20191318实验四 《Python程序设计》实验报告
作者:互联网
20191318 《Python程序设计》实验三报告
课程:《Python程序设计》
班级: 1913
姓名: 王泽文
学号:20191318
实验教师:王志强
实验日期:2020年6月10日
必修/选修: 公选课
1. 实验内容
- Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
- 我选择了一个爬虫,爬取bilibili弹幕网站单个视频和up主的一些信息。
2. 实验过程及结果
- 在这次的编程中需要用到
re,requests,json,tkinter,xlwt,xmltodict,time的Python库。 - 首先需要对B站的网页进行分析,在网上进行查询后我得知可以通过一些api的接口获得B站的数据。于是我便使用了一些api网址来简化我的网页分析。
BilibiliAPI合集 - 对于一些api中没有的信息,爬取便通过正则表达式获得。
- 爬虫分两个部分,一是对视频的爬取,二是对up主的爬取。
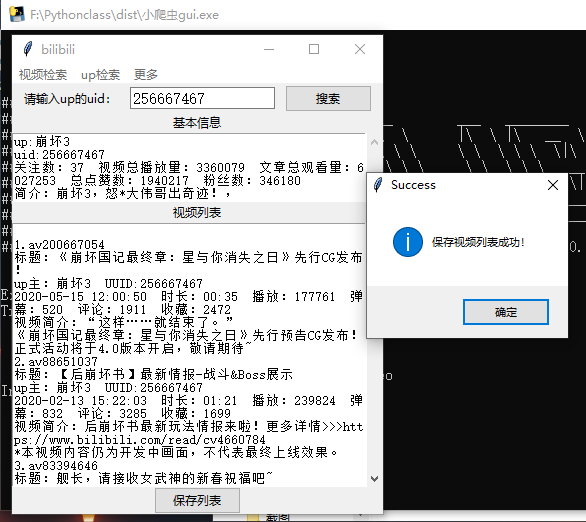
