马蜂窝推荐系统容灾缓存服务的设计与实现
作者:互联网
数据库突然断开连接、第三方接口迟迟不返回结果、高峰期网络发生抖动… 当程序突发异常时,我们的应用可以告诉调用方或者用户「对不起,服务器出了点问题」;或者找到更好的方式,达到提升用户体验的目的。
一、背景
用户在马蜂窝 App 上「刷刷刷」时,推荐系统需要持续给用户推荐可能感兴趣的内容,主要分为根据用户特性和业务场景,召回根据各种机器学习算法计算过的内容,然后对这些内容进行排序后返回给前端这几个步骤。
推荐的过程涉及到 MySQL 和 Redis 查询、REST 服务调用、数据处理等一系列操作。对于推荐系统来说,对时延的要求比较高。马蜂窝推荐系统对于请求的平均处理时延要求在 10ms 级别,时延的 99 线保持在 1s 以内。

当外部或者内部系统出现异常时,推荐系统就无法在限定时间内返回数据给到前端,导致用户刷不出来新内容,影响用户体验。
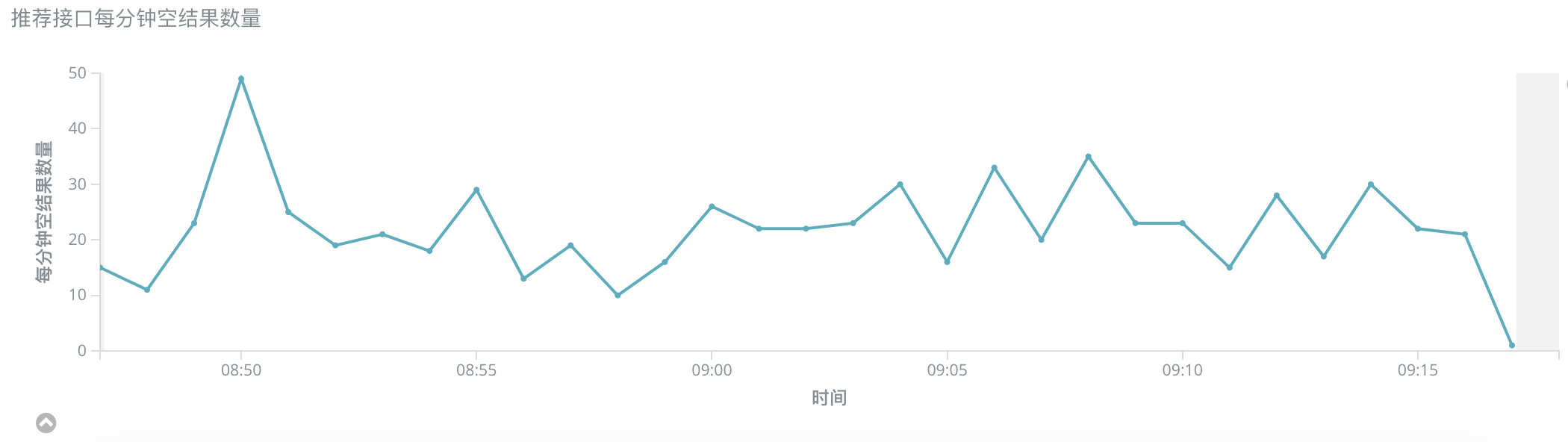
所以我们希望通过设计一套容灾缓存服务,实现在应用本身或者依赖的服务发生超时等异常情况时,可以返回缓存数据给到前端和用户,来减少空结果数量,并且保证这些数据尽可能是用户感兴趣的。
二、设计与实现
设计思路和技术选型
不仅仅是推荐系统,缓存技术在很多系统中已经被广泛应用,小到 JVM 中的常用整型数,大到网站用户的 session 状态。缓存的目的不尽相同,有些是为了提高效率,有些是为了备份;缓存的要求也高低不一,有些要求一致性,有些则没有要求。我们需要根据业务场景选择合适的缓存方案。
