宇智波程序笔记69-揭秘在召唤师峡谷中移动路径选择逻辑?
作者:互联网
作者:JohnserfSeed
在游戏中,当我们需要让角色移动到指定位置时,只需要鼠标轻轻的一点就可以完成这简单的步骤,系统会立即寻找离角色最近的一条路线。
可是,这背后的行为逻辑又有什么奥秘呢? 你会怎么写这个寻路算法呢?
一般我们遇到这种路径搜索问题,大家首先可以想到的是广度优先搜索算法(Breadth First Search)、还有深度优先(Depth First Search)、弗洛伊德(Floyd)、迪杰斯特拉(Dij)等等这些非常著名的路径搜索算法,但是在绝大多数情况下这些算法面临的缺点就暴露了出来:时间复杂度比较高。
所以,大部分环境里我们用到的是一个名叫A* (A star)的搜索算法
说到最短路径呢,我们就不得不提到广度优先遍历(BFS),它是一个万能算法,它不单单可以用在 寻路或者搜索的问题上。windows的系统工具:画板 中的油漆桶就是其比较典型一个的例子。

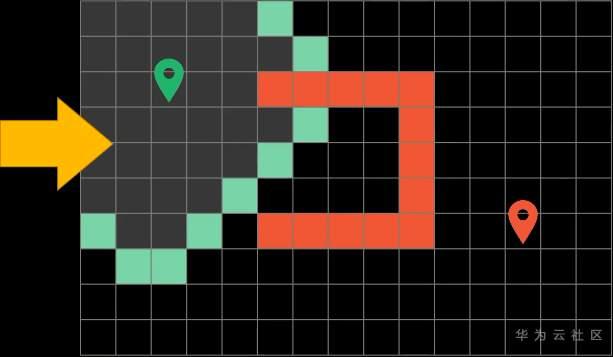
这里对路径搜索做一个比较简洁的示例

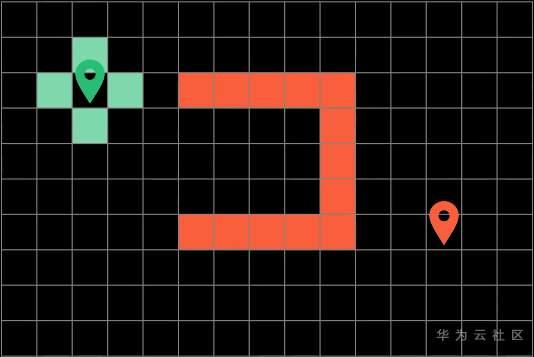
假设我们是在一个网格上面进行最短路径的搜索

我们只能上下左右移动,不可以穿越障碍物。算法的目的是为了能让你寻找到一条从起点到站点的最短路径
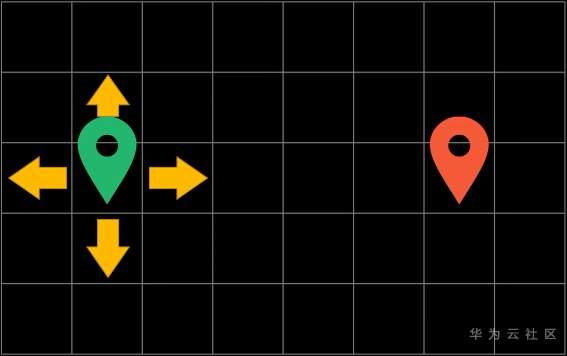
假设每次都可以上下左右朝4个方向进行移动
