dfs序与树链剖分
作者:互联网
dfs序与树链剖分
本文根据以下视频整理
引子
先看一个题:
已知一棵树,每个节点包含一个权值,你需要设法实现以下操作
操作1: 格式: 1 x y z 表示将树从x到y结点最短路径上所有结点的值加上z
操作2: 格式: 2 x y 表示求树从x到y结点最短路径上所有结点的值之和
操作3: 格式: 3 x z 表示将以x为根的子树所有结点都加上z
操作4: 格式: 4 x 表示求以x为根的子树的所有结点权值之和
dfs序
- 顾名思义就是dfs访问结点的顺序
- 如下图
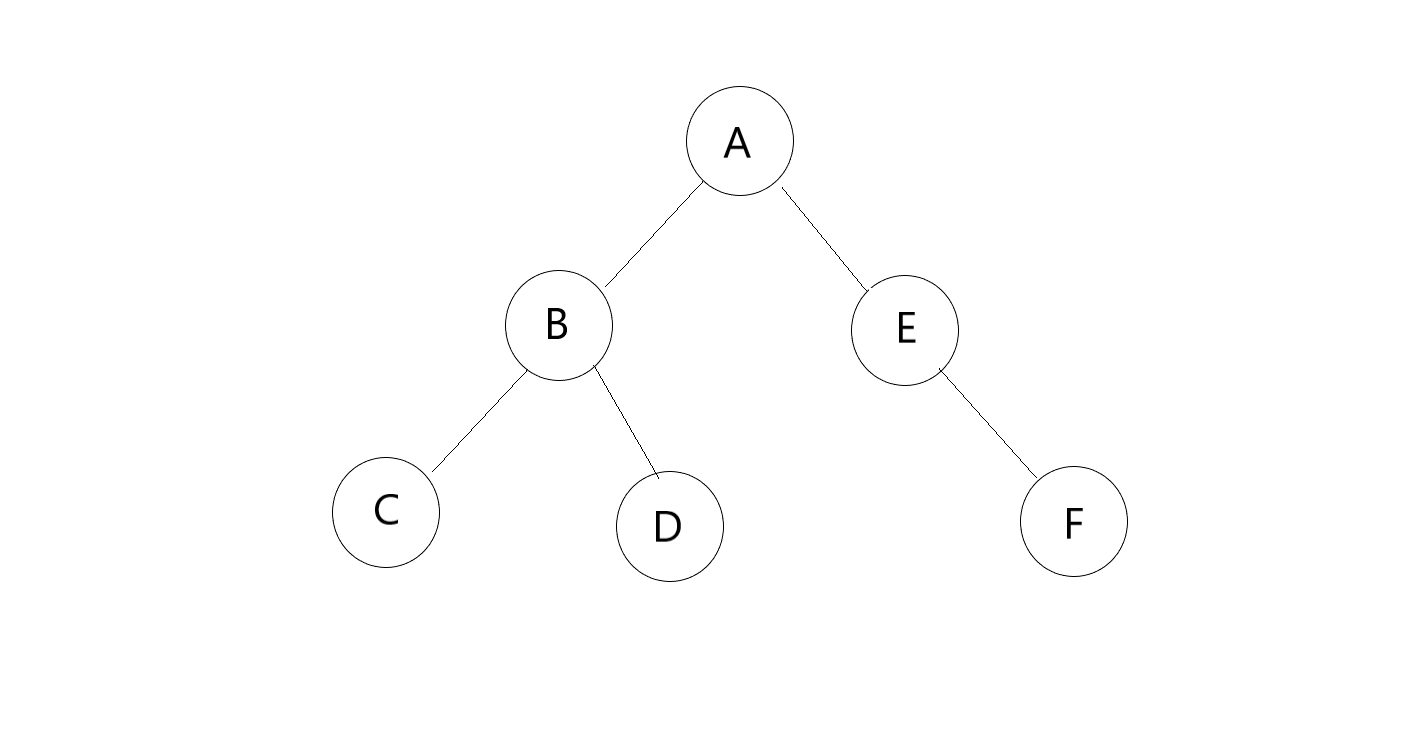
假如其dfs的访问次序是: \(A\ B\ C\ D\ E\ F\)
时间戳
我们给dfs遍历出的序列加上时间戳(即每个点加上编号)
例如: \(A(1)\ B(2)\ C(3)\ D(4)\ E(5)\ F(6)\)
因为dfs是深度优先遍历,因此如果我们知道以 \((i)\)为根结点的子树的大小 \((size[i])\),那么在dfs序中 \([i, i + size[i] - 1]\) 即为以i为根结点的子树,因此我么只需要以dfs序建树,并且处理出每个结点的子树大小,就可以解决后两个问题。
树链剖分
基础知识
重儿子: 表示其子节点中子树最大的子结点。如果有多个子树最大的子结点,取其一。如果没有子节点,就无重子节点。
轻儿子: 表示剩余的所有子结点。
从当前结点到重子节点的边为 重边,到其他轻子节点的边为 轻边。
若干条首尾衔接的重边构成 重链。
把落单的结点也当作重链,那么整棵树就被剖分成若干条重链。
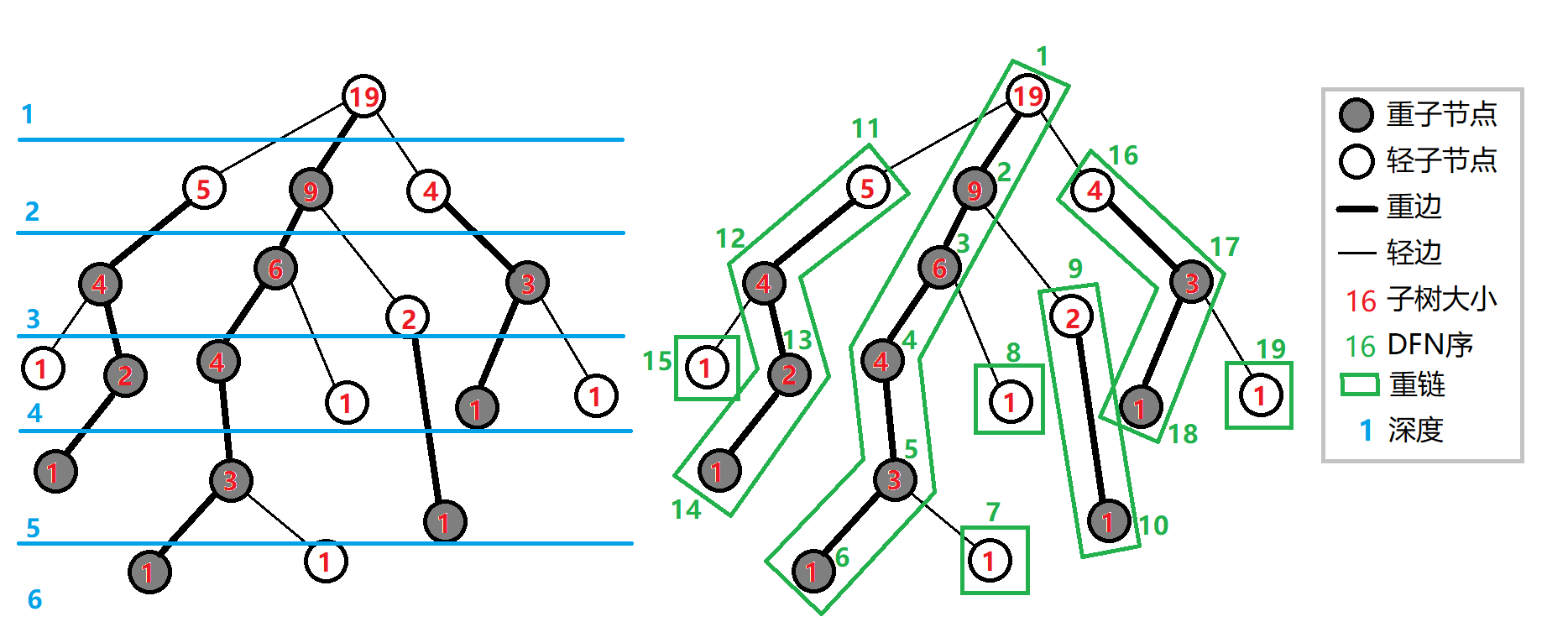
定义(对 \(x\)点)
- \(fa[x]\) 表示 \(x\) 的父亲节点
- \(dep[x]\) 表示 \(x\) 的深度
- \(siz[x]\) 表示 \(x\)的子树大小
- \(son[x]\) 表示 \(x\)的重儿子
