从技术演变的角度看互联网后台架构
作者:互联网
这是去年在部门内部做的一个面向后台开发新同学的课程,因为其他BG一些同学要求分享,所以发一下。
其实内容都是些常见开源组件的high level描述,比如flask, express框架,中间件的演化,micro service的概念,一些对nosql/column based db的概念介绍,docker的一些简单概念等等。从单个概念来说,这只是一些科普。
但是为什么当时要开这门课呢?重点是我发现很多新入职的后台开发同学并不太清楚自己做的东西在现代互联网整体架构中处于一个什么样的角色,而在IEG内部则因为游戏开发和互联网开发的一些历史性差异,有些概念并不清晰。
拿中间件来说,很多web application不用啥中间件一样可以跑很好,那么是不是都要上redis?到底解决什么问题?中间件又存在什么问题?中台和中间件又是个什么关系?如果开个mq就是中间件,微服务又是要做啥?
如果能从这十多年来互联网应用的整个tech stack变化去看待backend architecture的一些改变,应该是一件有趣也有意思的事情。这是当时写这个ppt开课的初衷。
我不敢说我在这个ppt里面的一些私货概念就是对的,但是也算是个人这么多年的一些认知理解,抛砖引玉吧。
强调一点,这个ppt的初衷是希望从近十多年来不同时代不同热点下技术栈的变化来看看我们是如何从最早的php/asp/jsp<=>mysql这样的两层架构,一个阶段一个阶段演变到现在繁复的大数据、机器学习、消息驱动、微服务架构这样的体系,然后在针对其中比较重要的几个方面来给新入门后台开发的同学起个“提纲目录”的作用。如果要对每个方面都深入去谈,那肯定不是一两页PPT就能做到的事情。
下面我们开始。首先看第一页如下图:什么是System Design?什么是架构设计?为什么要谈架构设计?

之所以抛出这个问题,是因为平时常常听到两个互相矛盾的说法:一方面很多人爱说“架构师都是不干活夸夸其谈”,另一方面又有很多人苦恼限于日常业务需求开发,无法或者没有机会去从整体架构思考,不知道怎么成长为架构师。
上面ppt中很有趣的是第一句英文,翻译过来恰好可以反映了论坛上经常有人问的“如何学习架构”的问题:很多leader一来就是扔几本书(书名)给新同学,期望他们读完书就马上升级。。。这种一般都只会带来失望。
何为架构师?不写代码只画PPT?
不是的,架构师的基本职责是要在项目早期就能设计好基本的框架,这个框架能够确保团队成员顺利coding满足近期内业务需求的变化,又能为进一步的发展留出空间(所谓scalability),这即是所谓技术选型。如何确保选型正确?对于简单的应用,或者没有新意完全是实践过多次的相同方案,确实靠几页PPT足矣。但是对于新的领域新的复杂需求,这个需求未必都是业务需求,也包括根据团队自身特点(人员太多、太少、某些环节成员不熟悉需要剥离开)来进行新的设计,对现有技术重新分解组合,这时候就需要架构师自己编码实现原型并验证思路正确性。
要达到这样的目标难不难?难!但是现在不是2000年了,是2019年了,大量的框架(framework)、开源工具和各种best practice,其实都是在帮我们解决这件事情。而这些框架并不是凭空而来,而是在这十多年互联网的演化中因为要解决各种具体业务难点而一点一点积累进化而来。无论是从mysql到mongodb到cassandra到time series db,或者从memcached到redis,从lucene到solr到elasticsearch,从离线批处理到hadoop到storm到spark到flink,技术不是突然出现的,总是站在前人的肩膀上不断演变的。而要能在浩如烟海的现代互联网技术栈中选择合适的来组装自己的方案,则需要对技术的来源和历史有一定的了解。否则就会出现一些新人张口ELK,闭口tensorflow,然后一个简单的异步消息处理就会让他们张口结舌的现象。
20多年前的经典著作DesignPatterns中讲过学习设计模式的意义,放在这里非常经典:学习设计模式并不是要你学习一种新的技术或者编程语言,而是建立一种交流的共同语言和词汇,在方案设计时方便沟通,同时也帮助人们从更抽象的层次去分析问题本质,而不被一些实现的细枝末节所困扰。同时,当我们能把很多问题抽象出来之后,也能帮我们更深入更好地去了解现有系统-------这些意义,对于今天的后端系统设计来说,也仍然是正确的。
下图是我们要谈的几个主要方面。

上面的几个主题中,第一个后台架构的演化是自己从业十多年来,体会到的互联网技术架构的整体变迁。然后分成后台前端应用框架、middleware和存储三大块谈一下,最后两节微服务和docker则是给刚进入后台开发的同学做一些概念普及。其中个人觉得最有趣的,是第一部分后台架构的演化和第三部分的中间件,因为这两者是很好地反映了过去十多年互联网发展期间技术栈的变化,从LAMP到MEAN Stack,从各种繁复的中间层到渐渐统一的消息驱动+流处理,每个阶段的业界热点都相当有代表性。
当然,不是说web框架、数据存储就不是热点了,姑且不说这几年web前端的复杂化,光后端应用框架,node的express,python的django/flask,go在国内的盛行,都是相当有趣的。在数据存储领域,列存储和时序数据随着物联网的发展也是备受重视。但是篇幅所限,在这个课程中这些话题也就只能一带而过,因为这些与其说是技术的演变过程,不如说是不同的技术选型和方向了,比如说Mysql适合OLTP(Online Transaction Processing),而Cassandra/Hbase等则适合OLAP(Online Analyical Processing),并不能说后者就优于前者。
下面我们先来看后台架构的演化