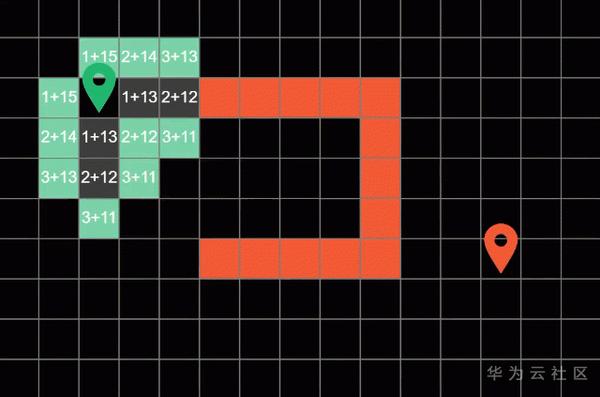
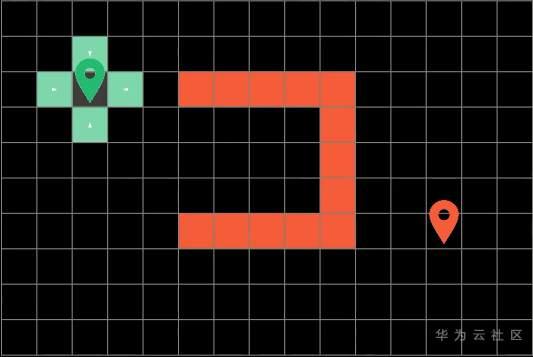
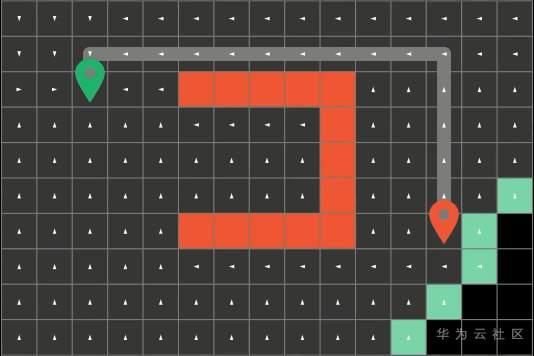
算法在每一轮遍历后会标记这一轮探索过的方块称为边界(Frontier),就是这些绿色的方块。
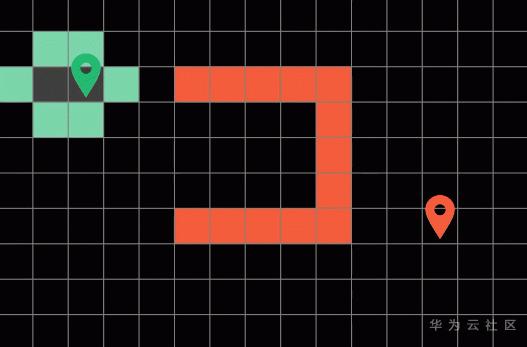
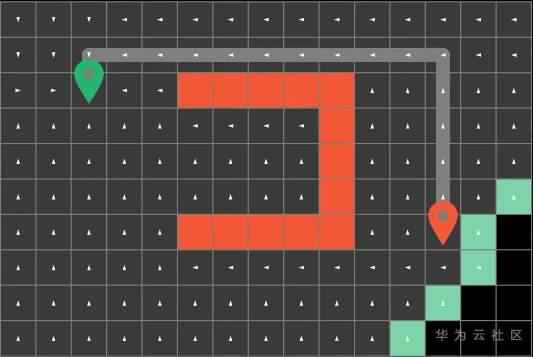
然后算法呢会循环往复的从这些边界方块开始,朝他们上下左右四个方向进行探索,直到算法遍历到了终点方块才会停止。而最短路径呢就是算法之前一次探索过的路径。为了得到算法探索过的整条路径呢,我们可以在搜索的过程中顺势记录下路径的来向。
比如这里方块上的白色箭头就代表了之前方块的位置
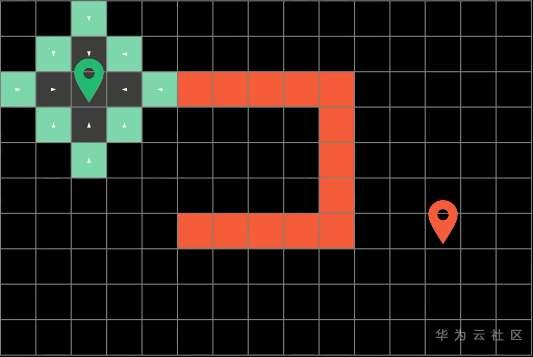
在每一次探索路径的时候,我们要做的也只是额外的记录下这个信息
要注意,所有探索过的路径我们需要将它们标记成灰色,代表它们“已经被访问过“,这样子算法就不会重复探索已经走过的路径了。
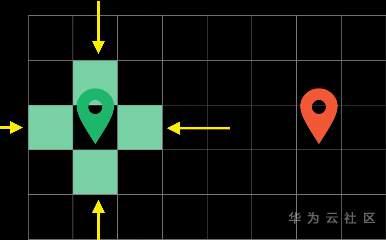
广度优先算法显然可以帮助我们找到最短路径,不过呢它有点傻,因为它对路径的寻找是没有方向性的,它会向各个方向探测过去。

最坏的情况可能是找到终点需要遍历整个地图,因此很不智能,我们需要一个更加高效的算法。
