go-zero微服务实战系列(十、分布式事务如何实现)
作者:互联网
在分布式应用场景中,分布式事务问题是不可回避的,在目前流行的微服务场景下更是如此。比如在我们的商城系统中,下单操作涉及创建订单和库存扣减操作两个操作,而订单服务和商品服务是两个独立的微服务,因为每个微服务独占一个数据库实例,所以下单操作就涉及到分布式事务问题,即要把整个下单操作看成一个整体,要么都成功要么都不成功。本篇文章我们就一起来学习下分布式事务的相关知识。
基于消息实现最终一致性
我们去店里就餐的时候,付钱点餐后往往服务员会先给我们一张小票,然后拿着小票去出餐口等待出餐。为什么要把付钱和取餐两个动作分开呢?很重要的一个原因是使他们的接客能力更强,对应到服务来说就是使并发处理能力更强。只要我们拿着小票,最终我们是可以拿到我们点的餐的,依靠小票这个凭证(消息)实现最终一致性。
对应到我们的下单操作来说,当用户下单后,我们可以先生成订单,然后发一条扣减库存的消息到消息队列中,这时候订单就算完成,但实际还没有扣减库存,因为库存的扣减和下单操作是异步的,也就是这个时候产生了数据的不一致。当消费到了扣减库存的消息后进行库存扣减操作,这个时候数据实现了最终一致性。
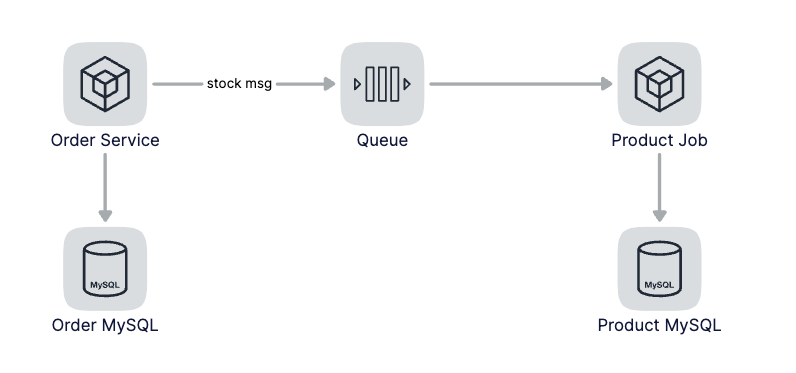
基于消息实现最终一致性这种策略适用于并发量比较高同时对于数据一致性要求不高的场景。我们商城中的一些非主干逻辑可以采用这种方式来提升吞吐,比如购买商品后获取优惠券等非核心逻辑并不需要数据的强一致,可以异步的给用户发放优惠券。
如果在消费到消息后,执行操作的时候失败了该怎么办呢?首先需要做重试,如果重试多次后仍然失败,这个时候需要发出告警或者记录日志,需要人工介入处理。
如果对数据有强一致要求的话,那这种方式是不适用的,请看下下面的两阶段提交协议。
XA协议
说起XA协议,这个名词你未必听说过,但一提到2PC你肯定听说过,这套方案依赖于底层数据库的支持,DB这层首先得要实现XA协议。比如MySQL InnoDB就是支持XA协议的数据库方案,可以把XA理解为一个强一致的中心化原子提交协议。
原子性的概念就是把一系列操作合并成一个整体,要么都执行,要么都不执行。而所谓的2PC就是把一个事务分成两步来提交,第一步做准备动作,第二步做提交/回滚,这两步之间的协调是由一个中心化的Coordinator来管理,保证多步操作的原子性。