严格说这是个很大的标题,从2000年到现在的故事太多了,我这里只能尽力而为从个人体验来分析。
首先是2008年以前,我把它称为网站时代。为什么这么说?因为那时候的后台开发就是写网站,而且通常是页面代码和后台数据逻辑一起写。你只要能写JSP/PHP/ASP来读写Mysql或者SQL Server,基本就能保证一份不错的工作了。
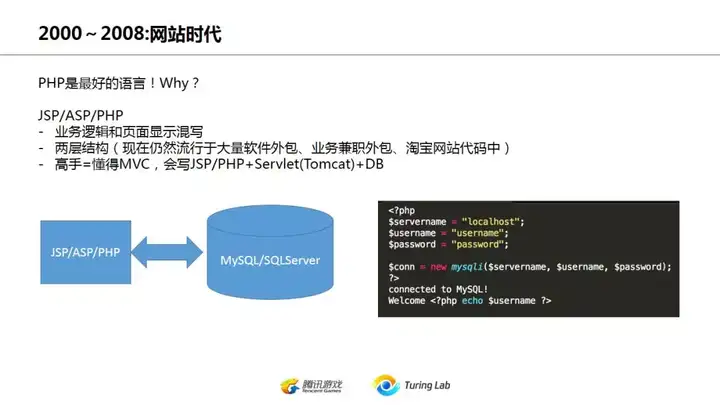
要强调一下,这种简单的两层结构并不能说就是落后。在现在各个企业、公司以及小团队的大量web应用包括移动App的后端服务中,采用这种架构的不在少数,尤其是很多公司、学校、企业的内部服务,用这种架构已经足够了。
注意一个时间节点:2008。
当然,这个节点是我YY的。这个节点可以是2007,或者2006。这个时间段发生了两个影响到现在的事情:google上市,facebook开始推开
我个人相信前者上市加上它发表的那三篇大数据paper影响了后来业界的技术方向,后者的火热则造成了社交成为业务热点。偏偏社交网站对大数据处理有着天然的需求,技术的积累和业务的需求就这么阴差阳错完美结合了起来,直接影响了大海那边后面的科技发展。
同时在中国,那个时候却是网络游戏MMO的黄金年代,对单机单服高并发实时交互的需求,远远压过了对海量数据data mining的需要,在这个时间点,中美两边的互联网科技树发生了比较大的分叉。这倒是并没有优劣之说,只是业务场景的重要性导致了技能树的侧重。直到今天,单机(包括简单的多服务器方案)高并发、高QPS仍然也是国内业界所追求的目标,而在美国那边,这只是一个业务指标而已,更看重的是如何进行水平扩展(horizontal scaling)和分散压力。
国内和美国的科技树回到一条线上,大数据的业务需求和相关技术发展紧密结合起来,可能要到2014年左右,随着互联网创业的盛行,O2O业务对大数据实时处理、机器学习推荐提出了真正的需求时,才是国内业界首次出现技术驱动业务,算法驱动产品的现象,重新和美国湾区那边站在了一条线上,而这则是后话了。
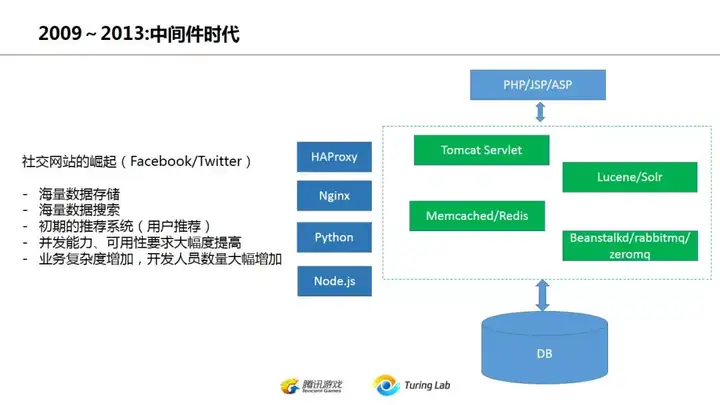
到了2010年前后,facebook在全球已经是现象级产品,当时微软直接放弃了windows live,就是为了避免在社交领域硬怼facebook。八卦一下当时在美国湾区那边聚餐的时候,如果谁说他是facebook的,那基本就是全场羡慕的焦点。
facebook的崛起也带动了其他大量的社交网站开始出现,社交网站最大的特点就是频繁的用户搜索、推荐,当用户上亿的时候,这就是前面传统的两层架构无法处理的问题了。因此这就带动了中间件的发展。实际上在国外很少有人用中间件或者middelware这个词,更多是探讨如何把各种service集成在一起,像国内这样强行分成frontend/middleware/storage的概念是没听人这么谈过的,后面中间件再说这问题。当时的一个惯例是用php做所谓的胶水语言(glue language),然后通过hessian这些协议工具来把其他java服务连接到一起。与此同时,为了提高访问速度,降低后端查询压力,memcached/redis也开始大量使用。基于lucene的搜索(2010左右很多是自行开发)或者solr也被用在用户搜索、推荐以及type ahead这些场景中。
我记忆中在2012年之前消息队列的使用还不是太频繁,不像后来这么重要。当时常见的应该就是beanstalkd/rabbitmq, zeromq其实我在湾区那边很少听人用,倒是后来回国后看到国内用的人还不少。Kafka在2011年已经出现了,有少部分公司开始用,不过还不是主流。
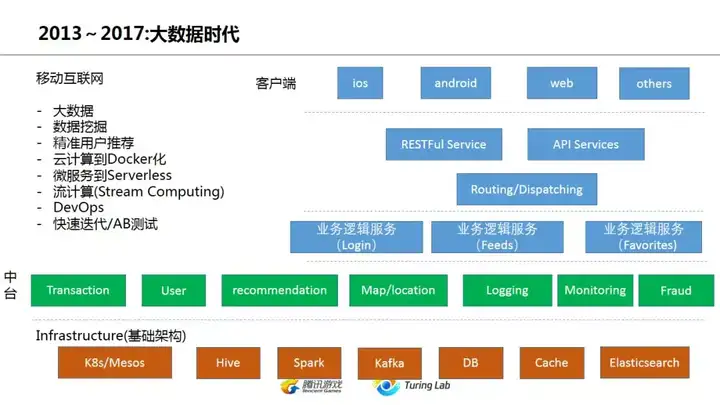
2013年之后就是大数据+云的时代了,如果大家回想一下,基本上国内也是差不多在2014年左右开始叫出了云+大数据的口号(2013年国内还在手游狂潮中...)。不谈国外,在中国那段时间就是互联网创业的时代,从千团大战到手游爆发到15年开始的O2O,业务的发展也带动了技术栈的飞速进步。左上角大致上也写了这个时代互联网业界的主要技术热点,实际上这也就是现在的热点。无论国内国外,绝大部分公司还并没有离开云+大数据这个时代。无论是大数据的实时处理、数据挖掘、推荐系统、Docker化,包括A/B测试,这些都是很多企业还正在努力全面解决的问题。
但是在少数站在业界技术顶端或者没有历史技术包袱的新兴公司,从某个角度上来说,他们已经开始在往下一个时代前进:机器学习AI驱动的时代
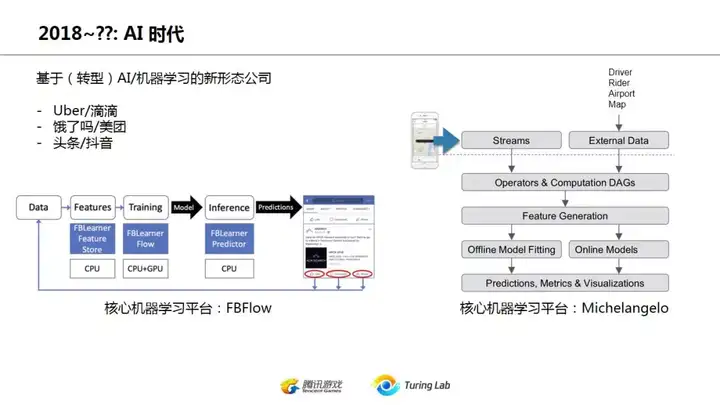
2018年开始,实际上可能是2017年中开始,AI驱动成了各大公司口号。上图是facebook和uber的机器学习平台使用情况,基本上已经全部进入业务核心。当然并不是说所有公司企业都要AI驱动,显然最近发生的波音737事件就说明该用传统的就该传统,别啥都往并不成熟的AI上堆。但另一方面,很多新兴公司的业务本身就是基于大数据或者算法的,因此他们在这个领域也往往走得比较激进。由于这个AI驱动还并没有一个很明确的定义和概念,还处于一种早期萌芽的阶段,在这里也就不多YY了。
互联网后台架构发展的简单过程就在这里讲得差不多了,然后我们快速谈一下web开发框架。

