“蚂蚁呀嘿” 刷屏的背后:算法工程师带你理性解构神曲
作者:互联网
前几天小伙伴们是不是都被魔性的「蚂蚁呀嘿」刷屏了?其实背后的技术含量并不复杂,主要依靠的是换脸技术和自动节奏检测,算法会找到节奏点,在这些节奏点摇脸换表情,这样一支魔性而上头短视频就诞生了。今天为大家一一解构那些网络神曲,分享音乐信息检索算法,带你理性看神曲,或许下一个网络神曲缔造者就是你!
作者:意姝
审校:泰一
什么是音乐?
《礼记》里说,“凡音者,生人心者也,情动于中,形于声,声成文,谓之音”,音是表情达意的一种方式。从乐理上讲,通常音乐是由节奏、旋律、和声这三要素构成的,十二平均律这些律式和数学紧密相关。所以我们可以说,音乐是一个感性与理性交融的产物。而今天要介绍的音乐信息检索(Music Information Retrieval,MIR),便是从音乐里提取 “信息” ,用算法将音乐中理性的一面挖掘出来。
哪些是音乐的信息?
1. 节奏
首先我们来听一首抖音神曲:《鳌拜鳌拜鳌拜拜》
https://y.qq.com/n/yqq/song/000ZCScz4g4BuM.html
歌曲中让你忍不住跟着一起摇头抖腿的强烈的鼓点,就是节奏点,这是对节奏一种感性的认知。
严格来说,节奏是被组织起来的音的长短关系,它像是音乐的骨架,把音乐支撑了起来。譬如下图乐谱上的 “4/4” 是拍号,代表着这首曲子的音长的组织形式为:以四分音符为一拍,每小节 4 拍。每小节的第一拍往往为强拍(downbeat),这里的 “down” 和指挥的手势一致。
其它常见的拍号还有:2/4,3/4 等,这些都是单拍子(simple meter),也就是每拍自然二等分的节拍。除此之外还有复拍子(compound meter),指的是每拍自然三等分的节拍,如 6/8,复二拍子,读作 “一二三,二二三,一二三,二二三” 。

爵士乐、灵魂乐的魅力很多都在于对节奏的运用,遗憾的是,相当一部分华语流行歌曲都是 4/4 拍子的,导致听感上有很多雷同之处。
2. 音高
音乐是一种声音,所以也是由物体震动产生的,音的高低是由振动频率决定的。乐器发出的声音或人声,一般都不会只包含一个频率,而是可以分解成若干个不同频率的音的叠加。
