论文阅读 A Data-Driven Graph Generative Model for Temporal Interaction Networks
作者:互联网
13 A Data-Driven Graph Generative Model for Temporal Interaction Networks
Abstract
本文提出了一个名为TagGen的端到端深度生成框架。通过一种新的采样策略,用于结合从时间网络中提取的结构和时间上下文信息。在此基础上,TagGen参数化了一个双级自注意力层以及一系列局部操作,以生成临时随机游走。最后,判别器选择在输入数据中可信的生成的时间随机游走,并将其输入到组装模块中生成时间网络。在7个真实数据集上的实验结果表明
(1)TagGen在时间交互网络生成问题上优于所有基线
(2)TagGen显著提高了预测模型在异常检测和链路预测任务中的性能。
Conclusion
在本文中提出了TagGen,通过直接学习时间戳边集合来生成时间网络的第一次尝试。TagGen能够通过一种新颖的上下文采样策略和双级自注意力机制生成捕捉输入数据的重要结构和时间属性的图表。作者提出:(1)TagGen在包含6个指标的7个数据集上始终优于基线方法;(2) TagGen通过数据增强提高了异常检测和链路预测方法的性能。
Figure and table
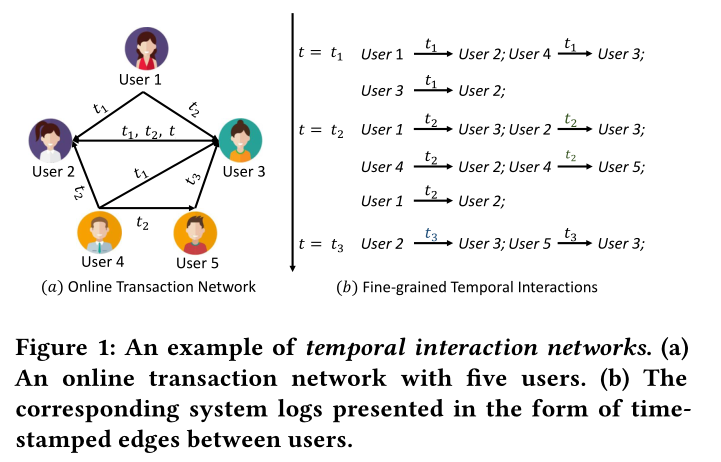
图1 一个时间交互网络的例子。(a)有五个用户的在线交互网络。(b)相应的系统日志以用户之间带时间戳的边的形式表示。

图2 图生成模型的二维概念空间(图生成模型的历史发展)
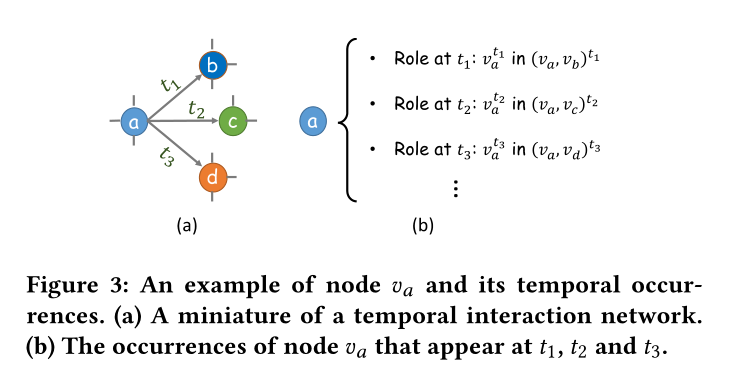
图3 节点\(v_a\)和它的时序事件的一个样例。(a)一个小型的时序交互网络。(b)节点\(v_a\)在时间\(t_1,t_2,t_3\)发生的事件
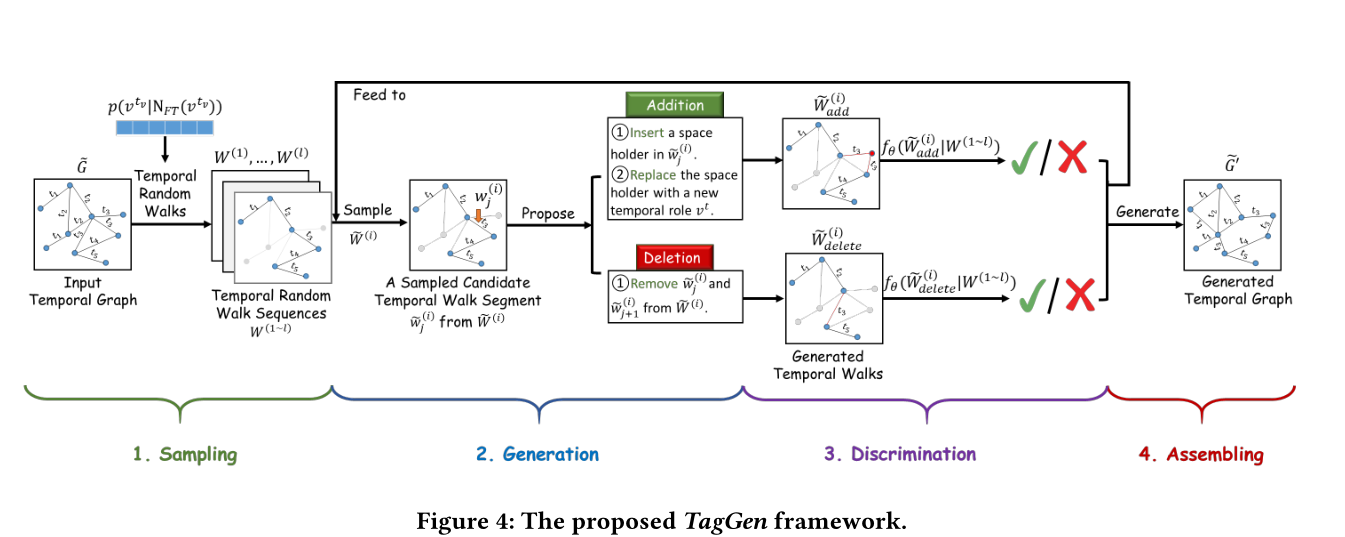
图4 TagGen框架结构
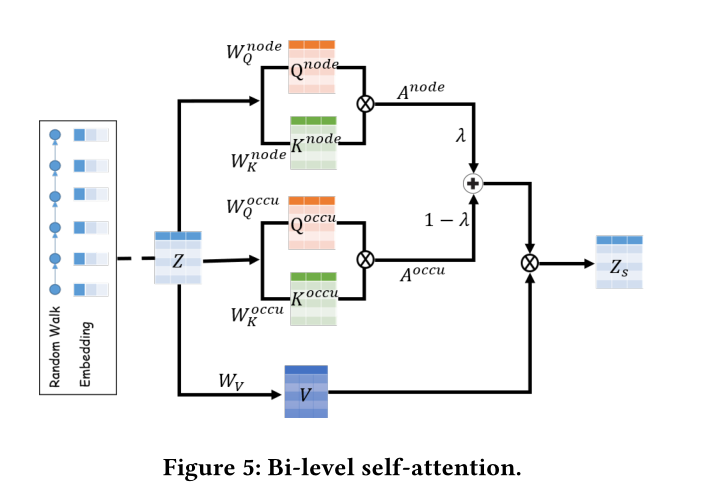
图5 双级自注意力架构(有点意思)
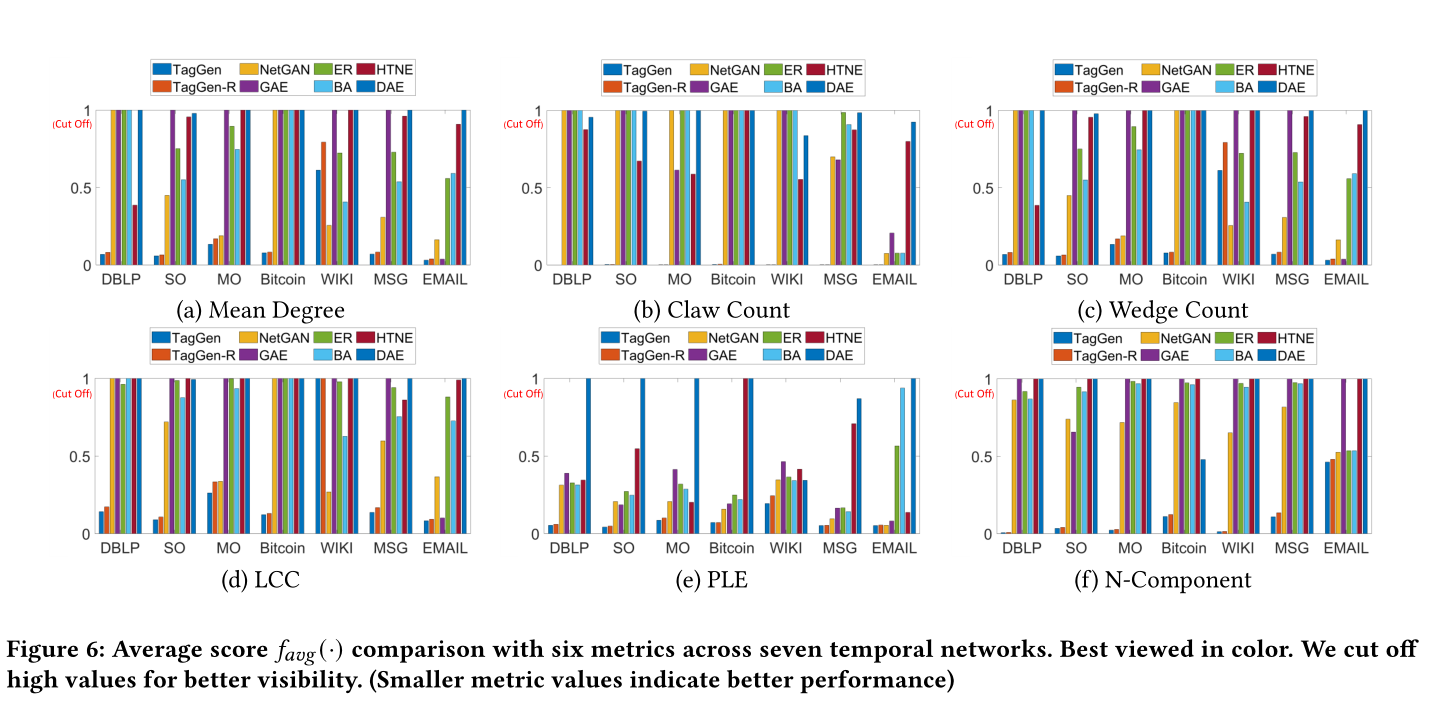
图6 7个时间网络中6个指标的平均得分\(f_{avg}(·)\)比较。为了更好的能展示,去掉了高值。(度量值越小表示性能越好)
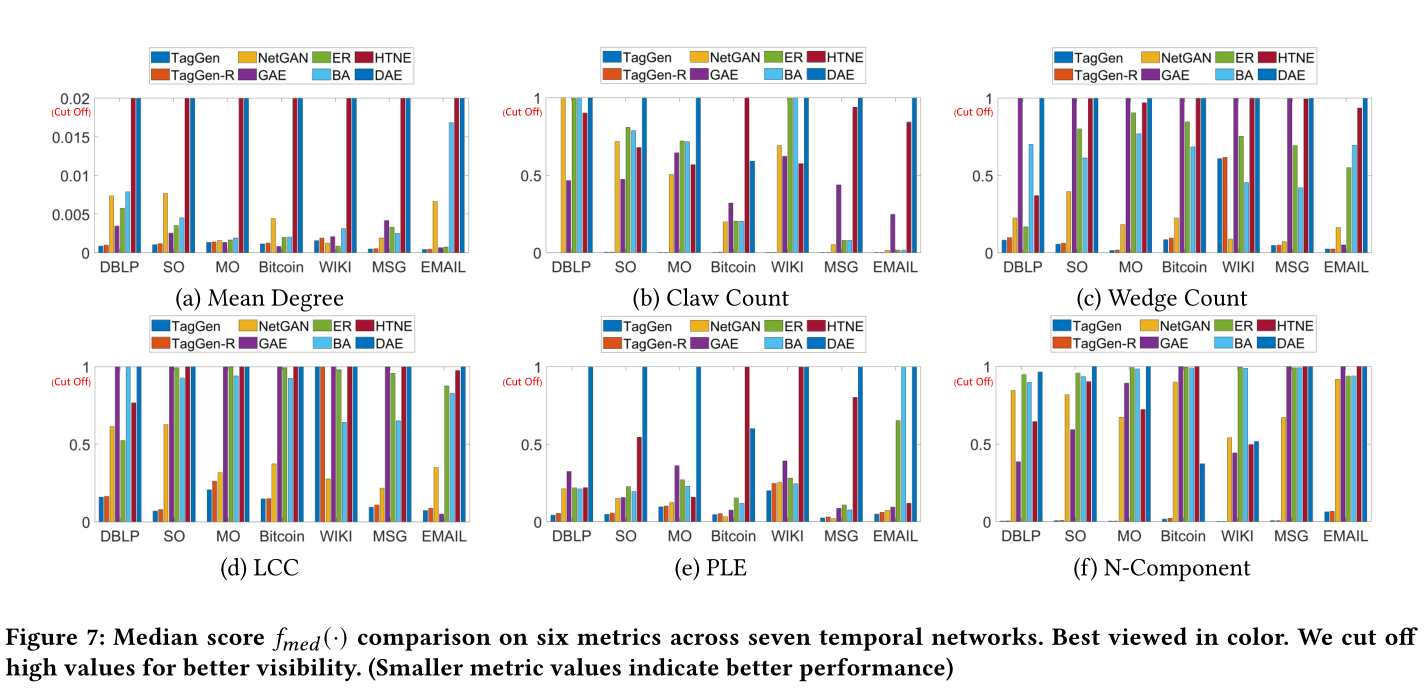
图7 7个时间网络的6个指标的中位数\(f_{med}(·)\)得分。为了更好的展示,去掉了高值。(度量值越小表示性能越好)
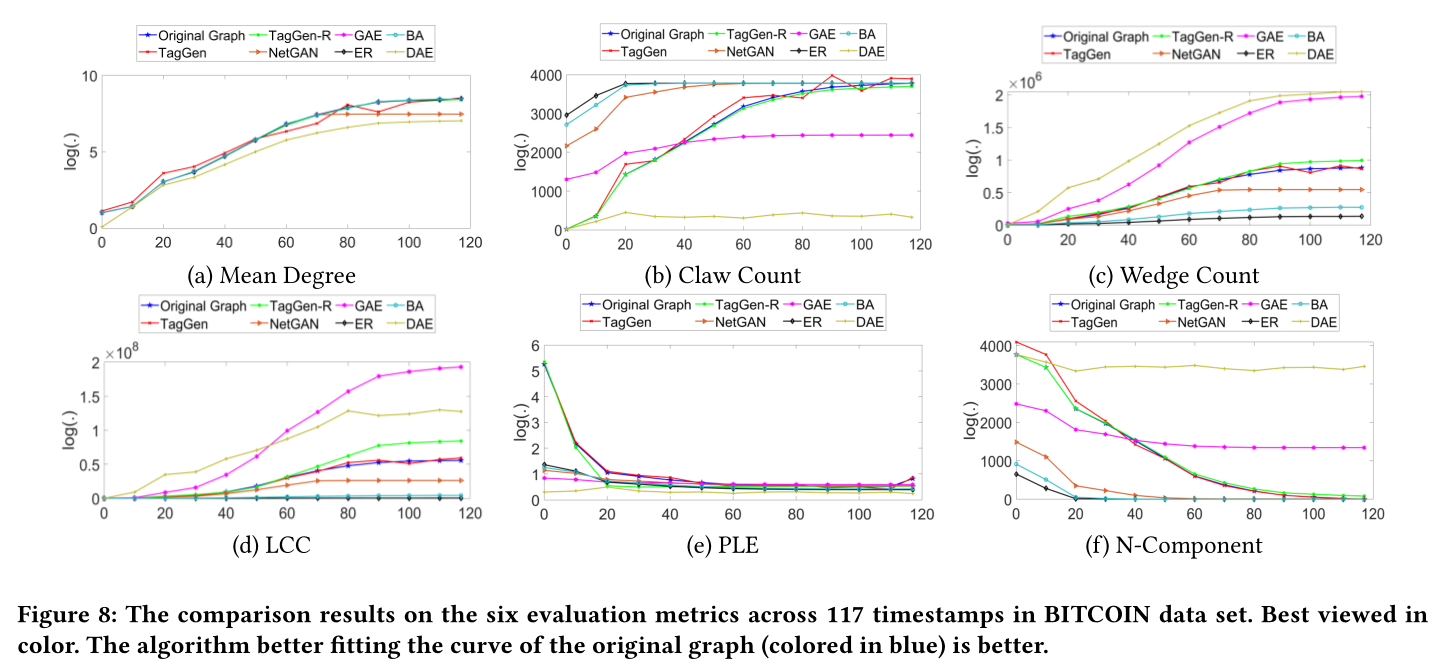
图8 比特币数据集中117个时间步下的6个评估指标的比较结果。更好地拟合原始图(蓝色)曲线的算法是更好的。
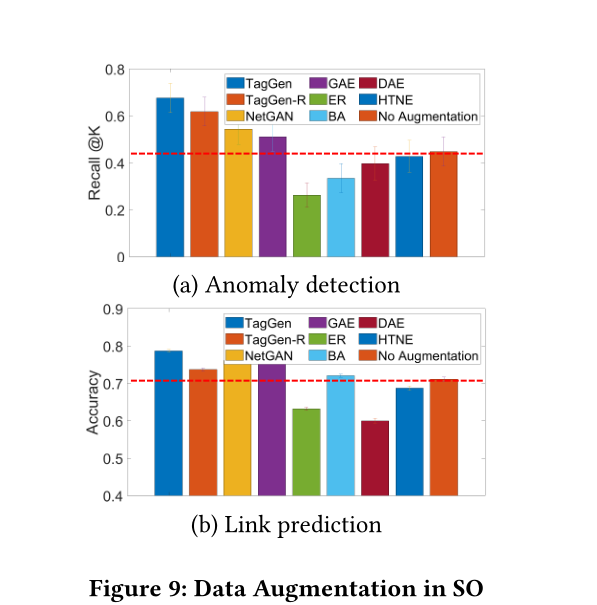
图9 SO中的数据增强
附录:

表1 相关符号
表2 数据集参数
Introduction
动态系统建模的传统方法是通过将时间戳聚合到一系列快照中来构建时间演化图。一个缺点是定义时间演进图的正确粒度的不确定性。在训练深度生成模型时,如果粒度过细,大量的快照会带来难以处理的计算成本;如果粒度太粗,细粒度的时间上下文信息(例如,节点和边的添加/删除)可能会在时间聚合期间丢失。
图2比较了各种图生成器,以说明现有技术与我们的技术相比的局限性。本文的目标是首次解决以下三个挑战(问题二算两个挑战吧):
(问题1)是否可以直接从原始时间网络(即时间交互网络)中学习,而不是构建时间演变图?
(问题2)能否开发一个端到端的深度生成模型,以确保生成的图能够保留原始数据的结构和时间特征(例如,度分布的重尾,以及随着时间的推移不断缩小的网络直径)?
为此,提出了时间交互网络的深层图生成模型TagGen,以解决上述所有挑战。首先提出了一种随机游走抽样策略,从输入图中结合提取关键的结构和时间上下文信息。在此基础上开发了一种双级的自我注意机制,该机制可以从提取的时间随机游动中直接训练,同时保留了时间交互网络的性质。此外,本文设计了一种新的网络上下文生成方案,该方案定义了一系列局部操作来执行节点和边的添加(在时间t随机选择一个节点与另一个节点连接)和删除(随机终止时间t的两个节点之间的交互),从而模拟了真实动态系统的演化过程。特别地,TagGen维护图的状态,并通过训练从提取的时间随机游走生成新的时间边缘。
