N-gram 以及 BLEU Score
作者:互联网
参考:
https://zhuanlan.zhihu.com/p/34219483
https://zhuanlan.zhihu.com/p/338488036
https://blog.csdn.net/nstarLDS/article/details/105895113
自然语言处理中的概念:在NLP中,我们需要计算句子的概率大小:
这也就表示一句话的概率——概率大,说明更合理;概率小,说明不合理。
因为是不能直接计算,所以我们先应用条件概率得到:
其中,条件概率P(B|A)指:A 条件下 B 发生的概率。
![]()
然而,如果直接使用条件概率转化后的公式,则需要对每个单词要考虑它前面的所有词,这在实际中意义不大,且不便于计算。
我们可以基于马尔科夫假设来做简化。
马尔科夫假设:
马尔科夫假设指,每个单词出现的概率只跟它前面的少数几个单词有关。比如,二阶马尔科夫假设只考虑前面两个词,相应的语言模型是三元模型。引入了马尔科夫假设的语言模型,也可以叫做马尔科夫模型。
马尔可夫链(Markov chain)为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。
也就是说,应用了这个假设表明了当前单词仅仅跟前面几个有限的词相关,因此也就不必追溯到最开始的单词,这样便可以大幅缩减上述算式的长度。即变成:
注:这里的m表示前m个词相关
然后,我们就可以设置m = 1,2,3,....得到相应的一元模型,二元模型,三元模型了,关于
当 m = 1, 一个一元模型(unigram model)即为 :
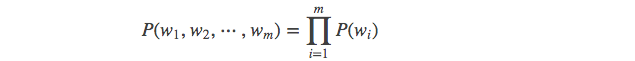
当 m = 2, 一个二元模型(bigram model)即为 :
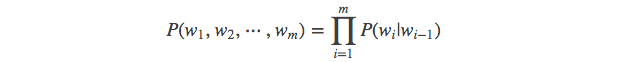
当 m = 3, 一个三元模型(trigram model)即为
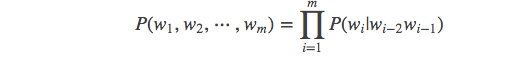
而N-Gram模型也就是这样,当m = 1,叫1-gram或者unigram ;m = 2,叫2-gram或者bigram ;当 m = 3叫3-gram或者trigram ;当m=N时,就表示的是N-gram。
BLEU Score BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具。它是用来评估机器翻译质量的工具。 BLEU的设计思想:机器翻译结果越接近专业人工翻译的结果,则越好。BLEU算法实际上就是在判断两个句子的相似程度。想知道一个句子翻译前后的表示是否意思一致,直接的办法是拿这个句子的标准人工翻译与机器翻译的结果作比较,如果它们是很相似的,说明我的翻译很成功。 例如法语翻译成英语的任务中,源语句是: Le chat est sur le tapis 而翻译成英语的形式多种多样,例如: reference1:The cat is on the mat. reference2:There is a cat on the mat. 这两句都是很不错的人工进行的翻译,那么如何利用这两句话对其他机器翻译得出的结果进行评估呢? 一般衡量机器翻译输出质量的方法之一是观察输出结果的每一个词,看其是否出现在参考(也就是人工翻译结果)中,这被称为是机器翻译的精确度。
- The modified precision measure(N-gram)

分母就是机器翻译得到的语句中所有的n-gram词组个数,分子就是出现在reference中词组(经过截断后)的个数。
- 多元评估的组合
 事实是这样:随着n-gram的增大,精度得分总体上成指数下降的,而且可以粗略的看成随着n而指数级的下降。我们这里采取几何加权平均,并且将各n-gram的作用视为等重要的,即取权重服从均匀分布。
pn 为改进的多元精度,wn 为赋予的权重。对应到上图,公式简单表示为:
p = exp(1/4∗(logp1+logp2+logp3+logp4))
事实是这样:随着n-gram的增大,精度得分总体上成指数下降的,而且可以粗略的看成随着n而指数级的下降。我们这里采取几何加权平均,并且将各n-gram的作用视为等重要的,即取权重服从均匀分布。
pn 为改进的多元精度,wn 为赋予的权重。对应到上图,公式简单表示为:
p = exp(1/4∗(logp1+logp2+logp3+logp4))
- 译句较短惩罚(Sentence brevity penalty )
 r 是参考翻译(reference)的词数,c是候选翻译(candidate)的词数,BP代表译句较短惩罚值。
由此就可以得出最终的BLEU分数:
r 是参考翻译(reference)的词数,c是候选翻译(candidate)的词数,BP代表译句较短惩罚值。
由此就可以得出最终的BLEU分数:
 使用log形式可以更清晰地理解:
使用log形式可以更清晰地理解:

标签:BLEU,词组,机器翻译,cat,单词,Score,gram 来源: https://www.cnblogs.com/mirrorigin/p/16465962.html