R语言数据加工厂——plyr包使用
作者:互联网
plyr包是Hadley Wickham大神为解决split – apply – combine问题而写的一个包,其动机在与提供超越for循环和内置的apply函数族的一个一揽子解决方案。使用plyr包可以针对不同的数据类型,在一个函数内同时完成split – apply – combine三个步骤。plyr 的功能已经远远超出数据整容的范围,Hadley在plyr中应用了split-apply-combine的数据处理哲学,即:先将数据分离,然后应用某些处理函数,最后将结果重新组合成所需的形式返回。某些人士喜欢用“揉”来表述这样的数据处理;“揉”,把数据当面团捣来捣去,很哲,砖家们的砖头落下来,拍死人绝不偿命。
一、plyr包函数命名规则
二、plyr包函数命名规则
apply族函数是R语言中很有特色的一类函数,包括了apply、sapply、lapply、tapply、aggregate等等。这一类函数本质上是将数据进行分割、计算和整合。它们在数据分析的各个阶段都有很好的用处。例如在数据准备阶段,我们可以按某个标准将数据分组,然后获得各组的统计描述。或是在建模阶段,为不同组的数据建立模型并比较建模结果。apply族函数与Google提出的mapreduce策略有着一致的思路。因为mapreduce的思路也是将数据进行分割、计算和整合。只不过它是将分割后的数据分发给多个处理核心进行运算。如果你熟悉了apply族函数,那么将数据转为并行运算是轻而易举的事情。plyr包则可看作是apply族函数的扩展,使之更容易运用,功能更为强大。
plyr包的主函数是**ply形式的,其中首字母可以是(d、l、a),第二个字母可以是(d、l、a、_),不同的字母表示不同的数据格式,d表示数据框格式,l表示列表,a表示数组,_则表示没有输出。第一个字母表示输入的待处理的数据格式,第二个字母表示输出的数据格式。例如ddply函数,即表示输入一个数据框,输出也是一个数据框。
3.1 命名规则
plyr的基本函数集
| array | data frame | list | nothing | |
| array | aaply | adply | alply | a_ply |
| data frame | daply | ddply | dlply | d_ply |
| list | laply | ldply | llply | l_ply |
| n replicates | raply | rdply | rlply | r_ply |
| function arguments | maply | mdply | mlply | m_ply |
plyr 与 R-Base基本函数对应表
| array | data frame | list | nothing | |
| array | apply | adply | alply | a_ply |
| data frame | daply | aggregate | by | d_ply |
| list | sapply | ldply | lapply | l_ply |
| n replicates | replicate | rdply | replicate | r_ply |
| function arguments | mapply | mdply | mapply | m_ply |
命名规则:前三行是基本类型。
根据输入类型和输出类型:a=array,d=data frame,l=list,_ 表示输出放弃。第一个字母表示输入,第2个字母表示输出。后两行是对应apply族的replicates和mapply这两个函数,分别表示n次重复和多元函数参数的情况,第2个字母还是表示输出类型。从命名特点来看,我们不需要列出每个函数的情况了,只要从输入和输出两方面分别讨论即可。
3.2 参数说明
a*ply(.data, .margins, .fun, ..., .progress = "none");d*ply(.data, .variables, .fun, ..., .progress = "none");l*ply(.data, .fun, ..., .progress = "none")
这些函数有两到三个主要的参数,依赖于输入的类型:
.data是我们要用来分片-计算-合并的;参数.margins或者.variables****.fun表示用来处理的函数,其它更多的参数(...)是传递给处理函数的;参数.progress用来控制显示一个进度条。
输入
输入类型有三种,每一种类型给出了如何进行分片的不同方法。
a*ply( ):数组(包括矩阵和向量)按维数分为低维的片。
d*ply( ):数据框被变量组合分成子集。
l*ply( ):列表的每个元素就是一个分片。
因此,对输入数据集的分片,不是取决于数据的结构,而是取决于所采用的方法。
三种类型各自的特点:
(a): 输入数组( a*ply )
a*ply的分片特点在于.margins参数,它和apply很相似。对于2维数组, .margins 可以取1,2,或者c(1:2),对应2维数组的3种分片方式。
.margins = 1: Slice up intorows. • .margins = 2: Slice up intocolumns. • .margins = c( 1, 2): Slice up intoindividual cells.