TagGen中的判别器模块根据所构造图的当前状态接受或拒绝所有图事件的操作。最后,将所选择的真实概率最大的时间随机游走输入组装模块,生成时间网络。
本文的主要贡献总结如下:
问题:正式定义了时间交互网络生成的问题,并确定了其在实际应用中产生的独特挑战。
算法:我们提出了一个端到端的时间交互网络生成学习框架,该框架可以(1)直接从一系列带时间戳的节点和边中学习,(2)保持输入数据的结构和时间特征。
评估:TagGen模型sota
Method
2 PROBLEM DEFINITION
附录表1展示了使用的符号解释
与传统的动态图定义为离散快照序列不同,时间交互网络表示为时间边的集合。每个节点在不同的时间戳上与多个时间戳边相关联,这导致节点\(v=\{v^{t_1},...,v^{T} \}\)出现的次数不同。例如,在图3中,节点\(v_a\)与三次事件的\(\{v_a^{t_1},v_a^{t_2},v_a^{t_3} \}\)相关联。这三次事件分别在\(t_1,t_2,t_3\)发生。在下面将给出时序交互网络和时序事件的形式定义
定义1(时序事件):在一个时间交互网络中,节点\(v\)与一个时序事件包\(\{v^{t_1},v^{t_2},... \}\)相关联,它实例化了节点\(v\)在网络中时间戳\(\{t_1,t_2,... \}\)的事件。
定义2(时间交互网络):时间互动网络\(\widetilde{G}=(\widetilde{V}, \widetilde{E})\)是由节点的集合\(\widetilde{V}=\{v_1,v_2,...v_n \}\)和边的集合\(\widetilde{E} = \{e_1^{t_{e_1}},e_2^{t_{e_2}},...,e_m^{t_{e_m}} \}\)组成的,其中\(e_i^{t_{e_i}} = (u_{e_i},v_{e_i})^{t_{e_i}}\)
定义3 (时间网络邻居):给定一个在时间戳\(t_v\)发生的时序事件\(v^{t_v}\),事件\(v^{t_v}\)的邻居被定义为\(\mathcal{N}_{F T}\left(v^{t_{v}}\right)=\left\{v_{i}^{t_{v_{i}}}\left|f_{s p}\left(v_{i}^{t_{v_{i}}}, v^{t_{v}}\right) \leq d_{\mathcal{N}_{F T}},\right| t_{v}-t_{v_{i}} \mid \leq t_{\mathcal{N}_{F T}}\right\}\),其中\(f_{sp}(·|·)\)两个节点之间的最短路径,\(d_{\mathcal{N}_{F T}}\)是自定义的邻居范围,\(t_{\mathcal{N}_{F T}}\)为自定义邻居时间窗口。
在CTDNE中作者定义了时序随机游走,它是一个遵循时间顺序约束的顶点序列。在本文中,将放宽这一约束:邻居时间窗口\([t_v-t_{\mathcal{N}_{F T}},t_v+t_{\mathcal{N}_{F T}}]\)内的所有节点都是\(v^{t_v}\)的时间邻居,可以从\(v\)通过随机漫步访问。下在面定义了k长度时间游走
定义4 (k长度时间游走):给定一个时序交互网络\(\widetilde{G}\),一个k长度的时间游走\(W=\left\{w_{1}, \ldots, w_{k}\right\}\)被定义为一个接一个遍历的事件时间遍历序列,即\(w_i=(u_{w_i},v_{w_i})^{t_{w_i}}\),其中\(u_{w_i}\)和\(v_{w_i}\)分别为\(W\)中第\(i\)次时间的源节点和目标节点。
有了上述所有的概念,我们准备将时间交互网络生成问题形式化如下。
问题1(时间交互网络生成):
输入:一个时间交互网络\(\widetilde{G}\),表示为时间戳边的集合\(\left\{\left(u_{e_{1}}, v_{e_{1}}\right)^{t_{e_{1}}}, \ldots,\left(u_{e_{m}}, v_{e_{m}}\right)^{t_{e_{m}}}\right\}\)
