云边通信中如何对边缘节点进行流量整形
作者:互联网
云边通信中如何对边缘节点进行流量整形?
收录于 2021-09-25 06:13:55 查看 2988 次 kubernetes KubeEdge Docker Linux1、问题背景
之前项目需要一个功能,但随之而来的问题是:
由于边缘节点网络带宽资源有限,加上云边网络的不稳定性,当边缘节点频繁拉取云端镜像文件时会占用大量的网络带宽,这样会阻碍其他网络应用程序的运行,比如此时我们的交互式SSH会话可能会变得异常迟钝以至于无法使用。因此我们需要一种方法来对高带宽应用进行流量整形。
目前可以根据 image id、container id来对特定容器进行带宽限制,下一步准备在k8s环境中进行运用。
代码地址:YRXING/bandwidth-limit
2、高效Linux限流神器——Trickle
如果在容器内使用trickle工具,加上--cap-add=NET_ADMIN选项
2.1、安装与使用
yum install trickle
#源码编译安装
wget https://codeload.github.com/mariusae/trickle/zip/master
mv master trickle-master.zip
unzip trickle-master.zip
yum -y install autoconf automake libtool libevent-devel
autoreconf -if
./configure
make
make install
#使用时,仅需要放在你想要运行的命令之前
trickle -d <download-rate> -u <update-rate> <command> #单位 KB/s
#trickle还可以以守护进程形式启动,它可以限制通过trickle启动的所有程序的总带宽使用
trickle -d 1000
2.2、trickle如何工作的
Trickle通过控制socket数据读写量来控制和限制应用的上传/下载速度。它使用另一个版本的BSD套接字API,但区别就是trickle还管理socket调用。
但是要注意的是trickle使用动态链接和加载,所以它只对于使用glibc库的程序有用。由于trickle可以设置数据在socket上的传输延迟,所以它可以用来限制一个应用的网络带宽。
Trickle通过在程序运行时,预先加载一个速率限制 socket 库 的方法,trickle 命令允许你改变任意一个特定程序的流量。trickle 命令有一个很好的特性是它仅在用户空间中运行,这意味着,你不必需要 root 权限就可以限制一个程序的带宽使用。要能使用 trickle 程序控制程序的带宽,这个程序就必须使用非静态链接库的套接字接口。当你想对一个不具有内置带宽控制功能的程序进行速率限制时,trickle 就派上用场了。
socket编程中,可以通过修改发送和接收缓冲区的大小,完全利用可用的带宽。
int ret, sock, sock_buf_size;
sock = socket( AF_INET, SOCK_STREAM, 0 );
sock_buf_size = BDP;
ret = setsockopt( sock, SOL_SOCKET, SO_SNDBUF,
(char *)&sock_buf_size, sizeof(sock_buf_size) );
ret = setsockopt( sock, SOL_SOCKET, SO_RCVBUF,
(char *)&sock_buf_size, sizeof(sock_buf_size) );
3、控制网卡带宽——wondershaper
3.1、安装与使用
yum install wondershaper
#使用
wondershaper <interface> <download-rate> <update-rate> #单位KB/s
#比如限制eth0网卡带宽
wondershaper etho 1000 500
#解除限制
wondershaper clear etho
wondershaper实际上是一个shell脚本,它使用tc来定义流量调整命令,使用QoS来处理特定的网络接口。外发流量通过放在不同优先级的队列中,达到限制传出流量速率的目的,而传入流量通过丢包的方式来达到速率限制的目的。
4、Linux自带高级流控——tc
Linux操作系统中的流量控制器TC(Traffic Control)用于Linux内核的流量控制,主要是通过在输出端口处建立一个队列来实现流量控制。tc属于 iproute2 可以直接修改内核的流控设置。
iproute2简介
iproute2是linux下管理控制TCP/IP网络和流量控制的新一代工具包,旨在替代老派的工具链net-tools,即大家比较熟悉的ifconfig,arp,route,netstat等命令。
要说这两套工具本质的区别,应该是net-tools是通过procfs(/proc)和ioctl系统调用去访问和改变内核网络配置,而iproute2则通过netlink套接字接口与内核通讯。
其次,net-tools的用法给人的感觉是比较乱,而iproute2的用户接口相对net-tools来说相对来说,更加直观。比如,各种网络资源(如link、IP地址、路由和隧道等)均使用合适的对象抽象去定义,使得用户可使用一致的语法去管理不同的对象

