(CVPR 2020 Oral)最新Scene Graph Generation开源框架
作者:互联网
(CVPR 2020 Oral)最新Scene Graph Generation开源框架与一些碎碎念
https://zhuanlan.zhihu.com/p/109657521
最新最完善的场景图生成Scene Graph Generation (SGG)代码框架介绍,以及关于场景图生成我们真正应该关心的是什么
前言:
2019上半年跌跌撞撞地搞了很多乱七八糟的东西但都没work,尤其让我酸的是我上半年没做work的一个VQA的idea居然在同年ICCV看到一篇极其相似的文章,虽然对方取巧用了BERT硬是提了一点才中的,但真的没产出的时候看着别人发paper太酸了。话虽如此,取巧用idea以外的trick发paper还是不值得学习的。同年下半年看了很久的《The Book of Why》来寻找灵感,最后到了临近CVPR deadline,还是回归了自己的老本行场景图生成,投稿了一篇《Unbiased Scene Graph Generation from Biased Training》,并幸运的以(SA,SA,WA)的分数中了今年的CVPR 2020 Oral。结合我之前对SGG领域的了解,我认为目前SGG领域内关于不同message passing模型设计带来的提升已经趋于饱和,且这个研究方向目前来看已经愈发没有意义,因为由于自然存在以及数据标注中的bias和长尾效应(long-tail effect), 所谓的模型优化已经渐渐变成了更好的拟合数据集的bias,而非提取真正有意义的relationships。在此基础上,我在该工作中主要做了如下两件事:
1)延续我去年在VCTree(CVPR 2019)中提出的mean Recall@K,设计了一个unbias的inference算法(注意不是training方法哦~),并希望让更多的人关注真正有意义的SGG,而不是去拟合数据集刷指标;
2)由于之前通用的SGG框架neural-motifs已经落后于时代,我设计了个新的代码框架(已于Github开源)。
不仅结合了最新的maskrnn-benchmark用于底层物体检测,同时集成了目前最全的metrics包括Recall,Mean Recall,No Graph Constraint Recall, Zero Shot Recall等,同时代码中为各种指标的evaluation统一了接口,希望后续有更多的研究者们可以设计出更有价值的metrics,从而使SGG领域不至于再只关注一个biased指标Recall而沦为灌水圣地。
框架说明:
如果在过去两年做过SGG的同学应该都或多或少知道neural-motifs代码框架,虽然Rowan Zellers本身是我非常崇拜的一位大神,但是他neural-motifs代码里的各种炫技操作和神乎其神的trick,经常让我非常头大,更不要说糟糕的文档和说明了。当然,真正让我下定决心要写个新的Codebase的主要原因还是因为neural-motifs的底层Faster R-CNN已经过于落后,毕竟SGG里物体的检测和识别也是非常重要的,甚至有时候比预测relationship更加重要。为了便于大多数有物体检测背景的同学follow,我挑选了去年最当红,哦不,最为可靠的facebookresearch/maskrcnn-benchmark框架作为基础,在其基础上搭建了我的Scene-Graph-Benchmark.pytorch。