输出:一个合成的时间交互网络\(\widetilde{G}^{\prime}=\left(\widetilde{V}^{\prime}, \widetilde{E}^{\prime}\right)\),该网络能准确地捕捉到观测到的时间网络\(\widetilde{G}\)的结构和时间特性。
3 MODEL
3.1 A Generic Learning Framework
图4概述了我们提出的框架,它包括四个主要阶段。给定一个由时间边集合(即带时间戳的交互)定义的时间交互网络,我们首先通过一种新的采样策略对的一组时间随机游动进行采样,提取时间交互网络的网络上下文信息。其次,我们开发了一种深层生成机制,它定义了一组简单而有效的操作(即在时间边上的添加和删除)来生成合成随机游走。第三,在采样的时间随机漫步上训练鉴别器,以确定生成的时间漫步是否与真实的时间漫步遵循相同的分布。最后,通过鉴别器收集符合条件的合成时间漫步,生成时间交互网络。在下面的小节中,我们将详细描述TagGen的每个阶段。
Context sampling:受网络嵌入方法deepwalk的启发,作者把时间网络上下文采样问题看作是通过时间随机游走在网络邻域\(\mathcal{N}_{F T}\)上进行局部探索的一种形式。具体来说,给定一个时间事件\(v^{t_v}\),我们的目标是提取一组序列,能够生成其邻居\(\mathcal{N}_{F T}\left(v^{t_{v}}\right)\)。为了公平有效地对邻域上下文进行采样,我们应该从整个数据中选择最具代表性的时间事件作为初始节点。这里我们提出通过计算每个事件\(v^{t_v}\)给定的其时间网络邻居\(\mathcal{N}_{F T}\left(v^{t_{v}}\right)\)的条件概率来估计的上下文重要性\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\),如下所示。
\[p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right)) = p(v^{t_v}|\mathcal{N}_{S}\left(v^{t_{v}}\right),\mathcal{N}_{T}\left(v^{t_{v}}\right))(1) \]其中\(\mathcal{N}_{T}\left(v^{t_{v}}\right)\)和\(\mathcal{N}_{S}\left(v^{t_{v}}\right)\)分别表示\(v^{t_v}\)的时间邻居和结构邻居
\[\begin{array}{c} \mathcal{N}_{T}\left(v^{t_{v}}\right)=\left\{v_{i}^{t_{v_{i}}}|| t_{v}-t_{v_{i}} \mid \leq t_{\mathcal{N}_{F T}}\right\} \\ \mathcal{N}_{S}\left(v^{t_{v}}\right)=\left\{v_{i}^{t_{v_{i}}} \mid f_{s p}\left(v_{i}^{t_{v_{i}}}, v^{t_{v}}\right) \leq d_{\mathcal{N}_{F T}}\right\} \end{array} \]直观上看,当\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\)高时,\(v^{t_v}\)是其邻居的一个代表性节点,这可能是一个很好的随机游走初始点;当\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\)值较低时,\(p(v^{t_v})\)极有可能是一个异常点,其行为与其相邻点发生偏离。这里主要的关键问题是如何评估\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\),如果\(\mathcal{N}_{T}\left(v^{t_{v}}\right)\)和\(\mathcal{N}_{S}\left(v^{t_{v}}\right)\)相互独立,那可以得到