结合到我们上面提到的业务场景和需求,我们采用了基于 OHC 堆外缓存和 SpringBoot 的方案,实现在现有推荐系统中增加本地容灾缓存系统。主要是考虑到以下几点因素:
1. 避免影响线上服务,将业务逻辑和缓存逻辑隔离
为了不影响线上服务,我们将缓存系统封装为一个 CacheService,配置在现有流程的末端,并提供读、写的 API 给外部调用,将业务逻辑和缓存逻辑隔离。
2. 异步写入缓存,提高性能
读、写缓存都会带来时间消耗,特别是写入缓存。为了提高性能,我们考虑将写入缓存做成异步的方式。这部分使用的是 JDK 提供的线程池 ThreadPoolExecutor 来实现,主线程只需要提交任务到线程池,由线程池里的 Worker 线程实现写入缓存。
3. 本地缓存,提高访问速度
在推荐系统中,给用户推荐的内容应该是千人千面的,甚至同一位用户每次刷新看到的内容都可能不同,这就不要求缓存具有强一致性。因此,我们只需要进行本地缓存,而不需要采用分布式的方式。这里使用到的是开源缓存工具 OHC,缓存的数据来源于成功处理过的请求。
4. 备份缓存实例,保证可用性
为了保证缓存的可用性,我们不仅在内存中进行缓存,还定时备份到文件系统中,从而保证在可以应用启动时从文件系统加载到内存。具体可以使用 SpringBoot 提供的定时任务、ApplicationRunner 来实现。
整体架构
我们保持了推荐系统的现有逻辑,并在现有流程的末端,配置了 CacheModule 和 CacheService,负责所有和缓存相关的逻辑。
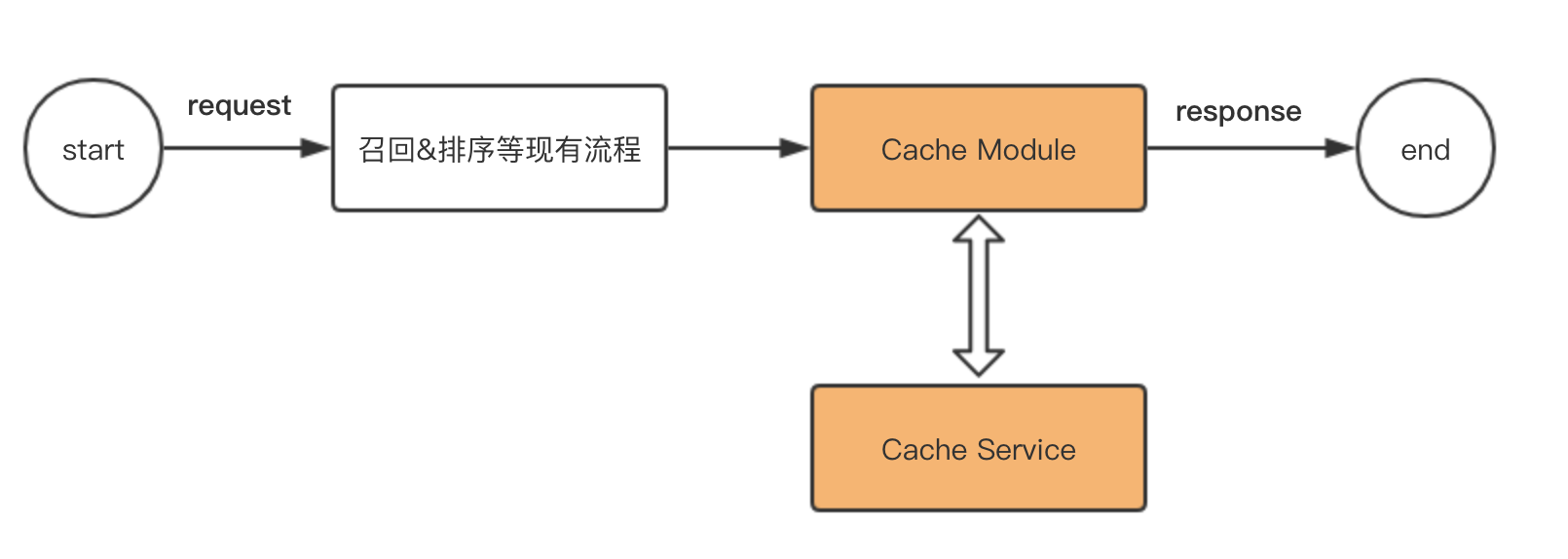
其中,CacheService 是缓存的具体实现,提供读写接口;CacheModule 对本次请求的数据进行处理,并决定是否需要调用 CacheService 对缓存进行操作。