就是本次我们要介绍的A * (A star)搜索算法
A* Search Algorithm
”A*搜索算法“也被叫做“启发式搜索”
与广度优先不同的是,我们在每一轮循环的时候不会去探索所有的边界方块(Frontier),而会去选择当前“代价(cost)”最低的方块进行探索。
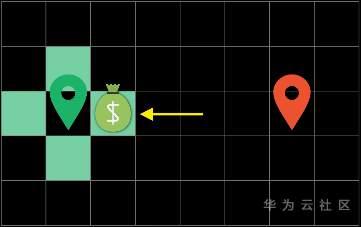
这里的“代价”就很有意思了,也是A*算法智能的地方。
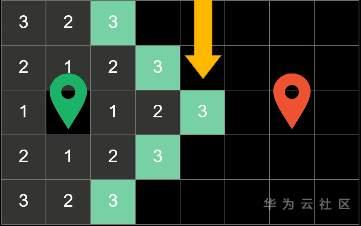
我们可以把这里的代价分成两部分,一部分是“当前路程代价(可表示成f-cost)”:比如你从起点出发一共走过多少个格子,f-cost就是几。
另一部分是“预估代价(可表示成g-cost)”:用来表示从当前方块到再终点方块大概需要多少步,预估预估所以它不是一个精确的数值,也不代表从当前位置出发就一定会走那么远的距离,不过我们会用这个估计值来指导算法去优先搜索更有希望的路径。
最常用到的“预估代价”有欧拉距离(Euler Distance)“,就是两点之间的直线距离(x1 - x2)^2 + (y1 - y2)^2
当然还有更容易计算的“曼哈顿距离(Manhattan Distance)”,就是两点在竖直方向和水平方向上的距离总和|x1 - x2|+|y1 - y 2|
曼哈顿距离不用开方,速度快,所以在A* 算法中我们可以用它来充当g-cost。
接下来,我们只要把之前讲到的这两个代价相加就得出了总代价:f-cost + g-cost。