\[p\left(v^{t_{v}} \mid \mathcal{N}_{F T}\left(v^{t_{v}}\right)\right)=p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right) p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)(2) \]然而,在真实的网络中,拓扑上下文和时间上下文在一定程度上是相关的,这在Temporal Information Transformed into a Spatial Code by a Neural Network with Realistic Properties.中已经观察到。例如,度较高的节点(即\(\mathcal{N}_{S}\left(v^{t_{v}}\right)\)较高)在未来的时间戳中具有较高的活跃概率(即\(\mathcal{N}_{T}\left(v^{t_{v}}\right)\)较高),反之亦然。这些观察结果使我们能够指出拓扑邻居分布和时间邻居分布之间存在弱依赖。
定义5(弱依赖):对于任意\(v^{t_{v}} \in \widetilde{V}\),对应的时间邻居分布\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\)与拓扑邻居分布\(p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)之间存在弱依赖关系,使得对于\(\delta > 0\)
\[p\left(v^{t_{v}} \mid \mathcal{N}_{F T}\left(v^{t_{v}}\right)\right) \geq \delta\left[p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right) p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\right] . \]基于定义5,这里尝试建立\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right),p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)和\(p\left(v^{t_{v}} \mid \mathcal{N}_{F T}\left(v^{t_{v}}\right)\right)\)的关系
引理1:对于任意的\(v^{t_{v}} \in \widetilde{V}\),如果时间邻居分布\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\)与拓扑邻居分布\(p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)之间存在弱依赖关系,则有下列不等式成立
\[\begin{array}{l} p\left(v^{t_{v}} \mid \mathcal{N}_{F T}\left(v^{t_{v}}\right)\right) \\ \geq \alpha \frac{p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right) p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right) p\left(\mathcal{N}_{S}\left(v^{t_{v}}\right)\right) p\left(\mathcal{N}_{T}\left(v^{t_{v}}\right)\right)}{p\left(\mathcal{N}_{S}\left(v^{t_{v}}\right), \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)} \end{array}(3) \\其中 \ \alpha=\frac{\delta}{p\left(v^{t}\right)} . \]这个引理的证明可以在附录B中找到。