R语言Logistic回归模型深度验证以及Nomogram绘制
作者:互联网
R语言Logistic回归模型深度验证以及Nomogram绘制
01 研究背景
本章将常用的基于R语言实现二元Logistic回归模型临床预测模型的构建和验证,以及诺曼图的绘制记录下来,更为复杂的生存分析中的Cox回归将在后续章节介绍。临床预测模型的思路总结如下:①明确临床问题,确定科学假设。②查找文献,确定预测模型的研究思路。③确定模型中结局变量。④确定模型中的预测因子。⑤构建模型,计算模型预测值。⑥模型区分度评估。⑦模型校准度评估。⑧临床实用型DCA评估。
02 案例研究
本文采用的数据是上海交大出版<医学统计学及SAS应用>第十一章数据。预测因子有性别、年龄和高血压等级,结局变量为是否患病。本文研究目的探讨患病的危险因素构建并验证模型。因数据量少且只有一个数据集,故只用此数据集建模,并验证,若有更多外部数据,最好拿外部数据来验证模型。
临床研究一般有提供多个危险因素,首先做单因素的筛选,具体筛选方法,见公众号之前的文章。筛选完的危险因素用来构建预测模型。
具体分析步骤是,①基于这些变量构建模型。②绘制Nomogram图。③计算模型ROC曲线面积(区分度)和绘制校准曲线并检验(校准度,U检验),该步骤用神包rms一步实现。接下来直接上代码。
03 R代码及解读
library(rms) ###加载rms包#
##建立数据集
y <- c(0,1,0,0,0,1,1,1,0,0,0,1,1,0,0,1,0,0,0,1,1,0,1,
1,0,1,1,1,0,1,0,1,0,0,1,1,0,0,1,1,0,1,0,0,0,1,
1,1,1,0,1,1,0,0,0,1,1,1,0,1,1,1,1,0,0,1,1,1,0,
0,0,1,0,1,0,1,0,1)
age <- c(28,42,46,45,34,44,48,45,38,45,49,45,41,46,49,46,44,48,
52,48,45,50,53,57,46,52,54,57,47,52,55,59,50,54,57,60,
51,55,46,63,51,59,48,35,53,59,57,37,55,32,60,43,59,37,
30,47,60,38,34,48,32,38,36,49,33,42,38,58,35,43,39,59,
39,43,42,60,40,44)
sex <- c(0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,
0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,
0,1,0,1,0,1,1,1,0,1,1,1,0,1,1,1,0,1,1,1,0,1,1,1,
0,1,1,1,0,1)
ECG <- c(0,0,1,1,0,0,1,1,0,0,1,1,0,0,1,1,0,0,1,1,0,0,1,1,
0,0,1,1,0,0,1,1,0,0,1,1,0,0,2,1,0,0,2,2,0,0,2,2,
0,1,2,2,0,1,0,2,0,1,0,2,1,1,0,2,1,1,0,2,1,1,0,2,
1,1,0,2,1,1)
dt <- data.frame(y,age,sex,ECG) ##把数据集设置成数据框结构str(dt) ##查看每个变量结构
'data.frame': 78 obs. of 4 variables:
$ y : num 0 1 0 0 0 1 1 1 0 0 ...
$ age: num 28 42 46 45 34 44 48 45 38 45 ...
$ sex: num 0 1 0 1 0 1 0 1 0 1 ...
$ ECG: num 0 0 1 1 0 0 1 1 0 0 ...