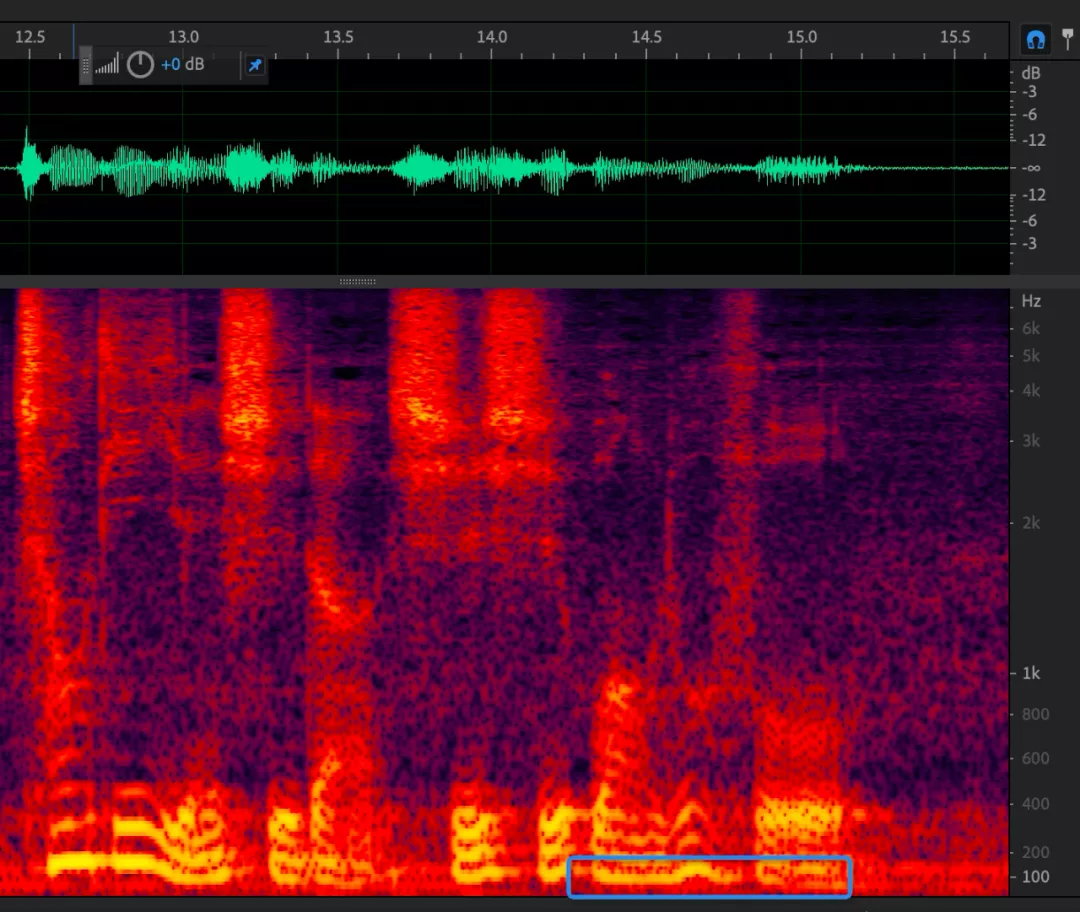
这些频率都是某一频率的倍数,这一频率就称作基频,也就决定了这个音的音高。下图为一段男声朗读的音频的语谱图,最下面蓝色框出来的部分就是当前时刻的基频。通常人声的音高在 100Hz~200Hz 左右。
对于流行歌曲而言,音高常常指的是它的主旋律,也就是人声唱的部分。
3. 和弦
现代音乐概念里面,由多个不同的音高同时发声就叫和声,三个或三个音以上的和声就叫做和弦。当这些音同时弹奏时,叫做柱式和弦,而当它们先后奏出时,便叫做分解和弦。
不过,并不是随便按下几个音,都可以带来悦耳的听感。由十二平均律可知,一个八度平均分成十二等份,每份称为半音,每个半音的频率为前一个半音的 2 的 12 次方根。常见的有三(个音的)和弦,七(度音的)和弦,基本的三和弦的组成如下图所示。

4. 段落
像文章一样,音乐也可以划分为一个个段落,让情感的表达有了起承转合。段落的组织形式多种多样,常见的有如下几种:
- AAA一段旋律的重复,简洁明了,常见于宗教音乐。
https://y.qq.com/n/yqq/song/004Yc5sF3Rq7Wn.html
- ABAB两段旋律交叉重复。
https://y.qq.com/n/yqq/song/000aKduC3mu0IL.html
钢铁侠出场音乐
- AABA在重复的旋律中添加一段不太一样的,避免乏味感,如这首圣诞歌曲。
https://y.qq.com/n/yqq/song/002zL7ur42FYtK.html
- 古典音乐
一些古典音乐有自己的内容组织形式,如奏鸣曲式(sonata form),它的结构由呈示部、展开部、再现部三大段依序组成。
- 流行音乐
大家比较熟悉的结构是 “前奏、(主歌 - 副歌)*n、尾奏” ,当然流行音乐的创作比较自由,有时创作者会在两段副歌之间添加桥段来避免单调,或在主歌与副歌之间添加过渡段,使得情绪过渡更为自然。
如何提取这些信息
传统的方法是 “提特征 + 分类器” ,这些特征包括时域和频域的。
音频信号常常用二维的特征来表征:一维频率、一维时间。这样我们可以用对待图像的方式,将音频特征输入到分类器中。不过音频特征和图像也有所区别,图像具有局部相关性,即相邻的像素点特征比较接近,而频谱的相关性,体现在各个泛音之间,局部的相似性比较弱。