模块解读
1. CacheModule
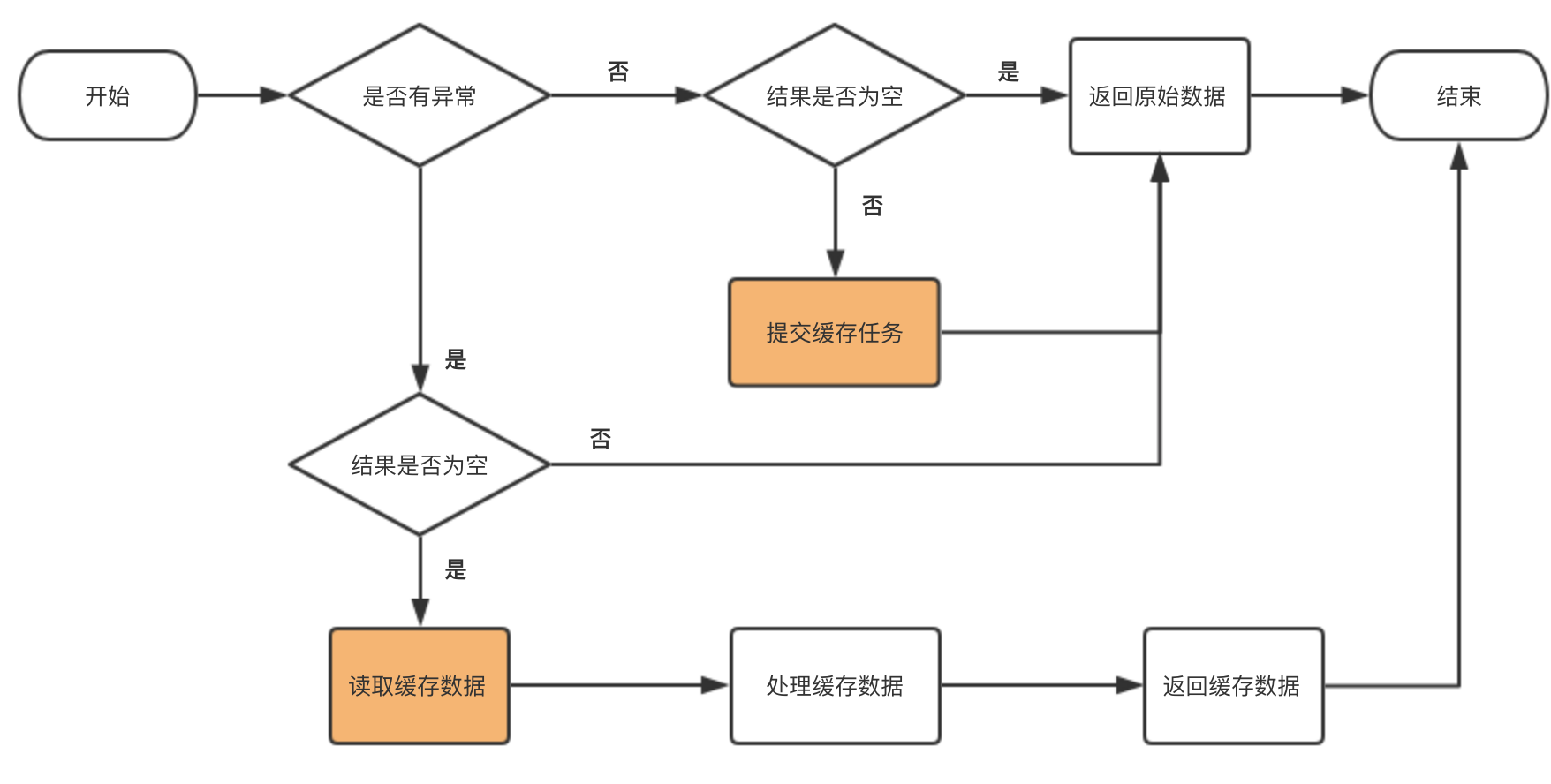
在完成推荐系统的原有流程处理之后,CacheModule 会对得到的响应报文进行判断,比如是否抛出了异常,响应是否为空等,然后决定是否读取缓存或者提交缓存任务。
CacheModule 的工作流程如图所示,其中橘黄色部分代表对 CacheService 的调用:
-
提交缓存任务。如果该次请求没有抛出异常,并且响应结果也不为空,则会提交一个缓存任务到 CacheService。任务的 key 值为对应的业务场景,value 为本次响应计算得到的内容。提交的动作是非阻塞的,对接口的耗时影响很小。
-
读取缓存数据。当应用本身或者依赖应用抛出异常时,系统会根据业务场景的 key 值从 CacheService 中读取缓存并返回给调用方。当出现用户本身已经刷完所有可用数据的情况时,就不需要读取缓存,而是将请求的数据及时反馈给用户。
2. CacheService
在缓存的具体实现上,CacheService 使用到了从 Apache Cassandra 项目中独立出来的 OHC。另外因为我们整个应用是基于 SpringBoot 的,也用到了 SpringBoot 提供的各种功能。
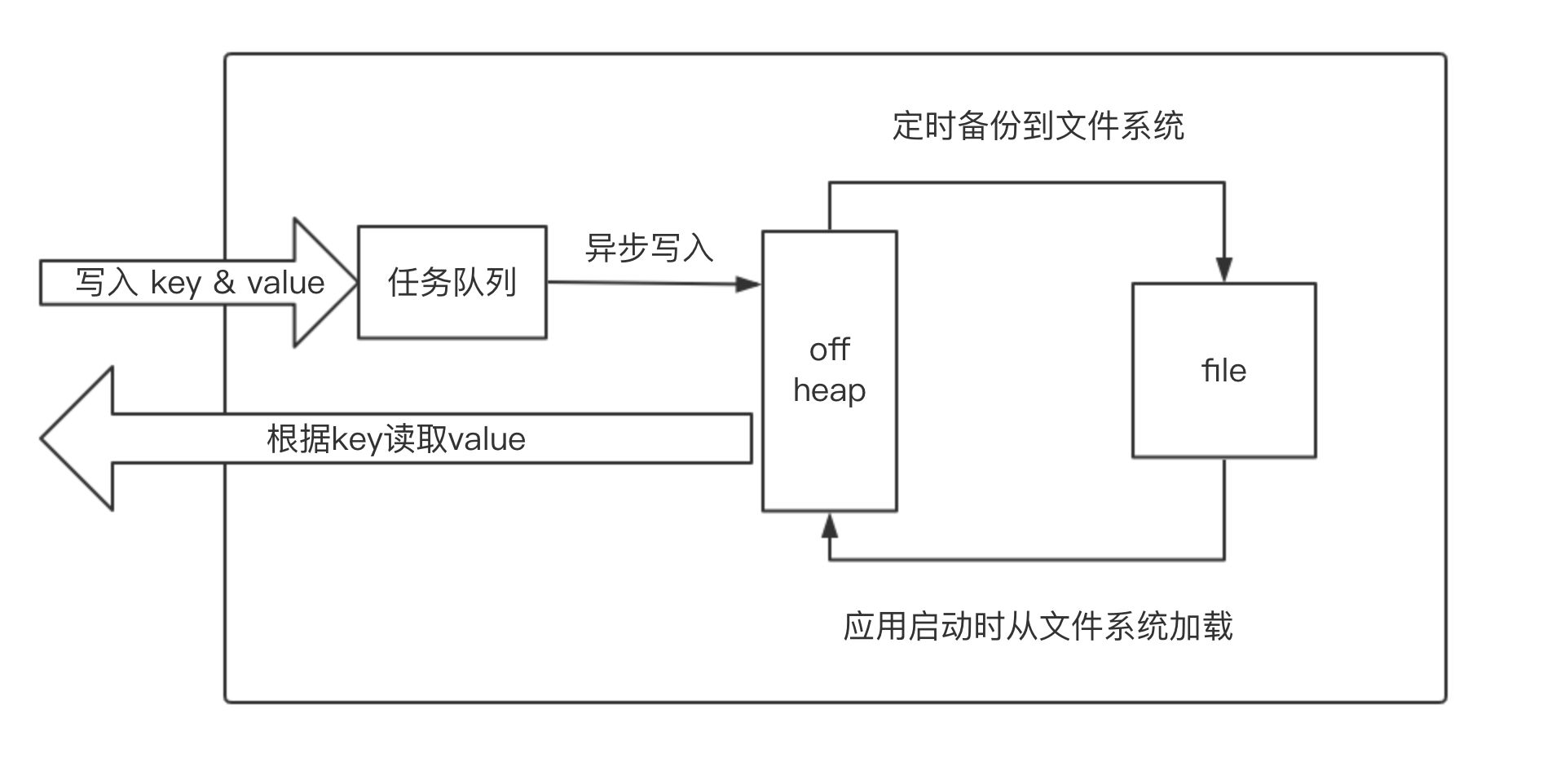
上文说到对缓存没有强一致性的要求,所以我们采用的是本地缓存而非分布式缓存,并且抽象出一个 CacheService 类负责对本地缓存进行维护。
(1) 数据格式
