列联表和卡方检验——统计学(九)
作者:互联网
人们在研究某一个事物或现象的过程中,有些时候不只考察单独某一方面的信息,即可以把几个方面的信息联合起来一并考察。这个过程称为交叉分析。列联分析和对应分析就是交叉分析的两种典型形式,同时也是数据降维分析的一种形式。
一、列联分析
对于定类或定序等定性数据的描述和分析,通常可使用列联表进行分析。本此主要介绍基于列联表\(\chi^2\) 检验的列联分析。并且在此基础之上进行独立性检验、关联度测量以及相关数据的可视化。
两个或两个以上变量交叉形成的二维频数分布表格,称之为列联表
列联表中变量的属性或取值通常也叫做水平,列联表行变量的水平个数一般用 R 表示,列变量水平的个数一般用 C表示,一个 R 行 C 列的频数分布表叫做 \(R\times C\) 列联表。
\(R\times C\) 列联表中各元素 $f_{ij} $就是行列变量进行交叉分类得到的观测值个数所形成的频数分布,行合计表示行变量每个水平在列变量不同水平交叉分类的观测值总数;列合计表示列变量每个水平在行变量不同水平交叉分类的观测值总数;行合计加总应当等于列合计加总,记为总计频数。
二、\(\chi^2\) 分布与检验
列联表的分布主要有观测值分布和期望值分布,同时也计算了观测值和期望值之间的偏差。设 \(f_{ij}^o\)表示各交叉分类频数的观测值,$f_{ij}^e $表示各交叉分类频数的期望值,则各交叉分类频数观测值与期望值的偏差为 $$\f_{ij}o-f_{ij}e $$,则 $\chi^2 $统计量为
\[\\chi^2 = \\sum\_{i=1}^{r}\\sum\_{j=1}^{c} \\frac{(f\_{ij}^o-f\_{ij}^e)^2}{f\_{ij}^e} \]当样本量较大时,χ2χ2\chi^2 统计量近似服从自由度为 (R−1)(C−1)(R−1)(C−1)(R-1)(C-1) 的 χ2χ2\chi^2 分布,χ2χ2\chi2值与期望值、观测值和期望值之差均有关,χ2χ2\chi2值越大表明观测值与期望值的差异越大。
χ2检验主要有三个用途:单样本方差的同质性检验、独立性检验和适合性检验。适合性检验和独立性检验都是应用于离散型资料的假设检验,其基本原理是通过χ2值的大小来检验观测值(observed value, O)与理论值(expected value, E)之间的偏离程度。
三、R实现
举个简单的2×2列联表的独立性检验
df <- matrix( c(26, 184, 50, 200), nr = 2,
dimnames = list(c("MJ", "WMJ"), c( "FB", "WFB" )) )
chisq.test(df)
运行结果
chisq.test(df.table)
Pearson's Chi-squared test with Yates' continuity correction
data: df.table
X-squared = 4.2671, df = 1, p-value = 0.03886
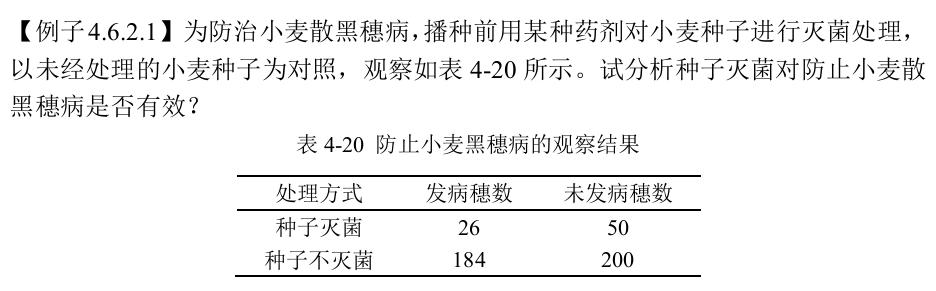
由上面的结果可知,p值 = 0.03886 < 0.05,表明种子灭菌与否和散黑穗病发病穗数显著相关。本例中,种子灭菌的发病率显著低于种子未灭菌的,所以小麦种子用该药剂灭菌对防止小麦散黑穗病是有效的。
适合性检验
适合性检验(compatibility test)是比较观测值与理论值是否符合的假设检验。在生物学研究中,有很多情况都会使用到适合性检验,也成为拟合优度检验,下面我们以孟德尔经典的例子来展示chisq.test() 在适合性检验方面的应用。
【例1】 孟德尔用豌豆的两对相对性状进行杂交实验,黄色圆滑种子与绿色皱缩种子的豌豆杂交后,F2代分离的情况为:黄圆315、黄皱101、绿圆108、绿皱32,共556粒,问此结果是否符合自由组合定律9:3:3:1?