首先在前面我提到,在后端架构中其实也有所谓的frontend(前台)开发存在,一般来说这是指响应用户请求,实现具体业务逻辑的业务逻辑层。当然这么定义略微粗糙了些,很多中间存储、消息服务也会封装一些业务相关逻辑。总之web开发框架往往就是为了更方便地实现这些业务逻辑而存在的。
前文提到在一段较长时间内,国内的技术热点是单机高并发高QPS,因此很多那个时代走过来的人会本能地质疑web框架的性能,而更偏好TCP长链接甚至UDP协议。然而这往往是自寻烦恼,因为除开特别的强实时系统,无论是休闲手游、视频点播还是信息流,都已经是基于HTTP的了。
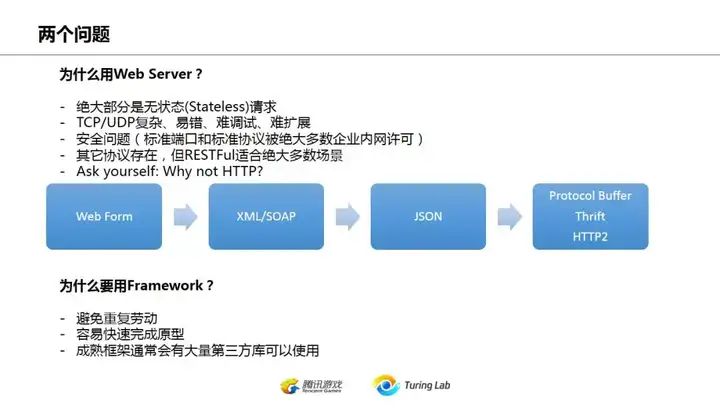
上图所提到的两个问题中,我想强调的是第一点:所有的业务,在能满足需求的情况下,首选HTTP协议进行数据交互。准确点说,首选JSON,使用web API。
Why? 这就是上图第一个问题所回答的:无状态、易调试易修改、一般没有80端口限制。
最为诟病的无非是性能,然而实际上对非实时应用,晚个半秒一秒不应该是大问题,要考虑的是水平扩展scalability,不是实时响应(因为前提就是非实时应用);其次实在不行你还有websocket可以用。

这一部分是简单列举了一下不同框架的使用,可以看出不同框架的概念其实差不多。重点是要注意到middleware这个说法在web framework和后端架构中的意义不同。在web framework中是指具体处理GET/POST这些请求之前的一个通用处理(往往是链式调用),比如可以把鉴权、一些日志处理和请求记录放在这里。但在后端架构设计中的middleware则是指类似消息队列、缓存这些在最终数据库之前的中间服务组件。
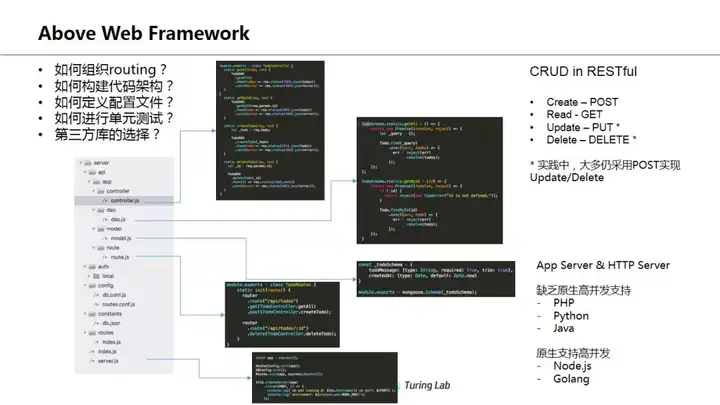
最后这里是想说web framework并不是包治百病,实际上那只是提供了基础功能的一个library,作为开发者则更多需要考虑如何定义配置文件,一些敏感参数如token、密码怎么传进来,开发环境和生产环境的配置如何自动切换,单元测试怎么搞,代码目录怎么组织。有时候我们可以用一些比如Yeoman之类的scaffold工具来自动生成项目代码框架,或者类似django这种也可能自动生成基本目录结构。
下面进入Middleware环节。again,强调一下这里只是根据个人经验和感受谈谈演化过程。