推荐系统返回数据时,根据业务场景和用户特征设定以「屏」为单位返回数据,每屏可以包含多个内容项,所以采取 key-set 的数据格式:key 值为业务场景,比如首页的「视频」频道;缓存内容则为「屏」的集合。
(2) 存储位置
对于 Java 应用,缓存可以存放在内存中或者硬盘文件中。而内存空间又分为 heap(堆内存)和 off-heap(堆外内存)。我们对这几种方式进行了对比:

为了保证较快的读写速度,避免缓存 GC 影响线上服务,所以选择 off-heap 作为缓存空间。OHC 最早包含在 Apache Cassandra 项目中,之后独立出来,成为了基于 off-heap 的开源缓存工具。它既可以维护大量的 off-heap 内存空间,同时也使用于低开销的小型缓存实体。所以我们使用 OHC 作为 off-heap 的缓存实现。
(3) 文件备份
在应用重启时,off-heap 中的缓存为空。为了尽快载入缓存,我们使用 SpringBoot 的 Scheduling Tasks 功能,定期将缓存从 off-heap 备份到文件系统;通过继承 SpringBoot 的 ApplicationRunner 监听应用启动的过程,启动完成后将硬盘中的备份文件加载到 off-heap,保证缓存数据的可用性。
CacheService 维护一个任务队列,队列中保存着 CacheModule 通过非阻塞的方式提交的缓存任务,由 CacheService 决定是否要执行这些缓存任务。
(4) 对 CacheModule 提供的 API
-
读取缓存时,传入 key 值,缓存模块随机从 set 中读取数据返回。
-
写入缓存时,将 key 和 value 封装为一个任务,提交到任务队列,由任务队列负责异步写入缓存。
