自编linearSVM
作者:互联网
转自https://zhuanlan.zhihu.com/p/27293420
Python · SVM(二)· LinearSVM
(这里是本章会用到的 Jupyter Notebook 地址)
很多人(包括我)第一次听说 SVM 时都觉得它是个非常厉害的东西,但其实 SVM 本身“只是”一个线性模型。只有在应用了核方法后,SVM 才会“升级”成为一个非线性模型
不过由于普遍说起 SVM 时我们都默认它带核方法,所以我们还是随大流、称 SVM 的原始版本为 LinearSVM。不过即使“只是”线性模型,这个“只是”也是要打双引号的——它依旧强大,且在许许多多的问题上甚至要比带核方法的 SVM 要好(比如文本分类)
感知机回顾
在进入正题之前,我们先回顾一下感知机,因为 LinearSVM 往简单来说其实就只是改了感知机的损失函数而已,而且改完之后还很像
感知机模型只有和
这两个参数,它们决定了一张超平面
。感知机最终目的是使得
,其中
是训练数据集、
只能取正负一
训练方法则是梯度下降,其中梯度公式为:
、
我们在实际实现时,采用了“极大梯度下降法”(亦即每次只选出使得损失函数最大的样本点来进行梯度下降)(注:这不是被广泛承认的称谓,只是本文的一个代称):
for _ in range(epoch):
# 计算 w·x+b
y_pred = x.dot(self._w) + self._b
# 选出使得损失函数最大的样本
idx = np.argmax(np.maximum(0, -y_pred * y))
# 若该样本被正确分类,则结束训练
if y[idx] * y_pred[idx] > 0:
break
# 否则,让参数沿着负梯度方向走一步
delta = lr * y[idx]
self._w += delta * x[idx]
self._b += delta
然后有理论证明,只要数据集线性可分,这样下去就一定能收敛
感知机的问题与 LinearSVM 的解决方案
由感知机损失函数的形式可知,感知机只要求样本被正确分类,而不要求样本被“很好地正确分类”。这就导致感知机弄出来的超平面(通常又称“决策面”)经常会“看上去很不舒服”:
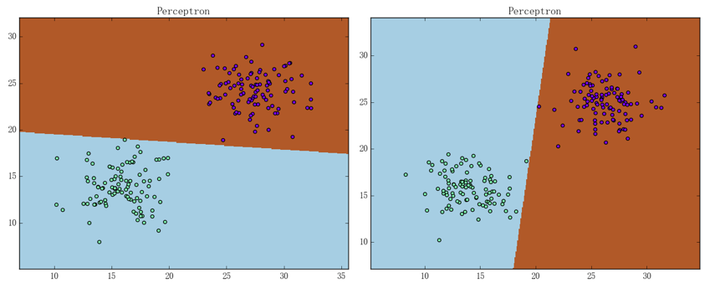
之所以看上去很不舒服,是因为决策面离两坨样本都太近了。从直观上来说,我们希望得到的是这样的决策面:
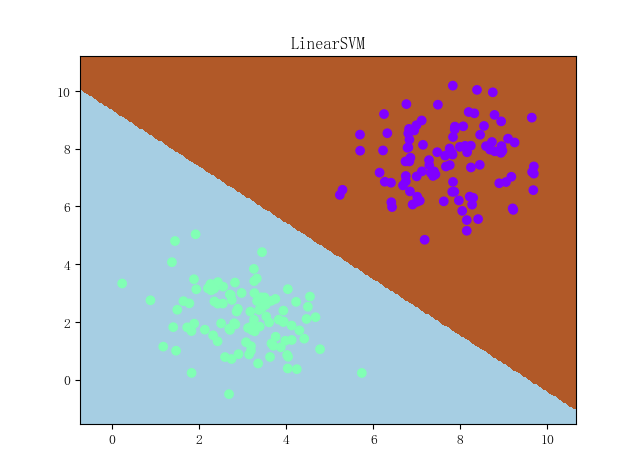
(之所以画风突变是因为 matplotlib 的默认画风变了,然后我懒得改了……)(喂
那么应该如何将这种理想的决策面的状态翻译成机器能够学习的东西呢?直观来说,就是让决策面离正负样本点的间隔都尽可能大;而这个“间隔”翻译成数学语言,其实就是简单的:
(文末会给出相应说明)
在有了样本点到决策面的间隔后,数据集到决策面的间隔也就好定义了:
所以我们现在的目的就转化为:
- 让所有样本点都被正确分类:
- 让决策面离正负样本点的间隔都尽可能大:
注意到的性质和
的值在
和
同时扩大 k 倍时不会改变,所以我们完全可以假设:
- 若
,则
(否则假设,令
即可)
注意由于这个最小化过程中
是固定的,所以我们可以把
这一项拿掉,从而:
所以
于是优化问题转为:
,使得
亦即
,使得