第一步(Prepare):Coordinator向各个分布式事务的参与者下达Prepare指令,各个事务分别将SQL语句在数据库执行但不提交,并且将准备就绪状态上报给Coordinator。
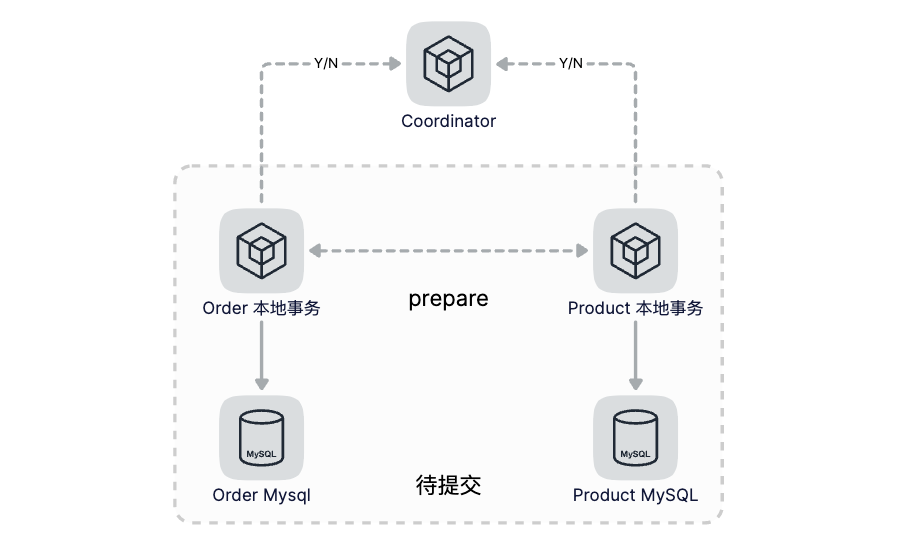
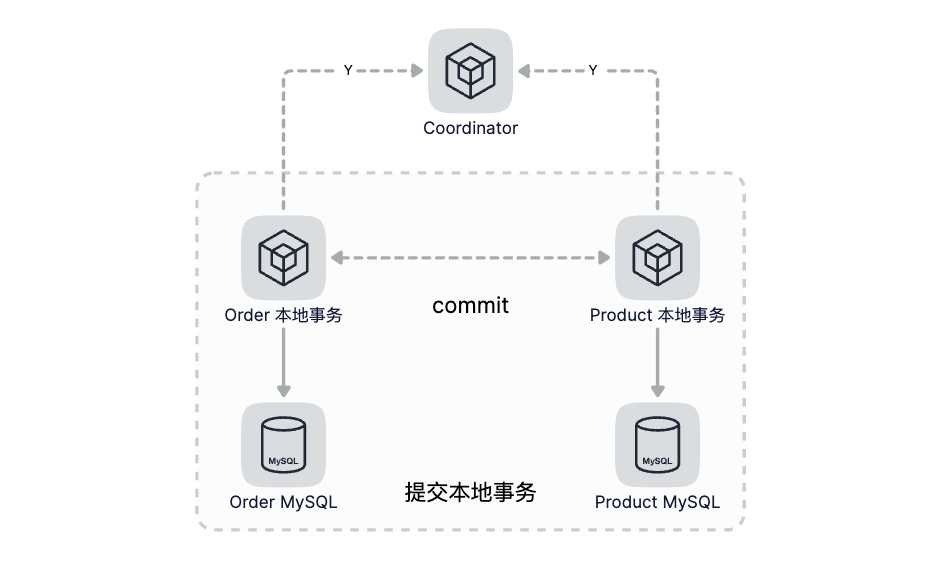
第二步(Commit/Rollback):如果所有节点都已就绪,那么Coordinator就下达Commit指令,各参与者提交本地事务,如果有任何一个节点不能就绪,Coordinator则下达Rollback指令进行本地回滚。
在我们的下单操作中,我们需要创建订单同时商品需要扣减库存,接下来我们来看下2PC是怎么解决这个问题的。2PC引入了一个事务协调者的角色,来协调订单和商品服务。所谓的两阶段是指准备阶段和提交阶段,在准备阶段,协调者分别给订单服务和商品服务发送准备命令,订单和商品服务收到准备命令后,开始执行准备操作,准备阶段需要做哪些事情呢?你可以理解为,除了提交数据库事务以外的所有工作,都要在准备阶段完成。比如订单服务在准备阶段需要完成:
- 在订单库开启一个数据库事务;
- 在订单表中写入订单数据
注意这里我们没有提交订单数据库事务,最后给书屋协调者返回准备成功。协调者在收到两个服务准备成功的响应后,开始进入第二阶段。进入提交阶段,提交阶段就比较简单了,协调者再给这两个系统发送提交命令,每个系统提交自己的数据库事务然后给协调者返回提交成功响应,协调者收到有响应之后,给客户端返回成功的响应,整个分布式事务就结束了,以下是这个过程的时序图:
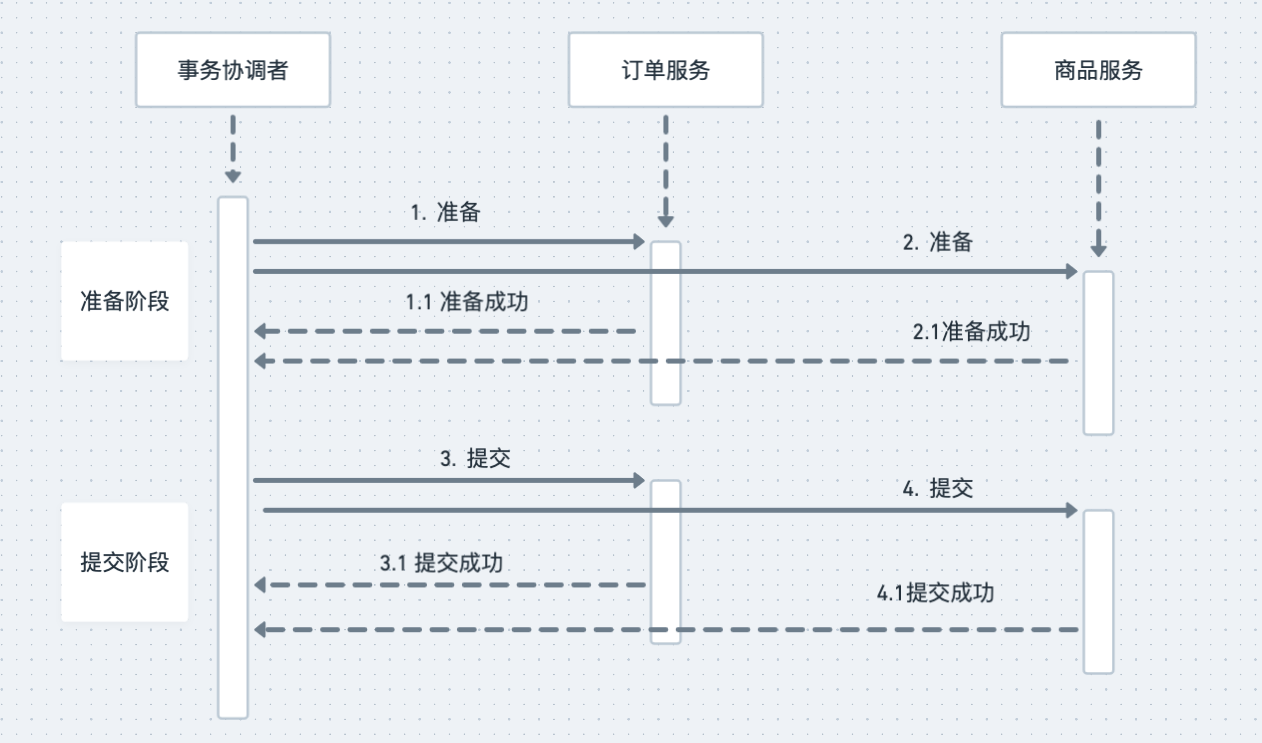
以上是正常情况,接下来才是重点,异常情况怎么办呢?我们还是分两阶段来说明,在准备阶段,如果任何异步出现错误或者超时,协调者就会给两个服务发送回滚事务请求,两个服务在收到请求之后,回滚自己的数据库事务,分布式事务执行失败,两个服务的数据库事务都回滚了,相关的所有数据回滚到分布式事务执行之前的状态,就像这个分布式事务没有执行一样,以下是异常情况的时序图:
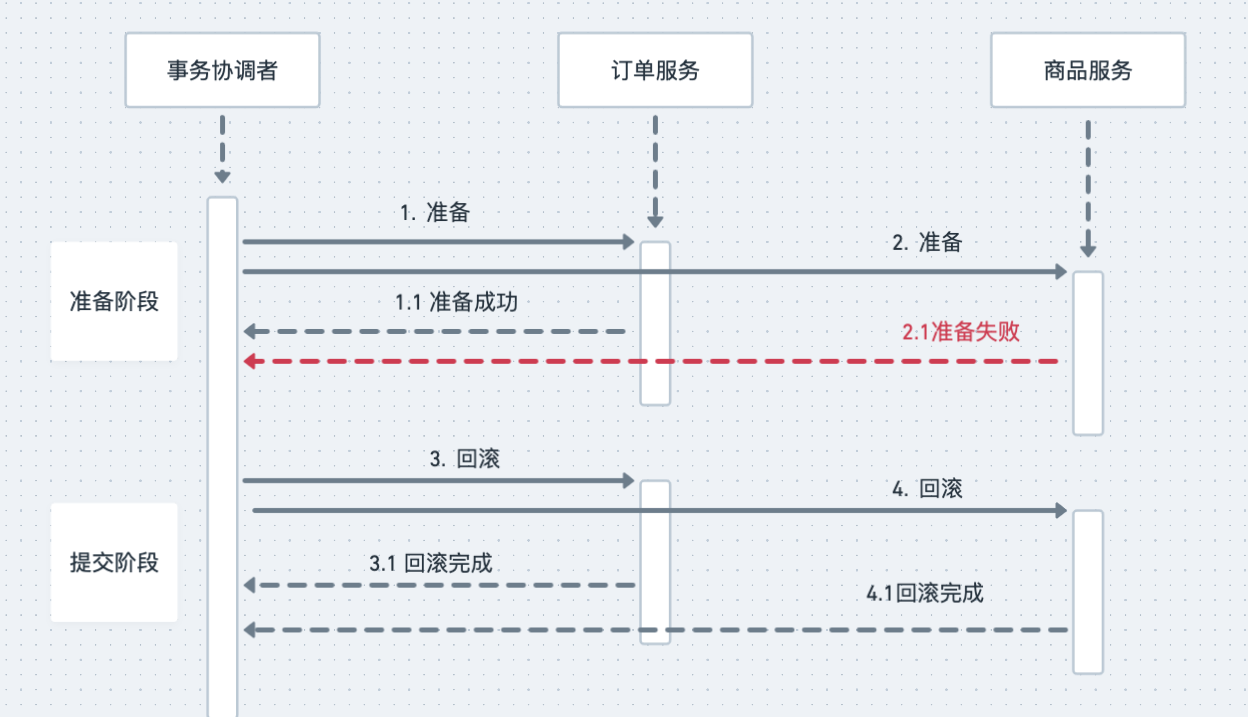
如果准备阶段成功,进入提交阶段,这个时候整个分布式事务就只能成功,不能失败。如果发生网络传输失败的情况,需要反复重试,直到提交成功为止,如果这个阶段发生宕机,包括两个数据库宕机或者订单服务、商品服务宕机,还是可能出现订单库完成了提交,但商品库因为宕机自动回滚,导致数据不一致的情况,但是,因为提交的过程非常简单,执行非常迅速,出现这种情况的概率比较低,所以,从实用的角度来说,2PC这种分布式事务方法,实际的数据一致性还是非常好的。
