微服务架构 | 怎样解决超大附件分片上传?
作者:互联网
导读:分片上传、断点续传,这两个名词对于做过或者熟悉文件上传的朋友来说应该不会陌生,总结本篇文章希望对从事相关工作的同学能够有所帮助或者启发。
当我们的文件特别大的时候,上传是不是需要很长的时间啊,这么长时间的长连接,如果网络波动了呢?中间网络断开了呢?在这么长时间的过程中如果出现不稳定的情况,本次上传的所有内容就全部失败了,又要重新上传。
分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为 Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。分片上传不仅可以避免因网络环境不好导致的一直需要从文件起始位置还是上传的问题,还能使用多线程对不同分块数据进行并发发送,提高发送效率,降低发送时间。
一、背景
在系统用户量突增以后,为了更好适配各群体的定制化需求。业务上慢慢实现了支持 C 端用户自定义布局和配置,导致配置数据读取 IO 激增。
为了更好优化此类场景,将用户自定义配置静态化管理!也就是将对应的配置文件生成静态文件,在生成静态文件的过程中遇到棘手的问题,配置文件文件过大导致在文件上传服务器等待时间过长,致使整个业务场景性能整体下滑。
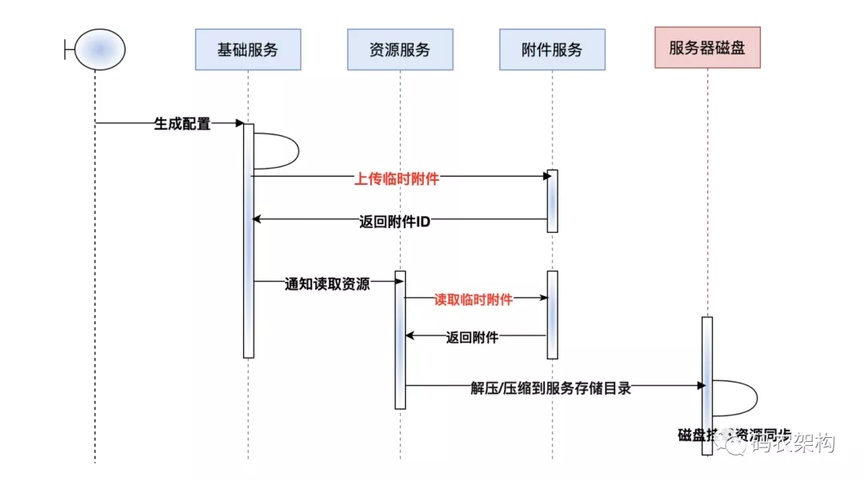
二、生成配置文件
生成文件三大要素
-
文件名
-
文件内容
-
文件存储格式
文件内容、文件存储格式都好理解和处理,当然先前整理过微服务中常用的加密方式
这里做下补充说明,如果要想对文件内容进行加密可以考虑。但是本文的案例场景对于配置信息保密程度较低,这里不做拓展。
而对于文件名的命名规范具体结合业务场景来定,通常都是以文件概要+时间戳格式为主。但是这类命名规范容易导致文件名冲突,造成没有必要的后续麻烦。
所以我这里对于文件名的命名做了特殊处理,有处理过前端 Route 路由经验的应该能联想到,文件名可以通过基于内容生成 Hash 值来代替。
在Spring 3.0 之后提供了计算摘要的的方法。
DigestUtils#md
返回给定字节的 MD5 摘要的十六进制字符串表示形式。
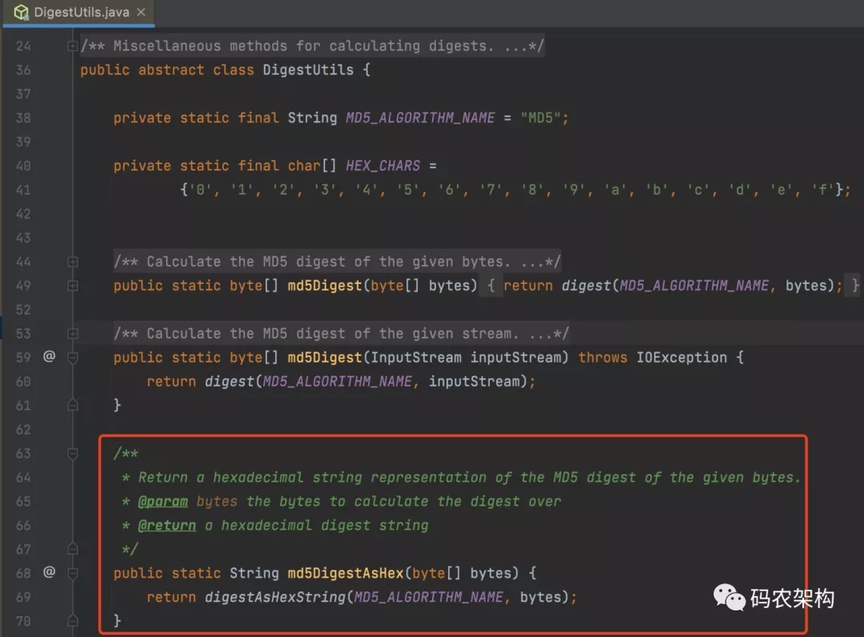
md5DigestAsHex 源码
/**
* 计算摘要的字节
* @param 一个十六进制摘要字符
* @return 串返回给定字节的 MD5 摘要的十六进制字符串表示形式。
*/
public static String md5DigestAsHex(byte[] bytes) {
return digestAsHexString(MD5_ALGORITHM_NAME, bytes);
}
文件名、内容、后缀(存储格式)确定后直接生成文件
/**
* 直接根据内容生成 文件
*/
public static void generateFile(String destDirPath, String fileName, String content) throws FileZipException {