在[30]之后,我们假设\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\)和\(p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)遵循均匀分布,在一个局部区域的所有时间实体都是同等重要的。接着通过计算,\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\),\(p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)和\(p\left( \mathcal{N}_{S}\left(v^{t_{v}}\right),\mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\)(例如,通过核密度估计接近Variable Kernel Density Estimation),对于初始节点的选择,我们可以根据式3推断上下文重要性\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\)。
在选择了初始时间事件后,我们使用有偏差的时间随机游走来提取一个时间游走集合,用于训练TagGen。采用基于随机游走的采样方法的关键原因在于其控制序列长度的灵活性以及联合捕获结构邻域和时间邻域上下文信息的能力。
Sequence generation:要生成合成的时间随机游走,一个简单的解决方案是通过从提取的随机游走[5]学习来训练序列模型。然而,在时间网络环境下,如何模拟网络演化并产生时间交互网络尚不清楚。因此,本文设计了一组局部操作,\(action = \{ add,delete \}\),用于对时间实体进行添加和删除操作,模拟真实动态网络的演化过程。给定一个k长度的时间随机游走\(\widetilde{W}^{(i)}=\left\{\widetilde{w}_{1}^{(i)}, \ldots, \widetilde{w}_{k}^{(i)}\right\}\),我们首先根据自定义的先验分布\(p(\widetilde{W}^{(i)})\)抽样一个候选时间游走段\(\widetilde{w}_{j}^{(i)} \in \widetilde{W}^{(i)}\)。在本文中,我们假设\(p(\widetilde{W}^{(i)})\)服从均匀分布。然后,我们以\(p_{action}= \{ p_{add},p_{delete}\}\)的概率随机执行下列操作之一。
add: 添加操作以两步方式完成。首先,我们在候选时间游走段\(\widetilde{w}_{j}^{(i)}=\left(u_{\widetilde{w}_{j}^{(i)}}, v_{\widetilde{w}_{j}^{(i)}}\right)^{{ }^{w_{j}^{(i)}}}\)中插入一个占位符标志,接着用一个时序实体\(v*^{t_{v*}}\)去代替占位符,然后将游走段分做两段,写作\(\left\{\left(u_{\widetilde{w}_{j}^{(i)}}, v *\right)^{t_{v *}},\left(v *, v_{\widetilde{w}_{j}^{(i)}} \right)^{t_{\widetilde{w}_{j}^{(i)}}}\right\}\)(吐槽一下这个式子,连公式识别都会识别错,有点滥用上下标了)。经过这次的添加以后时间随机游走序列\(\widetilde{W}^{(i)}_{add}\)将会变成k+1。
delete:删除操作从\(\widetilde{W}^{(i)}=\left\{\widetilde{w}_{1}^{(i)}, \ldots, \widetilde{w}_{j}^{(i)}, \ldots, \widetilde{w}_{k}^{(i)}\right\}\)中删除候选的时间游走段\(\widetilde{w}_{j}^{(i)}\),使修改后的时间随机游走\(\widetilde{W}^{(i)}_{delete}\)的长度为k-1