Linux流量控制主要分为建立队列、建立分类和建立过滤器三个方面。
4.1、原理
它以qdisc-class-filter的树形结构来实现对流量的分层控制


qdisc通过队列将数据包缓存起来,用来控制网络收发的速度class用来表示控制策略filter用来将数据包划分到具体的控制策略中
类(Class)组成一个树,每个类都只有一个父类,而一个类可以有多个子类。某些QDisc(例如:CBQ和HTB)允许在运行时动态添加类,而其它的QDisc(例如:PRIO)不允许动态建立类。允许动态添加类的QDisc可以有零个或者多个子类,由它们为数据包排队。此外,每个类都有一个叶子QDisc,默认情况下,这个叶子QDisc使用pfifo的方式排队,我们也可以使用其它类型的QDisc代替这个默认的QDisc。而且,这个叶子QDisc有可以分类,不过每个子类只能有一个叶子QDisc。 当一个数据包进入一个分类QDisc,它会被归入某个子类。 我们可以使用以下三种方式为数据包归类,不过不是所有的QDisc都能够使用这三种方式:
- tc过滤器(tc filter): 如果过滤器附属于一个类,相关的指令就会对它们进行查询。过滤器能够匹配数据包头所有的域,也可以匹配由ipchains或者iptables做的标记。
- 服务类型(Type of Service): 某些QDisc有基于服务类型(Type of Service,ToS)的内置的规则为数据包分类。
- skb->priority: 用户空间的应用程序可以使用SO_PRIORITY选项在skb->priority域设置一个类的ID。 树的每个节点都可以有自己的过滤器,但是高层的过滤器也可以直接用于其子类。 如果数据包没有被成功归类,就会被排到这个类的叶子QDisc的队中。
4.2、应用
-
针对端口进行限速
#查看现有的队列 tc -s qdisc ls dev eth0 #查看现有的分类 tc -s class ls dev eth0 #创建队列 tc qdisc add dev eth0 root handle 1:0 htb default 1 #添加一个tbf队列,绑定到eth0上,命名为1:0 ,默认归类为1 #handle:为队列命名或指定某队列 #创建分类 tc class add dev eth0 parent 1:0 classid 1:1 htb rate 10Mbit burst 15k #为eth0下的root队列1:0添加一个分类并命名为1:1,类型为htb,带宽为10M #rate: 是一个类保证得到的带宽值.如果有不只一个类,请保证所有子类总和是小于或等于父类. #ceil: ceil是一个类最大能得到的带宽值. #创建一个子分类 tc class add dev eth0 parent 1:1 classid 1:10 htb rate 10Mbit ceil 10Mbit burst 15k #为1:1类规则添加一个名为1:10的类,类型为htb,带宽为10M #为了避免一个会话永占带宽,添加随即公平队列sfq. tc qdisc add dev eth0 parent 1:10 handle 10: sfq perturb 10 #perturb:是多少秒后重新配置一次散列算法,默认为10秒 #sfq,他可以防止一个段内的一个ip占用整个带宽 #使用u32创建过滤器 tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip sport 22 flowid 1:10 #删除队列 tc qdisc del dev eth0 root 配置完成后加入本地启动文件: /etc/rc.local -
针对ip进行限速:
情景: 因为带宽资源有限(20Mbit≈2Mbyte),使用git拉取代码的时候导致带宽资源告警,所以对git进行限速,要求:内网不限速;外网下载速度为1M左右。(注意:此处需要注意单位转换1byte=8bit)...
#!/bin/bash #针对不同的ip进行限速 #清空原有规则 tc qdisc del dev eth0 root #创建根序列 tc qdisc add dev eth0 root handle 1: htb default 1 #创建一个主分类绑定所有带宽资源(20M) tc class add dev eth0 parent 1:0 classid 1:1 htb rate 20Mbit burst 15k #创建子分类 tc class add dev eth0 parent 1:1 classid 1:10 htb rate 20Mbit ceil 10Mbit burst 15k tc class add dev eth0 parent 1:1 classid 1:20 htb rate 20Mbit ceil 20Mbit burst 15k #避免一个ip霸占带宽资源(1有讲到) tc qdisc add dev eth0 parent 1:10 handle 10: sfq perturb 10 tc qdisc add dev eth0 parent 1:20 handle 20: sfq perturb 10 #创建过滤器 #对所有ip限速 tc filter add dev eth0 protocol ip parent 1:0 prio 2 u32 match ip dst 0.0.0.0/0 flowid 1:10 #对内网ip放行 tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dst 12.0.0.0/8 flowid 1:20 -
控制出口流量
基于 classless 队列,我们可以进行故障模拟,也可以用来限制带宽。TC 使用 linux network netem 模块进行网络故障模拟。
#模拟网络延迟 tc qdisc add dev eth0 root netem delay 100ms #添加一个固定延迟到本地网卡eth0 tc qdisc change dev eth0 root netem delay 100ms 10ms #延迟有10ms的上下波动 tc qdisc change dev eth0 root netem delay 100ms 10ms 25% #添加25%的相关概率 tc qdisc change dev eth0 root netem delay 100ms 10ms distribution normal #让波动成正太分布 #模拟网络丢包 tc qdisc change dev eth0 root netem loss 1% #丢包率1% tc qdisc change dev eth0 root netem loss 1% 25% #当前丢包概率与上一条数据包丢包概率有25%的相关性 #模拟数据包重复 tc qdisc change dev eth0 root netem duplicate 1% #模拟数据包损坏 tc qdisc change dev eth0 root netem corrupt 2% #模拟数据包乱序 tc qdisc change dev eth0 root netem gap 5 delay 10ms #没5th的包延迟10ms tc qdisc change dev eth0 root netem delay 10ms reorder 25% 50% # 25%的立刻发送(50%的相关性),其余的延迟 10ms -
控制入口流量
使用 TC 进行入口限流,需要把流量重定向到 ifb 虚拟网卡,然后在控制 ifb 的输出流量
