000帧,播放Walk动画。结果:
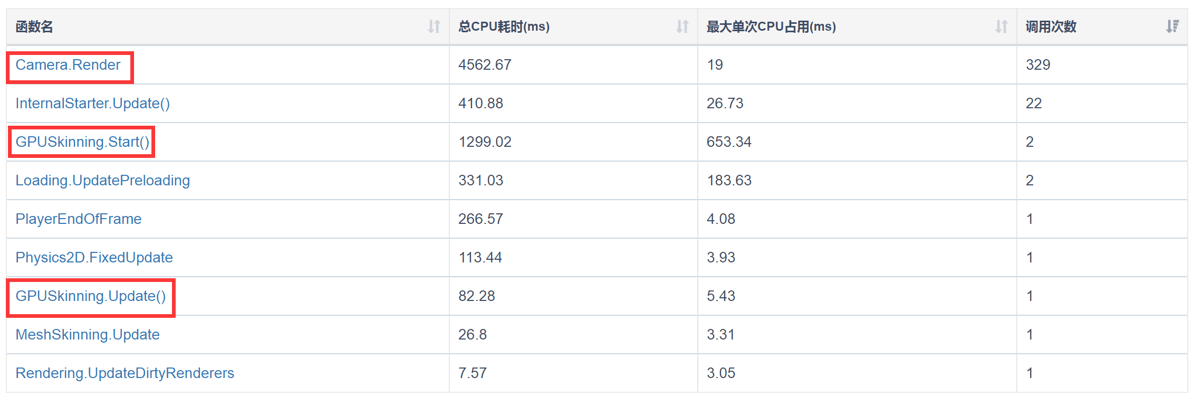
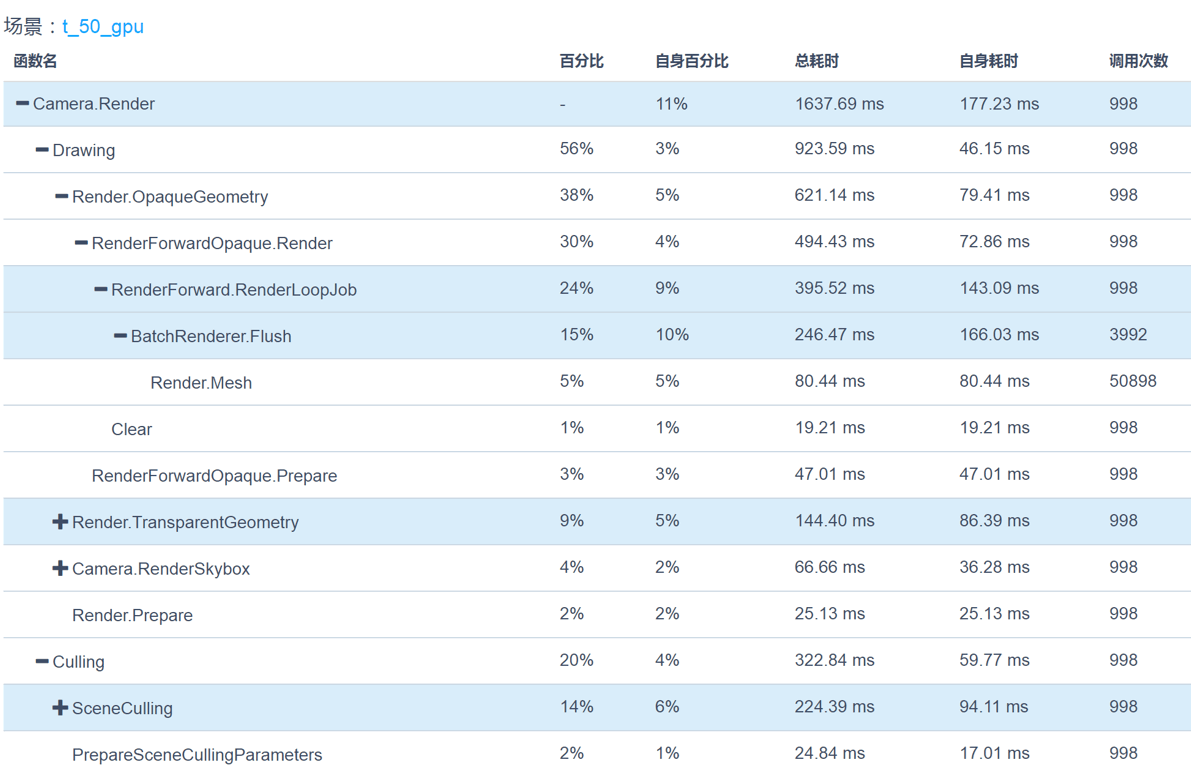
该方案测试效率如下图所示,除Camera.Render外,MeshSkinning.Update和Animator.Update已经消失,但增加了GPUSkinning.Start和GPUSkinning.Update函数。通过分析可知,在红米Note2设备上,开启多线程渲染功能,测试帧数总计1000帧,50个模型的CPU平均耗时0.6ms;200个模型的CPU平均耗时1.6ms。
图1:使用GPU Skinning方案后,红米Note2上的Top10 CPU占用情况
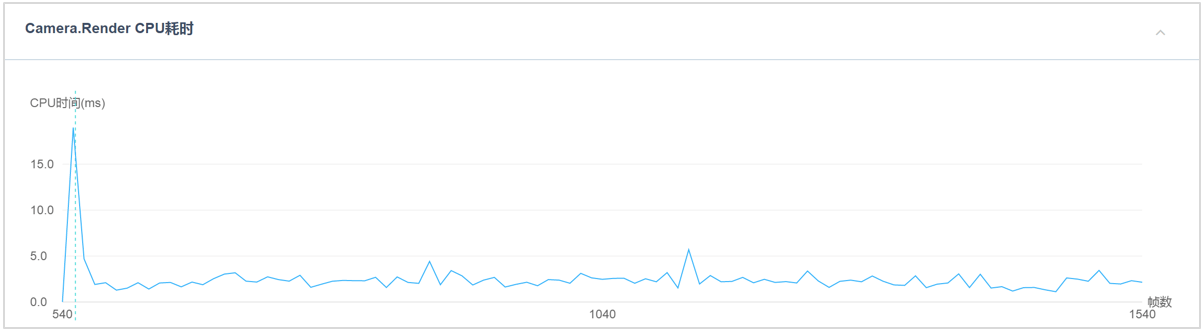
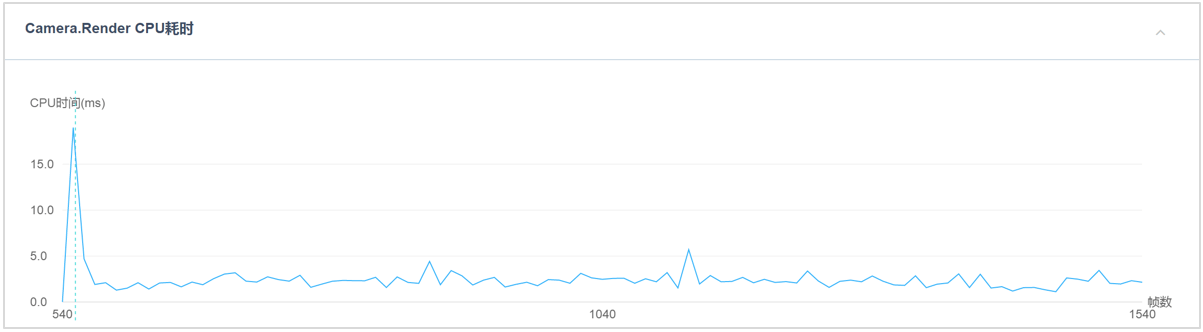
使用GPU Skinning方案后,红米Note2上的Camera.Render耗时情况。