> x <- c(315, 101, 108, 32) #输入样本资料
> p <- c(9/16, 3/16, 3/16, 1/16) #输入待检验的比例
> chisq.test(x, p = p)
Chi-squared test for given probabilities
data: x
X-squared = 0.47002, df = 3, p-value = 0.9254
chisq.test直接的输出值包括了:卡方值、自由度和p值。
从以上的p值来看,这次检验也是接受H0,即实验结果符合自由组合定律的。
独立性检验
独立性检验(independent test)是判断两个或两个以上因素之间是否具有关联关系的假设检验,常用列联表进行检验。而列联表又可分为2 x 2,2 x c , r x c的形式(r ≥ 3, c ≥ 3),然而实则上三种列联表的计算大同小异,不同的只是2 x 2列联表需要进行连续性矫正。下面将分别以几个例子展示chisq.test() 在独立性检验方面的应用。
2 x 2列联表
【例2】 现随机抽样对吸烟人群和不吸烟人群是否患有气管炎进行调查,试检验吸烟与患气管炎有无关联?
> tab <- as.table(cbind(c(50,5), c(250,195))) #创建列联表
> dimnames(tab) <- list(c("smoker", "non-smoker"),
+ c("illness", "un-illness"))
> tab
illness un-illness
smoker 50 250
non-smoker 5 195
> tab_Xsqtest <- chisq.test(tab)
> tab_Xsqtest
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 23.174, df = 1, p-value = 1.48e-06
在本例中:
H0:吸烟与患气管炎无关。
HA:吸烟与患气管炎有关。
另外,由于是2 x 2列联表独立性检验,自由度小于2,因此进行了连续性矫正。检验的p值小于0.01,说明吸烟与患气管炎有关联。同时,我们还可以注意到chisq.test还会输出其他的内容(但并没有直接打印出来)

包括了:
- 样本的观测值
- 样本的理论值
- 计算的残差和标准化后的残差
当我们需要使用这些数据时,不妨将检验的结果保存在一变量中,以便调用。
2 x c列联表
【例3】 现随机抽样对性别和参与的党派进行调查,检验性别与党派是否有关。
> M <- as.table(rbind(c(762, 327, 468), c(484, 239, 477)))
> dimnames(M) <- list(gender = c("F", "M"),
+ party = c("Democrat","Independent", "Republican"))
> M
party
gender Democrat Independent Republican
F 762 327 468
M 484 239 477
> Xsq <- chisq.test(M)
> Xsq
Pearson's Chi-squared test
data: M
X-squared = 30.07, df = 2, p-value = 2.954e-07
卡方检验的p值小于0.01,说明性别与党派是有显著关系的。
可以注意到,2 x c 列联表和2 x 2的代码,除了输入数据的差别外,其他也是几乎一致的。而r x c的代码也是更换输入数据的差别而已。
参考文献
1.(R | 卡方检验)[https://www.jianshu.com/p/78812aaef793]
2.(R语言入门之频率表和列联表)[https://zhuanlan.zhihu.com/p/121813131]
3.(R语言卡方检验)[https://blog.csdn.net/renewallee/article/details/103018523]
4.()[]
标签:统计学,df,squared,检验,卡方,ij,test,列联表 来源: https://www.cnblogs.com/haohai9309/p/16546190.html