但是这会导致另一个问题:当数据集线性不可分时,上述优化问题是必定无解的,这就会导致模型震荡(换句话说,这个约束太“硬”了)。所以为了让模型在线性不可分的数据上仍有不错的表现,从直观来说,我们应该“放松”对我们模型的限制(让我们模型的约束“软”一点):
其中。当然仅仅放松限制会使模型变得怠惰(咦),所以我们还需要让这种放松受到惩罚:
,使得
(
)
其中是一个常数,可以把它理解为“惩罚力度”(这样做的合理性会在文末给出)。若假设数据集为
的话,那么经过数学变换后,可知上述优化问题等价于(文末会给出过程):
其中“”其实就是 ReLU 函数:
注意我们感知机的损失函数为,于是综上所述可以看出,LinearSVM 在形式上和感知机的差别只在于损失函数、且这两个损失函数确实长得很像
LinearSVM 的训练
【虽然比较简单,但是调优 LinearSVM 的训练这个过程是相当有启发性的事情。仍然是那句老话:麻雀虽小,五脏俱全。我们会先展示“极大梯度下降法”的有效性,然后会展示极大梯度下降法存在的问题,最后则会介绍如何应用 Mini-Batch 梯度下降法(MBGD)来进行训练】
为了使用梯度下降法,我们需要先求导。我们已知:
所以我们可以认为:
于是:
- 当
时:
、
- 当
时:
、
所以我们可以把极大梯度下降的形式写成(假设学习速率为):
- 若
,然后:
我们完全可以照搬感知机里的代码来完成实现(由于思路基本一致,这里就略去注释了):
import numpy as np
class LinearSVM:
def __init__(self):
self._w = self._b = None
def fit(self, x, y, c=1, lr=0.01, epoch=10000):
x, y = np.asarray(x, np.float32), np.asarray(y, np.float32)
self._w = np.zeros(x.shape[1])
self._b = 0.
for _ in range(epoch):
self._w *= 1 - lr
err = 1 - y * self.predict(x, True)
idx = np.argmax(err)
# 注意即使所有 x, y 都满足 w·x + b >= 1
# 由于损失里面有一个 w 的模长平方
# 所以仍然不能终止训练,只能截断当前的梯度下降
if err[idx] <= 0:
continue
delta = lr * c * y[idx]
self._w += delta * x[idx]
self._b += delta
def predict(self, x, raw=False):
x = np.asarray(x, np.float32)
y_pred = x.dot(self._w) + self._b
if raw:
return y_pred
return np.sign(y_pred).astype(np.float32)下面这张动图是该 LinearSVM 的训练过程:
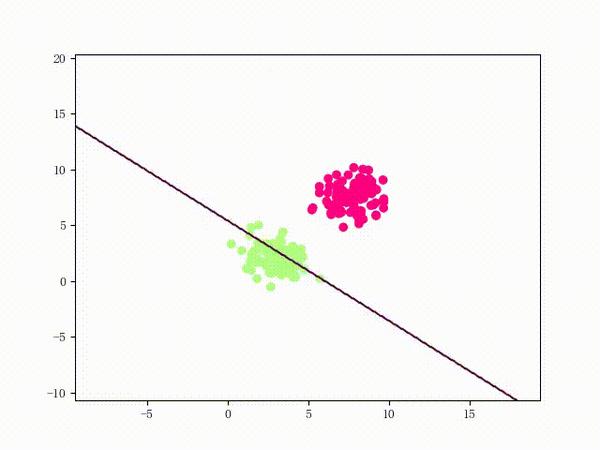
虽然看上去不错,但仍然存在着问题:
- 训练过程其实非常不稳定
- 从直观上来说,由于 LinearSVM 的损失函数比感知机要更复杂,所以相应的函数形状也会更复杂。这意味着当数据集稍微差一点的时候,直接单纯地应用极大梯度下降法可能会导致一些问题——比如说模型会卡在某个很奇怪的地方无法自拔(什么鬼)
通过将正负样本点的“中心”从原点 (0, 0)(默认值)挪到 (5, 5)(亦即破坏了一定的对称性)并将正负样本点之间的距离拉近一点,我们可以复现这个问题:
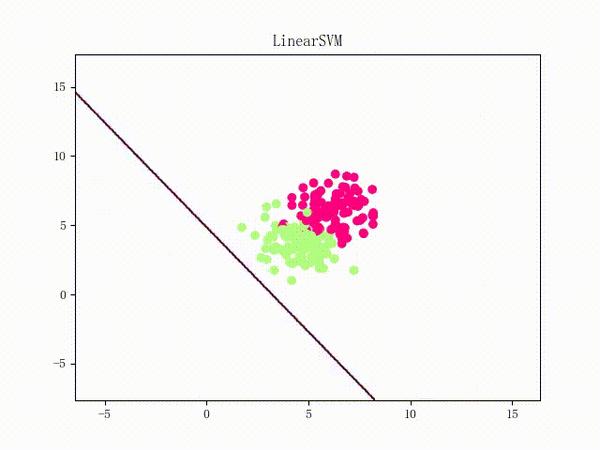
原理我不敢乱说,这里只提供一个牵强附会的直观解释:
- 每次只取使得损失函数极大的一个样本进行梯度下降
模型在某个地方可能来来回回都只受那么几个样本的影响
专业的理论就留待专业的观众老爷补充吧 ( σ'ω')σ
然后解决方案的话,主要还是从改进随机梯度下降(SGD)的思路入手(因为极大梯度下降法其实就是 SGD 的特殊形式)。我们知道 SGD 的“升级版”是 MBGD、亦即拿随机 Mini-Batch 代替随机抽样,我们这里也完全可以依样画葫芦。以下是对应代码(只显示出了核心部分):
self._w *= 1 - lr
# 随机选取 batch_size 个样本
batch = np.random.choice(len(x), batch_size)
x_batch, y_batch = x[batch], y[batch]
err = 1 - y_batch * self.predict(x_batch, True)
if np.max(err) <= 0:
continue
# 注意这里我们只能利用误分类的样本做梯度下降
# 因为被正确分类的样本处、这一部分的梯度为 0
mask = err > 0
delta = lr * c * y_batch[mask]
# 取各梯度平均并做一步梯度下降
self._w += np.mean(delta[..., None] * x_batch[mask], axis=0)
self._b += np.mean(delta)这样的话,通常而言会比 SGD 要好
但是问题仍然是存在的:那就是它们所运用的梯度下降法都只是朴素的 Vanilla Update,这会导致当数据的 scale 很大时模型对参数极为敏感、从而导致持续的震荡(所谓的 scale 比较大,可以理解为“规模很大”,或者直白一点——以二维数据为例的话——就是横纵坐标的数值很大)。下面这张动图或许能提供一些直观:

Again,原理我不敢乱说,所以只提供一个有可能对(更有可能错)(喂)的直观解释:
- scale太大
专业的理论就留待专业的观众老爷补充吧 ( σ'ω')σ
解决方案的话,一个很直接的想法就是进行数据归一化:。事实证明这样做了之后,最基本的极大梯度下降法也能解决上文出现过的所有问题了
然后一个稍微“偷懒”一点的做法就是,用更好的梯度下降算法来代替朴素的 Vanilla Update。比如说 Adam 的训练过程将如下(这张动图被知乎弄得有点崩……将就着看吧 ( σ'ω')σ):
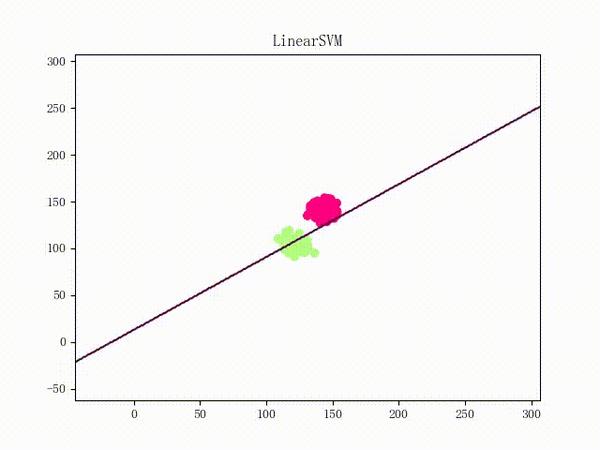
关于各种梯度下降算法的定义、性质等等可以参见这篇文章,实现和在 LinearSVM 上的应用则可以参见这里和这里
相关数学理论
我们尚未解决的问题有三个,但这些问题基本都挺直观的,所以大体上不深究也没问题(趴:
- 为什么被正确分类的样本
的间隔可以写成
- 为什么把优化问题从
*
转化成
*
是合理的 - 为什么上面这 个优化问题
*
等价于
*
这三个问题有一定递进关系,我们一个个来看
1)间隔的定义
我们在定义点到平面(超平面)
的间隔时,一般都是这样做的:
- 将
上
- 设投影点为
,则定义
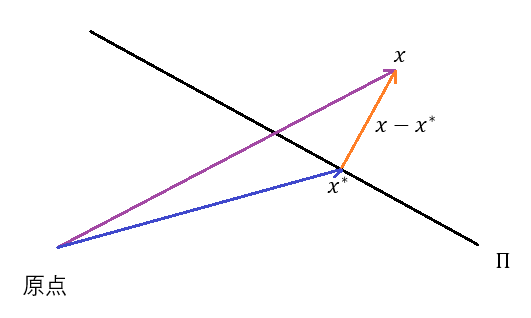