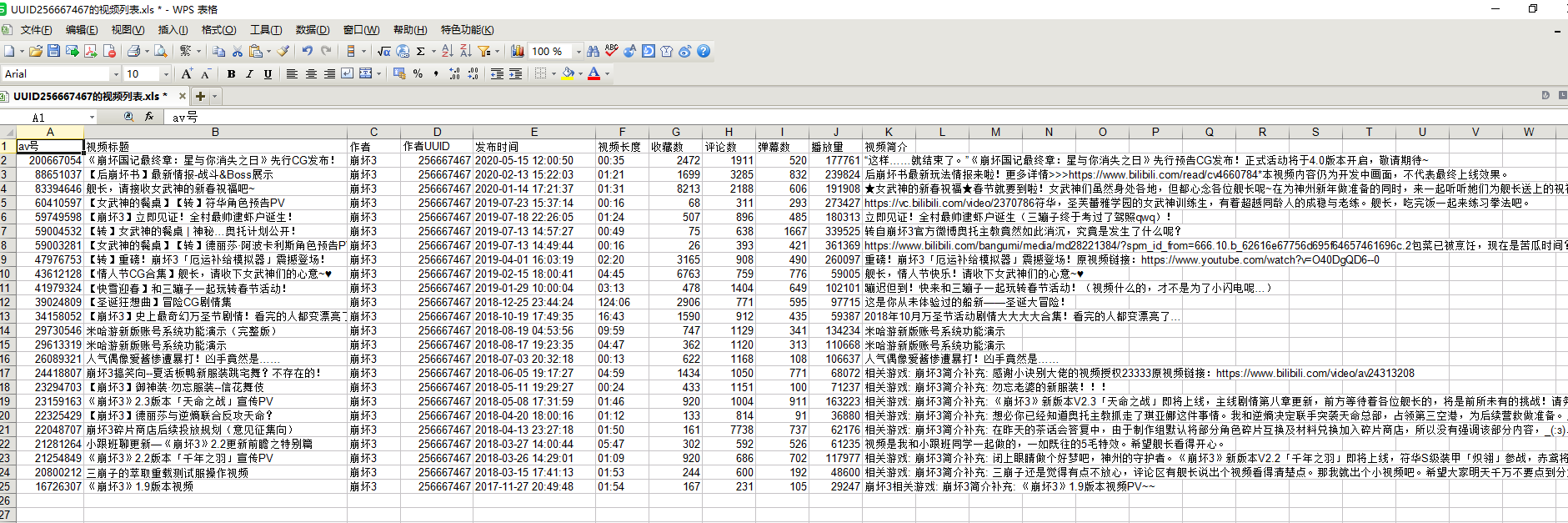
运行效果如图
以up主 崩坏三 (UUID:256667467)为例:
以视频BV号:BV1Yz411q7iT为例:
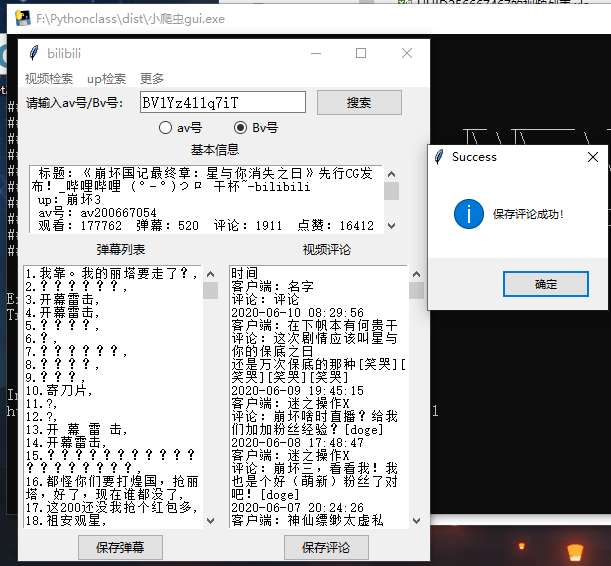
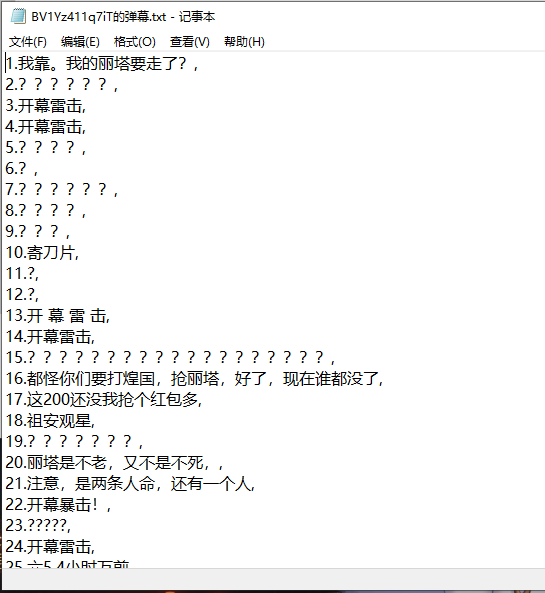
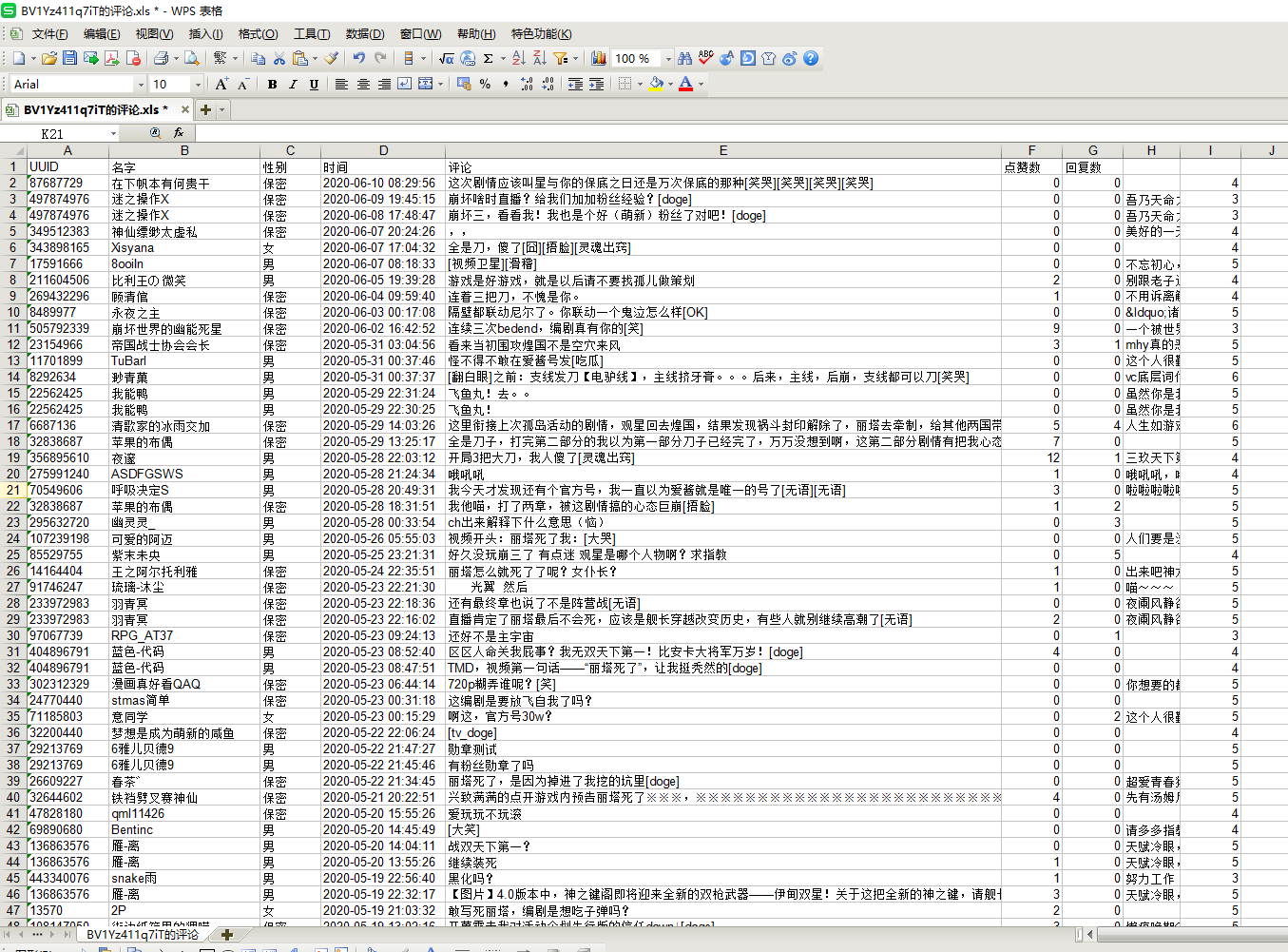
- 代码如下
import tkinter as tk
from tkinter import ttk
import tkinter.scrolledtext as tks
import re
import requests
import json
import tkinter.messagebox
import xlwt
import xmltodict
import time
a = '''
//
\ \ //
\ \ //
##DDDDDDDDDDDDDDDDDDDDDD##
## DDDDDDDDDDDDDDDDDDDD ## ________ ___ ___ ___ ________ ___ ___ ___
## hh hh ## |\ __ \ |\ \ |\ \ |\ \ |\ __ \ |\ \ |\ \ |\ \
## hh // \ \ hh ## \ \ \|\ /_\ \ \ \ \ \ \ \ \ \ \ \|\ /_ \ \ \ \ \ \ \ \ \
## hh // \ \ hh ## \ \ __ \ \ \ \ \ \ \ \ \ \ \ \ __ \ \ \ \ \ \ \ \ \ \
## hh hh ## \ \ \|\ \ \ \ \ \ \ \____ \ \ \ \ \ \|\ \ \ \ \ \ \ \____ \ \ \
## hh wwww hh ## \ \______\ \ \__\ \ \_____\ \ \__\ \ \_______\ \ \_\ \ \______\ \ \__\
## hh hh ## \|_______| \|__| \|_______| \|__| \|_______| \|__| \|_______| \|__|
## MMMMMMMMMMMMMMMMMMMM ##
##MMMMMMMMMMMMMMMMMMMMMM## Bilibili Tool 1.0.1. Designed by wzwWhitecat.