- \(top[x]\) 表示 \(x\)所在重链的顶部节点(深度最小)
- \(dfn[x]\) 表示 \(x\)在dfs序中的时间戳
void dfs1(int o) {
son[o] = -1;
siz[o] = 1;
for (int j = h[o]; j; j = nxt[j])
if (!dep[p[j]]) {
dep[p[j]] = dep[o] + 1;
fa[p[j]] = o;
dfs1(p[j]);
siz[o] += siz[p[j]];
if (son[o] == -1 || siz[p[j]] > siz[son[o]]) son[o] = p[j];
}
}
void dfs2(int o, int t) {
top[o] = t;
cnt++;
dfn[o] = cnt;
rnk[cnt] = o;
if (son[o] == -1) return;
dfs2(son[o], t); // 优先对重儿子进行 DFS,可以保证同一条重链上的点 DFS 序连续
for (int j = h[o]; j; j = nxt[j])
if (p[j] != son[o] && p[j] != fa[o]) dfs2(p[j], p[j]);
}
重链剖分的性质
树上每个节点都属于且仅属于一条重链
重链开头的节点不一定是重儿子
所有重链将整棵树 完全剖分
在剖分时 重边优先遍历,最后输的DFS序上,重链内的DFS序是连续的。
因此对于树上任意一条路径,把它拆分成从 \(lca\)分别向两边往下走,分别最多走 \(O(logn)\)次,所以树上所有路径可以被拆分成不超过 \(O(logn)\)条重链。
求最近公共祖先
不断向上跳找那个链,知道跳到一条重链为止。深度较小的结点即位 \(lca\)。
向上跳重链时需要先跳所在重链顶端深度较大的那个。
int lca(int u, int v) {
while (top[u] != top[v]) {
if (dep[top[u]] > dep[top[v]])
u = fa[top[u]];