# 开启 ifb 虚拟网卡 modprobe ifb numifbs=1 ip link set ifb0 up # 将 eth0 流量重定向到 ifb0 tc qdisc add dev eth0 ingress handle ffff: tc filter add dev eth0 parent ffff: protocol ip prio 0 u32 match u32 0 0 flowid ffff: action mirred egress redirect dev ifb0 # 然后就是限制 ifb0 的输出就可以了 # ...... -
监视
#显示队列的情况 tc [-s] qdisc|class|filter| ls dev eth0 # -s 显示详细信息
4.3、队列规则Qdisc详解
无分类的qdisc:只能用于root队列
-
[p|b]fifo:简单先进先出(p是package b是byte)
-
pfifo_fast:根据数据包的tos将队列划分到3个band,内核会检查数据包的TOS字段,将“最小延迟”的包放到band0。每个band内部先进先出,一个网络接口上如果没有设置QDisc,pfifo_fast就作为缺省的QDisc。
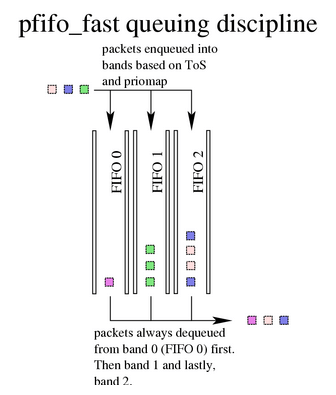
不要将
pfifo_fast qdisc与后面介绍的PRIO qdisc混淆,后者是 classful 的! 虽然二者行为类似,但pfifo_fast是无类别的,这意味你无法通过tc命令向pfifo_fast内添加另一个 qdisc。 -
TBF:对于没有超过预设速率的流量直接透传,但也能容忍超过预设速率的短时抖动。如果想对一个网卡限速,TBF是第一选择。
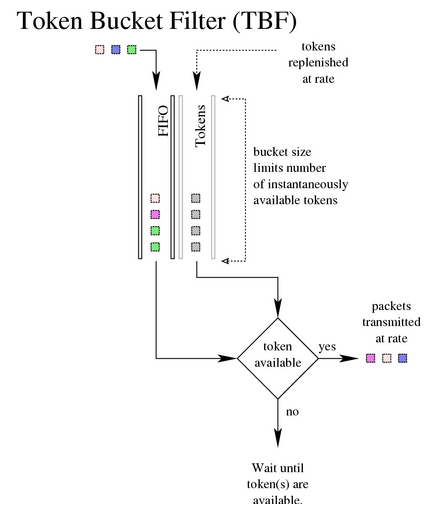
在实际实现中,token基于字节数,而不是包数。下面是一些可配置的参数:
limit or latency: limit是因等待token而被放入队列的字节数,latency是每个包在TBF中停留的时间。limit基于latency、bucket size、rate、 peakrate来计算。 burst/buffer/maxburst: bucket的大小,单位是字节。总体来说,越大的rates就需要越大的缓冲区。要在intel网卡上实现10mbit/s整流,至少需要10kbyte缓冲区,最小缓 冲区的大小可以通过rate/HZ来计算得到。如果缓冲区太小,可能会丢包,因为 token 到来太快导致无法放入 bucket 中。 mpu: 最小包单元,对于以太网,任何一个包的字节数不会少于64 rate: 流量整形速率 peakrate: 默认情况下,包到了之后只要有 token 就会被立即发送。这可能不是你期 望的,尤其当 bucket 很大的时候。peakrate 可指定 bucket 发送数据的最快速度 mtu/minburst: 计算最大可能的 peakrate 时,用 MTU 乘以 100(更准确地说,乘以 HZ 数,例如 Intel 上是 100,Alpha 上是 1024) -
SFQ:按照会话对流量排序并循环发送每个会话的数据包,SFQ将TCP和UDP流量平均的分配至多个FIFO队列中,每个队列对应一个或多个会话,然后按照轮询的方法依次从每个FIFO队列中取数据发送。保证数据发送的公平性。这种方式保证每一个会话都不会被其他会话所淹没,会话通过散列算法映射到某个队列里去。
SFQ 只有在实际出向带宽已经非常饱和的情况下才有效,这一点非常重要!说的更明确一点:没用配套的整流配置的话,单纯在(连接 modem 的)以太网接口上配置SFQ 是毫无意义的。
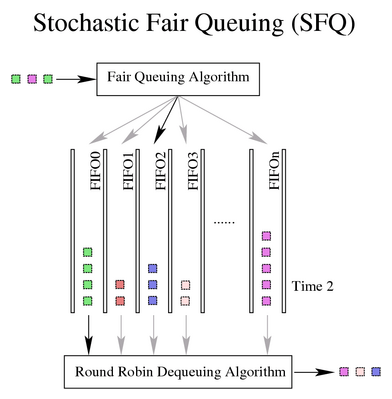
参数和用法:
perturb: 每隔多少秒就重新配置哈希算法,10s是个不错的选择。 quantum: 当前queue允许出队的最大字节数,默认是一个MTU。 limit: SFQ能缓存的最大包数。
使用建议
- 单纯对出口流量限速使用TBF,针对大带宽进行限速,需要将bucket调大。
- 如果带宽已经被打满,想确保带宽没有任何单个session占据,推荐使用SFQ。
- 如果你不需要整形,只是想看看网络接口是否过载,使用pfifo(内部没有bands,但会记录backlog的大小)。
有分类的qdisc(可以包括多个队列)
如果想对不同的流量做不同的处理,那么classful qdisc非常有用。
-
CBQ:基于类的排队规则是最复杂最花哨的,CBQ 的工作原理是:在发送包之前等待足够长的时间,以将带宽控制到期望 的阈值。为实现这个目标,它需要计算包之间的等待间隔。由于它与Linux的工作方式不是太匹配,导致它的算法不精确。
相关参数:
avpkt: 平均包长,单位是字节,计算maxidle会用到 bandwidth: 设备物理带宽,计算idle time会用到 cell: 包长的增长步长,默认值是8,必须是2的幂。 maxburst: 计算 maxidle 时用到,单位:包数(number of packets)。 当 avgidle == maxidle 时,可以并发发送 maxburst 个包,直到 avgidle == 0。 注意 maxidle 是无法直接设置的,只能通过 这个参数间接设置。 minburst: 前面提到,overlimit 情况下 CBQ 要执行 throttle。理想情况下是精确 throttle calculated idel time,然后发送一个包。 但对 Unix 内核来说,通常很难调度 10ms 以下精度的事件,因此最好的方式就是 throttle 更长一段时间,然后一次发 送 minburst 个包,然后再睡眠 minburst 倍的时间。 从较长时间跨度看,更大的 minburst 会使得整形更加精确,但会导致在毫秒级别有更大的波动性。 minidle: 如果 avgidle < 0,那说明 overlimits,需要等到 avgidle 足够大才能发送下一个包。 为防止突然的 burst 打爆链路带宽,当 avgidle 降到一个非常小的值之后,会 reset 到 minidle。minidle单位是负微秒 mpu: 最小包长 rate: 期望离开这个qdisc的流量速率除了整形之外,CBQ 也能完成类似
PRIOqueue 的功能 。每次硬件层请求一个数据包来发送时,都会开启一个 weighted round robin (WRR)过程, 从优先级最高的 class 开始(注意,优先级越高对应的 priority number 越小)allot: 每次轮到一个class时发送的数据量大小 prio: 内部的classes都有一个优先级prio weight: 这个参数用于 WRR 过程。每个 class 都有机会发送数据。如果要指定某个 class 使用更大的带宽,就调大其 weight CBQ 会将一个 class 内的所有权重归一化,因此指定用整数还是小数都没关系:重要的是比例。大家的经验值是 “rate/10”,这个值 看上去工作良好。归一化后的 weight 乘以 allot,决定了每次能发送的数据量除了限制特定类型的流量,还能指定哪些 class 能从另外哪些 class 借容量(borrow capacity)或者说,借带宽
isolated/sharing: 配置了 isolated 的 class 不会向 sibling classes 借出带宽,sharing作用相反 bounded/borrow: 也可以配置 class 为 bounded,这表示它不会向其他 siblings 借带宽,borrow作用相反示例配置:

# webserver 限制为 5Mbps # SMTP 流量限制为 3Mbps # webserver + SMTP 总共不超过6Mbps # 无力网卡是100Mbps # 每个class之间可以互借宽带 tc qdisc add dev eth0 root handle 1:0 cbq bandwidth 100Mbit avpkt 1000 cell 8 tc class add dev eth0 parent 1:0 classid 1:1 cbq bandwidth 100Mbit rate 6Mbit weight 0.6Mbit prio 8 \ allot 1514 cell 8 maxburst 20 avpkt 1000 bounded # 这个1:1class是bounded类型,因此总带宽不会超过设置的6Mbps限制。 tc class add dev eth0 parent 1:1 classid 1:3 cbq bandwidth 100Mbit \ rate 5Mbit wight 0.5Mbit prio 5 allot 1514 cell 8 maxburst 20 avpkt 1000 tc class add dev eth0 parent 1:1 classid 1:4 cbq bandwidth 100Mbit \ rate 3Mbit wight 0.3Mbit prio 5 allot 1514 cell 8 maxburst 20 avpkt 1000 tc qdisc add dev eth0 parent 1:3 handle 30: sfq tc qdisc add dev eth0 parent 1:4 handle 40: sfq #这些过滤规则直接作用在root qdisc,作用是将流量分类到下面正确的qdisc tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 match ip sport 80 0xffff flowid 1:3 tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 match ip sprot 25 0xffff flowid 1:4没有匹配到以上两条规则的流量会进入1:0接受处理,而这里是没有限速的。
如果SMTP+web的总带宽超过6Mbps,那总带宽将根据给定的权重参数分为两部分,5/8给webserver,3/8给邮件服务。也就是说webserver在任何情况下至少能获得5/8 * 6Mbps = 3.75Mbps带宽。
-
HTB:由于CBQ太复杂,devik设计了HTB。
适用场景:
有一个固定总带宽,想将其分割成几个部分,分别用作不同的目的;每个部分的带宽是保证的;还可以指定每个部分向其他部分借带宽。

HTB工作方式与CBQ类似,但不是借助于计算空闲时间来实现整形,在内部,它其实是一个 classful TBF。
示例配置:
# 功能和前面CBQ配置一样的HTB配置 tc qdisc add dev eth0 root handle 1: htb default 30 tc class add dev eth0 parent 1: classid 1:1 htb rate 6mbit burst 15k tc class add dev eth0 parent 1:1 classid 1:10 htb rate 5mbit burst 15k tc class add dev eth0 parent 1:1 classid 1:20 htb rate 3mbit ceil 6mbit burst 15k tc class add dev eth0 parent 1:1 classid 1:30 htb rate 1kbit ceil 6mbit burst 15k #htb作者推荐在这些class内部适用SFQ tc qdisc add dev eth0 parent 1:10 handle 10: sfq perturb 10 tc qdisc add dev eth0 parent 1:20 handle 20: sfq perturb 10 tc qdisc add dev eth0 parent 1:30 handle 30: sfq perturb 10 #将流量导向这些class的过滤器 U32="tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32" U32 match ip dport 80 0xffff flowid 1:10 U32 match ip sport 25 0xffff flowid 1:20未分类的流量会进入30: 这个band带宽很小,但能够从剩余的可用带宽中借带宽来用。
-
PRIO:优先级排队规则实际上并不进行整形,它仅仅根据你配置的过滤器把流量分类,缺省会自动创建三个
FIFO类。(它不允许动态添加类)
prio像是pfifo_fast的升级版,它也有多个band,但每个band都是一个class,如果想基于tc filters而不仅仅是TOS flags做流量的优先级分类,这个qdisc非常有用。由于prio没有流量整形的功能,因此针对SFQ的忠告也适用于这里。