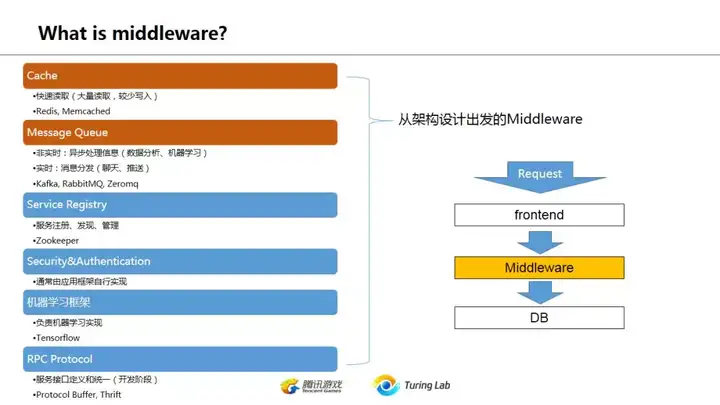
这一页只是大致讲一下怎么定义中间件middleware。说句题外话,在美国湾区那边提这个概念的很少,而阿里又特别喜欢说中间件,两者相互的交流非常头痛。湾区那边不少google、facebook还有pinterest/uber这些的朋友好几次都在群里问说啥叫中间件。
中间件这个概念很含糊,应该是阿里提出来的,对应于middleware(不过似乎也不是完全对应),可能是因为早期java的EJB那些概念里面比较强调middleware这一点吧(个人猜的)。大致上,如果我们把web后端分为直接处理用户请求的frontend,最后对数据进行持久存储(persistant storage)这两块,那么中间对数据的所有处理环节都可以视为middleware。
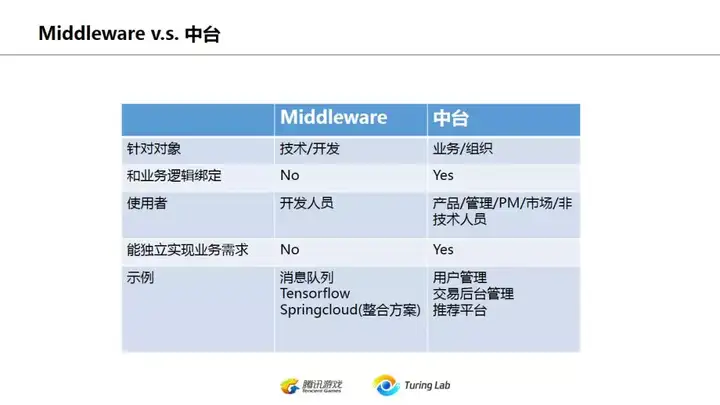
和中间件对应的另一个阿里发明的概念是中台。近一年多阿里的中台概念都相当引人注意,这里对中台不做太多描述。总体来说中台更多是偏向业务和组织架构划分,不能说是一个技术概念,也不是面向开发人员的。而中间件middleware是标准的技术组件服务。
那么我们自然会有一个问题:为什么要用中间件?
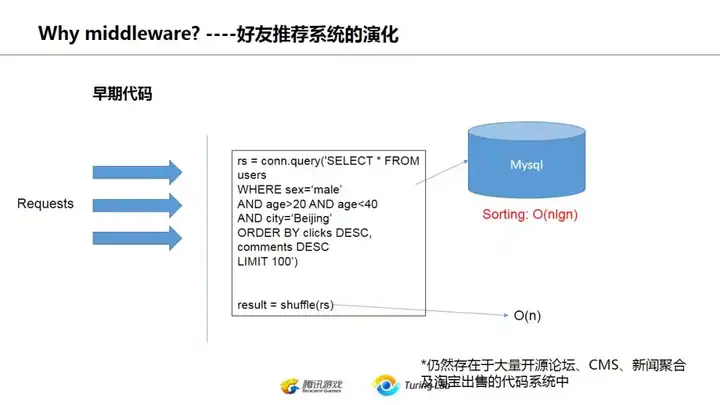
谈到为什么要用middlware,这里用推荐系统举例。
推荐系统,对数据少用户少的情况下,简单的mysql即可,比如早期论坛的什么top 10热门话题啊,最多回复的话题啊,都可以视为简单的推荐,数据量又不大的情况下,直接select就可以了。
如果是用户推荐的话,用户量不大的情况下,也可以如法炮制,选择同一区域(城市)年龄相当的异性,最后随机挑几个给你,相信世纪佳缘之类的交友网站早期实现也就是类似的模式。
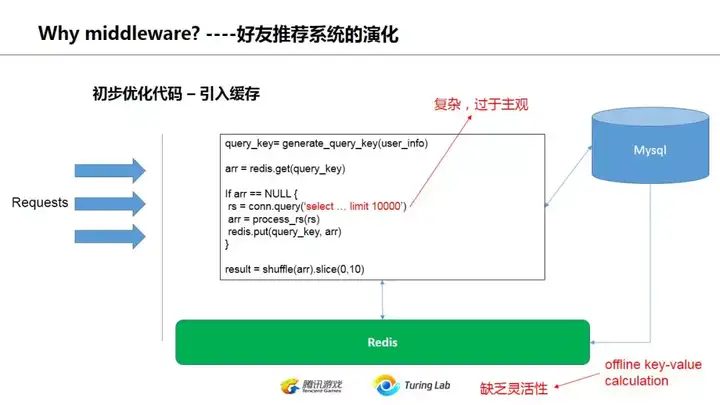
那么,如果用户量多了呢?每次都去搜数据库,同时在线用户又多,那对数据库的压力就巨大了。这时候就是引入缓存,memcached、redis就出现了。
简单的做法就是把搜索条件作为key,把结果作为value存入缓存。打个比方你可以把key存为 20:40:beijing:male (20到40岁之间北京的男性),然后把第一次搜索的结果全部打乱shuffle后,存前1000个,10分钟过期,再有人用类似条件搜索,就直接把缓存数据随机挑几个返回。放心,一般来说不会有人10分钟就把1000个用户的资料都看完了,中间偶有重复也没人在意(用世纪佳缘、百合网啥的时候看到过重复的吧)。
不过话又说回来,现代数据库,尤其是类似mongodb/es这些大量占用内存的nosql,已经对经常查询的数据做了缓存,在这之上再加cache,未必真的很有效,这需要case by case去分析了,总之盲目加cache也并不推荐。
加缓存是为了解决访问速度,减轻数据库压力,但是并不提高推荐精准度。如果我们要提高推荐效果呢?在2015年之前机器学习还没那么普及成熟的时候,我们怎么搞呢?
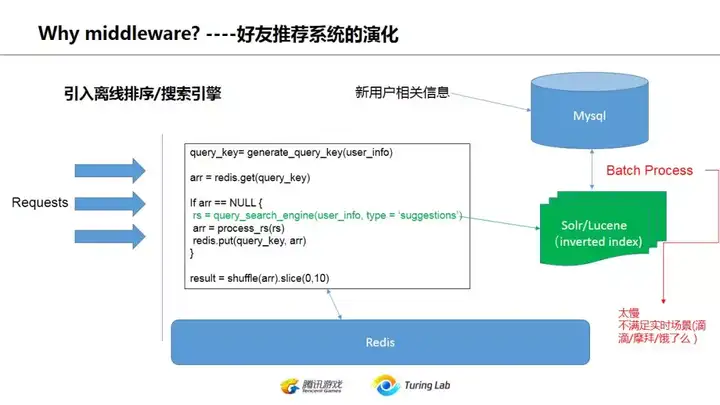
提高推荐效果,在机器学习之前有两种做法:
- 引入基于lucene的搜索引擎,在搜索的同时通过定制方案实现scoring,比如我可以利用lucene对用户的年龄、性别、地址等进行indexing,但是再返回结果时我再根据用户和查询者两人的具体信息进行关联,自定义返回的score(可以视为推荐相关系数)
- 采用离线批处理。固然可以用hadoop,但是就太杀鸡用牛刀了。常见的是定时批处理任务,按某种规则划分用户群体,对每个群体再做全量计算后把推荐结果写入缓存。这种可以做很繁复准确的计算,虽然慢,但效果往往不错。这种做法也常用在手机游戏的PvP对战列表里面。
这些处理方法对社交网络/手游这类型的其实已经足够了,但是新的业务是不断出现的。随着uber/滴滴/饿了么/美团这些需要实时处理数据的app崛起,作为一个司机,并不想你上线后过几分钟才有客人来吧,你希望你开到一个热点区域,一开机就马上接单。
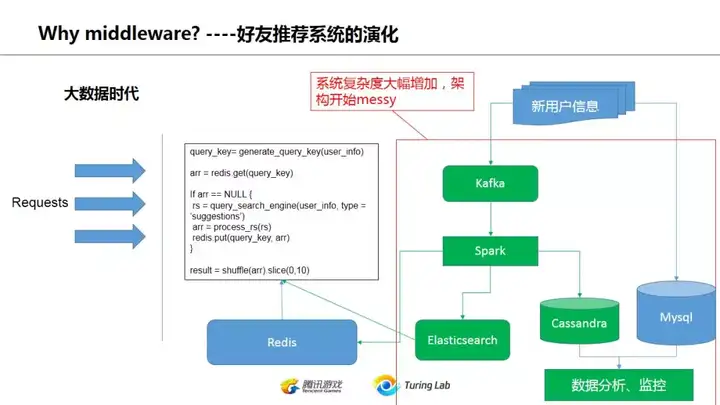