(5) 任务队列与异步写入
这里我们使用了 JDK 中的线程池来实现。在构造线程池时,使用 LinkedBlockingQueue 作为任务队列,可以实现快速增删元素;因为应用的 QPS 在 100 以内,所以工作线程数目固定为 1;队列写满之后,则执行 DiscardPolicy,放弃插入队列。
(6) 缓存数量控制
如果缓存占用内存空间过大,会影响线上应用,我们可以采用为不同的业务场景配置最大缓存数量来控制缓存数量。没有达到配置值时,将成功处理过的数据写入缓存;达到配置值时可以随机抽样覆盖原有缓存项,来保证缓存的实时性。
综合考虑以上各个方面,CacheService 的设计如下:
线上表现
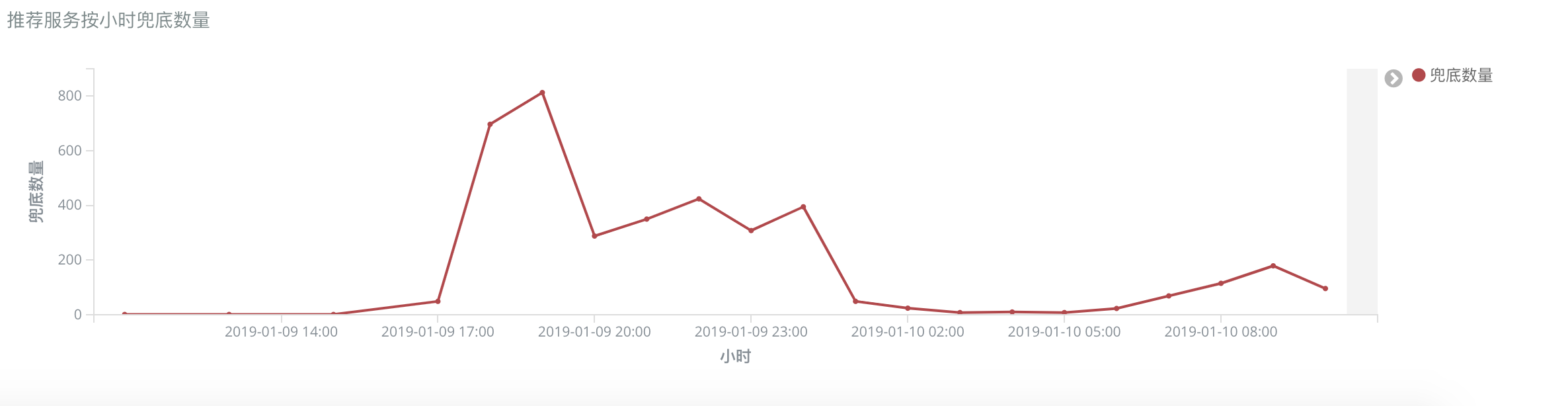
为了验证容灾缓存的效果,我们在命中缓存时进行了埋点,并通过 Kibana 查看每小时缓存的命中数量。如图所示,在 18:00 到 19:00 系统存在一定的超时,而这段时间由于缓存服务发挥了作用,使系统的可用性得到提升。
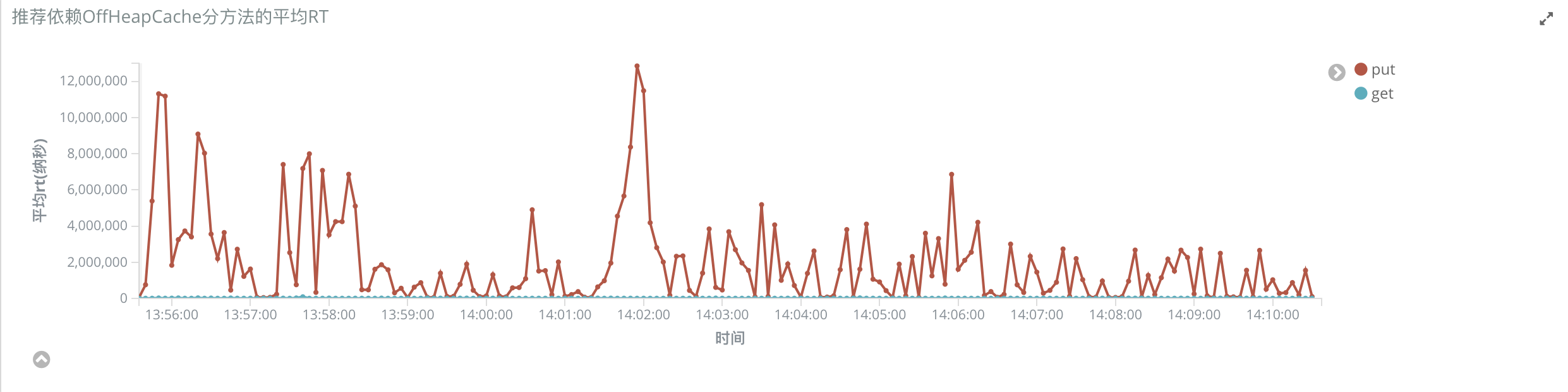
我们还对 OHC 的读取和写入速度进行了监控。写入缓存的时延在毫秒级别,并且是异步写入;读取缓存的时延在微秒级别。基本没有给系统增加额外的时间消耗。
踩过的坑
在将缓存写入 OHC 之前,需要进行序列化,我们使用了开源的 kryo 作为序列化工具。之前在使用 kyro 时,发现对于没有实现 Serializable 的类,反序列化时可能失败,比如使用 List#subList 方法返回的内部类 java.util.ArrayList$SubList。这里可以手动注册 Serializer 来解决这个问题,在 Github 上开源的 kryo-serializers 仓库提供了各种类型的 serializers。