相关参数:
bands: 需要创建的band数量 priomap: 如果没有提供 tc filters 来指导如何对流量分类,那 PRIO qdisc 将依据 TC_PRIO 优先级来决定优先级PRIO qdisc 里面的 band 都是 class,默认情况下名字分别为
major:1、major:2、major:3, 因此如果你的 PRIO qdisc 是12:,那 tc filter 送到12:1的流量就有更高的优先级。重复一遍:band 0 对应的 minor number 是 1! band 1 对应的 minor number 是 2 ,以此类推。
示例配置:

高吞吐量流量将会进入优先级比较低的30:这个band,而交互式流量会进入优先级更高的bands 10:或20:
tc qdisc add dev eth0 root handle 1: prio #立即创建类 1:1 1:2 1:3 tc qdisc add dev eth0 parent 1:1 handle 10: sfq tc qdisc add dev eth0 parent 1:2 handle 20: tbf rate 20kbit buffer 1600 limit 3000 tc qdisc add dev eth0 parent 1:3 handle 30: sfq #查看排队规则 tc -s qdisc ls dev eth0
4.4、用过滤器对流量进行分类
class用来表示控制策略,只用于有分类的qdisc上。每个class要么包含多个子类,要么只包含一个子qdisc。当然,每个class还包括一些列的filter,控制数据包流向不同的子类,或者是直接丢掉。
filter用来将数据包划分到具体的控制策略中,filter是在qdisc内部。包括以下几种:
-
u32:根据协议、IP、端口等过滤数据包# 匹配源/目的IP match ip src/dst 1.2.3.0/24 # 匹配源/目的端口,任何IP协议 match ip sport/dport 80 0xffff # 匹配ip protocol(tcp udp icmp gre ipsec) # 使用/etc/protocols里面的协议号,例如ICMP是1: match ip protocol 1 0xffff -
fwmark:根据iptables MARK来过滤数据包# 可以用ipchains/iptables等工具对包打标(mark),这些mark在不同接口之间路由时是不会丢失的 # 例如:只对从eth0进入eth1的流量进行整形的功能 tc filter add dev eth1 protocol ip parent 1: prio 1 handle 6 fw flowid 1:1 iptables -A PREROUTING -t mangle -i eth0 -j MARK --set-mark 6 #下面的命令会打印 mangle 表内所有的 mark 规则,已经每个规则已经匹配到多少包和字节数: iptables -L -t mangle -n -v -
tos:根据tos字段过滤数据包#选择交互式、最小延迟流量: tc filter add dev ppp0 parent 1: protocol ip prio 10 u32 match ip tos 0x10 0xff flowid 1:4 #高吞吐流量(bulk traffic)对应的过滤条件是 0x08 0xff

当enqueue一个包时,在每一个分叉的地方都需要查询相关的过滤规则。
一种配置是:在1:1配置一个filter,将包送到12: 。在12:配置一个filter,将包送到12:2
另一种配置是将两个filter都配置在1:1,但将更精确的filter放到更下面的位置有助于提升性能。
需要注意的是,包是无法向上过滤的(filter a packet ‘upwards’)。 另外,使用 HTB 时,所有的 filters 必须 attach 到 root!
示例配置:
# 假设一个名为10:的PRIO qdisc,我们想将端口22的流量都导向优先级最高的band
tc filter add dev eth0 protocol ip parent 10: prio 1 u32 match ip dport 22 0xffff flowid 10:1
tc filter add dev eth0 protocol ip parent 10: prio 1 u32 match ip sprot 80 0xffff flowid 10:1
tc filter add dev eth0 protocol ip parent 10: prio 2 flowid 10:2 #为匹配上面的包都发送到优先级次高的band 10:2
# 精确匹配单个IP地址
tc filter add dev eth0 parent 10: protocol ip prio 1 u32 match ip dst 4.3.2.1/32 flowid 10:1
tc filter add dev eth0 parent 10: protocol ip prio 1 u32 match ip src 1.2.3.4/32 flowid 10:1
tc filter add dev eth0 parent 10: protocol ip prio 2 flowid 10:2
#这会将 dst_ip=4.3.2.1 或 src_ip=1.2.3.4 的流量送到优先级最高的队列,其他流量送到优先级次高的队列
#还可以将多个match级联起来,同时匹配源IP和port
tc filter add dev eth0 parent 10: protocol ip prio 1 u32 match ip port src 4.3.2.1/32 \
match ip port 80 0xffff flowid 10:1
4.5、ingress shaping
IMQ
中介队列设备用来解决两个局限:
- 只能进行出口整形
- 一个队列规定只能处理一块网卡的流量,无法设置全局的限速
对外部进来的包先打上标记(mark),打了标的包在经过 netfilter NF_IP_PRE_ROUTING 和 NF_IP_POST_ROUTING hook 点时会被捕获,送到 IMQ 设备上 attach 的 qdisc。就能实现入向整型(ingress shaping);将接口们作为 classes(treat interfaces as classes),就能设置全局限速。
示例配置:
tc qdisc add dev imq0 root handle 1: htb default 20
tc class add dev imq0 parent 1: classid 1:1 htb rate 2mbit burst 15k
tc class add dev imq0 parent 1:1 classid 1:10 htb rate 1mbit
tc class add dev imq0 parent 1:1 classid 1:20 htb rate 1mbit
tc qdisc add dev imq0 parent 1:10 handle 10: pfifo
tc qdisc add dev imq0 parent 1:20 handle 20: sfq
tc filter add dev imq0 parent 10:0 protocol ip prio 1 u32 match \
ip dst 10.0.0.230/32 flowid 1:10
接下来选中流量,给他们打上标记,以便被正确送到imq0设备:
iptabels -t mangle -A PREROUTING -i eth0 -j IMQ --todev 0
ip link set imq0 up
ifb——见5.3
5、Linux网络测试工具
5.1、实时网络流量监控——iftop
Iftop工具主要用来显示本机网络流量情况及各相互通信的流量集合,如单独同哪台机器间的流量大小,非常适合于代理服务器和iptables服务器使用,这样可以方便的查看各客户端流量情况。iftop可以用来监控网卡的实时流量(可以指定网段)、反向解析IP、显示端口信息等,详细的将会在后面的使用参数中说明。
# 安装所需依赖包
yum -y install flex byacc libpcap ncurses ncurses-devel libpcap-devel
wget http://www.ex-parrot.com/pdw/iftop/download/iftop-0.17.tar.gz #下载安装包
tar zxvf iftop-0.17.tar.gz #解压
cd iftop-0.17
./configure --prefix=/usr/local/iftop #配置安装目录
make && make install #编译、安装
cp /usr/local/iftop /usr/local/bin