该代码不仅兼容了maskrcnn-benchmark所支持的所有detector模型,且得益于facebookresearch优秀的代码功底,更大大增加了SGG部分的可读性和可操作性(BoxList类的设计简直是人类工程智慧的结晶,崇拜,从早年的faster-rcnn框架过来的我热泪盈眶)。目前我们框架提供的各种baseline模型,有着当之无愧的State-of-The-Art SGCls和SGGen结果(如下图,PredCls我还需要花时间调一下)。由于复现版本的VCTree为了简便省略了原文的Hybrid Learning,同时SGGen/SGCls/PredCls超参也做了统一,而非各自最优,所以此处的PredCls低于VCTree原文。
传送门:
https://link.zhihu.com/?target=https%3A//github.com/KaihuaTang/Scene-Graph-Benchmark.pytorch
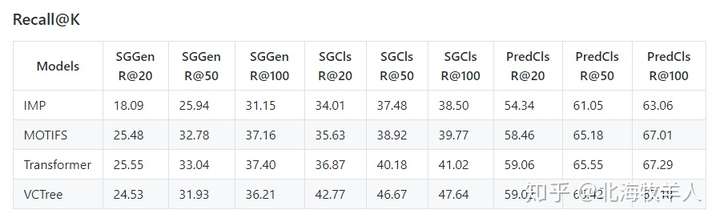
Recall@K for Iterative Message Passing(IMP), Neural Motifs, Transformer,VCTree
- Faster R-CNN预训练
该项目的Faster R-CNN预训练部分基本完全采用maskrcnn-benchmark的源代码(虽然我们又增加了attribute_head的实现,但还没开始正式使用),仅就数据集做了更换,换成SGG的VisualGenome数据集。因此后续研究者可以完全参考maskrcnn-benchmark的代码设计新的detector,并运用于SGG中。下面是一个训练命令行样例:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --master_port 10001 --nproc_per_node=4 tools/detector_pretrain_net.py --config-file "configs/e2e_relation_detector_X_101_32_8_FPN_1x.yaml" SOLVER.IMS_PER_BATCH 8 TEST.IMS_PER_BATCH 4 DTYPE "float16" SOLVER.MAX_ITER 50000 SOLVER.STEPS "(30000, 45000)" SOLVER.VAL_PERIOD 2000 SOLVER.CHECKPOINT_PERIOD 2000 MODEL.RELATION_ON False OUTPUT_DIR /home/kaihua/checkpoints/pretrained_faster_rcnn SOLVER.PRE_VAL False
主要参数文件可以参考"configs/e2e_relation_detector_X_101_32_8_FPN_1x.yaml"。注意所有config文件的default设置在"maskrcnn_benchmark/config/defaults.py"中,而优先级如下,具体每个参数的意义可以参考我Github项目中的解释。
命令行参数 ===》(覆盖)===》xxx.yaml参数 ===》(覆盖)===》defaults.py参数
当然因为detector的训练费时费力费卡,而且考虑到公平起见以往大部分SGG的工作都会follow一个固定的预训练模型,即neural-motifs项目所给的预训练detector模型。我这里也release了一个我训练好的ResNeXt-101-32x8模型。考虑到国内同学可能下载不便,我这里给一个百度网盘的链接(提取码:gsfn):