所以这种对数据进行实时(近实时)处理的需求也带动了后端体系的大发展,kafka/spark等等流处理大行其道。这时候的后端体系就渐渐引入了消息驱动的模式,所谓消息驱动,就是对新的生产数据会有多个消费者,有的是满足实时计算的需求(比如司机信息需要立刻能够被快速检索到,又不能每次都做全量indexing,就需要用到spark),有的只是为了数据分析,写入类似cassandra这些数据库里,还有的可能是为了生成定时报表,写入到mysql。
大数据的处理一直是业界热点领域。记得2015年硅谷一个朋友就是从一家小公司做php跳去另一家物联网公司做spark相关的工作,之前还很担心玩不转,搞了两年就俨然业界大佬被oracle挖去负责云平台~~~
anyway,这时候对后端体系的要求是一方面能快速满足实时需求,另一方面又能满足各种耗时长的数据分析、data lake存储等等,以及当时渐渐普及的机器学习模型(当时2015年初和几个朋友搞startup,其中一个是walmart lab的机器学习专家,上来就一堆模型,啥数据和用户都还没有就把模型摆上来了,后来搞得非常头痛。当时没有keras/pytorch/tf这些,那堆模型是真心搞不太懂,但是又不敢扔,要靠那东西去包装拿投资的。。。)
但是我们再看上面的图,是不是感觉比较乱呢?各种系统的数据写来写去,是不是有点messy?当公司团队增多,系统复杂度越来越高的时候,我们该怎么梳理?
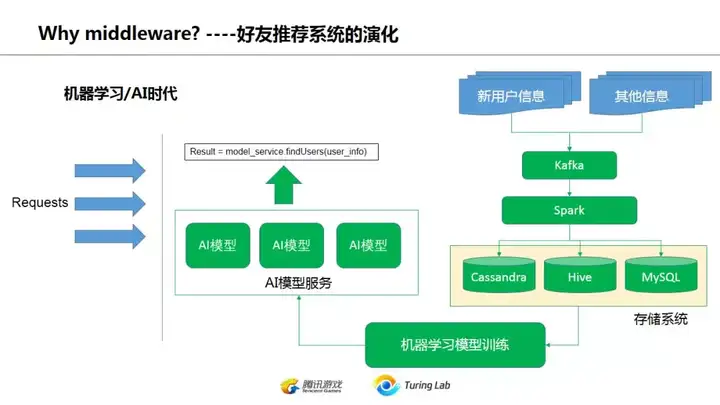
到了2017之后,前面千奇百怪的后端体系基本上都趋同了。kafka的实时消息队列,spark的流处理(当然现在也可以换成flink,不过大部分应该还是spark),然后后端的存储,基于hive的数据分析查询,然后根据业务的模型训练平台。各个公司反正都差不多这一套,在具体细节上根据业务有所差异,或者有些实力强大的公司会把中间一些环节替换成自己的实现,不过不管怎么千变万化,整体思路基本都一致了。
这里可以看到机器学习和AI模型的引入。个人认为,machine learning的很大一个好处,是简化业务逻辑,简化后台流程,不然一套业务一套实现,各种数据和业务规则很难用一个整体的技术平台来完成。相比前面一页的后台架构,这一页要清晰许多,而且是一个DAG有向无环图的形式,数据流向很明确。我们在下面再来说这个机器学习对业务数据流程的简化。
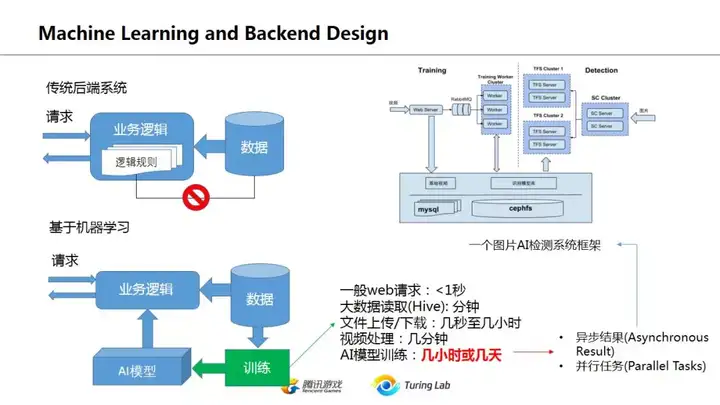
在传统后端系统中,业务逻辑其实和数据是客观分离的,逻辑规则和数据之间并不存在客观联系,而是人为主观加入,并没形成闭环,如上图左上所示。而基于机器学习的平台,这个闭环就形成了,从业务数据->AI模型->业务逻辑->影响用户行为->新的业务数据这个流程是自给自足的。这在很多推荐系统中表现得很明显,通过用户行为数据训练模型,模型对页面信息流进行调整,从而影响用户行为,然后用新的用户行为数据再次调整模型。而在机器学习之前,这些观察工作是交给运营人员去手工猜测调整。
上图右边谈的是机器学习相关后台架构和传统web后台的一些差别,重点是耗时太长,必须异步处理。因此消息驱动机制对机器学习后台是一个必须的设计。
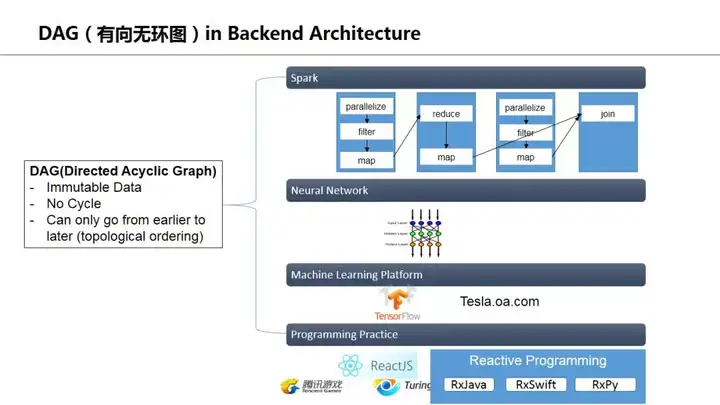
这页是一些个人的感受,现代的后端数据处理越来越偏向于DAG的形态,Spark不说了,DAG是最大特色;神经网络本身也可以看作是一个DAG(RNN其实也可以看作无数个单向DNN的组合);tensorflow也是强调其Graph是DAG,另外编程模式上,Reactive编程也很受追捧。
其实DAG的形态重点强调的就是数据本身是immutable(不可修改),只能transform后成为新的数据进入下一环。这个思维其实可以贯穿到现代后台系统设计的每个环节,比如trakcing、analytics、数据表设计、microservice等等,但具体实施还是要case by case了。
无论如何,数据,数据的跟踪tracking,数据的流向,是现代后台系统的核心问题,只有data flow和data pipeline清晰了,整个后台架构才会清楚。
数据库是个非常复杂的领域,在下面对几个基本常用的概念做一些介绍。注意一点是graph database在这里没有提到,因为日常使用较少,相对来说facebook提出的GraphQL倒是个有趣的概念,但也只是在传统db上的一个概念封装。