\/ \/
'''
# BV号转AV号
def bv_to_av(bv):
bv_data = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M",
"N",
"P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j",
"k",
"m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"]
data = [13, 12, 46, 31, 43, 18, 40, 28, 5, 54, 20, 15, 8, 39, 57, 45, 36, 38, 51, 42, 49, 52, 53, 7, 4, 9, 50, 10,
44, 34, 6, 25, 1, 26, 29, 56, 3, 24, 0, 47, 27, 22, 41, 16, 11, 37, 2, 35, 21, 17, 33, 30, 48, 23, 55, 32,
14, 19]
num0 = [6, 2, 4, 8, 5, 9, 3, 7, 1, 0]
num1 = 100618342136696320
num2 = 177451812
bv_new = []
for i in bv:
bv_new.append(i)
del bv_new[0]
del bv_new[0]
for i in range(len(bv_new)):
for n in range(len(bv_data)):
if bv_new[i] == bv_data[n]:
bv_new[i] = data[n]
data_sum = 0
for i in range(len(bv_new)):
bv_new[i] = bv_new[i] * (58 ** num0[i])
data_sum = data_sum + bv_new[i]
av_result = (data_sum - num1) ^ num2
return av_result
# 视频爬取按键控制
def searchav(var):
global aid
t31.delete('1.0', 'end')
t32.delete('1.0', 'end')
t33.delete('1.0', 'end')
id = entry3.get()
if var.get() == 1:
aid = id
elif var.get() == 2:
aid = bv_to_av(id)
main_message(aid)
find_danmu(aid)
find_pinglun(aid)
# 爬取视频主要信息
def main_message(aid):
global response3, barrages, barrages_2
url = 'http://api.bilibili.com/archive_stat/stat?aid=' + str(aid) + '&type=jsonp'
url2 = 'https://api.bilibili.com/x/web-interface/archive/desc?&aid=' + str(aid)
url3 = 'https://www.bilibili.com/video/av' + str(aid)
headers = {"user-agent": "Mozilla/5.0"}
response1 = requests.get(url, headers=headers).text
response2 = requests.get(url2, headers=headers).text
barrages = json.loads(response1)
barrages_2 = json.loads(response2)
try:
response3 = requests.get(url3, headers=headers).text
text = r'<title data-vue-meta="true">(.*?)</title>'
text0 = r'<meta data-vue-meta="true" itemprop="author" name="author" content="(.*?)">'
text1 = re.findall(text, response3)
text2 = re.findall(text0, response3)
t31.insert("end", " 标题:" + text1[0] + "\n" + " up:" + text2[0] + "\n")
except:
try:
url4 = 'https://search.bilibili.com/all?keyword=' + str(aid)
response4 = requests.get(url4, headers=headers).text
text11 = r'title="(.*?)"'
text3 = re.findall(text11, response4)
t31.insert("end", " 标题:" + text3[0] + "\n")
except:
t31.insert('end', "Error!\n")
t31.insert("end", " av号:av" + str(aid) + "\n" + " 观看:" + str(barrages['data']['view']) + " 弹幕:" + str(
barrages['data']['danmaku']) + " 评论:" +
str(barrages['data']['reply']) + " 点赞:" + str(barrages['data']['like']) + " 投币:" + str(
barrages['data']['coin']) + " 收藏:" +
str(barrages['data']['favorite']) + " 分享:" + str(barrages['data']['share']) + "\n")
t31.insert("end", " 视频简介:" + barrages_2['data'] + "\n")
# 爬取视频弹幕
def find_danmu(aid):
barrages_cs.clear()
global barrages
headers = {"user-agent": "Mozilla/5.0"}
url = f"https://api.bilibili.com/x/player/pagelist?aid={aid}&jsonp=jsonp"
response = requests.get(url, headers=headers).text
cid_dict_list = json.loads(response)["data"]
# print(cid_dict_list)
# print(len(cid_dict_list))
for cid in cid_dict_list:
cid = cid["cid"]
url = f"https://api.bilibili.com/x/v1/dm/list.so?oid={cid}"
print(url)
try:
barrages_xml = requests.get(url, headers=headers).content.decode("utf-8")
barrages_json = xmltodict.parse(barrages_xml)
barrages_str = json.dumps(barrages_json)
barrages = json.loads(barrages_str).get("i").get("d")
except requests.HTTPError as e:
t32.insert('end', e)
except requests.RequestException as e:
t32.insert('end', e)
except:
t32.insert('end', "Unknown Error!")