- 默认使用第一个网络接口
eth0 - 默认显示
rates的3列数据分别表示:最近2秒,10秒和40秒的平均流量。 peak指网络速率的尖峰值(最大)cum表示累积流量cumulative,在交互界面时按下T就可以看到主机对之间累计的网络数据流量
交互界面操作
T- 显示或隐藏累积网络数据量(cumulative),会在显示主机对的3列网络速率rate左边再增加一列显示累积数据量cumS- 显示源端端口D- 显示目的端端口n- 显示主机IP地址而不是解析的主机名1/2/3- 按照指定列进行排序<- 根据源名字排序>- 根据目的名字排序P- 暂停显示(否则就不断更新当前显示)j/k- 滚动显示?- 帮助
过滤和排序&启动参数
在交互模式,按下l(表示limit)会在顶端显示一个文本输入框,可以输入过滤规则,只显示特定内容。
iftop大多数启动参数和交互界面的快捷键相关。
使用-f参数是一种过滤特性数据包的方法,可以组合网络,主机或端口。例如以下只显示在/dev/wlan0无限网卡接口的ssh数据包
iftop -i wlan0 -f "dst port 22"
| 过滤器 | 描述 |
|---|---|
| dst host 1.2.3.4 | 所有目标地址是1.2.3.4的数据包 |
| src port 22 | 所有从端口22发出的数据包 |
| dst portrange 22-23 | 端口范围是22到23的数据包 |
| gateway 1.2.3.5 | 使用网关地址1.2.3.5的数据包 |
5.2、带宽测试工具——iperf3
Iperf可以测试最大TCP和UDP带宽性能,具有多种参数和UDP特性,可以根据需要调整,可以报告带宽、延迟抖动和数据包丢失.对于每个测试,它都会报告带宽,丢包和其他参数,可在Windows、Mac OS X、Linux、FreeBSD等各种平台使用,是一个简单又实用的小工具。
Iperf3也是C/S(客户端/服务器端)架构模式,在使用iperf3测试时,要同时在server端与client端都各执行一个程序,让它们互相传送报文进行测试。
yum install -y iperf3
服务端命令行
-s 表示服务器端;
-p 定义端口号;
-i 设置每次报告之间的时间间隔,单位为秒,如果设置为非零值,就会按照此时间间隔输出测试报告,默认值为零
客户端命令行
-c 表示服务器的IP地址;
-p 表示服务器的端口号;
-t 参数可以指定传输测试的持续时间,Iperf在指定的时间内,重复的发送指定长度的数据包,默认是10秒钟.
-i 设置每次报告之间的时间间隔,单位为秒,如果设置为非零值,就会按照此时间间隔输出测试报告,默认值为零;
-w 设置套接字缓冲区为指定大小,对于TCP方式,此设置为TCP窗口大小,对于UDP方式,此设置为接受UDP数据包的缓冲区大小,限制可以接受数据包的最大值.
--logfile 参数可以将输出的测试结果储存至文件中.
-J 来输出JSON格式测试结果.
-R 反向传输,缺省iperf3使用上传模式:Client负责发送数据,Server负责接收;如果需要测试下载速度,则在Client侧使用-R参数即可.
-u 采用udp协议
6、实验过程
实验一共两个节点,IP为172.16.9.3/172.16.9.5。通过改变5号机的tc策略,将其带宽限制在某个值以内,然后用3号机测试上传速度是否符合预期。本次实验主要测试tc的入口流量限制能否有效。
先看一下两个节点之间原本的带宽。
#3号机
iperf3 -s -p 80
#5号机
ieprf3 -c 172.16.9.3 -p 80 -R #测试下载速度

现在限制5号机入口流量
#按照前面方法将流量重定向到ifb0网卡
tc qdisc add dev ifb0 root tbf rate 100mbit latency 50ms burst 1600