Sample discrimination:为了确保生成的图上下文遵循与输入相似的全局结构分布,TagGen配备了一个判别器模型\(f_\theta(·)\),该模型的作用是区分生成的时间网络是否遵循与原始图相同的分布。对于每个生成的时间随机游走,\(W^{(1 \sim l)}=\{ W^{(1)},...,W^{(l)}\}\)经过一系列的操作\(action = \{add,delete\}\),给定提取的真实时间随机游走\(W^{(1 \sim l)}=\{ W^{(1)},...,W^{(l)}\}\),TagGen计算条件概率\(p\left(\widetilde{W}_{\text {action }}^{(i)} \mid W^{(1 \sim l)}\right)\)如下
\[p\left(\widetilde{W}_{\text {action }}^{(i)} \mid W^{(1 \sim l)}\right) \propto p_{\text {action }}(\text { action }) f_{\theta}\left(\widetilde{W}_{\text {action }}^{(i)}\right) \]其中,\(f_\theta(·)\)计算在给定训练数据\(W^{(1 \sim l)}=\{ W^{(1)},...,W^{(l)}\}\)的情况下,\(\widetilde{W}^{(i)}_{action}\)的可信度,\(p_{\text {action }}(\text { action })\)是\(\widetilde{W}^{(i)}_{action}\)的权重系数。
为了计算并行提高效率,作者使用了Transformer的架构(LSTM或者RNN的架构很难并行,导致效率较低)
但是,使用标准Transformer参数化的直接实现可能无法捕获这种双级依赖项(即节点级依赖项和事件级依赖项)。本文提出了一个双级的自我注意机制,如图5所示。
给定一个长度为k的时间游走\(\widetilde{W}^{(i)}\),首先通过时间网络嵌入方法(CTDNE)为每个节点\(v^t\)(在\(t\)时刻的节点\(v\))得到一个\(d\)维的表示\(\mathbf{Z} \in {\mathbb{R}}^{n \times d}\)。因此,每个节点\(v\)被表示为一个时间事件\(v=\{v^{t1},v^{t2},...,v^T\}\)的包
双层自我注意机制旨在共同学习:
(1)\(\widetilde{G}\)中节点之间的依赖关系
(2)不同时间事件之间的依赖关系。
按照transformer中的符号,我们如下所示定义事件级注意\(\mathbf{A^{occu}} \in {\mathbb{R}}^{n_r \times n_r}\)和节点级注意\(\mathbf{A^{node}} \in {\mathbb{R}}^{n_r \times n_r}\)。
\[\begin{array}{l} \mathbf{A^{occu}}\left(v_{i}^{t_{1}}, v_{j}^{t_{2}}\right)=\frac{\left(z_{i}^{t_{1}} \mathbf{W_{Q}^{o c c u}}\right) \odot\left(z_{j}^{t_{2}} \mathbf{W_{K}^{\text {occu }}}\right)} {\sqrt{d_{k}}}\\ \mathbf{A^{node}}\left(v_{i}^{t_{1}}, v_{j}^{t_{2}}\right)=\frac{\left(f_{a g g}\left(z_{i}^{t_{1}}\right) \mathbf{W_{Q}^{\text {node }}}\right) \odot\left(f_{a g g}\left(z_{j}^{t_{2}}\right) \mathbf{W_{K}^{\text {node }}}\right)}{\sqrt{d_{k}}} \end{array} \]其中\(z^{t1}_i(z^{t1}_j) \in {\mathbb{R}}^{1 \times d}\)是节点\(z^{t1}_i(z^{t1}_j)\)的d维嵌入
\(\mathbf{W_{Q}^{o c c u}} \in {\mathbb{R}}^{d \times d_k}\)和\(\mathbf{W_{K}^{occu}} \in {\mathbb{R}}^{d \times d_k}\)分别是事件级别的query矩阵和key矩阵,