另外一点,需要注意根据具体使用场景,来配置 OHC 中的 capacity 和 maxEntrySize。如果配置的值太小的话,会导致写入缓存失败。可以在上线之前测算缓存的空间占用,合理设置整个缓存空间的大小和每个缓存 entry 的大小。
三、优化方向
基于 SpringBoot 和 OHC,我们在现有的推荐系统中增加了一个本地容灾缓存系统,当依赖服务或者应用本身突发异常时可以返回缓存的数据。
该缓存系统还存在一些不足,我们近期会针对以下几点进行重点优化:
-
缓存数目写满之后,目前应用会随机覆写已经存在的缓存。未来可以进行优化,将最老的缓存项替换。
-
在某些场景下缓存的粒度不够精细,比如目的地页推荐共用一个缓存的 key 值。未来可以根据目的地的 ID,为每个目的地配置一份缓存。
-
现在推荐系统还有部分配置依赖于 MySQL,未来会考虑将在本地进行文件缓存。
[参考资料]
1. Java Caching Benchmarks 2016 - Part 1
2. On Heap vs Off Heap Memory Usage
本文作者:孙兴斌,马蜂窝推荐和搜索后端研发工程师。
(马蜂窝技术原创内容,转载务必注明出处保存文末二维码图片,谢谢配合。)

标签:缓存,CacheService,马蜂窝,写入,OHC,系统,heap,容灾 来源: https://blog.csdn.net/weixin_43846997/article/details/90377423