for barrage in barrages:
if "#text" in barrage:
barrage = str(barrage["#text"]) + ","
# t32.insert('end', barrage+"\n")
barrages_cs.append(barrage)
for i in range(len(barrages_cs)):
t32.insert('end', str(i + 1) + "." + barrages_cs[i] + "\n")
t32.insert('end', "总共" + str(len(barrages_cs)) + "条\n")
# 爬取视频评论
def find_pinglun(aid):
commentlist.clear()
global barrages
hlist = []
hlist.append("UUID")
hlist.append("名字")
hlist.append("性别")
hlist.append("时间")
hlist.append("评论")
hlist.append("点赞数")
hlist.append("回复数")
commentlist.append(hlist)
for n in range(20):
page = str(n + 1)
headers = {"user-agent": "Mozilla/5.0"}
url = f"http://api.bilibili.com/x/v2/reply?jsonp=jsonp&;pn={page}&type=1&oid={aid}"
try:
response = requests.get(url, headers=headers).text
barrages = json.loads(response)
for i in range(20):
comment = barrages['data']['replies'][i]
blist = []
mid = comment['member']['mid']
username = comment['member']['uname']
sex = comment['member']['sex']
ctime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(comment['ctime']))
content = comment['content']['message']
likes = comment['like']
rcounts = comment['rcount']
signature = comment['member']['sign']
level = comment['member']['level_info']['current_level']
blist.append(mid)
blist.append(username)
blist.append(sex)
blist.append(ctime)
blist.append(content)
blist.append(likes)
blist.append(rcounts)
blist.append(signature)
blist.append(level)
commentlist.append(blist)
except requests.HTTPError as e:
t33.insert('end', e)
except requests.RequestException as e:
t33.insert('end', e)
except IndexError:
t33.insert('end', "第" + str(n + 1) + "页" + "IndexError\n")
except:
t33.insert('end', "第" + str(n + 1) + "页" + "Unknown Error!\n")
for i in range(len(commentlist)):
t33.insert('end',
str(commentlist[i][3]) + "\n客户端:" + str(commentlist[i][1]) + "\n评论:" + str(commentlist[i][4]) + "\n")
# 爬取up主按键控制
def searchup():
t41.delete('1.0', 'end')
t43.delete('1.0', 'end')
uid = entry4.get()
up_message(uid)
find_up_video(uid)
# 爬取Up主信息
def up_message(uid):
url = f'https://api.bilibili.com/x/relation/stat?vmid={uid}&jsonp=jsonp'
url2 = f'https://api.bilibili.com/x/space/upstat?mid={uid}'
url3 = f'https://space.bilibili.com/{uid}'
text0 = r'<title>(.*?)的个人空间 - 哔哩哔哩 [(] ゜- ゜[)]つロ 乾杯~ Bilibili</title>'
text1 = r'<meta name="description" content="(.*?)bilibili是国内知名的视频弹幕网站,这里有最及时的动漫新番,最棒的ACG氛围,最有创意的Up主。大家可以在这里找到许多欢乐。"/>'
headers = {"user-agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers).text
response2 = requests.get(url2, headers=headers).text
response3 = requests.get(url3, headers=headers).text
up_message_barrages1 = json.loads(response).get("data")
up_message_barrages2 = json.loads(response2)
up_uid = str(up_message_barrages1["mid"])
up_following = str(up_message_barrages1["following"])
up_watchv = str(up_message_barrages2['data']['archive']['view'])
up_watcha = str(up_message_barrages2["data"]["article"]["view"])
up_likes = str(up_message_barrages2["data"]["likes"])
up_follower = str(up_message_barrages1["follower"])
up_name = re.findall(text0, response3)
up_main = re.findall(text1, response3)
t41.insert("end", "up:" + up_name[
0] + "\nuid:" + up_uid + "\n关注数:" + up_following + " 视频总播放量:" + up_watchv + " 文章总观看量:" + up_watcha + " 总点赞数:" + up_likes + " 粉丝数:" + up_follower + "\n简介:" +