https://link.zhihu.com/?target=https%3A//pan.baidu.com/s/1MDFgqluIe_LKhi7MP2Pjqw
值得一提的是,我们的Faster R-CNN其实还支持了attribute_head,即物体的属性,但为了公平比较,我目前还没有在发表的文章中加入对应实验,欢迎大家完善这部分工作。
- SGG as RoI_Head
关于最主要的SGG部分,我将其设计为了一个roi_head,参考其他roi_heads,如box_head的设计,我将主要代码集中于"maskrcnn_benchmark/ modeling/ roi_heads/ relation_head"目录下,结构如下:
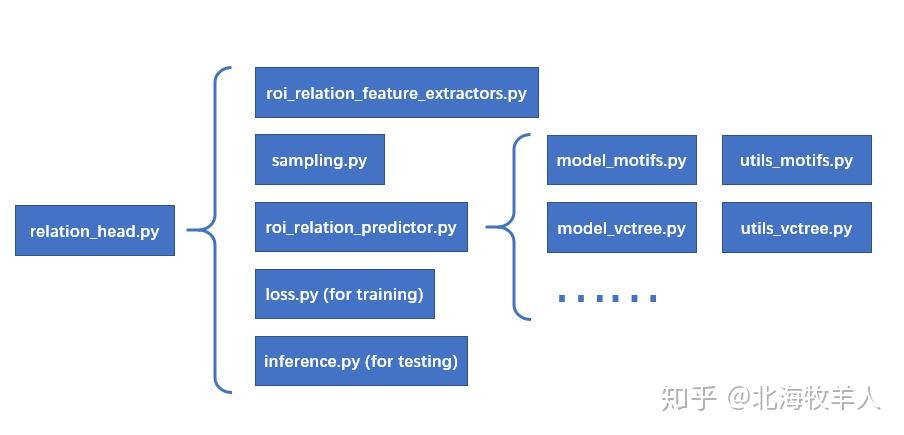
relation_head代码结构
所以,如果想要设计自己的新模型,大部分情况下,只需要修改 "roi_relation_predictor.py" 以及增加相应的"model_xxx.py"和"utils_xxx.py"足矣。目前我们框架所提供的模型有:
-
Neural-MOTIFS: https://arxiv.org/abs/1711.06640
-
Iterative-Message-Passing: https://arxiv.org/abs/1701.02426
-
VCTree: https://arxiv.org/abs/1812.01880
-
Transformer (由史佳欣实现,没有发表单独的paper)
-
Causal-TDE:https://arxiv.org/abs/2002.11949
-
- MOTIFS: https://arxiv.org/abs/1711.06640
- VCTree: https://arxiv.org/abs/1812.01880
- VTransE: https://arxiv.org/abs/1702.08319
他们可以通过"MODEL.ROI_RELATION_HEAD.PREDICTOR"参数进行选择。因为最后一个Causal-TDE是我今年CVPR2020提出的一个特殊的Inference方式,而非具体的模型,所以它测试了三种模型。我们会在下文无偏见的场景图生成中具体的介绍这个方法。
- 所有指标简介
作为基础知识,我先简单介绍下SGG的三种设定: 1) Predicate Classification (PredCls): 给定所有ground-truth的物体类别和bounding boxes,求这张图的场景图。2)Scene Graph Classification (SGCls): 给定所有ground-truth物体的bounding boxes,求场景图(需要预测物体类别)3) Scene Graph Detection/Generation (SGDet/SGGen) :只给图片,自己跑detection检测物体,最后预测场景图。
然后关于指标,之前的SGG最大的问题之一,就是过度依赖单一指标Recall@K,而这个指标因为不区分各个类别的贡献加上VisualGenome本身的长尾效应,很容易被过拟合。这导致了近年大多数SGG的文章,只是在过拟合的道路上越走越远,而非真正生成了更有意义的场景图。于是我在该框架中整合了已知的所有指标,也希望后续的工作可以report更多有意义的指标来分析算法有优缺。下图是我代码的一个结果输出样例。
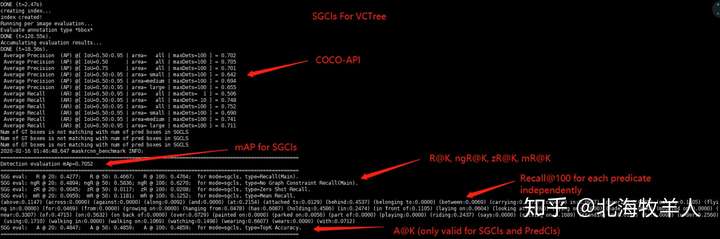
项目在测试/验证时的输出格式
所有本框架支持的指标有:
- Recall@K (R@K): 这是最早的也是最广为接受的指标,由卢老师在https://arxiv.org/abs/1608.00187中提出。因为VisualGenome数据集的ground-truth中对relationship的标注并不完整,所以简单的正确率并不能很好的反映SGG的效果。卢老师用了检索的指标Recall,把SGG看成检索问题,不仅要求识别准确,也要求能更好的剔除无关系的物体对。
- No Graph Constraint Recall@K (ngR@K):这个指标最早由Pixel2Graph使用,由Neural-MOTIFS命名。这个指标的目的在于,传统的Recall计算里,一对物体只能有一个relation参与最终的排序,但ngR@K允许一对物体的所有relation都能参与排序。这也非常有道理,比如 human(0.9) - riding (0.6) - horse (0.9):total score=0.9x0.6x0.9,可能这对物体还有另一个relation:human(0.9) - on (0.3) - horse (0.9):total score=0.9x0.3x0.9。后者虽然分数比riding低,但也是一种可能的情况。ngR@K的结果往往大大高于单纯的R@K。
- Mean Recall@K (mR@K): 这个指标由我的VCTree和另外一个同学的KERN在2019年的CVPR中同时提出,不过我并没有作为VCTree的主要贡献,只在补充材料中完整展示了结果表。由于VisualGenome数据集的长尾效应,传统Recall往往只要学会几个主要的relation类比如on,near等,即便完全忽视大部分类别也可以取得很好的结果。这当然不是我们想看到的,所以mean Recall做了一件很简单的事,把所有谓语类别的Recall单独计算,然后求均值,这样所有类别就一样重要了。模型的驱动也从学会尽可能多个relation(有大量简单relation的重复)变成学会尽可能多种类的relation。
- Zero Shot Recall@K (zR@K):在早期的视觉关系识别中,人们也使用了Zero Shot Recall指标,但在SGG中又渐渐被人忽视了,我们在这又重新增加了这个指标,因为它可以很好的展示SGG的拓展能力。Zero Shot Recall指的并不是从来没见过的relation,而只是在training中没见过的主语-谓语-宾语的三元组组合,所有单独的object和relation类别还是都见过的,不然就没法学了。
- Top@K Accuracy (A@K):这个指标来自于某个之前研究者对PredCls和SGCls的误解,并不建议大家report到文章中,这里列出来是希望大家以后别犯这个错。该同学在PredCls和SGCls中不仅给了所有object的bounding box,还给了主语-宾语所有pair的组合,所以这就完全不是一个Recall的检索了,而是给定两个物体,来判断他们relation的正确率。
- Sentence-to-Graph Retrieval (S2G):最后是我在Causal-TDE中提出的ground-truth caption到SG检索,它可以看成一个理想的下游任务,可以看作一个VQA:问指定图片的SG符不符合给定描述。他的意义在于,他完全摒弃了visual feature,只使用符号化的SG。他可以测试检测出的SG是否可以用来完整地丰富地表示原图(潜台词:从而支持符号化的推理)。由于这需要额外的训练过程,所以并不能直接在SGG的val/test里输出。
当然现有的metrics也许仍然不够完善,如果有更好的能体现SG效果或有助于分析SGG的指标,我的代码框架也支持自定义指标,本项目的所有指标都通过如下类实现,可以添加至"maskrcnn_benchmark/data/datasets/evaluation/vg/sgg_eval.py"并在同目录下的"vg_eval.py"中调用。