File targetFile = new File(destDirPath + File.separator + fileName);
//确保父级目录存在
if (!targetFile.getParentFile().exists()) {
if (!targetFile.getParentFile().mkdirs()) {
throw new FileZipException(" path is not found ");
}
}
//设置文件编码格式
try (PrintWriter writer = new PrintWriter(new BufferedWriter(new OutputStreamWriter(new FileOutputStream(targetFile), ENCODING)))
) {
writer.write(content);
return;
} catch (Exception e) {
throw new FileZipException("create file error",e);
}
}
通过内容生成文件优点不言而喻,可以极大减少我们主动基于内容比较来生成新的文件、如果文件内容较大生成对应的文件名相同则表示内容未做任何调整,此时我们也就不用做后续的文件更新操作。
三、分片上传附件
所谓的分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为 Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。分片上传不仅可以避免因网络环境不好导致的一直需要从文件起始位置还是上传的问题,还能使用多线程对不同分块数据进行并发发送,提高发送效率,降低发送时间。
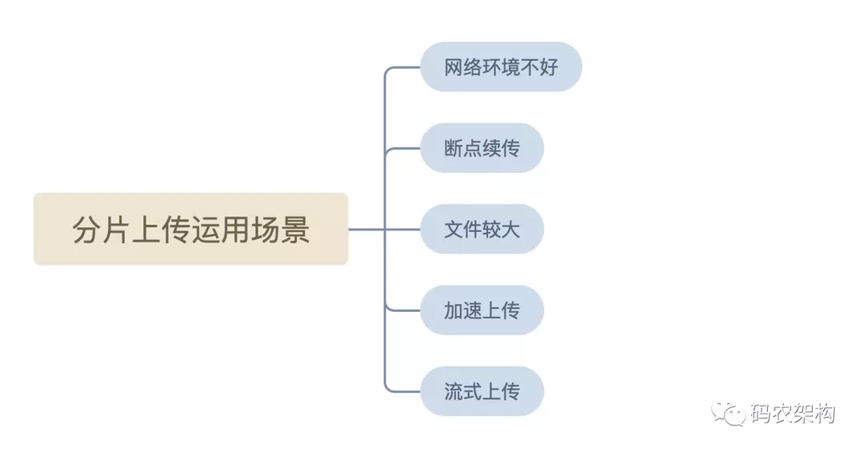
分片上传主要适用于以下几种场景:
-
网络环境不好:当出现上传失败的时候,可以对失败的 Part 进行独立的重试,而不需要重新上传其他的 Part。
-
断点续传:中途暂停之后,可以从上次上传完成的 Part 的位置继续上传。
-
加速上传:要上传到 OSS 的本地文件很大的时候,可以并行上传多个 Part 以加快上传。
-
流式上传:可以在需要上传的文件大小还不确定的情况下开始上传。这种场景在视频监控等行业应用中比较常见。
-
文件较大:一般文件比较大时,默认情况下一般都会采用分片上传。
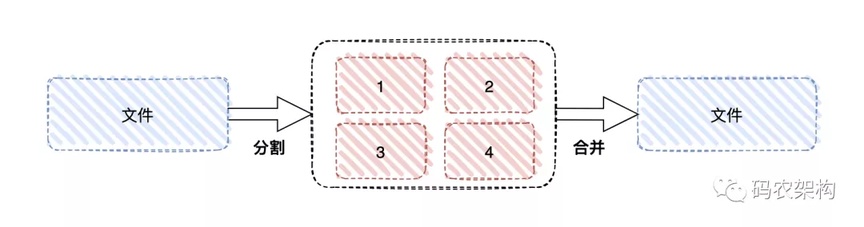
分片上传的整个流程大致如下:
-
将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;
-
初始化一个分片上传任务,返回本次分片上传唯一标识;
-
按照一定的策略(串行或并行)发送各个分片数据块;
-
发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件
▐ 定义分片规则大小
默认情况都以文件达到 20MB 进行强制分片