可以看到带宽为80Mbit,虽然有误差,但已经达起到了限制入口流量的作用。经过调试发现这么大的误差跟burst参数值的设置有关,我索性增加10倍,改为16000。
让我们多测几次看一看误差有多少,发现只要burst值设置的够大,基本有4%-5%的误差,可以接受。
| 限制带宽 | 实际带宽 | Burst | 误差 |
|---|---|---|---|
| 10mbit | 9.67mbit | 16000 | 3.3% |
| 100mbit | 96mbit | 16000 | 4% |
| 200mbit | 142mbit | 1600 | 29% |
| 350mbit | 336mbit | 160000 | 4% |
| 350mbit | 333mbit | 16000 | 4.9% |
| 500mbit | 478mbit | 16000 | 4.4% |
7、拓展
7.1、百度网盘是怎么限速的?
百度网盘是在服务器端做了限速,控制发送数据的频率来实现,而pandownload破解限速的原理就是开启多线程。
7.2、QoS
服务质量(英语:Quality of Service,缩写QoS)是一个术语,在分组交换网络领域中指网络满足给定业务合约的几率;或在许多情况下,非正式地指分组在网络中两点间通过的几率。QoS是一种控制机制,它提供了针对不同用户或者不同数据流采用相应不同的优先级,或者是根据应用程序的要求,保证数据流的性能达到一定的水准。QoS的保证对于容量有限的网络来说是十分重要的,特别是对于流多媒体应用,例如VoIP和IPTV等,因为这些应用常常需要固定的传输率,对延迟也比较敏感。
分组排序和带宽分配的QoS机制分别是排队和带宽管理。然而,在实施之前,必须使用分类工具区分流量。根据策略对流量进行分类使组织能够为其最重要的应用程序确保资源的一致性和足够的可用性。
流量可以按端口或 IP 进行粗略分类,也可以使用更复杂的方法(例如按应用程序或用户)进行分类。后面的参数允许更有意义的识别,并因此对数据进行分类
7.3、ifb虚拟网卡是什么?
Linux TC是一个控发不控收的框架,然而这是对于TC所置于的位置而言的,而不是TC本身的限制,事实上,你完全可以自己在ingress点上实现一个队列机制,说TC控发不控收只是因为Linux TC目前的实现没有实现ingress队列而已。
ifb驱动模拟一块虚拟网卡,它可以被看作是一个只有TC过滤功能的虚拟网卡,说它只有过滤功能,是因为它并不改变数据包的方向,即对于往外发的数据包被 重定向到ifb之后,经过ifb的TC过滤之后,依然是通过重定向之前的网卡发出去,对于一个网卡接收的数据包,被重定向到ifb之后,经过ifb的TC 过滤之后,依然被重定向之前的网卡继续进行接收处理,不管是从一块网卡发送数据包还是从一块网卡接收数据包,重定向到ifb之后,都要经过一个经由ifb 虚拟网卡的dev_queue_xmit操作。

除 了ingress队列之外,在多个网卡之间共享一个根Qdisc是ifb实现的另一个初衷,可以从文件头的注释中看出来。如果你有10块网卡,想在这10 块网卡上实现相同的流控策略,你需要配置10遍吗?将相同的东西抽出来,实现一个ifb虚拟网卡,然后将这10块网卡的流量全部重定向到这个ifb虚拟网 卡上,此时只需要在这个虚拟网卡上配置一个Qdisc就可以了。
7.4、数据包传输过程中用到的各种队列
驱动程序队列(又名环形缓冲区)
在IP堆栈和NIC之间是驱动程序队列,该队列不包含数据包数据,他由指向称为套接字内核缓冲区SKB的其他数据结构的描述符组成,这些数据结构保存数据包数据,并在整个内核中使用。
驱动程序队列存在的原因是为了确保每当系统有数据要传输时,这些数据都可以立即传输给 NIC,也就是说它充当生产者-消费者中的缓存作用,使得数据的生产和消费异步起来,提高效率。

来自堆栈的大数据包
大多数NIC都有一个固定的最大传输单元MTU,对于以太网默认为1500字节。如果应用程序向TCP套接字写入2000字节,则IP堆栈需要创建两个IP数据包并通过驱动程序队列传输,更多的数据包意味着更多的网络协议头部开销。为了避免这种情况,Linux内核实施了很多优化:TCP分段卸载(TSO)、UDP分段卸载(UFO)和通用分段卸载(GSO)。

当启用 TSO、UFO 或 GSO 时,可以将大数据包发送到 NIC。这会大大增加驱动程序队列中的字节数。得注意的是,Linux 还具有接收端优化,其操作类似于 TSO、UFO 和 GSO。这些优化的目的还在于减少每个数据包的开销。具体来说,通用接收卸载 ( GRO ) 允许 NIC 驱动程序将接收到的数据包组合成一个大数据包,然后将其传递到 IP 堆栈。在转发数据包时,GRO 允许重构原始数据包,这是保持 IP 数据包端到端性质所必需的。然而,有一个方面的影响,当大数据包在转发操作的传输侧被分解时,它会导致流的多个数据包同时排队。数据包的这种“微突发”会对流间延迟产生负面影响。
饥饿和延迟
尽管有其必要性和好处,但 IP 堆栈和硬件之间的队列引入了两个问题:饥饿和延迟。
如果NIC驱动程序唤醒以从队列中拉出数据包进行传输,并且队列为空,则硬件将错过传输机会,从而降低系统的吞吐量。这被称为饥饿。如果在一个繁忙的系统中,IP堆栈将获得更少的机会把数据包添加到缓冲区,那么硬件很可能在新的数据包到来之前消耗完缓冲区,因此需要一个大的缓冲区来减少饥饿的可能并确保高吞吐量,但它的缺点是引入大量延迟。