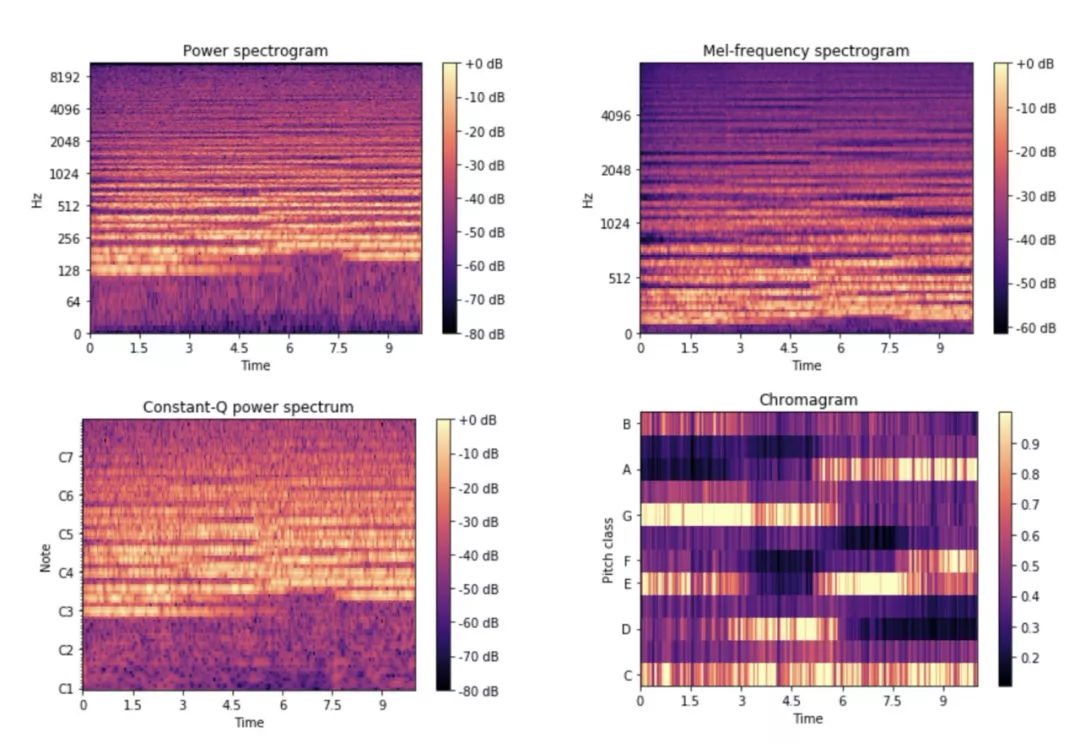
举个栗子,我们用周杰伦《简单爱》的前 10s 的和弦(C,G,Am,F)渲染出一段音频,下图所示的 4 个频谱类的特征,从左上到右下分别为:短时傅立叶变换、Mel-Spectrogram、Constant-Q Transform、Chromagram,前三个都可以理解为通过滤波器组把原始的音频信号做拆分。
在提取特征的过程中,一些抽象的、隐藏在音乐信号中的语义便浮出水面。在 Chromagram 中,纵轴是 Pitch Class(音高集合,e.g. “音高集合 C” 包含了 C1,C2,C3....)。从图中可以看出,0s~3s 最亮的三个音分别是 C、E、G,可以推测出这是一个 C 和弦,合适的特征让 “和弦检测” 这个分类任务的难度有所降低。
随着深度学习在各个领域的蓬勃发展,深度网络也逐渐成为 “分类器” 的首选,不过也要 “因地制宜” ,像节奏这种对音乐上下文有所依赖的音乐 “信息”,RNN 类的网络往往效果更佳。
我们现在能做到哪些
因为我们的应用场景同时包含了实时与离线,所以下列算法很多都有实时的版本,可用在实时音视频通信等场景。
1. 节奏检测
如上文所述,节奏点就是歌曲拍子所在的位置。前阵子比较火的 “蚂蚁呀嘿”,照片中头动起来的样子非常魔性,这些动作就是按照歌曲的节奏点来设计的。下面我们把利用算法检测出来的节拍,用类似于节拍器的声音呈现出来,学过乐器的同学应该对这 “嗒嗒嗒” 的声音有印象。通过节奏检测的算法自动识别出其他歌曲的节奏点,我们也可以制作自己的 “蚂蚁呀嘿” 模板。
https://v.youku.com/v_show/id_XNTExOTA4Mzc2MA==.html
上文还提到了 “强拍” ,可以用来区分小节。我们的方法除了检测出 beat,还能区分出 downbeat,下面的视频展示出了 “蚂蚁呀嘿” 里的 downbeat:
https://v.youku.com/v_show/id_XNTExOTA4MzQ1Mg==.html
有同学可能会好奇,你们的算法检测出 beat、downbeat 有什么用啊,不就是一些时间点嘛?