else
v = fa[top[v]];
}
return dep[u] > dep[v] ? v : u;
}
对于因子中的操作1( \(x\)到 \(y\)路径上所有节点的值加上 \(z\))
解决方法很明显,把两个点移动到同一条重链中即可,即找 \(lca\)
分几种情况讨论:
如果 \(z\)和\(y\) 在同一条重链中 \((top[x] = top[y])\),则直接进行 \([dfn[x],\ dfn[y]]\) 区间加操作即可。
否则就将深度大的结点一直向上移动直到满足上述条件。
void updateTree(int x, int y, int val) { //对于x,y路径上的点加val的权值
while (top[x] != top[y]) {
if (deep[top[x]] < deep[top[y]]) swap(x, y);
update(1, dfn[ top[x] ], dfn[x], val);
x = fa[ top[x] ];
}
if (dep[x] > dep[y]) swap(x, y);
update(1, dfn[x], dfn[y], val); //update(rt,l,r,v) [l,r]区间➕val
}
时间复杂度:
因为前面已经得出重链最多有 \(logn\)条,而每次需要更新线段树,即 \(O(logn)\),因此处理每次询问的复杂度为: \(O(log^2n)\)
故 \(q\)次询问的复杂度为: \(O(qlog^2n)\),并且常数很小。
至此完成了所有操作。
小结
首先处理出所需条件,以给出树的\(dfs\)序建树
对于后两个操作,直接根据 \(dfs\)序时间戳和 \(siz[]\) 建线段树维护即可
对于前两个操作,需要对树进行重链剖分,在两个点找 \(lca\)的过程中同时更新线段树即可。
标签:结点,剖分,int,top,dfs,树链,dep,重链 来源: https://www.cnblogs.com/KeepInCode/p/15150528.html