class SceneGraphEvaluation(ABC):
def __init__(self, result_dict):
super().__init__()
self.result_dict = result_dict
@abstractmethod
def register_container(self, mode):
print("Register Result Container")
pass
@abstractmethod
def generate_print_string(self, mode):
print("Generate Print String")
pass
# Don't forget the calculation function
# def calculate_recall()
# return
- 常见误区
在从事SGG研究的这两年里,我从看的paper,代码,和自己当reviewer审的paper里,发现两个常见的误区,这会导致结果异常的高。我假设这些作者是出于无心,所以在此澄清。
- 不加区分No Graph Constraint Recall@K (ngR@K)和Recall@K (R@K)。除了早期最开始提出ngR的Pixel2Graph外,我还看到过一些人,直接将自己ngR的结果和别人单纯Recall的结果作比较,声称自己是state-of-the-art的结果。这是非常不公平的。他们常见的症状有:1)没有明显理由的情况下PredCls的Recall@100大于75%,2)文中没有明确提及ngR和R的区别。目前比较合理的推测是,在VisualGenome数据集中,传统Recall@100在Predcls上的上限应当在70%左右。因为数据集的不完整性,其实很多预测都是正确的,只是数据集里没标,所以这造成了传统Recall永远无法达到理论的100%。那么如果自称PredCls的Recall@100大于75%的,多半其实是用了ngRecall。
- 在PredCls和SGCls中,使用Top@K Accuracy (A@K)来报告成Recall,这又是另一个误区。因为PredCls和SGCls中给定的只是所有object的bounding box,而非具体的主语-宾语的pair信息。一旦给定了pair信息,那么其实就没有recall的ranking了,只是纯粹的accuracy。这个误区最初发现于contrastive loss中。我花了小半个月才发现为什么他的PredCls和SGCls结果这么好。它的症状也很简单,PredCls和SGCls中的Recall@50, Recall@100结果一摸一样,只有Recall@20稍低。因为没有了ranking,top50和100也就没区别了,没有图片有多于50个的ground-truth relationships。
- 额外的话
- 对于一些模型,打开或关闭 "MODEL.ROI_RELATION_HEAD.POOLING_ALL_LEVELS" 这个设置会很大地影响relation的预测,比如如果在VCTree的Predcls中关闭这个设置,就可以提升结果,但在对应的SGCls和SGGen中却不行。上文的VCTree结果,我为了统一都打开了这个设定。