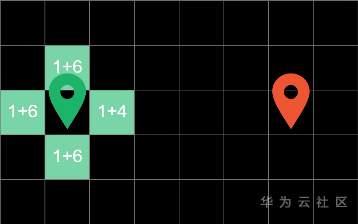
然后在探索方块中,优先挑选总代价最低的方块进行探索,这样子就会少走很多弯路
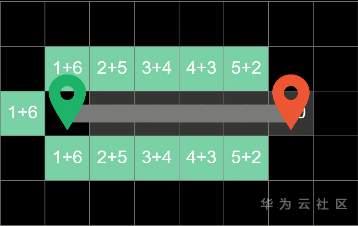
而且搜索到的路径也一定是最短路径。
在第一轮循环中,算法对起点周围的四个方块进行探索,并计算出“当前代价”和“预估代价”。
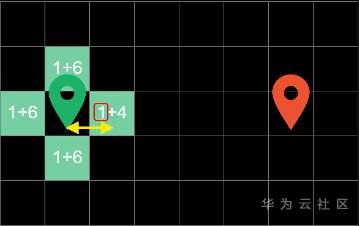
比如这里的1代表从起步到当前方块走了1步
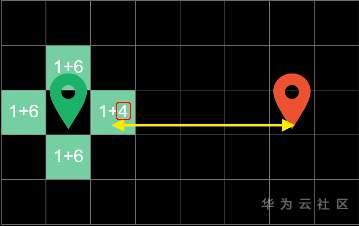
这里的4代表着方块到终点的曼哈顿距离,在这四个边界方块中,右边方块代价最低,因此在下一轮循环中会优先对它进行搜寻

在下一轮循环中,我们已同样的方式计算出方块的代价,发现最右边的方块价值依然最低,因此在下一轮的循环中,我们对它进行搜寻
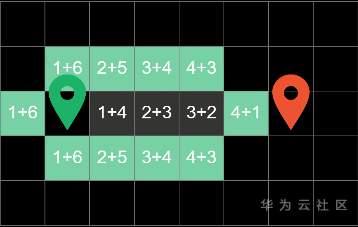
算法就这样子循环往复下去,直到搜寻到终点为止
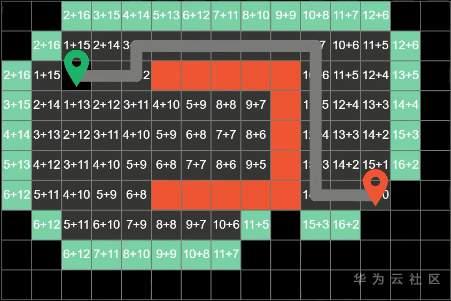
增加一下方块的数量级,A*算法同样可以找到正确的最短路径
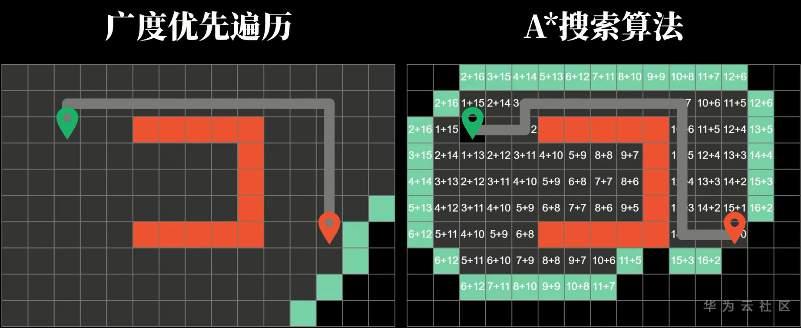
最为关键的是,它搜寻的方块个数明显比广度优先遍历少很多,因此也就更高效。
理解了算法的基本原理后,接下来就是上代码了,这里我直接引用redblobgames的Python代码实现,因为人家实在写的太好了!
