colab-tf2.x炼丹小技巧&bug锦集
作者:互联网
2020-07-23
bug1:Calling read(nbytes) on source failed. Try engine='python'
今天在用colab的时候跳出来一个


意思大概就是我的colab没问题,但是他连不上我放在Google drive里面的文件了(其实就是数据集鸭,,毕竟 代码我们都是直接写在colab里面的)。。
然后在处理数据集的时候就会报错:
然后在处理数据集的时候就会报错tes) on source failed. Try engine='python'其实我们需要的也仅仅是GPU,所以,解决方法就是:
直接把我们的数据集上传到colab里面就可以用了(像这样):
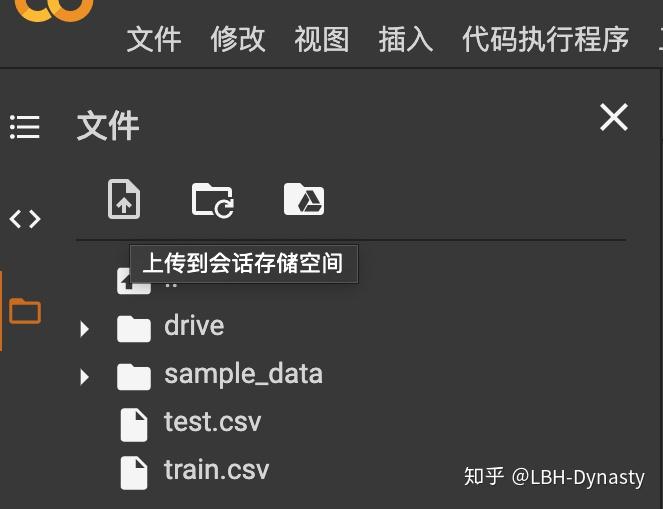
然后直接把地址改成文件名就行了(毕竟已经在同一个目录下啦)
df= pd.read_csv('train.csv') 2020-07-24
薅羊毛也有技巧,colab会随机为免费用户提供4个炼丹炉,其中T4和Tesla-P100的算力最强。可以通过下面这个命令查询自己是哪个炼丹炉
!nvidia-smi比如我现在用的就是:
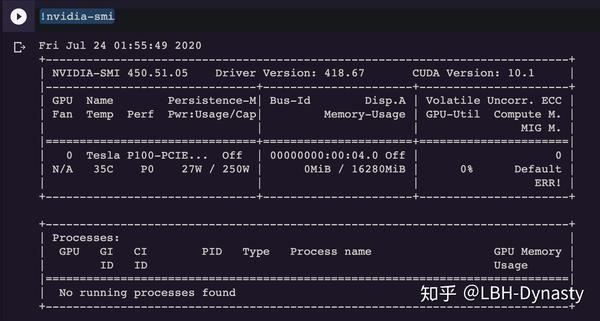
如果运算量很大而且随机到的炼丹炉很差的话,建议直接停掉,重新连接重新随机炼丹炉。
比如我现在这个数据集有12000条数据,昨天随机到一个先对来说很差的,跑一个epoch需要2580+s(忘记存图了)
今天用这个P100跑,就只要1300+s


一倍的时间差距
(另外我看到一个算力比较的 P100似乎比colab提供最次的K80计算速度快6.5倍)
晚上又遇到好多个bug:
”您的会话因占满了所有可用 RAM 而导致崩溃。 查看运行时日志“
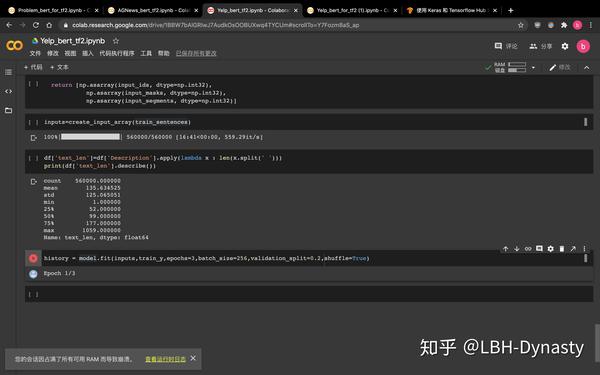
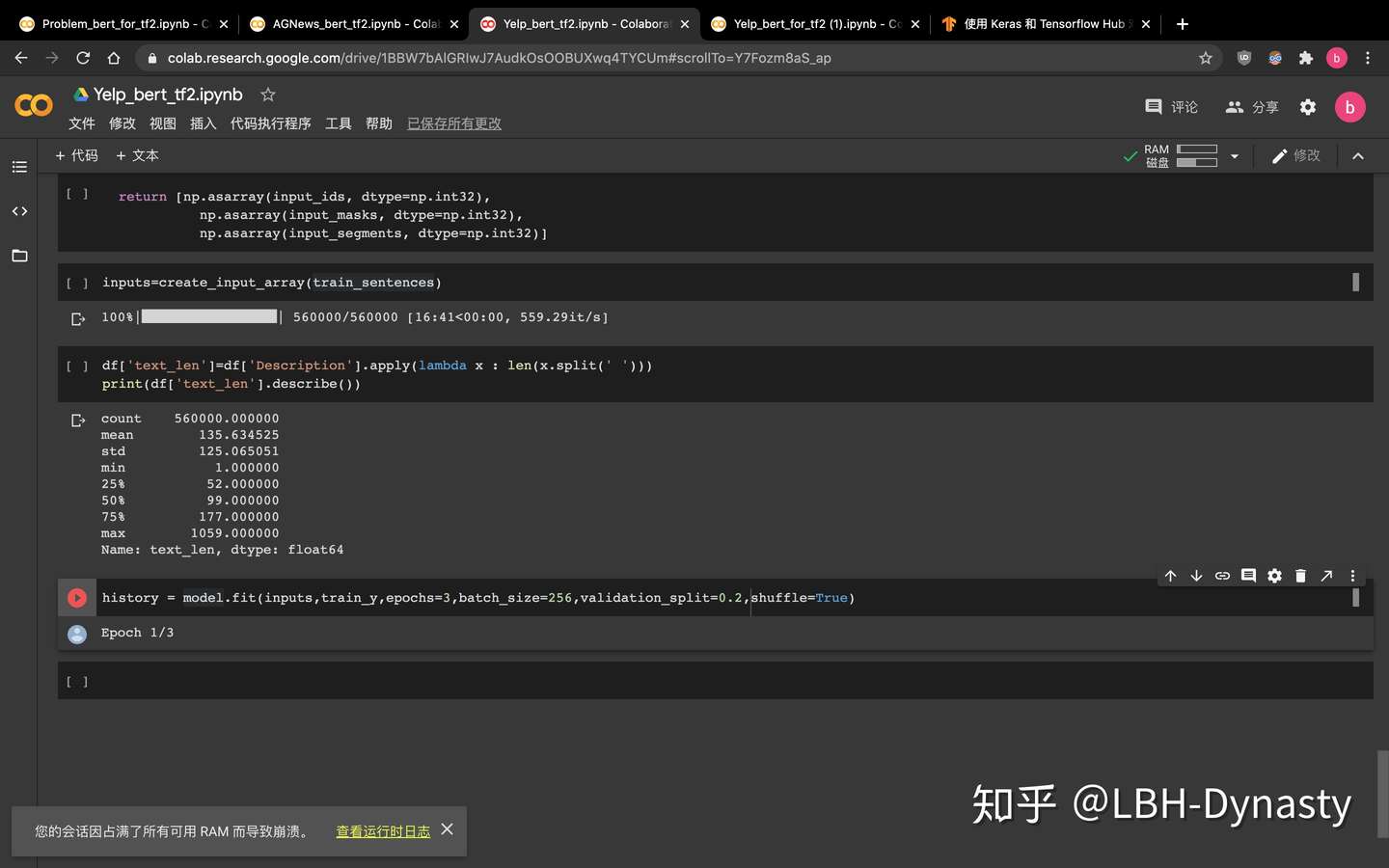
左下角这个。。。就是我把colab的GPU的显存用光了。。
解决方法:把batch_size缩小(卑微的已经缩小到32了)
tips:查看当前句子的长度(没有分词之前,唔至少可以提供一下最小长度参考吧,特别是英语文本)(可以作为batch_size参考,唔,,前提是你的显存够大,哈哈哈哈哈哈哈哈哈嗝)