但这种分布式事务有一个天然缺陷,导致XA特别不适合用在互联网高并发的场景里面,因为每个本地事务在Prepare阶段,都要一直占用一个数据库的连接资源,这个资源直到第二阶段Commit或者Rollback之后才会被释放。但互联网场景的特性是什么?是高并发,因为并发量特别高,所以每个事务必须尽快释放掉所持有的数据库连接资源。事务执行时间越短越好,这样才能让别的事务尽快被执行。
所以,只有在需要强一致,并且并发量不大的场景下,才考虑2PC。
2PC也有一些改进版本,比如3PC,大体思想和2PC是差不多的,解决了2PC的一些问题,但是也会带来新的问题,实现起来也更复杂,限于篇幅我们没法每个都详细的去讲解,在理解了2PC的基础上,大家可以自行搜索相关资料进行学习。
分布式事务框架
想要自己实现一套比较完善且没有bug的分布式事务逻辑还是比较复杂的,好在我们不用重复造轮子,已经有一些现成的框架可以帮我们实现分布式事务,这里主要介绍使用和go-zero结合比较好的DTM。
引用DTM官网的的介绍,DTM是一款变革性的分布式事务框架,提供了傻瓜式的使用方式,极大地降低了分布式事务的使用门槛,改了变了”能不用分布式事务就不用“的行业现状,优雅的解决了服务间的数据一致性问题。
本文作者在写这篇文章之前听过DTM,但从来没有使用过,大概花了十几分钟看了下官方文档,就能照葫芦画瓢地使用起来了,也足以说明DTM的使用是非常简单的,相信聪明的你肯定也是一看就会。接下来我们就使用DTM基于TCC来实现分布式事务。

首先需要安装dtm,我使用的是mac,直接使用如下命令安装:
brew install dtm
给DTM创建配置文件dtm.yml,内容如下:
MicroService:
Driver: 'dtm-driver-gozero' # 配置dtm使用go-zero的微服务协议
Target: 'etcd://localhost:2379/dtmservice' # 把dtm注册到etcd的这个地址
EndPoint: 'localhost:36790' # dtm的本地地址
# 启动dtm
dtm -c /opt/homebrew/etc/dtm.yml
在seckill-rmq中消费到订单数据后进行下单和扣库存操作,这里改成基于TCC的分布式事务方式,注意 dtmServer 和DTM配置文件中的Target对应:
var dtmServer = "etcd://localhost:2379/dtmservice"
由于TCC由三个部分组成,分别是Try、Confirm和Cancel,所以在订单服务和商品服务中我们给这三个阶段分别提供了对应的RPC方法,
在Try对应的方法中主要做一些数据的Check操作,Check数据满足下单要求后,执行Confirm对应的方法,Confirm对应的方法是真正实现业务逻辑的,如果失败回滚则执行Cancel对应的方法,Cancel方法主要是对Confirm方法的数据进行补偿。代码如下:
var dtmServer = "etcd://localhost:2379/dtmservice"
func (s *Service) consumeDTM(ch chan *KafkaData) {
defer s.waiter.Done()
productServer, err := s.c.ProductRPC.BuildTarget()
if err != nil {
log.Fatalf("s.c.ProductRPC.BuildTarget error: %v", err)
}
orderServer, err := s.c.OrderRPC.BuildTarget()
if err != nil {
log.Fatalf("s.c.OrderRPC.BuildTarget error: %v", err)
}
for {
m, ok := <-ch
if !ok {
log.Fatal("seckill rmq exit")
}
fmt.Printf("consume msg: %+v\n", m)
gid := dtmgrpc.MustGenGid(dtmServer)
err := dtmgrpc.TccGlobalTransaction(dtmServer, gid, func(tcc *dtmgrpc.TccGrpc) error {
if e := tcc.CallBranch(
&product.UpdateProductStockRequest{ProductId: m.Pid, Num: 1},
productServer+"/product.Product/CheckProductStock",
productServer+"/product.Product/UpdateProductStock",