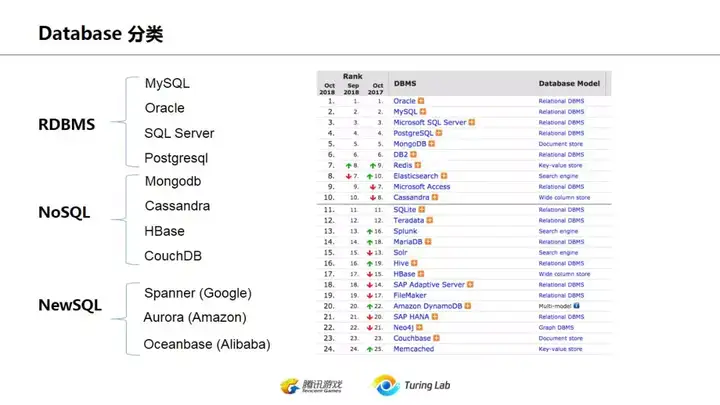
上图是2018年12月初热门数据库的排名,我们可以看到关系数据库RDBMS和NOSQL数据库基本上平分秋色。而NOSQL中实际上又可以分为key-value storage(包括文档型)及column based DB.

mysql这个没啥好讲,大概提一下就是。有趣的是曾经看到一篇文章是aws CTO谈的一些内容,其中印象深刻是:如果你的用户还不到100万,就别折腾了,无脑使用mysql吧)
在2015年之前的一个趋势是不少公司使用mysql作为数据存储,但是把indexing放在外部去做。这个思路最早似乎是friendster提出的,后来uber也模仿这种做法设计了自己的数据库schemaless。然而随着postgreSQL的普及(postgreSQL支持对json的索引),这种做法是否还有意义就值得商榷了。

nosql最早的使用就是key-value的查找,典型的就是redis。实际上后来的像mongo这些documentbased db也是类似的key value,只是它对document中的内容又做了一次index (inverted index),用空间换时间来提供查找数据,这也是cs不变的思维。
mongo/elasticsearch收到热捧主要是因为它们的schemaless属性,也就是不需要提前定义数据格式,只要是json就存,还都能根据每个field搜索,这非常方便程序员快速出demo。但是实际上数据量大之后还是要规范数据结构,定义需要indexing的field的。
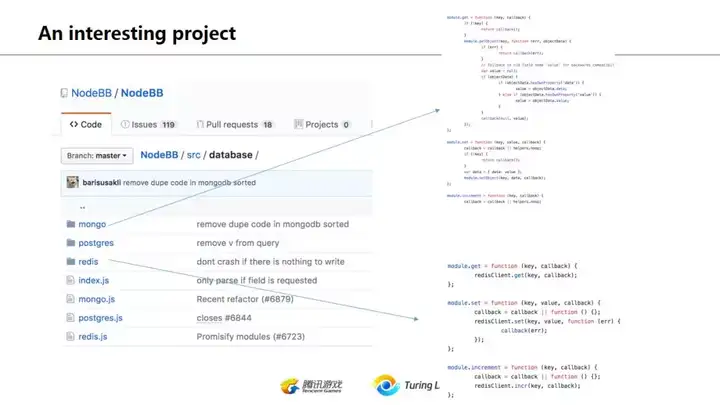
这里提一个比较好玩的开源project nodebb, 这是个node.js开发的论坛系统。在我前几年看到这个的时候它其实只支持redis,然后当时因为一个项目把它改造了让他支持mysql。去年再看的时候发现它同时支持了redis/postres/mongo,如果对比一下同样的功能他如何在这三种db实现的,相信会很有帮助。
稍微谈谈列存储。常见mysql你在select的时候其实往往会把整行都读出来,再在其中挑那么一两个你需要的属性,非常浪费。而mongo这些文件型db,又不支持常见SQL。而列存储DB的好处就是快,不用把一行所有信息读出来,只是按列读取你需要的,对现在的大数据分析特别是OLAP(Online Analytical Processing)来说特别重要。然而据另外的说法,实际上像casssandra/hbase这些并不是真正的列存储,而只是借用了一些概念。这个我也没深入去了解,有兴趣的同学可以自己研究研究。