df['text_len']=df['Description'].apply(lambda x : len(x.split(' ')))
print(df['text_len'].describe())下面是常用的绘制图像的套路:
#导入包
import matplotlib.pyplot as plt
import numpy as np
#创建数据
x = np.linspace(-5, 5, 100)
y1 = np.sin(x)
y2 = np.cos(x)
#创建figure窗口
plt.figure(num=3, figsize=(8, 5))
#画曲线1
plt.plot(x, y1)
#画曲线2
plt.plot(x, y2, color='blue', linewidth=5.0, linestyle='--')
#设置坐标轴范围
plt.xlim((-5, 5))
plt.ylim((-2, 2))
#设置坐标轴名称
plt.xlabel('Iteration')
plt.ylabel('Accuracy')
#设置坐标轴刻度
my_x_ticks = np.arange(-5, 5, 0.5)
my_y_ticks = np.arange(-2, 2, 0.3)
plt.xticks(my_x_ticks)
plt.yticks(my_y_ticks)
#显示出所有设置
plt.show()2020-07-29
当我们要比较两个算法在同一个数据集上的效果的时候,我们就可能需要把第一个训练好的模型先存起来:
https://www.tensorflow.org/api_docs/python/tf/saved_model/savewww.tensorflow.org就用
tf.saved_model.save(
obj, export_dir, signatures=None, options=None
)这个函数就可以了
2020-07-30
在做embedding的时候:
trunc_type="post" #表示超过maxlen的部分 选择后面多的截断
转载 https://zhuanlan.zhihu.com/p/163222953
标签:plt,07,ticks,2020,colab,锦集,np,bug 来源: https://www.cnblogs.com/gaodi2345/p/14825593.html