up_main[0])
# 爬取up主投稿视频列表
def find_up_video(uid):
videolist.clear()
hlist = []
hlist.append("av号")
hlist.append("视频标题")
hlist.append("作者")
hlist.append("作者UUID")
hlist.append("发布时间")
hlist.append("视频长度")
hlist.append("收藏数")
hlist.append("评论数")
hlist.append("弹幕数")
hlist.append("播放量")
hlist.append("视频简介")
videolist.append(hlist)
for n in range(20):
page = str(n + 1)
headers = {"user-agent": "Mozilla/5.0"}
url = 'http://space.bilibili.com/ajax/member/getSubmitVideos?mid=' + uid + '&pagesize=20&page=' + page + '&jsonp=jsonp'
try:
response = requests.get(url, headers=headers).text
barrages = json.loads(response)
v_message = barrages['data']['vlist']
for i in v_message:
blist = []
aid = i['aid']
v_tiltle = i['title']
v_author = i['author']
mid = i['mid']
v_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(i['created']))
v_length = i['length']
v_favorites = i['favorites']
v_comment = i['comment']
video_review = i['video_review']
v_play = i['play']
v_description = i['description']
blist.append(aid)
blist.append(v_tiltle)
blist.append(v_author)
blist.append(mid)
blist.append(v_time)
blist.append(v_length)
blist.append(v_favorites)
blist.append(v_comment)
blist.append(video_review)
blist.append(v_play)
blist.append(v_description)
videolist.append(blist)
except requests.HTTPError as e:
t43.insert('end', e)
except requests.RequestException as e:
t43.insert('end', e)
except IndexError:
t43.insert('end', "第" + str(n + 1) + "页" + "IndexError\n")
except:
t43.insert('end', "第" + str(n + 1) + "页" + "Unknown Error!\n")
for i in range(len(videolist)):
t43.insert("end",
"\n" + str(i + 1) + ".av" + str(videolist[i + 1][0]) + "\n标题:" + videolist[i + 1][1] + "\nup主:" +
videolist[i + 1][2] + " UUID:" + str(videolist[i + 1][3]) + "\n" +
str(videolist[i + 1][4]) + " 时长:" + str(videolist[i + 1][5]) + " 播放:" + str(
videolist[i + 1][9]) + " 弹幕:" + str(videolist[i + 1][8]) +
" 评论:" + str(videolist[i + 1][7]) + " 收藏:" + str(videolist[i + 1][6]) + "\n视频简介:" +
videolist[i + 1][10])
# 保存信息按键控制
def save_data(n):
if n == 1:
id = entry3.get()
for i in range(len(barrages_cs)):
b = open(str(id) + "的弹幕.txt", "a", newline="\n", encoding="utf-8")
b.write(str(i + 1) + "." + barrages_cs[i] + "\n")
b.close()
tkinter.messagebox.showinfo(title='Success', message='保存弹幕成功!')
if n == 2:
id = entry3.get()
work_book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = work_book.add_sheet(str(id) + '的评论', cell_overwrite_ok=True)
for i in range(len(commentlist)):
for m in range(len(commentlist[i])):
sheet.write(i, m, commentlist[i][m])
work_book.save(str(id) + '的评论.xls')
tkinter.messagebox.showinfo(title='Success', message='保存评论成功!')
if n == 3:
id = entry4.get()
work_book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = work_book.add_sheet('UUID' + str(id) + '的视频列表', cell_overwrite_ok=True)
for i in range(len(videolist)):
for m in range(len(videolist[i])):
sheet.write(i, m, videolist[i][m])
work_book.save('UUID' + str(id) + '的视频列表.xls')
tkinter.messagebox.showinfo(title='Success', message='保存视频列表成功!')
# 窗口页面跳转控制
def changetab(a):
fr3.pack_forget()
fr4.pack_forget()
if a == 3:
fr3.pack()
if a == 4:
fr4.pack()
def loading():
tkinter.messagebox.showinfo(title='Thanks', message='更多功能敬请期待!')