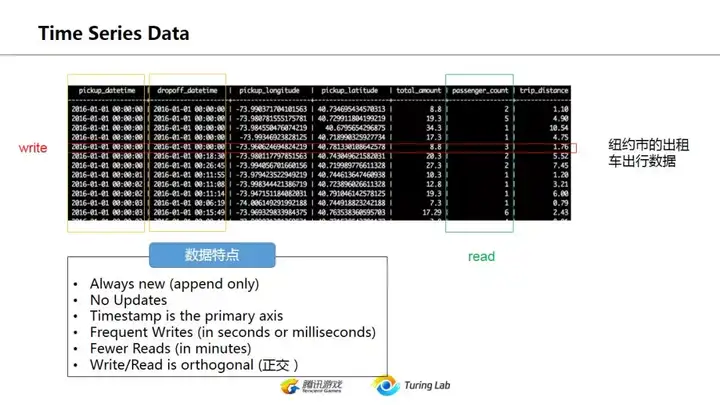
列存储的一个重要领域是时序数据库,物联网用得多。其特色是大量写入,只增不改(不修改数据),但是读的次数相对于很少(想想物联网的特点,随时有数据写入,但是你不会随时都在看你家小米电器的状态。。。)
注意说write/read是正交的。这意思是每次写入是一次一行,而读是按列,加上又不会修改数据,因此各自都能保持极快的速度
下面简单谈一下微服务,大部分直接看PPT就可以了,有几页略微谈一下个人思考。

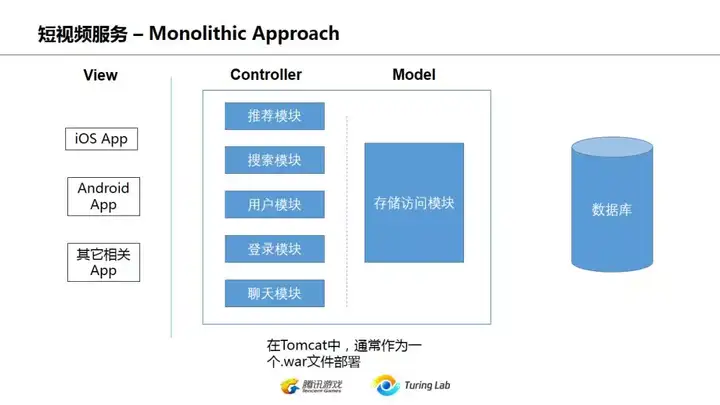

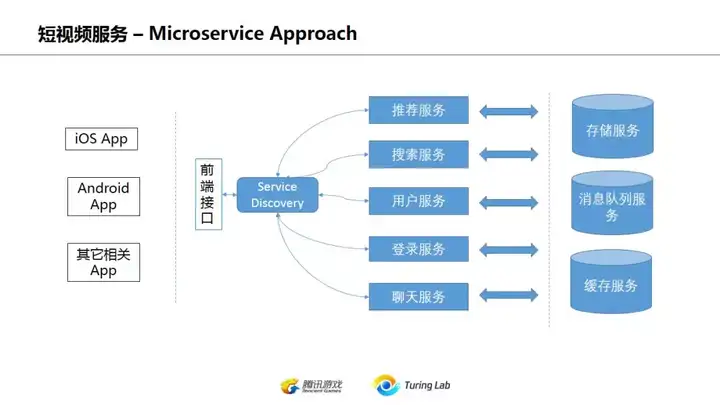

上面这页说说,其实微服务所谓的服务发现/name service不要被忽悠觉得是多神奇的东西。最简单的Nginx/Apache这些都能做(域名转向,proxy),或者你要写个name : address的对应关系到db里面也完全可以,再配一个定时healthcheck的服务,最简单的服务发现也就行了。
高级点用到zookeeper/etcd等等,或者SpringCloud全家桶,那只是简化配置,原理都一样。从开发角度来看,微服务的开发并不是难点,难点是微服务的配置和部署。最近一段时间微服务部署也是业界热点,除了全家桶形态的SpringCloud,也可以看看lstio这些开源工具。

上图主要大致对比一下,看看从早期的Spring到现在Spring Cloud的变化。想来用过Java Tomcat的朋友都能体会Java这一套Config based development的繁琐,开发的精力很多不是在业务代码上,往往会化不少精力去折腾配置文件。当然,Spring Cloud在这方面简化了不少,不过个人还是不太喜欢java,搞很多复杂的设计模式,封装了又封装。
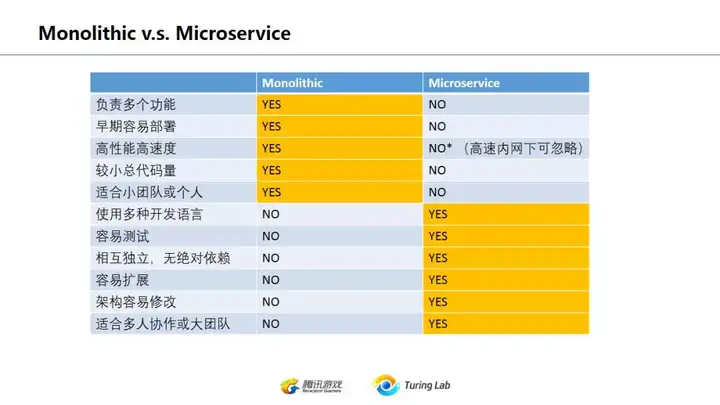
这里要说并不是微服务解决一切,热门的Python Django尽管有restful-framework,但是它实际上是一个典型的Monolithic体系。对很多核心业务,其实未必要拆开成微服务。
这两者是互补关系,不是替代关系。
下面的docker我就不仔细谈了,PPT基本表达了我想表述的概念,主要意思是
- docker能够简化部署,简化开发,能够在某种程度上让开发环境和产品环境尽量接近
- 不要担心docker的性能,它不是虚拟机,可以看作在server上运行的一个process。