图2:50个模型
图3:200个模型
使用GPU Skinning方案后,红米Note2上的50个模型时的Camera.Render耗时情况。
图4
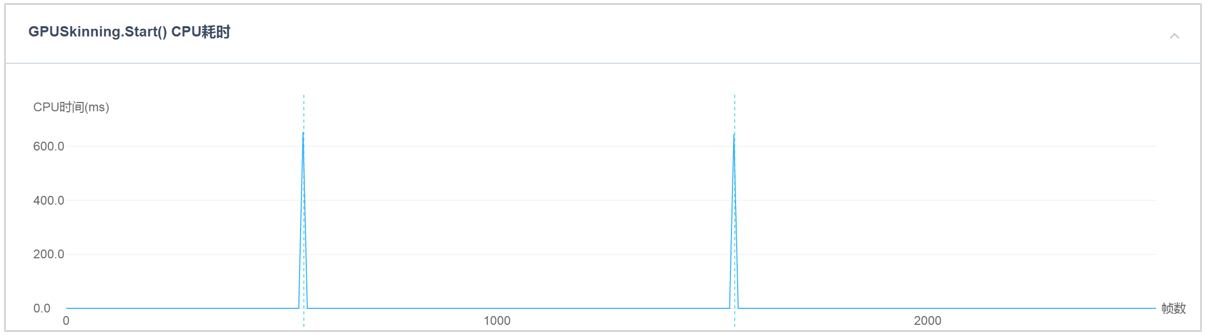
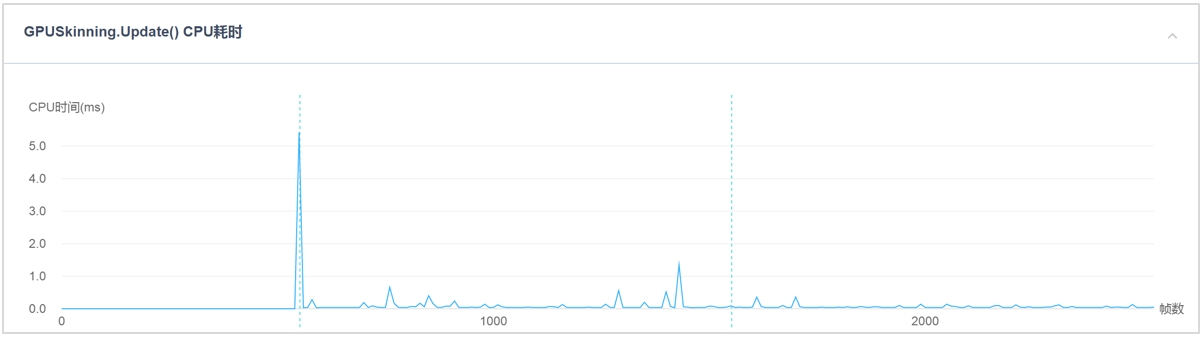
同时,GPU Skinning.Start和GPU Skinning.Update耗时在游戏运行过程中很小,如图5所示。
图5:GPU Skinning.Start和GPU Skinning.Update耗时在游戏运行过程中的CPU耗时
总结:
(1)该方案可以大幅降低Animators.Update和MeshSkinning.Update的CPU耗时,同时内存占用较小小。以r_gunman模型为例,其所有动画文件时长8秒,如果采样率为30fps时,通过纹理来进行记录,只需要128x128的纹理即可得到更为精细的动画数据;
(2)该方案对于GPU的压力更大,需要研发团队对GPU方面的压力进行进一步权衡。

该回答由UWA提供