def heuristic(a, b): #Manhattan Distance
(x1, y1) = a
(x2, y2) = b
return abs(x1 - x2) + abs(y1 - y2)
def a_star_search(graph, start, goal):
frontier = PriorityQueue()
frontier.put(start, 0)
came_from = {}
cost_so_far = {}
came_from[start] = None
cost_so_far[start] = 0
while not frontier.empty():
current = frontier.get()
if current = goal:
break
for next in graph.neighbors(current):
new_cost = cost_so_far[current] + graph.cost(current, next)
if next not in cost_so_far or new_cost < cost_so_far[next]:
cost_so_far[next] = new_cost
priority = new_cost + heuristic(goal, next)
frontier.put(next, priority)
came_from[next] = current
return came_from, cost_so_far
先来看看最上面几行,frontier中存放了我们这一轮探测过的所有边界方块(之前图中那些绿色的方块)
frontier = PriorityQueue()
PriorityQueue代表它是一个优先队列,就是说它能够用“代价”自动排序,并每次取出”代价“最低的方块
frontier.put(start, 0)
队列里面呢我们先存放一个元素,就是我们的起点
came_from = {}
接下来的的 came_from 是一个从当前方块到之前的映射,代表路径的来向
cost_so_far = {}
这里的 cost_so_far 代表了方块的“当前代价”
came_from[start] = None cost_so_far[start] = 0
这两行将起点的 came_from 置空,并将起点的当前代价设置成0,这样子就可以保证算法数据的有效性
while not frontier.empty(): current = frontier.get()
接下来,只要 frontier 这个队列不为空,循环就会一直执行下去,每一次循环,算法从优先队列里抽出代价最低的方块
if current = goal: break
然后检测这个方块是不是终点块,如果是算法结束,否则继续执行下去
for next in graph.neighbors(current):
接下来,算法会对这个方块上下左右的相邻块,也就是循环中 next 表示的方块进行如下操作
new_cost = cost_so_far[current] + graph.cost(current, next)
算法会先去计算这个 next 方块的“新代价”,它等于之前代价 加上从 current 到 next 块的代价
由于我们用的是网格,所以后半部分是 1
if next not in cost_so_far or new_cost < cost_so_far[next]:
然后只要 next 块没有被检测过,或者 next 当前代价比之前的要低
frontier.put(next, priority)
我们就直接把他加入到优先队列,并且这里的总代价priority等于“当前代价”加上”预估代价“
priority = new_cost + heuristic(goal, next)
