大数据SQL中的Join谓词下推,真的那么难懂?
作者:互联网
听到谓词下推这个词,是不是觉得很高大上,找点资料看了半天才能搞懂概念和思想,借这个机会好好学习一下吧。
引用范欣欣大佬的博客中写道,以前经常满大街听到谓词下推,然而对谓词下推却总感觉懵懵懂懂,并不明白的很真切。这里拿出来和大家交流交流。个人认为谓词下推有两个层面的理解:
-
其一是逻辑执行计划优化层面的说法,比如SQL语句:select * from order ,item where item.id = order.item_id and item.category = ‘book’,正常情况语法解析之后应该是先执行Join操作,再执行Filter操作。通过谓词下推,可以将Filter操作下推到Join操作之前执行。即将where item.category = ‘book’下推到 item.id = order.item_id之前先行执行。
-
其二是真正实现层面的说法,谓词下推是将过滤条件从计算进程下推到存储进程先行执行,注意这里有两种类型进程:计算进程以及存储进程。计算与存储分离思想,这在大数据领域相当常见,比如最常见的计算进程有SparkSQL、Hive、impala等,负责SQL解析优化、数据计算聚合等,存储进程有HDFS(DataNode)、Kudu、HBase,负责数据存储。正常情况下应该是将所有数据从存储进程加载到计算进程,再进行过滤计算。谓词下推是说将一些过滤条件下推到存储进程,直接让存储进程将数据过滤掉。这样的好处显而易见,过滤的越早,数据量越少,序列化开销、网络开销、计算开销这一系列都会减少,性能自然会提高。
谓词下推 Predicate Pushdown(PPD):简而言之,就是在不影响结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,节约了集群的资源,也提升了任务的性能。
PPD 配置
PPD控制参数:hive.optimize.ppd,默认值:true
PPD规则:
| Preserved Row tables | Null Supplying tables | |
|---|---|---|
| Join Predicate | Case J1: Not Pushed | Case J2: Pushed |
| Where Predicate | Case W1: Pushed | Case W2: Not Pushed |
Push:谓词下推,可以理解为被优化
Not Push:谓词没有下推,可以理解为没有被优化
实验
实验结果列表形式:
| Pushed or Not | SQL |
|---|---|
| Pushed | select ename,dept_name from E join D on ( E.dept_id = D.dept_id and E.eid='HZ001'); |
| Pushed | select ename,dept_name from E join D on E.dept_id = D.dept_id where E.eid='HZ001'; |
| Pushed | select ename,dept_name from E join D on ( E.dept_id = D.dept_id and D.dept_id='D001'); |
| Pushed | select ename,dept_name from E join D on E.dept_id = D.dept_id where D.dept_id='D001'; |
| Not Pushed | select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001'); |
| Pushed | select ename,dept_name from E left outer join D on E.dept_id = D.dept_id where E.eid='HZ001'; |
| Pushed | select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001'); |
| Not Pushed | select ename,dept_name from E left outer join D on E.dept_id = D.dept_id where D.dept_id='D001'; |
| Pushed | select ename,dept_name from E right outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001'); |
| Not Pushed | select ename,dept_name from E right outer join D on E.dept_id = D.dept_id where E.eid='HZ001'; |
| Not Pushed | select ename,dept_name from E right outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001'); |
| Pushed | select ename,dept_name from E right outer join D on E.dept_id = D.dept_id where D.dept_id='D001'; |
| Not Pushed | select ename,dept_name from E full outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001'); |
| Not Pushed | select ename,dept_name from E full outer join D on E.dept_id = D.dept_id where E.eid='HZ001'; |
| Not Pushed | select ename,dept_name from E full outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001'); |
| Not Pushed | select ename,dept_name from E full outer join D on E.dept_id = D.dept_id where D.dept_id='D001'; |
实验结果表格形式:
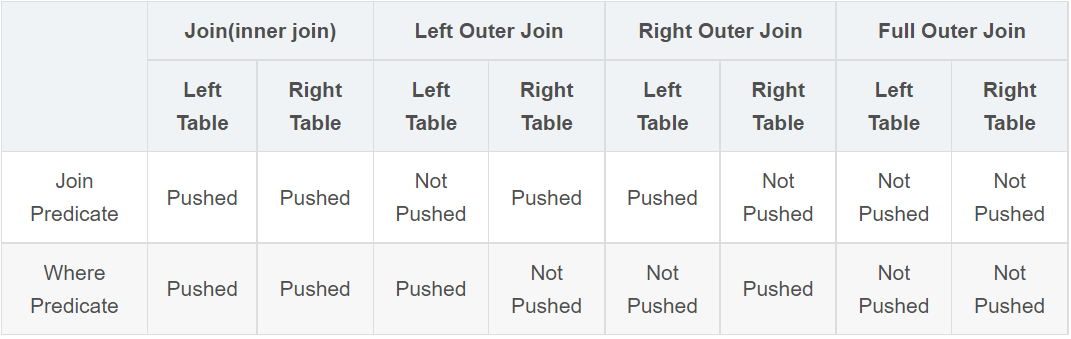
此表实际上就是上述PPD规则表。
结论
1、对于Join(Inner Join)、Full outer Join,条件写在on后面,还是where后面,性能上面没有区别;
2、对于Left outer Join ,右侧的表写在on后面、左侧的表写在where后面,性能上有提高;
3、对于Right outer Join,左侧的表写在on后面、右侧的表写在where后面,性能上有提高;
4、当条件分散在两个表时,谓词下推可按上述结论2和3自由组合,情况如下:
| SQL | 过滤时机 |
|---|---|
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001' and D.dept_id = 'D001'); |
dept_id在map端过滤,eid在reduce端过滤 |
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and D.dept_id = 'D001') where E.eid='HZ001'; |
dept_id,eid都在map端过滤 |
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001') where D.dept_id = 'D001'; |
dept_id,eid都在reduce端过滤 |
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id ) where E.eid='HZ001' and D.dept_id = 'D001'; |
dept_id在reduce端过滤,eid在map端过滤 |
注意:如果在表达式中含有不确定函数,整个表达式的谓词将不会被pushed,例如
select a.*
from a join b on a.id = b.id
where a.ds = '2019-10-09' and a.create_time = unix_timestamp();
因为unix_timestamp是不确定函数,在编译的时候无法得知,所以,整个表达式不会被pushed,即ds='2019-10-09'也不会被提前过滤。类似的不确定函数还有rand()等。
参考文献:
[1] https://cwiki.apache.org/confluence/display/Hive/OuterJoinBehavior
引用:https://blog.csdn.net/strongyoung88/article/details/81156271
猜你喜欢
Hive计算最大连续登陆天数
Hadoop 数据迁移用法详解
Hbase修复工具Hbck
数仓建模分层理论
一文搞懂Hive的数据存储与压缩
大数据组件重点学习这几个
标签:Join,name,Pushed,下推,dept,SQL,join,id,select 来源: https://www.cnblogs.com/data-magnifier/p/15531261.html