# 窗口设计
print(a)
win = tk.Tk()
win.title("bilibili")
menubar = tk.Menu(win)
moremenu = tk.Menu(menubar, tearoff=0)
menubar.add_command(label='视频检索', command=lambda: changetab(3))
menubar.add_command(label='up检索', command=lambda: changetab(4))
menubar.add_cascade(label='更多', menu=moremenu)
moremenu.add_cascade(label='高级功能', command=lambda: loading())
moremenu.add_separator()
moremenu.add_command(label='退出', command=win.quit)
win.config(menu=menubar)
fr3 = ttk.Frame(win)
fr3.pack()
l31 = ttk.Label(fr3, text='请输入av号/Bv号:')
l31.grid(column=0, row=0)
entry3 = ttk.Entry(fr3, justify="left", font=1, width=20)
entry3.grid(row=0, column=1, columnspan=6)
b3_search = ttk.Button(fr3, text='搜索', command=lambda: searchav(var3))
b3_search.grid(row=0, column=7)
var3 = tk.IntVar()
var3.set(1)
r31 = ttk.Radiobutton(fr3, text='av号', variable=var3, value=1, command=0)
r31.grid(row=1, column=2)
r32 = ttk.Radiobutton(fr3, text='Bv号', variable=var3, value=2, command=0)
r32.grid(row=1, column=5)
l32 = ttk.Label(fr3, text='基本信息')
l32.grid(row=2, column=0, columnspan=8)
t31 = tks.ScrolledText(fr3, height=5, width=50)
t31.grid(row=3, column=0, columnspan=8, padx=10, pady=5)
l32 = ttk.Label(fr3, text='弹幕列表')
l32.grid(row=4, column=0, columnspan=4)
l32 = ttk.Label(fr3, text='视频评论')
l32.grid(row=4, column=5, columnspan=4)
t32 = tks.ScrolledText(fr3, height=20, width=25)
t32.grid(row=5, column=0, columnspan=4, padx=5, pady=5)
t33 = tks.ScrolledText(fr3, height=20, width=25)
t33.grid(row=5, column=5, columnspan=4, padx=5, pady=5)
b31 = ttk.Button(fr3, text='保存弹幕', command=lambda: save_data(1))
b31.grid(row=6, column=0, columnspan=4)
b31 = ttk.Button(fr3, text='保存评论', command=lambda: save_data(2))
b31.grid(row=6, column=5, columnspan=4)
commentlist = []
barrages_cs = []
fr4 = ttk.Frame(win)
l41 = ttk.Label(fr4, text='请输入up的uid:')
l41.grid(column=0, row=0)
entry4 = ttk.Entry(fr4, justify="left", font=1, width=20)
entry4.grid(row=0, column=1, columnspan=6)
b4_search = ttk.Button(fr4, text='搜索', command=lambda: searchup())
b4_search.grid(row=0, column=7)
l42 = ttk.Label(fr4, text='基本信息')
l42.grid(row=2, column=0, columnspan=8)
t41 = tks.ScrolledText(fr4, height=5, width=50)
t41.grid(row=3, column=0, columnspan=8, rowspan=2)
l44 = ttk.Label(fr4, text='视频列表')
l44.grid(row=5, column=0, columnspan=8)
t43 = tks.ScrolledText(fr4, height=20, width=50)
t43.grid(row=6, column=0, columnspan=8)
b41 = ttk.Button(fr4, text='保存列表', command=lambda: save_data(3))
b41.grid(row=7, column=0, columnspan=8)
videolist = []
win.mainloop()
代码链接https://gitee.com/python_programming/wzw20191318/blob/52f1a8f173e2941863684b9466746e2445a74226/小爬虫gui.py
3. 实验过程中遇到的问题和解决过程
- 网络上提供的B站api接口都是以AV号为基础,但在三月份时B站将AV号升级为了BV号
解决方法:通过查询网络得知AV号与BV号之间的转换其实是一个base58编码的魔改,于是根据其转换原理编写了从BV号转为AV号的程序。
def bv_to_av(bv):
bv_data = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M",
"N",
"P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j",
"k",
"m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"]
data = [13, 12, 46, 31, 43, 18, 40, 28, 5, 54, 20, 15, 8, 39, 57, 45, 36, 38, 51, 42, 49, 52, 53, 7, 4, 9, 50, 10,
44, 34, 6, 25, 1, 26, 29, 56, 3, 24, 0, 47, 27, 22, 41, 16, 11, 37, 2, 35, 21, 17, 33, 30, 48, 23, 55, 32,
14, 19]
num0 = [6, 2, 4, 8, 5, 9, 3, 7, 1, 0]
num1 = 100618342136696320
num2 = 177451812
bv_new = []
for i in bv:
bv_new.append(i)
del bv_new[0]
del bv_new[0]
for i in range(len(bv_new)):
for n in range(len(bv_data)):
if bv_new[i] == bv_data[n]:
bv_new[i] = data[n]
data_sum = 0
for i in range(len(bv_new)):
bv_new[i] = bv_new[i] * (58 ** num0[i])
data_sum = data_sum + bv_new[i]
av_result = (data_sum - num1) ^ num2
return av_result
4. 思考和感悟
- 经过一学期的Python程序设计课程学习,我对Python这门语言有了一个较为深刻的理解,对我运用编程解决问题的能力有了很大的提升。
参考资料
标签:barrages,Python,up,bv,20191318,str,实验报告,data,append 来源: https://www.cnblogs.com/wzwyoshino/p/13088784.html