对于2维数组,则有3种分片方式:
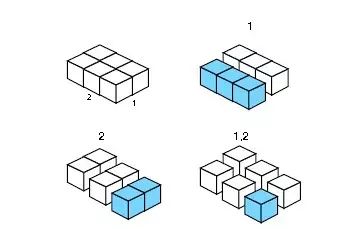
对于3维数组,则有7种分片方式:
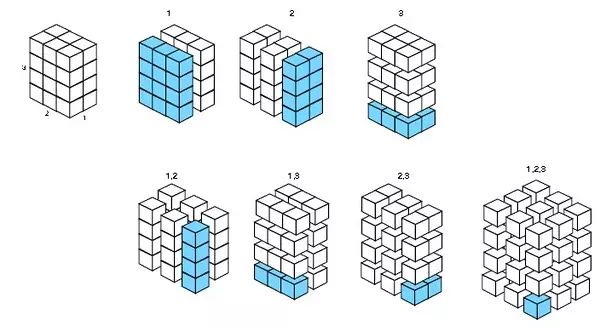
.margins对应更高维的情况,可能会面临一种爆发式的组合。
(b)输入数据框( d*ply )
使用d*ply时,需要特别指定分组所用的变量或变量函数,它们会被首先计算,然后才是整个数据框。
有下面几种指定方式:
.(var1)。按照变量var1的值来对数据框分组 • 多重变量 .(a,b, c)。将按照三个变量的交互值来分组。
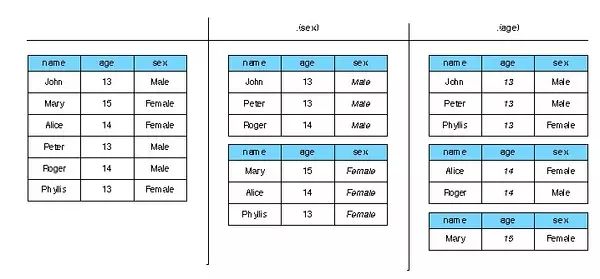
这种形式输出的时候,有点复杂。如果输出为数组,则数组会有三个维度,分别以 a,b,c 的值作为维数名。如果输出为数据框,将会包含 a,b,c 取值的三个额外的列。如果输出为列表,则列表元素名为按周期分割的 a,b,c 的值。
作为列名的字符向量: c( "var1", "var2")。 • 公式~ var1 + var2。
(c) 输入列表( l*ply )
l * ply 不需要描述如何分片的函数,因为列表本身就是按照元素的分划。使用l * ply相当于a*ply作用于一维数组的效果。
三、plyr包应用
这里使用plyr包来进行数据处理,重点在于plyr包的应用,而不是深入地探讨数据的分析。此例来源于 Wickham 的论文[Hadley Wickham :The Split-Apply-Combine Strategy for Data Analysis Journal of Statistical Software,April 2011, Volume 40, Issue 1.],布拉德.皮特在《点球成金》里用数据方法发掘棒球运动员的价值。plyr包的baseball数据集包括了1887-2007年间1228位美国职业棒球运动员15年以上的击球记录。
library(plyr) > data(baseball)> dim(baseball) [ 1] 2169922id:运动员的身份; year:纪录的年份; rbi:跑垒得分,运动员在赛季内的跑动数目; ad:轮到击球或者面对投手的次数。
对某一位运动员:
baberuth <- subset(baseball, id== "ruthba01") > # 在baberuth里加入cyear > baberuth <- transform(baberuth, cyear = year - min(year) + 1)
对所有的运动员:
baseball <- ddply( baseball, .( id), transform, cyear = year - min( year) + 1)
先看看Babe Ruth这位运动员的模式,画rbi/ab(每次击球的跑动)的时间序列图:
library(ggplot2) > cyear <- baberuth\(cyear > ra <- (baberuth\)rbi)/(baberuth$ab) > a <- data.frame(cyear,ra)> p <- ggplot(a,aes(cyear,ra)) > p + geom_line > # 或者(画图代码) > # qplot(cyear, rbi / ab, data= baberuth, geom = "line")
参考文献
(R语言中plyr包 )[https://i.cnblogs.com/posts/edit]
标签:语言,ply,plyr,加工厂,分片,apply,数据,函数 来源: https://www.cnblogs.com/haohai9309/p/16373314.html