\(\mathbf{W_{Q}^{node}} \in {\mathbb{R}}^{d \times d_k}\)和\(\mathbf{W_{K}^{node}} \in {\mathbb{R}}^{d \times d_k}\)分别是节点级别的query矩阵和key矩阵,
\(d_k\)是一个可调整的维度参数
\(f_{agg}(·)\)是一个聚合函数,它汇总每个节点的所有事件级信息。在实现上,写作\(\operatorname{f_{agg}}\left(v_{i}^{t}\right)=\sum_{v_{i}^{t} \in v_{i}}\mathbf{z_{i}^{t}}\),因此无论时间如何,同一个节点的该函数值总是相同的,例如当\(t_1 \ne t_2\)时,\(\operatorname{f_{agg}}\left(v_{i}^{t_1}\right)=\operatorname{f_{agg}}\left(v_{i}^{t_2}\right)\),这样,\(\mathbf{A^{occu}}\)和\(\mathbf{A^{node}}\)中的元素就完全对齐了。此外,我们引入一个系数\(\lambda \in [0,1]\)来平衡事件级注意和节点级注意,得到最终的双层自我注意\(\mathbf{Z_s}\)
\[\mathbf{Z_s}=[\lambda \times \text{softmax}(\mathbf{A^{node}})+(1-\lambda) \times \text{softmax}(\mathbf{A^{occu}})] \]其中 \(\mathbf{W_vZ}\),\(\mathbf{W_V}\)表示权重矩阵
对于图5中描述的单头部注意,我们在鉴别器\(f_{\theta}(·)\)中使用\(ℎ= 4\)个并行注意层(即头部)来选择合格的合成随机游走\(\widetilde{W}^{(i)}_{action}\)。\(f_{\theta}(·)\)中隐藏表示的更新规则与中定义的标准Transformer模型相同。在阶段3结束时,所有经过\(f_{\theta}(·)\)选择的合成时间随机游走将被输入到阶段2的开始(见图4),逐步修改这些序列,直到满足自定义的停止标准,序列准备合成(阶段4)。
Graph assembling:在此阶段,我们将所有生成的时间随机游走集合起来,生成时间交互网络。首先计算生成的时间随机游走中每个时间边\(e^{t_e}=(u,v)^{t_e}\)的频率计数\(s(e^{t_e})\)。为了确保频率计数是可靠的,所以从原始图中提取了大量的时间随机游走,以避免一些未被表示的时间事件(即度较小的节点)没有抽样。为了将这些频率计数转换为离散的时间边,我们使用以下策略:
(1)首先,我们以\(p\left(v^{t_{v}}, v^{*} \in \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)=\frac{s\left(e^{t_{e}}=\left(v, v^{*}\right)^{t_{v}}\right)}{\sum_{v^{*} \in \mathcal{N}_{S}\left(v^{t_{v}}\right)} s\left(e^{t_{e}}=\left(v, v^{*}\right)^{t_{v}}\right)}\)为概率从每个时间事件\(v^{t_v}\)开始生成至少一条时间边,以确保\(\widetilde{G}\)中所有观察到的时间事件都包含在内;
(2)然后在每个时间戳以概率\(p(e^{t_e})=\frac{s(e^{t_e})}{\sum_{e_i^{t_{e_i}}} s({e_i^{t_{e_i}}})}\)生成至少一个时间边
(3)生成数量最大的时间边,直到生成的图具有与原始图相同的边缘密度。
3.2 Optimization Algorithm