Render
Q:我是用世界坐标去采样一张Filter Mode为Point的纹理,PC和Android真机上采样是正确的,Mac和iPhone7/7Plus上采样结果产生了偏移。
PC上的截图(分别为输出UV和输出采样结果):
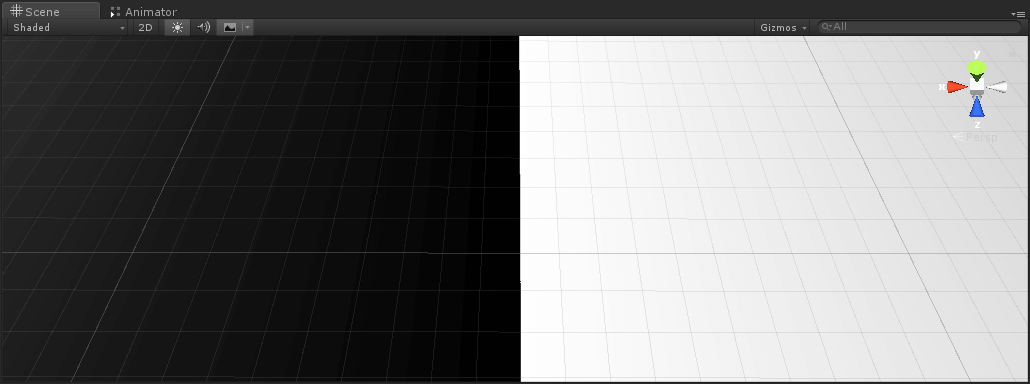
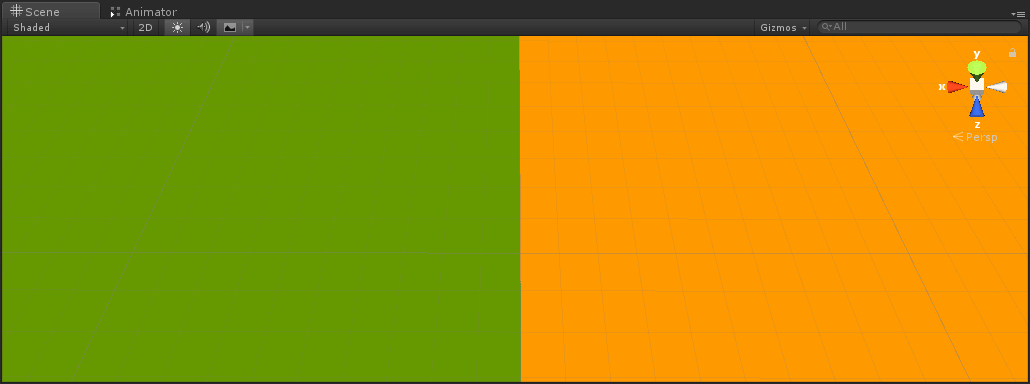
Mac上的截图:
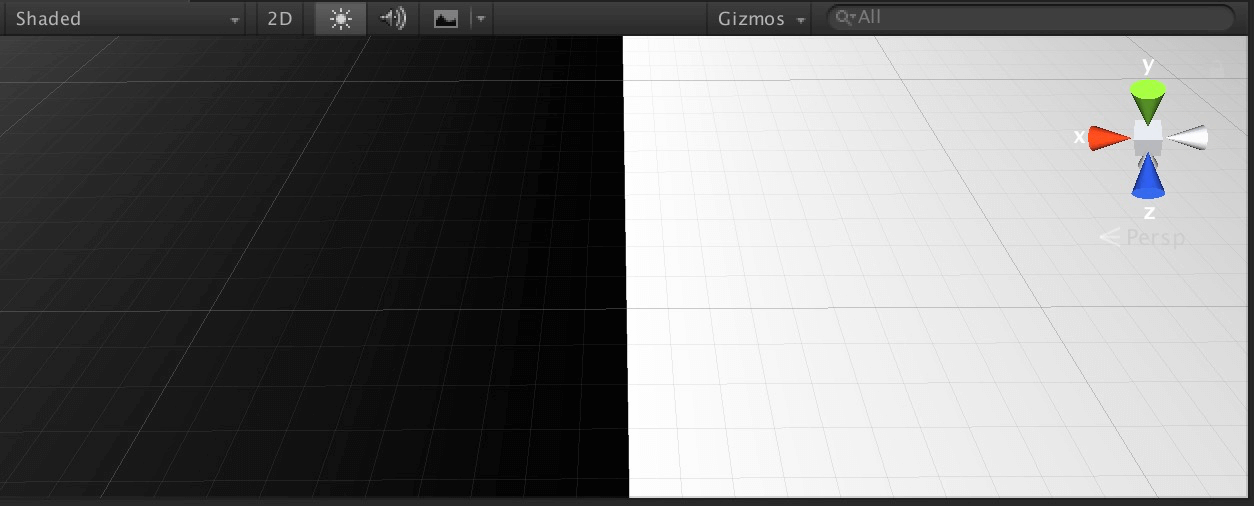
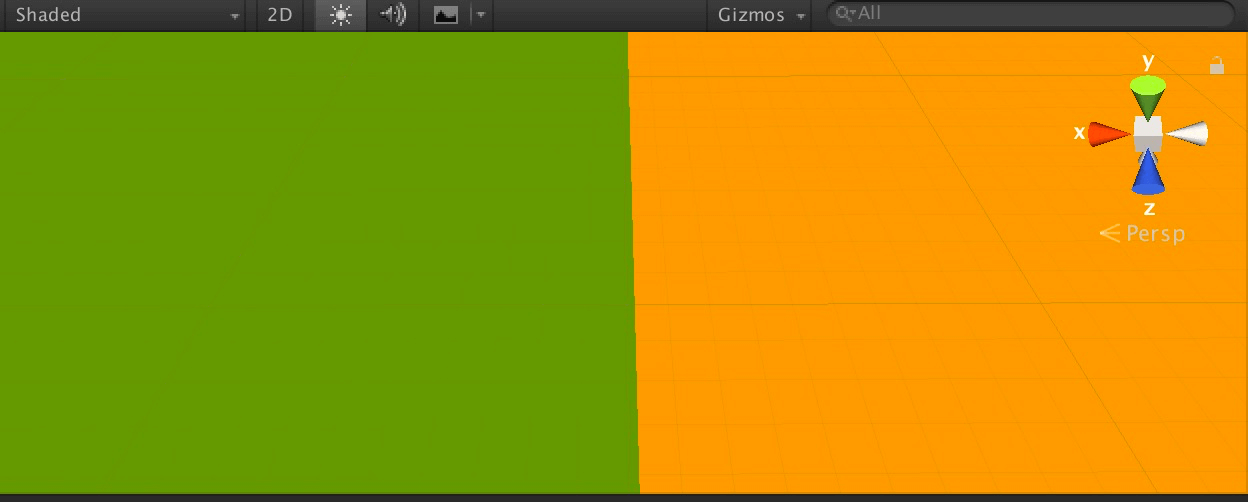
注意看网格线的对比,Mac上的采样图出现了偏移,但UV是正确的(为了方便观察,UV进行了缩放,采样是用未缩放的UV)。

有人碰到过类似的问题吗?怎么处理的?
A1:问题根源并没有找到,目前采用了一个取巧的方案绕过该问题。
原本需求就是用世界坐标采样一张Filter Mode 为Point 的纹理,因此直接在Shader中棋盘化采样点,伪代码:
float2 uv = floor(worldPos.xz / rectSize) / texSize.xy + 1.0 / (3.0 * texSize.xy);
(rectSize 为棋盘格子的大小;texSize 为采样图的大小)
最后加的那个值(1.0 / (3.0 * texSize.xy))是测试发现如果没有该值,PC采样结果和Mac下会有偏差,因此加上了三分之一个单位的偏移。
感谢珂@UWA问答社区提供了回答
A2:应该和这个问题类似吧,不过half pixel offset好像是bilinear filter才会有的,point可能也有不同平台采样结果不一样的问题。
https://docs.microsoft.com/zh-cn/windows/win32/direct3d9/nearest-point-sampling
可以看看上面两个链接有没有帮助。
感谢noah@UWA问答社区提供了回答
RenderTexture
Q:在同一个场景我先后使用不同的摄像机不同的角度拍摄深度,那么应该得到多张不同的深度图,我想了解Unity对这多张深度图是怎么管理的?比如:我只保留其中一张,其它的深度图都不需要了,我该怎么处理?
A:Unity默认渲染管线是多相机共享RenderTexture的方式,即多个相机逐一使用公共的CameraDepthRenderTexture绘制,每个相机绘制完是否Clear,取决于你下一个相机的ClearMode。至于RenderTexture的内存分配和管理,与你所有的相机是否开启绘制深度有关,全部关掉绘制深度底层会释放掉RenderTexture。如果要保留一张给下一帧使用,那么建议拷贝出来,这样不会影响下一帧其它相机使用。
感谢Wangtao@UWA问答社区提供了回答
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:793972859(原群已满员)
标签:采样,Update,Skinning,花屏,GPU,UWA,Instancing 来源: https://www.cnblogs.com/uwatechnologies/p/12625088.html