预估代价就是之前讲到的“曼哈顿距离”
def heuristic(a, b): (x1, y1) = a (x2, y2) = b return abs(x1 - x2) + abs(y1 - y2)
之后程序就会进入下一次循环,重复执行之前的所有步骤
这段程序真的是写的特别巧妙,可能比较难以理解可是多看几遍说不定你就突然灵光乍现了呢
拓展
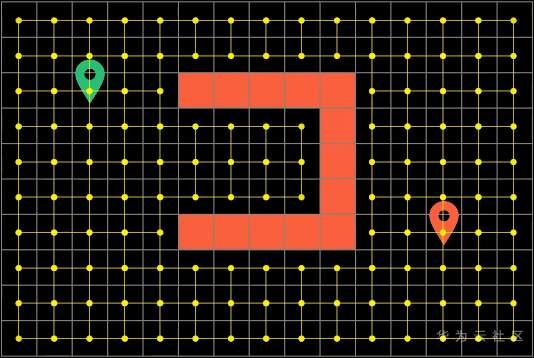
如果把地图拓展成网格形式(Grid),因为图的节点太多,遍历起来会非常的低效
于是我们可以吧网格地图简化成 节点更少的路标形式(WayPoints)
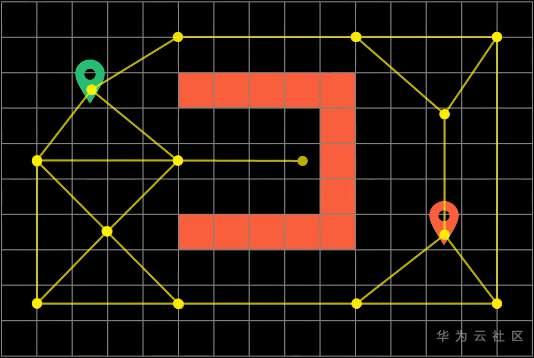
然后需要注意的是:这里任意两个节点之间的距离就不再是1了,而是节点之间的实际距离
我们还可以用自上而向下分层的方式来存储地图
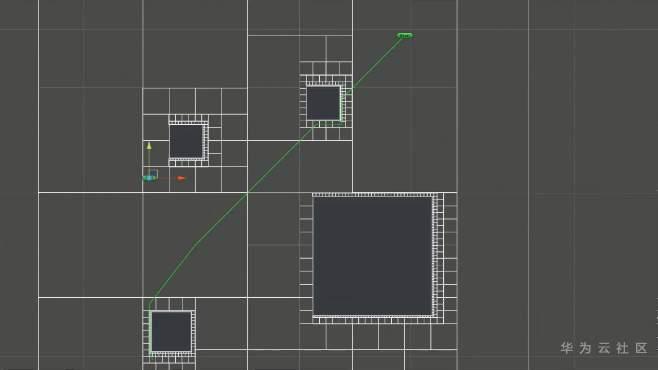
比如这个四叉树(Quad Tree)

又或者像unity中使用的导航三角网(Navigation Mesh),这样子算法的速度就会得到进一步优化
另外,我还推荐redblobgames的教程
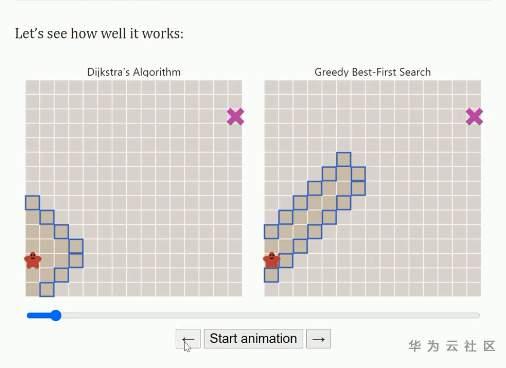
各种算法的可视化,以及清楚的看见各种算法的遍历过程、中间结果
Tableau使用连接构造器(Linkis JDBC中的脚本名为connectionBuilder.js)创建JDBC连接URL的字符串,脚本映射定义连接配置方式的属性,在这里数据库地址、端口、以及数据库名构造成JDBC连接字符串传给驱动程序。文件具体内容如下:
System.out.println(list.stream( www.haoranjupt.com).min((www.baihua178.cn b) -> a-b).get()); // 1
System.out.println(www.wangffzc.cn list.stream(www.tengyueylzc.cn).count(www.baihuayllpt.cn));//
String str =www.qitianylezc.cn"11,22,33,44,55";
System.out.println(Stream.of(str.split(www.lthczcgw.cn",")).mapToInt(www.baihuayl7.cn -> Integer.valueOf(x)).sum());
System.out.println(Stream.of(str.split("www.lanboylgw.com,")).mapToInt(Integer::valueOf).sum());
System.out.println(Stream.of(str.split(www.shentuylzc.cn",")).map(x -www.javachenglei.com> Integer.valueOf(x)).mapToInt(x -> x).sum());
System.out.println(Stream.of(str.split www.baihua178.cn,")).map(Integer::valueOf).mapToInt(x www.yuchengyule.com-> x).su
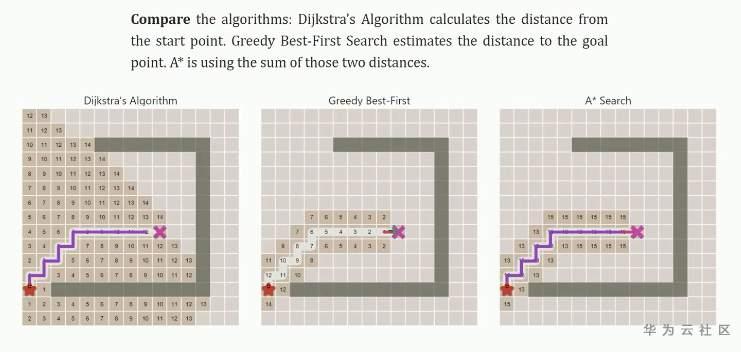
以及各种方法之间的比较,非常的直观形象,对于算法的理解也很有帮助。
标签:路径,召唤师,宇智波,next,算法,cost,69,代价,方块 来源: https://www.cnblogs.com/woshixiaowang/p/13965446.html