上图驱动程序队列中,几乎充满了高带宽,大容量的TCP段,排在最后的是来自 VoIP 或游戏流的数据包(黄色)。VoIP 或游戏等交互式应用程序通常以固定间隔发出小数据包,这些数据包对延迟敏感,而高带宽数据传输会产生更高的数据包速率和更大的数据包。这种较高的数据包速率可以填充交互数据包之间的缓冲区,从而导致交互数据包的传输延迟。
因此,为驱动程序队列选择合适的大小是一个“Goldilocks problem”。
字节队列限制BQL
字节队列限制 (BQL) 是最近的 Linux 内核 (> 3.3.0) 中的一项新功能,它试图自动解决驱动程序队列大小的问题。这是通过添加一个层来实现的,该层基于计算在当前系统条件下避免饥饿所需的最小缓冲区大小来启用和禁用对驱动程序队列的排队。回想之前,排队数据量越小,排队数据包所经历的最大延迟越低。
理解 BQL 不会改变驱动程序队列的实际大小是关键。而是 BQL 计算当前时间可以排队的数据量(以字节为单位)的限制。超过此限制的任何字节都必须由驱动程序队列上方的层保留或丢弃。
BQL 基于测试设备是否处于饥饿状态。如果它被饿死,那么 LIMIT 会增加,允许更多的数据排队,从而减少饿死的机会。如果设备在整个时间间隔内都处于忙碌状态,并且队列中仍有字节要传输,则队列大于当前条件下系统所需的队列,并且减少 LIMIT 以限制延迟,这个机制有点类似于TCP的拥塞控制机制。
BQL 通过将排队数据量限制为避免饥饿所需的最低限度来减少网络延迟。它还具有非常重要的副作用,将大多数数据包排队的点从驱动程序队列(一个简单的 FIFO)移动到队列规则 (QDisc) 层,该层能够实现更复杂的排队策略。
排队规则Qdisc
驱动程序队列是一个简单的先进先出 (FIFO) 队列。它平等地对待所有数据包,并且没有区分不同流的数据包的能力。这种设计使 NIC 驱动程序软件保持简单和快速。夹在 IP 堆栈和驱动程序队列之间的是排队规则 (QDisc) 层。该层实现了 Linux 内核的流量管理功能,包括流量分类、优先级和速率整形。
默认情况下,每个网络接口都分配了一个pfifo_fast QDisc,它基于 TOS 位实现了一个简单的三频段优先级方案。类和过滤器的概念不在介绍。
传输层和排队规则之间的缓冲
在查看前面的图时,您可能已经注意到在排队规则层之上没有数据包队列。这意味着网络数据包直接放入排队规则中,对于具有单个队列的 QDisc,会出现上图中针对驱动程序队列概述的相同问题。也就是说,单个高带宽或高数据包速率流会消耗队列中的所有空间,从而导致数据包丢失并给其他流增加显着的延迟。
从 Linux 3.6.0 (2012-09-30) 开始,Linux 内核有一个名为 TCP Small Queues 的新功能,旨在解决 TCP 的这个问题。
另一个部分解决方案是使用一个 QDisc,它有许多队列,理想情况下每个网络流一个。随机公平队列 ( SFQ ) 和具有受控延迟的公平队列 ( fq_codel ) QDisc 都很好地解决了这个问题,因为它们实际上每个网络流都有一个队列。
如何在Linux中操作队列大小
ethtool命令用于控制以太网设备驱动程序队列的大小。ethtool 还提供低级接口统计信息以及启用和禁用 IP 堆栈和驱动程序功能的能力。

而BQL算法是自调整的,因此不需要过多地弄乱它。如果非要修改,那么需要覆盖计算出的LIMIT值的上限,根据NIC的位置和名称,可以在/sys目录中找到BQL的状态和配置。在我的服务器上,eth0目录是/sys/devices/pci0000:00/0000:00:14.0/net/eth0/queues/tx-0/byte_queue_limits。
这个目录下主要的两个文件:
- limit_max:LIMIT的可配置最大值,将此值设置得较低以优化延迟
- limit_min:LIMIT的可配置最小值,将此值设置得较高以优化吞吐量
什么是txqueuelen

Linux 中传输队列的长度默认为 1,000 个数据包,这是一个很大的缓冲,尤其是在低带宽下。txqueuelen 仅用作某些排队规则的默认队列长度。
对于大多数排队规则,tc命令行上的limit参数会覆盖txqueuelen的默认值,也可以通过ip命令设置。
ip link set txqueuelen 500 dev eth0
7.5、微服务限流是限制带宽吗?
微服务限流是通过对并发/请求进行限速来保护系统,防止系统过载,限流的方式有:
- QPS:限制每秒的请求数
- 并发数:避免开启过多县城导致资源耗尽
- 连接数:限制TCP连接数
所以,微服务的限流并不是限制带宽,而是限制一定时间区间内的并发数量,而常见的限流算法:漏桶算法、令牌桶算法等是针对这个的。Golang标准库中也自带了限流算法的实现golang.org/x/time/rate,该限流器是基于Token Bucket实现的。
参考链接:
How to limit network bandwidth on Linux
Linux Advanced Routing & Traffic Control HOWTO
Trickle: A Userland Bandwidth Shaper for Unix-like Systems
Queue in the Linux Network Stack
https://cloud.tencent.com/developer/article/1409664
图解linux网络包接收过程
多线程下载 一个大文件的速度更快的真正原因是什么
linux网络工具iproute2的使用简介
Linux TC的ifb原理以及ingress流控
标签:qdisc,云边,整形,dev,tc,add,数据包,节点,eth0 来源: https://www.cnblogs.com/zafu/p/15898784.html