用的SGD,优化算法见算法1。给定的输入包括时间交互网络\(\widetilde{G}\)、邻居范围\(d_{\mathcal{N}_{FT}}\)、邻居时间窗\(t_{\mathcal{N}_{FT}}\)、初始节点数\(l\)、每个初始节点的步行数\(\gamma\)、步行长度K、每个序列的操作数\(c_1\)和常数参数\(\xi \in (0.5,1)\)。对于\(\xi > 0.5\),我们强制添加操作数大于删除操作数。这样,我们就可以避免生成零入口的时间随机游走序列的情况。从步骤1到步骤3,我们从输入数据中抽取一组时间随机游走\(\mathcal{S}\),训练鉴别器\(f_\theta(·)\)。步骤4到步骤14是TagGen的主体,它生成时间随机游走\(\mathcal{S}\)的准确样本数量。
首先以\(W^{(i)}\)的第一个条目初始化每个合成漫步\(\widetilde{W}^{(i)}\),即\(\widetilde{W}^{(i)}={w_1^{(i)}}\)。从步骤7到步骤12,我们执行\(c_1\)次操作(即添加和删除)为每个合成游走\(\widetilde{W}^{(i)}\)生成上下文,并使用鉴别器\(f_\theta(·)\)选择符合条件的时间随机游走存储在\(\mathcal{S’}\)中。最后,步骤15通过确保所有时间事件和时间戳都包含在\(\widetilde{G’}\)中,从而在\(\mathcal{S’}\)的基础上构造\(\widetilde{G’}\)。
Experiment
4 EXPERIMENTAL RESULTS
4.1 Experiment Setup
数据集:DBLP,SO,MO,WIKI,EMAIL,MSG,BITCOIN
baseline: Erdös-Rényi (ER),Barabási-Albert (BA) ,GAE [18],NetGAN [5],HTNE [45], DAE [13]
评价指标:Mean Degree, Claw Count, Wedge Count, PLE, LCC, N-Component但是推广到了动态图。给定一个真实网络\(\widetilde{G}\),合成网络\(\widetilde{G’}\)和用户特定指标\(f_m(·)\),首先通过从初始时间戳到当前时间戳\(t\)的聚合来构造\(\widetilde{G}(\widetilde{G^{\prime}})\)的快照\(\widetilde{S}^{t}(\widetilde{S^{\prime}}^{t}),t=1,...,T\)序列:
\[\begin{array}{c} f_{\text {avg }}\left(\widetilde{G}, \widetilde{G^{\prime}}, f_{m}\right)=\operatorname{Mean}_{t=1: T}\left(\left|\frac{f_{m}\left(\widetilde{S}^{t}\right)-f_{m}\left({\widetilde{S^{\prime}}}^{t}\right)}{f_{m}\left(\widetilde{S^{t}}\right)}\right|\right) \\ f_{\text {med }}\left(\widetilde{G}, \widetilde{G^{\prime}}, f_{m}\right)=\operatorname{Median}_{t=1: T}\left(\left|\frac{f_{m}\left(\widetilde{S}^{t}\right)-f_{m}\left({\widetilde{S^{\prime}}}^{t}\right)}{f_{m}\left(\widetilde{S}^{t}\right)}\right|\right) \end{array} \]4.2 Quantitative Results for Graph Generation
sota见图7,图8
4.3 Case Studies in Data Augmentation
数据增强效果见图9
Summary
时序图+GAN+transformer,综合性很强的论文,其中比较有意思的就是提出那个双级自注意力。
标签:时间,Interaction,Graph,Temporal,right,widetilde,mathcal,游走,left 来源: https://www.cnblogs.com/luoyoucode/p/16483050.html