生物序列智能分析平台blog(19)
作者:互联网
2021SC@SDUSC
这篇博客主要做一篇论文的解读,关于RNA甲基化问题的研究,对后面自己的工作有着很大的帮助。
Attention-based multi-label neural networks for integrated prediction and interpretation of twelve widely occurring RNA modifications
作者单位:西交利物浦大学
简介:一个RNA的多修饰点的分类器(可以分类12种RNA修饰器的模型)
Introduction
- RNA修饰的作用很多,在生物的领域very important
- 其他工作的介绍,但是有缺点
- 没有注意到RNA修饰位点之间的联系
- 数据量不足,考察的位点太少
- 有一些的模型准确度可以,但是可解释性太差(即使有CNN核的可视化,但解释还是很模糊,only vague)
- 还有一些修饰位点,比如 $ m^6Am $,虽然传统的基于表转录组的传统方法和数据都是有了,但预测模型还没有完善
- 论文提出了一个新的模型,基于注意力机制的多标签的分类方法
- 12个RNA修饰点的识别
- 除了可以分析出每个修饰位点的独特特征,也能了解他们之间的关系
- 为了解决标签不平衡的问题,在训练时采用了OHEM和Uncertain Weight两种方法(其他方法也有采用)
- 运用了integrated gradient(IG)和attention weight 来获得更好的解释
- 建立了一个web server来给别人使用
Results
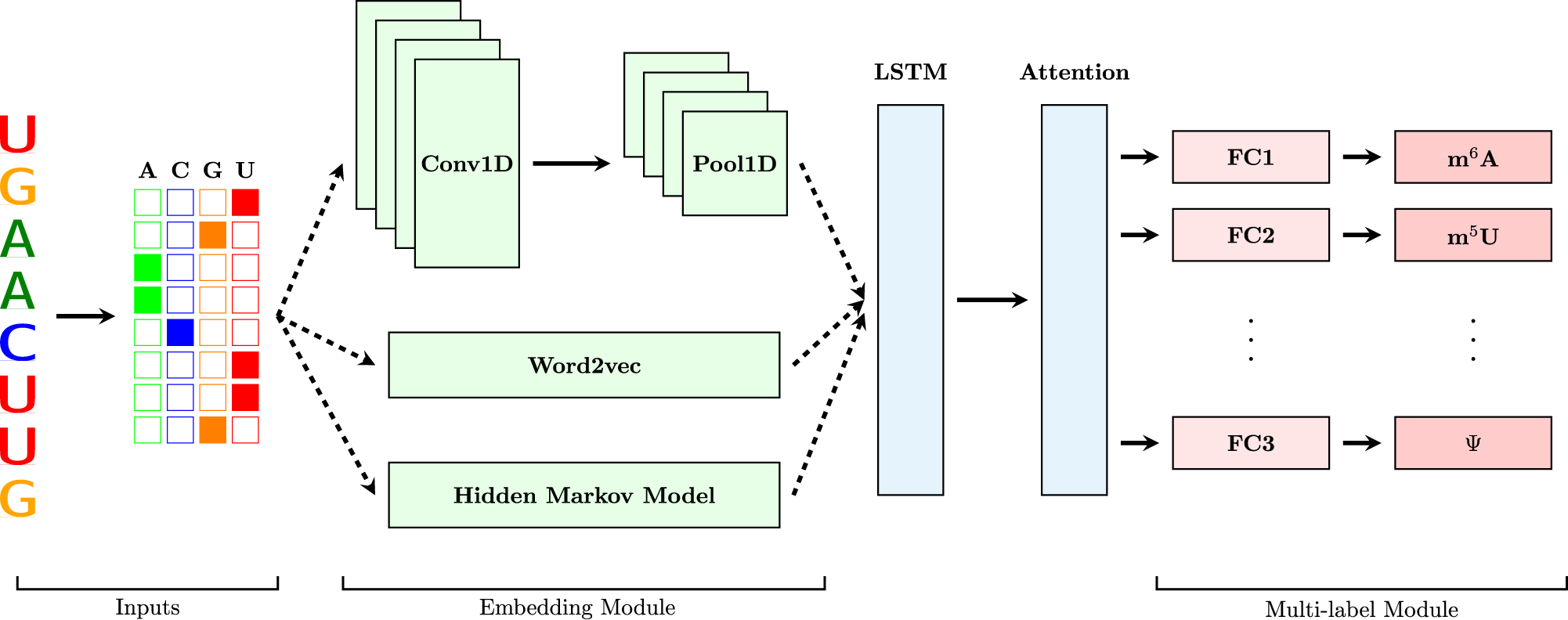
模型结构:embedding层+LSTM+注意力机制层+全连接层的分类器,优化器是交叉熵+OHEM和Uncertain Weight
表现(performance)
- 51-bp的input长度预测是最准确的
- OHEM和UW的加入都能提高模型的精度和准确性
- 和其他方法的对比,效果挺好的
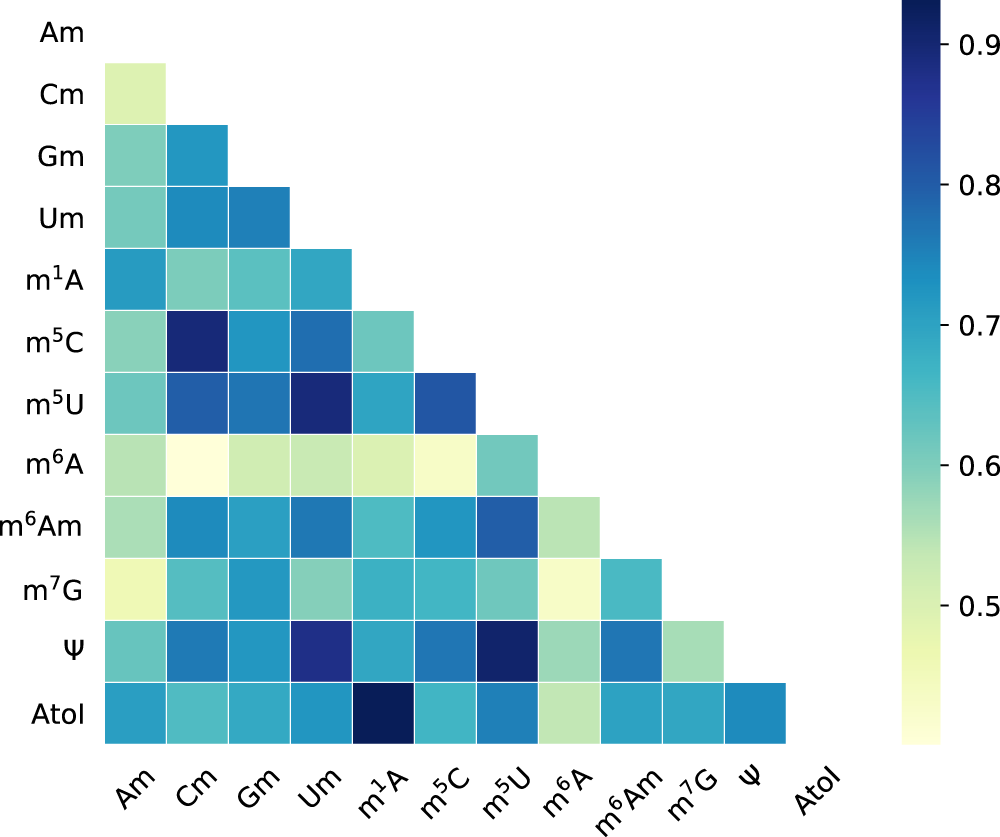
解释(interpretation)
- 一些相同的位点对RNA的整体影响很大,而且这些位点的模式也符合传统方法DREAM和STREAM,用TOMTOM计算出来的相似度也接近
- 用attention mechanism方法提取了十二个类别对应的十二个向量,研究其中的相似度,并发现 m 5 c m^5c m5c和 C m Cm Cm, I I I和 m 1 A m^1A m1A很接近,以及其他之间的关联,如 m 6 A m^6A m6A与其他的修饰器的关联都是温和的(mild),意味着其在转译规则中的特殊作用
最后一个就是其建立的web server的相关介绍
Discussion
一些工作总结
- 在这篇工作里,作者提出了一个可以预测十二种广泛出现的RNA分类器。
- 测试了三种embedding的方法,最后发现Word2Vector的方法最好。
- 同时也发现,并不是RNA序列输入越长,预测的值就越准确。
- 引用了OHEM和UW的方法来解决不平衡的标签数据。
- 采用的数据都是高质量的,这样避免了采用不同方法导致的数据不一致性的问题,增加了模型的鲁棒性和可靠性。