- 对于一些模型(不是全部),使用Learning to Count Object中提出的一种fusion方法,可以显著地提升结果。这种fusion算法的公式为:\(f(x_1,x_2)=ReLU(x_1+x_2)-(x_1-x_2)^2\) 。使用方法是,在 "roi_relation_predictors.py" 中,将主语宾语特征的混合方式改为这个公式,目前项目中使用的为简单的torch.cat((head_rep, tail_rep), dim=-1)。
- 另外更不要说一些hidden_dim的参数了。我想表达的是,因为时间的限制(还有卡的),我其实没有对这个项目做过多的调参,我写的一些超参我也没有完整测试。如果有打比赛经验的同学,通过修改参数达到更好的结果我一定不会惊讶。
无偏见的场景图生成(和一些不成熟的想法)
其实在我接触SGG以来最大的困惑不是SGG做的不好,而是现在的SGG如果单看Recall明明已经非常好了,但为什么仍没有得到广泛的应用。换句话说,SGG画的饼这么香为什么没人吃,虽然也有一些下游任务中有人利用SGG发了paper,但都没有成为主流。我的想法是relationship是一个非常主观且很依赖语境的标签,这不同于简单的物体分类和识别,在后者中对就是对错就是错。而我的理解里单纯的deep learning的本质是memorize所有数据集,并做一些简单的归纳汇总(一定程度的generalize),这是一个非常passive的过程,所以在简单的分类识别等passive的任务上效果最为显著。比作人类的话,这可以看作人下意识情况下做的一些工作(我们从来不知道自己是怎么识别出苹果的,识别的时候纯粹是下意识反应,也不会去思考为什么是苹果)。最新的NLP中的研究也发现,进入Transformer时代后,很多简单的问答,机器已经可以做的非常拟人了。但如果稍微在问题中加入一个简单的1+1之类的需要思考的过程,模型瞬间给出很多滑稽的结果。所以现在的deep learning学出来的模型,更像一个被动的只靠直觉驱使的人。而SGG和任何需要Reasoning的任务比如VQA,都更加主动和主观。比如SGG中到底是(human, on, horse)还是(human, riding, horse),取决于语境是关注“what's on horse?(空间关系)”还是“what is the man doing?(具体动作)”,不能简单地说谁对谁做(如果直接归为多类别问题的话,又会因为同义词太多而无法得到足够好的标注)。我不认为现在的大部分推理(Reasoning)的文章,真正做到了推理(虽然我们组就是做这个的),加了很多attention也只是更好的拟合了数据集而已。因为给定同一份输入,一个确定的网络(假设不包含随机sample等操作)永远只会得到一个结果,是一个passive的反馈。而我们最新的CVPR 2020的文章“Unbiased Scene Graph Generation from Biased Training”就尝试通过对因果图的干预,使同一份输入,同一个网络,得到不同的输出,用于不同的目的。类似于人对于同一个问题,可以在脑海里思考各种可能选择,做出权衡。我觉得这可能是未来真正解决Reasoning的一个可能方向,用一个deep model拟合对世界的认知(知识),但真正的推理在于对这些知识的应用和分析,即对模型中各个节点进行不同的干预后的观察。当然这种干预用什么去驱使,RL?Sample?还有待考虑(这怕不是要靠意识本身)。
扯远了,回到SGG中。虽然我们还是无法解决用什么标准去评价一个更主观更有意义的SGG,但肯定不是目前最主流的Recall@K,在这种指标下即便模型只学出了on/near/wear/has等少数几种relationship,模型的Recall@K依然非常高,这种场景图对下游reasoning任务的帮助非常有限,简单的来说没有引入足够多的信息量,那么一个最简单的办法,就是让relationship尽可能地diverse,学到尽可能多种类的relationship就有更多信息量了。所以去年CVPR 2019,我在VCTree这篇文章里提了个mean Recall的指标用于评价一个无偏见的场景图,上文也作了介绍。