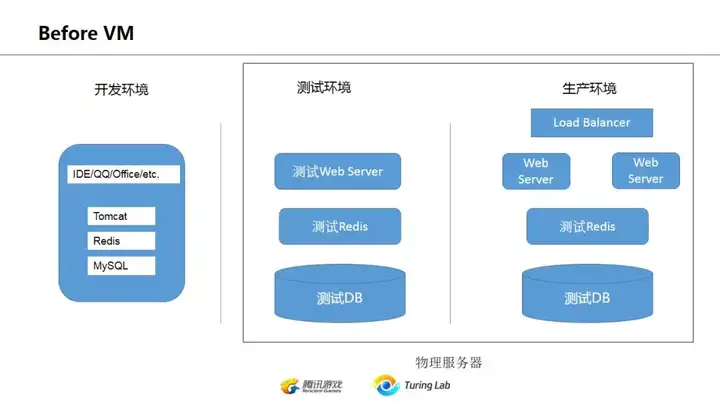
上图是描述docker之前开发人员的常见开发环境,首先在自己机器上装一大堆服务,像mysql, redis, tomcat啥的。也有直接在远程服务器安装环境后,多人共同登录远端开发,各自使用一个端口避免冲突…. 实际上这种土法炼钢的形态,在2019年的今天仍然在国内非常普及。
这种形态的后果就是在最后发布到生产环境时,不同开发人员会经历长时间的“联调”,各种端口、权限、脚本、环境设置在生产环境再来一遍…这也是过去运维人员的主要工作。
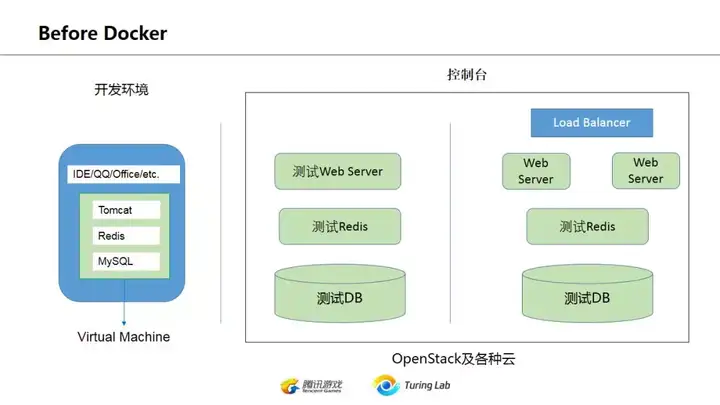
上一页提到的问题,并不是一定要docker来解决。在这之前,虚拟机VM的出现,以及vagrant这样的工具,都让开发环境的搭建多少轻松了一些。不过思路仍然是把VM作为一个独立服务器使用,只是因为快照、镜像和辅助工具,让环境的配置、统一和迁移更加简单快捷。
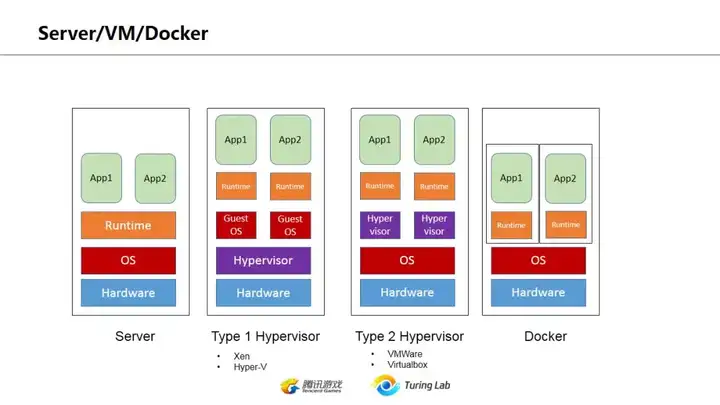
上图是对比程序运行在物理服务器、VM及docker时的资源共享情况,可以看到运行在Docker的应用,并没有比并发运行在物理服务器上占用更多资源。
下图是简单的docker使用,不做赘述。
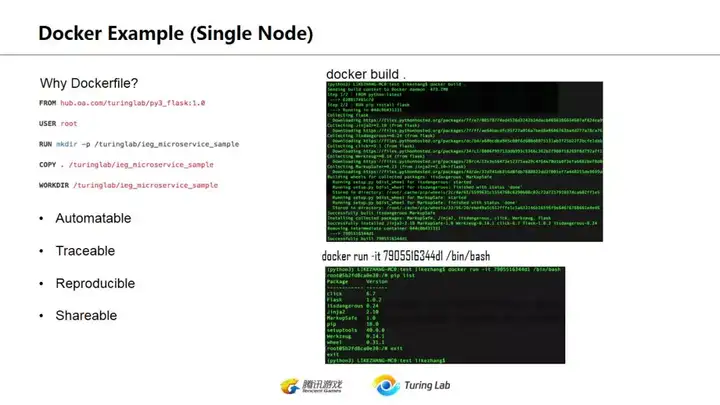
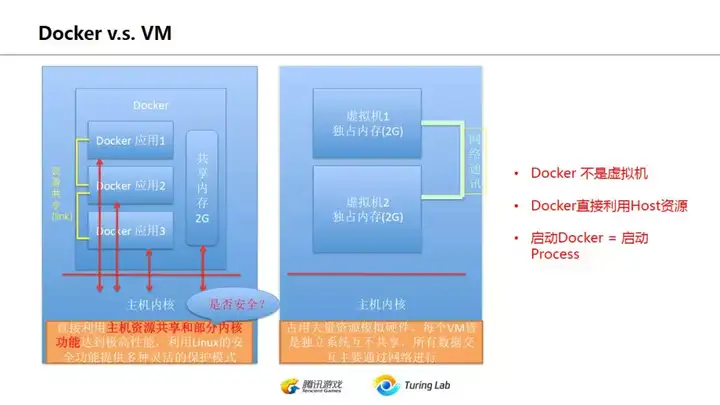
这一页主要是强调Docker并不等同于虚拟机。虚拟机所占资源是独享的,比如你启动一个VM,分配2G内存,那么这个VM里不管是否运行程序都会占用2G内存。然而如果你启动一个Docker,里面运行一个简单web服务,在不强制指定内存占用情况下,如果没有请求进入,没有额外占用内存,那么这个docker服务对整机的内存占用几乎为0(当然仍然存在一些开销,但主要是根据该程序自身的运行状况而定)。
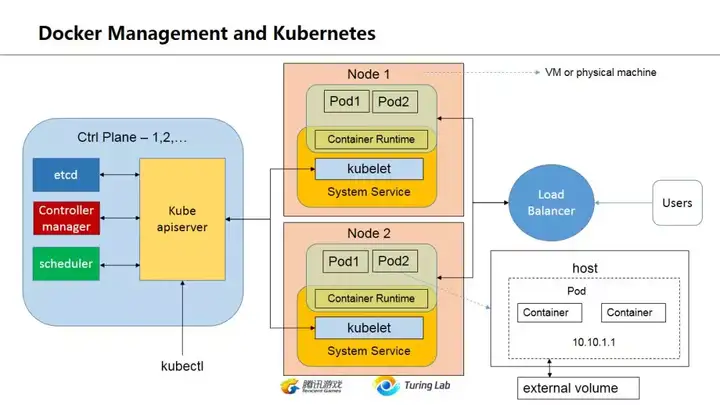
最后Kubernetes这里大概说说host-pod-container的关系,一个host可以是物理机或者vm,pod不是一个docker,而是可以看作有一个ip的...(不知道怎么形容),总之一个pod可以包括多个container(docker),pod之中的container可以共享该pod的资源(ip,storage等)。不过现实中似乎大多是一个pod对一个container。
对互联网一些热门概念和演变过程的一个很简略的描述就到这里了,谢谢。
标签:web,架构,中间件,业务,角度看,后台,数据 来源: https://blog.51cto.com/13591395/2364627