注意这里我们允许(当样本被错分类时的)间隔为负数,所以间隔其实严格来说并不是一般意义上的距离
那么为了找到垂直投影,我们得先找到垂直于超平面的方向。不难看出
就是垂直于
的,因为对
,由
知
(两式相减即可),从而
垂直于向量
,从而也就垂直于
:
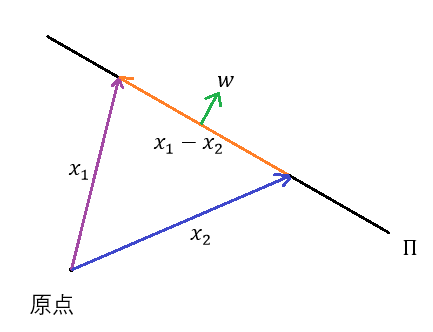
那么结合之前那张图,不难得知我们可以设(这里的
可正可负),于是就有(注意由
知
)
从而
注意这么定义的间隔有一个大问题:当和
同时增大
倍时,新得到的超平面
其实等价于原超平面
:
但此时却会直接增大
倍。极端的情况就是,当
和
同时增大无穷倍时,超平面没变,间隔却也跟着增大了无穷倍,这当然是不合理的
所以我们需要把 scale 的影响给抹去,常见的做法就是做某种意义上的归一化:
(注意:由于 scale 的影响已被抹去,所以也就跟着被抹去了;同时由
知,我们需要在抹去
的同时、给
套一个绝对值)
不难看出上式可改写为:
这正是我们想要的结果
2)优化问题的转化的合理性
我们已知原问题为
且由 1)知,式中的其实就是(没有抹去 scale 的影响的)间隔。所以想要放松对模型的限制的话,很自然的想法就是让这个间隔不必一定要不小于 1、而是只要不小于
就行,其中
是个不小于 0 的数。正如前文所说,只放松限制的话肯定不行、还得给这个放松一些惩罚,所以就在损失函数中加一个
即可,其中
是个大于 0 的常数、可以理解为对放松的惩罚力度
综上所述,优化问题即可合理地转化为:
3)优化问题的等价性
为方便,称优化问题:
为问题一;称:
为问题二,则我们需要证明问题一与问题二等价
先来看问题一怎么转为问题二。事实上不难得知:
注意问题一是针对和
进行优化的,且当
和
固定时,为使
最小,必有:
时,
时,
(因为我们要求
亦即。此时损失函数即为
,换句话说,我们就把问题一转为了问题二
再来看问题二怎么转为问题一。事实上,直接令,就有:
- 模型的损失为
- 模型的约束为
且
亦即转为了问题一
4)LinearSVM 的对偶问题
原始问题
的对偶问题为
,使得
、
通过拉格朗日乘子法可以比较简单地完成证明。不难得知原始问题相应的拉格朗日函数为:
其中、
,于是原始问题为
从而对偶问题为
于是我们需要求偏导并令它们为 0:
- 对
求偏导:
- 对
求偏导:
- 对
求偏导:
注意这些约束中除了
之外没有其它约束,
的约束可以转为
。然后把这些东西代入拉格朗日函数
、即可得到:
于是对偶问题为
,使得
亦即
可以看到在对偶形式中,样本仅以内积的形式()出现,这就使得核方法的引入变得简单而自然
5)Extra
作为结尾,我来叙述一些上文用到过的、但是没有给出具体名字的概念(假设样本为,超平面为
)
- 样本到超平面的函数间隔为:
- 样本到超平面的几何间隔为:
- 优化问题
*
的求解过程常称为硬间隔最大化,求解出来的超平面则常称为最大硬间隔分离超平面 - 优化问题
*
的求解过程常称为软间隔最大化,求解出来的超平面则常称为最大软间隔分离超平面
然后最后的最后,请允许我不加证明地给出两个结论(因为结论直观且证明太长……):
- 若数据集线性可分,则最大硬间隔分离超平面存在且唯一
- 若数据集线性不可分,则最大软间隔分离超平面的解存在但不唯一,其中:
- 法向量(
)唯一
- 偏置量(
标签:间隔,梯度,自编,样本,linearSVM,问题,超平面,self 来源: https://www.cnblogs.com/wcxia1985/p/15016576.html