- KERN与VCTree(CVPR 2019)
其实同年,有两篇工作同时提出了一摸一样的mean Recall的指标,名字都一样。除了我们的VCTree还有一篇叫KERN的工作。这两篇工作首次开始关注,怎么衡量和解决无偏见的场景图。且这两篇给出的solutions都和网络的message-passing的结构有关。传统的方法往往通过attention来体现这种结构,这样也就将结构和feature一起end-to-end地训练了,就非常容易造成网络的过拟合,即产生结果完全biased到一些大类中:on/near。那么我们来看看VCTree和KERN给的两种解决方案。
1)KERN使用了一个基于统计的message-passing structure,这个结构是一个hard structure无法学习(基于他们的代码,我发现这个结构matrix被设为requires_grad = False)。既然结构都不学了,所以也就不存在结构上的过拟合。
2)VCTree则用一个独立的分支来学习structure,并确保feature learning的分支和structure learning的分支没有/中断反向传播。这也就保证了,结构和feature不会共同过拟合到一起。下图是我对VCTree核心idea的一个概览图。
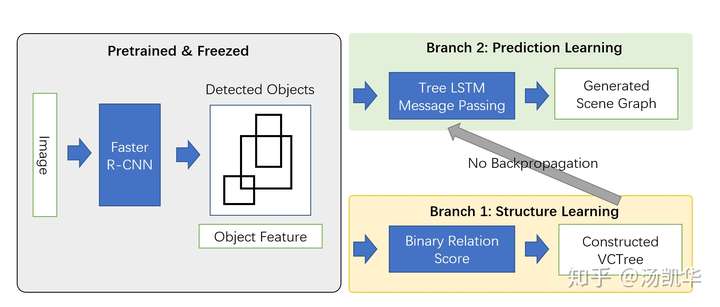
VCTree结构分支与feature分支概览图
到了今年的CVPR,我们做了一个更大胆的构想。我们将常见的MOTIFS和VCTree等模型归纳为了如下的因果图。因果图中每个节点为一些关键变量,而其中的有向边就是对各种网络forward运算的简化,仅体现了一种因果上的决定关系。
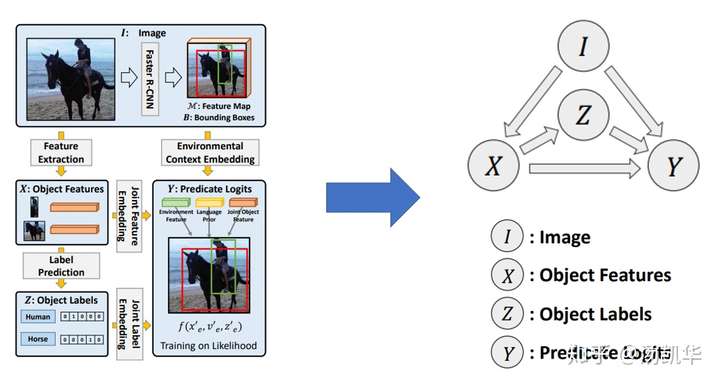
左侧为网络概述,右侧为对应的因果图
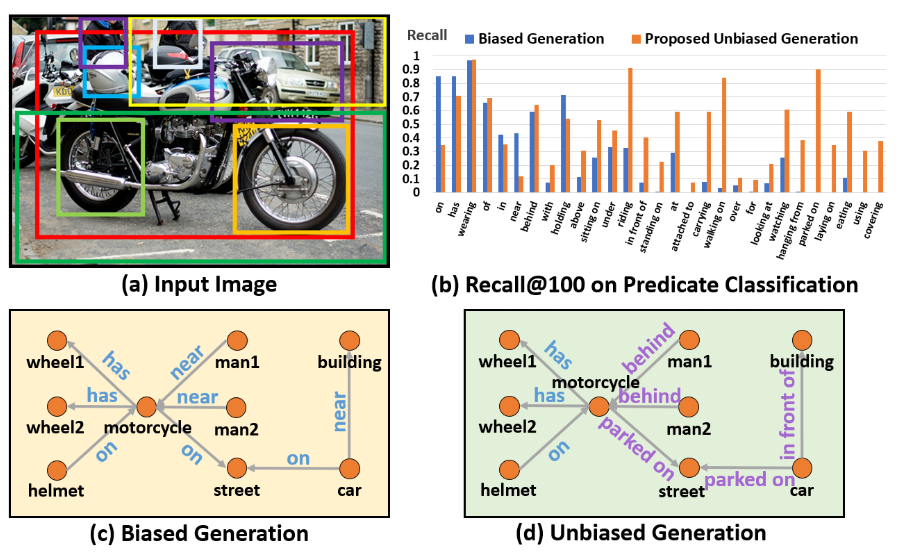
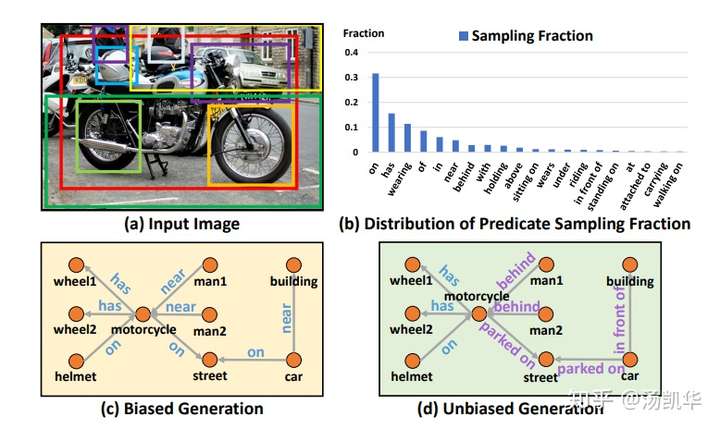
然后,我们分析了这些模型中偏见到底来自于哪里。我们认为,SGG中的偏见主要来源于下图右下角的那种场景,即不看具体的两个物体的状态(feature),单纯通过两个物体的label和一个union box的环境信息,就盲猜这两个物体是什么relationship。因为VisualGenome数据集的bias和长尾效应,偏偏这种盲猜不仅更容易学习还大部分情况下都是对的。这就导致了模型不再关注物体具体的状态(feature)而直接take了盲猜的biased shortcut(毕竟deep learning永远优先收敛到各种shortcut上)。导致的结果就是,具体的visual feature不再重要,也就预测不出真正有意义的finegrain的relationships了。因为更finegrain的relation出现太少,而且很容易错,所以干脆把所有复杂的sitting on/standing on/riding全预测成on。
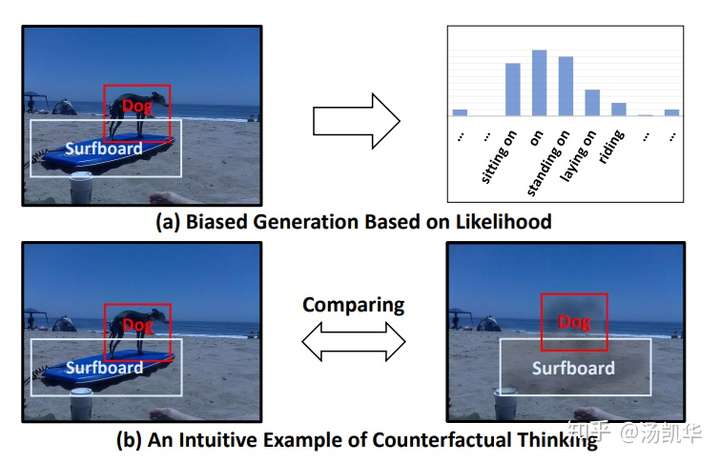