其实可以衍生出很多音乐的玩法,譬如说前几年很火的音乐游戏,节奏大师,一个跟着旋律、节奏来疯狂输出的游戏。
我们在公开数据集(GTZAN)和由 100 首流行歌曲构成的内部数据集上,评测了我们的方法,结果如下表所示。我们的方法在两个数据集上均有 0.8 以上的 F 值,具有一定的鲁棒性。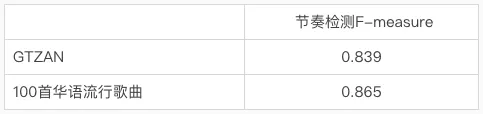
2. 实时音高检测
我们的方法可以做到输入一帧音频,然后输出当前帧的音高,以赫兹为单位。
上面这句话看上去似乎有些干瘪,那这些数字有哪些作用呢?
举个栗子,很多 K 歌软件里都有下图中红框中的内容,它们是歌曲的音高线。衡量歌唱得准不准,主要就是看演唱者的音高、节奏和原曲的匹配程度。
在这个场景下,我们的音高检测算法可以实时地分析用户的演唱水平,并给出分数。
除此之外,实时音视频通信中的一些场景也依赖音高检测,如 Voice Activity Detection (VAD),如果当前帧有音高的话,说明有人声。

3. 段落检测
流行音乐常见的段落类型有:前奏、主歌、过渡段、副歌、间奏、桥段、尾奏这 7 种。
我们调研了市面上做段落检测的方法,很多都是基于自相似矩阵(Self-Similarity Matrix, SSM),对音乐结构做了 segmentation,也即它们仅仅能划分时间区间,而无法给出具体的段落类型;Ullrich et al. 提出了基于 CNN 的有监督学习的方法,可以检测出不同粒度下段落的边界。除了 “segmentation” ,我们的方法还可以做到 “classification”,即可以给出每个段落的时间区间和类型(上述 7 种)。
我们选取了音乐软件上热门榜单里的前 100 首歌曲,来作为我们的评测样本集,评测结果及指标含义如下所示:

这 100 首中包含了 19 首土味 DJ remix 歌曲,由于这些歌曲动态范围较小,能量很强,“动词打次” 的声音掩盖了很多原曲的特质,所以在这类歌曲上,段落检测算法表现较弱。刨除这些 DJ 歌曲后,算法的 F_pairwise_chorus 可以达到 0.863。
考虑到现在对音乐的消费越来越快餐,而且有时候为了给视频配乐,需要截取音乐的片段,而副歌往往是一首流行乐最 “抓耳” 的部分,我们将算法封装为 “副歌检测” 的功能,一键帮用户筛选出流行歌里所有的副歌,具体的调用方式在这里。
这里以周杰伦的《说好的幸福呢》为例,算法的输出结果如下图所示,时间单位为秒,大家可以边欣赏 MV、边感受副歌的情感与能量~ 
4. 实时声音场景识别
上文提到了一些 MIR 算法的效果及应用,不过在哪些场景下可以使用它们呢?也即如何区分出音乐场景呢?
针对这个问题,我们提供有声音场景识别的算法能力,可以识别出当前是 “语音、音乐、噪声” 中的哪一种,而且针对语音,可以进一步区分性别(男 | 女)。
下面是一段《新闻联播》的音频,声音场景识别算法标记出了其中的音乐、男声、女声,以及无声音(也即没有能量)的部分。
https://v.youku.com/v_show/id_XNTExOTA4NDQ0NA==.html
关于我们
阿里云视频云 - 语音与音乐算法团队,主要为视频时代的娱乐、教育等场景提供语音音乐等音频的解决方案。在这里你可以了解到更多前沿的音频算法应用,欢迎与我们一起打造更好的音频世界!
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。
标签:音高,节奏,刷屏,神曲,音乐,解构,算法,副歌,音频 来源: https://blog.51cto.com/14968479/2656160