- webserver供人们使用。
- 研究了RNA修饰位点之间的一些联系,可以进一步促进生物学者的研究。
不足
- 现在模型只能预测到人类的RNA修饰,对于其他物种(如老鼠和酵母),还不行。
- 很重要的一点是,不同RNA修饰的数据量有着很大的区别,这样导致了小规模的RNA修饰有着更高的错误率,这个问题主要是现在生物对RNA修饰的测试不同的方法的一致性有待提升。所以当数据量提升上来后,模型的准确度也会提升。
Data关于数据的一些介绍
- 这些数据都是从从多个实验里得到的数据使用的,一些有瑕疵的数据都没有使用
- 最终得到了20个转录组,从15个不同的实验里得到的12种RNA修饰的分类(表五)
- 数据涵盖了所有能通过基本方法检测出来的RNA修饰
- 300k的位点(sites)收纳在实验数据里
All data used in this study were already publicly available in the GEO database, RMBase, and RADAR database.
In GEO database, m6A data can be collected from GSE71154, GSE86336, GSE98623 and GSE63753; Pseudouridine (Ψ): GSE60047, GSE58200, GSE63655 and GSE90963; m1A: GSE97908, GSE102040, GSE90963, GSE97419 and GSE70485; m6Am: GSE122948, GSE78040 and GSE63753; 2′-O-methyladenosine (Am, Cm, Gm, Um): GSE90164; m5C: GSE122260; m7G: GSE112276; m5U: GSE109183.
2′-O-methyladenosine data was also collected from the RMBase database under 2′-O-Me[http://rna.sysu.edu.cn/rmbase/2-O-Methylation.php] tag. Inosine data was collected from the RADAR database. All accession codes for data used are found in Table 5.
All processed sequence data is freely available on the MultiRM web server at www.xjtlu.edu.cn/biologicalsciences/multirm. Detailed data profile information can be found in Supplementary Materials. All data are available from the authors upon reasonable request.
标签:19,位点,RNA,方法,blog,修饰,序列,data,模型 来源: https://blog.csdn.net/qq_49215659/article/details/121969515