productServer+"/product.Product/RollbackProductStock",
&product.UpdateProductStockRequest{}); err != nil {
logx.Errorf("tcc.CallBranch server: %s error: %v", productServer, err)
return e
}
if e := tcc.CallBranch(
&order.CreateOrderRequest{Uid: m.Uid, Pid: m.Pid},
orderServer+"/order.Order/CreateOrderCheck",
orderServer+"/order.Order/CreateOrder",
orderServer+"/order.Order/RollbackOrder",
&order.CreateOrderResponse{},
); err != nil {
logx.Errorf("tcc.CallBranch server: %s error: %v", orderServer, err)
return e
}
return nil
})
logger.FatalIfError(err)
}
}
结束语
本篇文章主要和大家一起学习了分布式事务相关的知识。在并发比较高且对数据没有强一致性要求的场景下我们可以通过消息队列的方式实现分布式事务达到最终一致性,如果对数据有强一致性的要求,可以使用2PC,但是数据强一致的保证必然会损失性能,所以一般只有在并发量不大,且对数据有强一致性要求时才会使用2PC。3PC、TCC等都是针对2PC的一些缺点进行了优化改造,由于篇幅限制所以这里没有详细展开来讲,感兴趣的朋友可以自行搜索相关资料进行学习。最后基于TCC使用DTM完成了一个下单过程分布式事务的例子,代码实现也非常简单易懂。对于分布式事务希望大家能先搞明白其中的原理,了解了原理后,不管使用什么框架那都不在话下了。
希望本篇文章对你有所帮助,谢谢。
每周一、周四更新
代码仓库: https://github.com/zhoushuguang/lebron
项目地址
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。
标签:事务,服务,2PC,订单,zero,提交,go,分布式 来源: https://www.cnblogs.com/kevinwan/p/16456914.html