然后就产生了下图C子图中的非常没有意义的scene graph,偏偏Recall还挺好。因为标注员本身就倾向于标这些简单的relationships。(标注员标注时候的状态基本就像我上文说的passive反馈状态,所以标出来的relationship都趋同,没有现实中真正结合语境时的那种灵活。一些Reasoning的任务,比如VQA,的标注也有类似问题。这些思维上比较active的任务,如果要求标注员自己列举各种语境下不同的结果(SGG)或标注的同时给出脑海里思考的过程(VQA),又显得代价太高昂而不现实)。
于是为了迫使模型预测更有意义的relationship,我们用了一个causal inference中的概念,即Total Direct Effect(TDE)来取代单纯的网络log-likelihood。Effect的概念可以理解为医学上为了确定一个药真正的疗效,我们除了观测患者服药后的表现(传统模型的预测),还要减去这个药的安慰剂效应(通过控制变量/反事实干预得到的bias)。这就体现在了下图中。我们的Unbiased TDE是一个除去了盲猜带来的“安慰剂效应”后的真正的relationship可能性。
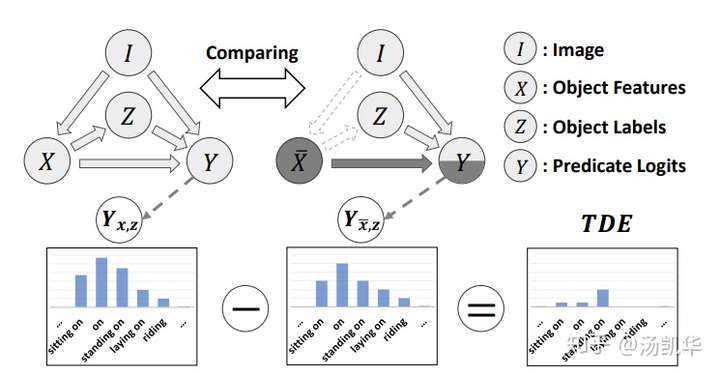
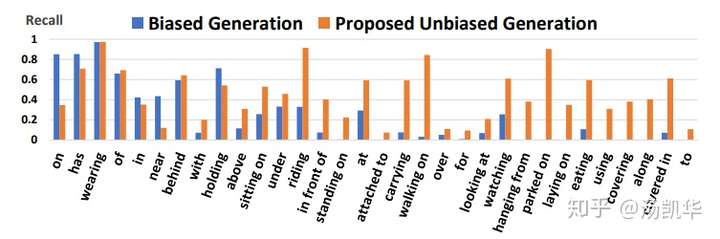
虽然简单,这样的方法却取得了非常有效的效果,从下图的各个predicate的单独Recall结果就可以看出。注意!有的人或许会问,为什么不一开始就删除模型中biased shortcut分支,只用feature预测relationship。这就好比去拟合Y=aX+b,想要得到一个无bias:b的模型,我们不能单纯的就用Y=aX去拟合数据,而是要先构建出Y=aX+b拟合完了再删去b。我们实验部分也证明了单纯去掉biased shortcut分支,并不会直接得到最好的unbiased SGG。另外,还有一些额外的使用TDE的trick,可以去我的Github上看对应的Tips and Tricks。
总结和展望
最后我想在总结里再唠叨唠叨场景图的应用,我一直觉得场景图是visual reasoning的基础,但同时现在的SGG还远不足以支撑visual reasoning。即便我提出的Unbiased SGG也还有很长的路要走。而具体怎么使用SG又是另一个问题了。
我们脑子里想事情的时候,往往都是先构建事物之间的相互关系,然后思考某些事物处于特定状态下对其他相关联事物的影响,然后关联事物的关联事物的影响。。。。这里我指的既可以是Unbiased SGG中提到的因果图,也可以是将SG运用于Visual Reasoning任务中后的SG。但重要的一点是,我觉得真正的Reasoning肯定不再是简单的用模型跑个one-time feedforwad。而是类似于:(1):干预1->观察1->Output1, 干预2->观察2->Output2, .... (2):{Output1, Output2,.....}->比较分析。
絮絮叨叨地说了一堆,最后都说的有点乱了。很多东西我也只是粗浅的不成熟的想法,有待更多的实验和研究去验证。毕竟不知道对不对,不知道work不work,不知道会发生什么,不知道结果为什么是这样,才是科研的常态。希望大家多多尝试些更有意思的想法,在state-of-the-art每天更新的时代,提升零点几个点也许远没有尝试些新的可能性,或者对一些现象做出有参考价值的分析来得有意义,哪怕performance不是最高也不要气馁。说起来我的Causal TDE还降低了传统指标Recall几个点呢。
标签:VCTree,Generation,Graph,模型,Scene,relation,Recall,SGG 来源: https://www.cnblogs.com/fusheng-rextimmy/p/15387817.html