/** * 强制分片文件大小(20MB) */ long FORCE_SLICE_FILE_SIZE = 20L* 1024 * 1024;
为了方便调试,强制分片文件的阈值调整为 1KB
▐ 定义分片上传对象
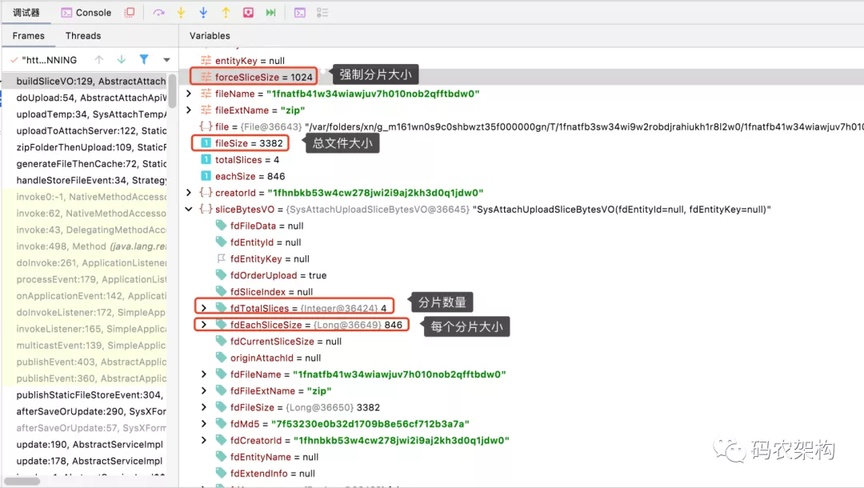
如上图红色序号的文件碎片,定义分片上传对象基础属性包含附件文件名、原始文件大小、原始文件 MD5 值、分片总数、每个分片大小、当前分片大小、当前分片序号等
定义基础属于便于后续对文件合理分割、分片的合并等业务拓展,当然根据业务场景可以定义拓展属性。
分片总数
long totalSlices = fileSize % forceSliceSize == 0 ? fileSize / forceSliceSize : fileSize / forceSliceSize + 1;
复制代码

每个分片大小
long eachSize = fileSize % totalSlices == 0 ? fileSize / totalSlices : fileSize / totalSlices + 1;

原始文件的 MD5 值
MD5Util.hex(file)
如:
当前附件大小为:3382KB,强制分片大小限制为 1024KB
通过上述计算:分片数量为 4 个,每个分片大小为 846KB
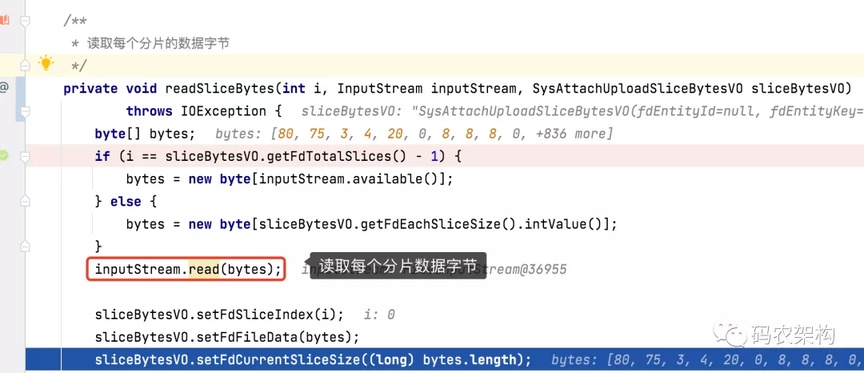
▐ 读取每个分片的数据字节
标记当前字节下标,循环读取 4 个分片的数据字节
try (InputStream inputStream = new FileInputStream(uploadVO.getFile())) {
for (int i = 0; i < sliceBytesVO.getFdTotalSlices(); i++) {
// 读取每个分片的数据字节
this.readSliceBytes(i, inputStream, sliceBytesVO);
// 调用分片上传API的函数
String result = sliceApiCallFunction.apply(sliceBytesVO);
if (StringUtils.isEmpty(result)) {
continue;
}
return result;
}
} catch (IOException e) {
throw e;
}
三、总结
所谓的分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为 Part)来进行分别上传。
处理大文件进行分片主要核心确定三大点
-
文件分片粒度大小
-
分片如何读取
-
分片如何存储
本篇文章主要分析和处理大文件上传过程中如何针对大文件文件文件内容比较、进行分片处理。合理设置分片阈值以及如何读取和标记分片。希望对从事相关工作的同学能够有所帮助或者启发。后续会对分片如何存储、标记、合并文件进行详细解读。

标签:文件,文件名,超大,Part,分片,new,上传 来源: https://www.cnblogs.com/ibytecoding/p/15732685.html