BiLSTM-CRF模型理解
作者:互联网
适用任务
中文分词、词性标注、命名实体识别是自然语言理解中,基础性的工作,同时也是非常重要的工作。
在很多NLP的项目中,工作开始之前都要经过这三者中的一到多项工作的处理。
在深度学习中,有一种模型可以同时胜任这三种工作,而且效果还很不错--那就是biLSTM_CRF。
biLSTM,指的是双向LSTM;CRF指的是条件随机场。
一些说明
以命名实体识别为例,我们规定在数据集中有两类实体,人名和组织机构名称。所以,其实在我们的数据集中总共有5类标签:
B-Person (人名的开始部分)
I- Person (人名的中间部分)
B-Organization (组织机构的开始部分)
I-Organization (组织机构的中间部分)
O (非实体信息)
此外,假设x 是包含了5个单词的一句话(w0,w1,w2,w3,w4)。在句子x中[w0,w1]是人名,[w3]是组织机构名称,其他都是“O”。
BiLSTM-CRF 模型
先来简要的介绍一下该模型。
如下图所示:
首先,句中的每个单词是一条包含词嵌入和字嵌入的词向量,词嵌入通常是事先训练好的,字嵌入则是随机初始化的。所有的嵌入都会随着训练的迭代过程被调整。
其次,BiLSTM-CRF的输入是词嵌入向量,输出是每个单词对应的预测标签。
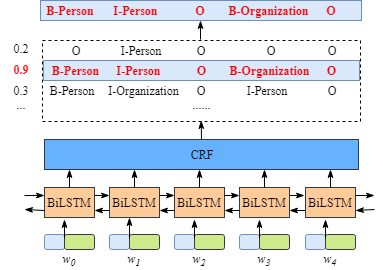
尽管不需要了解BiLSTM的实现细节,但为了更好的理解CRF层,我们还是需要知道一下BiLSTM的输出到底是什么意思。
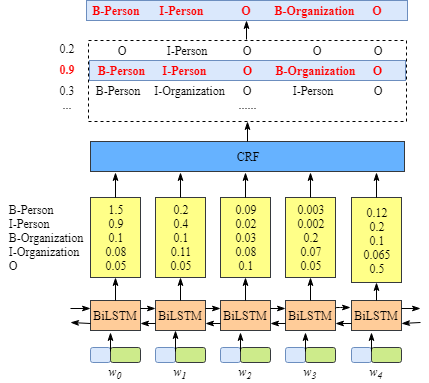
如上图所示,BiLSTM层的输入表示该单词对应各个类别的分数。如W0,BiLSTM节点的输出是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) and 0.05 (O)。这些分数将会是CRF层的输入。
所有的经BiLSTM层输出的分数将作为CRF层的输入,类别序列中分数最高的类别就是我们预测的最终结果。
标签:人名,嵌入,BiLSTM,模型,Person,CRF,Organization 来源: https://www.cnblogs.com/shona/p/11563112.html