对偶与Proximal
作者:互联网
定理.conjugate subgradient theorem

这个定理比较重要的一点在于指导如何求解对偶梯度,例如对于\(y\)存在\(x\in\partial f^*(y)\),则\(x\)需要满足
\[\langle x,y\rangle-f(x)=f^*(y)=\max_{\sup \tilde{x}}(\langle \tilde x, y\rangle-f(\tilde x)) \]那么这时候我们只需要找到\(\tilde{x}\)即可求得对偶函数的梯度。
无约束条件下的算法
BB Algorithm
\[\begin{align} x^{k+1}&=x^{k}-\alpha_k\nabla f(x^k)\\ \alpha_k&=\frac{s_k^Ts_k}{s_k^Ty_k} \end{align} \]where
\[\begin{align} s^k&=x^k-x^{k-1}\\ y_k&=\nabla f(x^{k})-\nabla f(x^{k-1}) \end{align} \]Proximal Point Method
\[\begin{align} x^{k+1}&=\arg\min_{x}\{f(x)+\frac{1}{2\alpha_k}\Vert x-x^k\Vert\}\\ &=\text{prox}_{\alpha_kf}(x^k) \end{align} \]对 \(x\)进行求梯度
\[x^{k+1}=x_k-\alpha_k\nabla f(x^{k+1}) \]Proximal Gradient Method
\[\min f(x)+g(x) \]其中\(f\)凸光滑,\(g\)凸不光滑。对\(f\)函数进行展开逼近
\[\begin{align}x^{k+1}&=\arg\min_{x}f(x^k)+\langle \nabla f(x^k), x-x^k\rangle+\frac{1}{2\alpha_k}\Vert x-x^k\Vert +g(x)\\ &=\text{prox}_{\alpha_kg}(x^k-\alpha_k\nabla f(x^k)) \end{align} \]对偶视角
考虑一个线性凸约束问题
\[\begin{align} \min_x & f(x)\\ \text{s.t.}&Ax=b \end{align} \]构建Lagrange函数
\[\mathcal{L}(x, y)=f(x)+\langle y, Ax-b\rangle \]令\(d(y)=-\min_{x}\mathcal{L}(x, y)\),则对偶问题为
\[\min_y d(y) \]对偶梯度上升
利用梯度的方法得到
\[y^{k+1}=y^k-\alpha_k\partial d(y^k) \]其中
\[\begin{align} d(y)&=-\min_x\mathcal{L}(x,y)\\ &=-\min_x f(x)+y^TAx-y^Tb\\ &=[-\min_x -(-y^TAx-f(x)]+y^Tb\\ &=f^*(-A^Ty)+y^Tb \end{align} \]则
\[\begin{align} \partial d(y)=-A f^*(-A^Ty)+b \label{eq:gradient of y} \end{align} \]利用共轭函数的定理需求共轭函数的梯度,则此时的\(\tilde{x}\)需要满足
\[\begin{align}\tilde{x}&=\arg\max_{\tilde{x}}\{\langle -A^Ty, \tilde{x}\rangle-f(\tilde{x})\}\\ &=\arg\min_{\tilde{x}}\{\langle A^Ty, \tilde{x}\rangle+f(\tilde{x})-y^Tb\}\\ &=\arg\min_x\mathcal{L}(x, y) \end{align} \]此时的更新方式为,也称对偶梯度上升
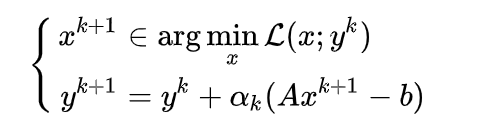
Dual Proximal point method
此时\(y\)的更新方式为
\[y^{k+1}=y^{k}-\alpha_k\partial d(y^{k+1}) \]由\(\ref{eq:gradient of y}\)可知
\[\begin{align} \partial d(y^k+1)&=-A \partial f(-A^Ty^{k+1})+b\\ &=-A\arg\min_x\mathcal{L}(x, y^{k+1})+b \end{align} \]得\(x^{k+1}\)为
\[\begin{align} x^{k+1}&=\arg\min_x \mathcal{L}(x, y^{k+1})\\ &=\arg\min_x f(x)+\langle y^{k+1}, A^Tx-b \rangle\\ &=\arg\min_x f(x)+\langle y^k+\alpha_k(A^Tx-b), A^Tx-b \rangle\\ &=\arg\min_x f(x)+\langle y^k,(A^Tx-b)\rangle +\frac{\alpha}{2}\Vert A^Tx-b \Vert^2\\ \end{align} \]\(x^{k+1}\)为增广拉格朗日,更新方式为
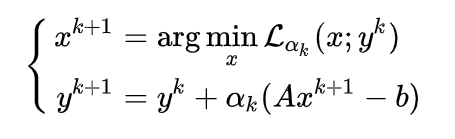
Dual Proximal Gradient Method
考虑问题
\[\begin{align} \min_x& f(x)+g(z)\\ \text{s.t.}& Ax+Bz=b \end{align} \]同样\(f\)凸光滑,\(g\)凸非光滑。Lagrange函数为
\[\mathcal{L}(x,z)=\underbrace{f(x)+y^TAx}_{\mathcal{L}_1(x, y)}+\underbrace{g(z)+y^TBz-y^Tb}_{\mathcal{L}_2(z,y)} \]令\(d_1(y)=-\min_x\mathcal{L}_1(x, y)\),\(d_2(y)=-\min_z\mathcal{L}_2(z,y)\)。对于对偶问题
\[\min_y d_1(y)+d_2(y) \]利用Proximal Gradient Method更新\(y\)得到
\[y^{k+1}=\text{prox}_{\alpha_k d_2} (y^k-\alpha_k\partial d_1(y^{k})) \]令
\[\left\{ \begin{align} y^{k+1/2}&=y^k-\alpha_k\partial d_1(y^k)& \\ y^{k+1}&=\text{prox}_{\alpha_k d_2}(y^{k+1/2})&\end{align}\right. \]\(y^{k+1/2}\)进行梯度下降,第二步进行proximal操作。其中
\[\partial d_1(y^{k})=-Ax^{k+1} \]\(x_{k+1}=\arg\min_x \mathcal{L_1}(x, y)\)。第二步\(y^{k+1}\)更新为
\[\begin{align} y^{k+1} &= \text{prox}_{\alpha_k d_2}(y^{k+1/2})\\ &=y^{k+1/2}-\alpha_k \partial d_2(y^{k+1}) \end{align} \]\(\partial d_2(y^{k+1})=-Bz^{k+1}+b\),而\(z^{k+1}=\arg\min_z \mathcal{L}_2(z,y^{k+1/2})\)。最终的更新为
\[\left \{ \begin{align} x^{k+1}&=\arg\min_x \mathcal{L}_1(x, y^k)\\ y^{k+1/2}&=y^{k}+\alpha_kAx^{k+1}\\ z^{k+1}&=\arg\min_z \mathcal{L}_2(z,y^{k+1/2})\\ y^{k+1}&=y^{k+1/2}+\alpha_k(Bz^{k+1}-b) \end{align} \right. \]总结
我们只需要记住proximal操作是
\[x^{k+1}=x^k-\alpha \nabla f(x^{k+1}) \]而对于有约束的问题我们需要求解对偶变量及其梯度。当求对偶变量梯度的时候使用共轭次梯度定理,满足定理条件的primal variable就是其当前次梯度。
\[x=\arg\max_x\{y^Tx-f(x)\} \]参考资料
标签:end,min,mathcal,align,Proximal,arg,alpha,对偶 来源: https://www.cnblogs.com/DemonHunter/p/15515580.html