head(dt) ##查看数据框前几行
y age sex ECG
1 0 28 0 0
2 1 42 1 0
3 0 46 0 1
4 0 45 1 1第一步,构建模型。
#设定环境参数#
ddist <- datadist(dt)
options(datadist='ddist')
###logistic
f <- lrm(dt$y~.,data=dt) ##注意此处使用lrm()函数构建二元LR
summary(f) ##也能用此函数看具体模型情况,模型的系数,置信区间等第二步:绘制nomogram图,注意该函数里面的参数设置。
### nomogram
par(mgp=c(1.6,0.6,0),mar=c(2,2,2,2)) ##设置画布
nomogram <- nomogram(f,fun=function(x)1/(1+exp(-x)), ##逻辑回归计算公式
fun.at = c(0.001,0.01,0.05,seq(0.1,0.9,by=0.1),0.95,0.99,0.999),#风险轴刻度
funlabel = "Risk of Death", #风险轴便签
lp=F, ##是否显示系数轴
conf.int = F, ##每个得分的置信度区间,用横线表示,横线越长置信度越
abbrev = F#是否用简称代表因子变量
)
plot(nomogram)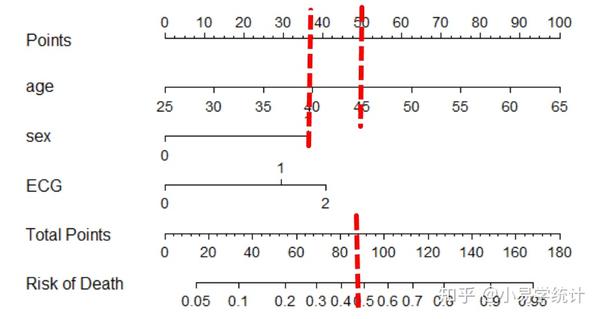
该图的使用,本质上这是将逻辑回归模型可视化展示,方便临床快速判断。假设有个病人年龄45岁,性别为男,高血压正常,Nomogram用法是在age变量上找到其值为45的刻度,然后画垂线投影到最上方的points刻度尺上,找到找到对应的分值为50分,同理找到sex为1的分值约为37分,ECG为0对应分值为0,将这三个因素的points值加起来总分87。下一步在下面的Total Points刻度尺上找到87,向下方的Risk of Death做垂线,87对应的值在0.4和0.5之间,约为0.48,说明该患者患病风险预测概率值为48%。
重头戏来了,第三步:利用rms包对该模型进行验证。
##模型验证
##以原数据集为验证集
f.glm <- glm(y~.,data=dt,family = binomial(link = "logit"))
P1 <- predict(f.glm,type = 'response') ##获得预测概率值
##关键的一步来了。
val.prob(P1,y) ##这个函数前面放概率值,后面芳结局变量
Dxy C (ROC) R2 D
5.675676e-01 7.837838e-01 3.164825e-01 2.578779e-01
D:Chi-sq D:p U U:Chi-sq
2.111448e+01 NA -2.564103e-02 -3.552714e-13
U:p Q Brier Intercept
1.000000e+00 2.835189e-01 1.885480e-01 -4.335689e-09
Slope Emax E90 Eavg
9.999998e-01 1.157412e-01 6.085456e-02 3.492462e-02
S:z S:p
-2.762507e-03 9.977958e-01 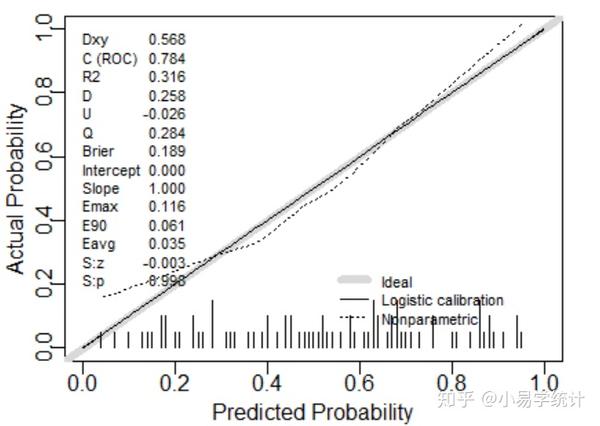
该函数可以一次性得到模型验证的多个指标和P值,并绘制出校准曲线,功能很强大了。
首先看代码中返回的结果,Emax是模型与理想模型的最大偏移量,Eavg是模型与理想模型的最小偏移量,这两个值越小越好,越小则说明模型与理想模型越接近。U是指Unreliability test 即U检验,用来判断构建的模型是否能通过校准度检验,其对应的P值在最下面,S:p,当S:p>0.05说明通过校准度检验。C(ROC)是ROC面积,该面积和C-index指数本质上是一样的,只不过一个对应LR,一个对应COX。
通过R计算的结果可看到,本模型通过校准度检验,p=0.998>0.05,Roc面积为0.784具有良好的区分能力,总体来说,该模型的预测能力是很优秀的~~。
04 总结
本文介绍了Logistic回归模型的深度验证和Nomogram的绘制及应用。需要注意的是:一个预测模型的好坏除了内部验证,还要看外部验证,即它的外推性是否好。本文由于数据量少,也没有获取外部验证集,仅用原始数据集作为训练集和验证集。
05 更多阅读
文章在公粽号:易学统计
文章里的干货更多哟
欢迎交流,欢迎提问
发布于 2020-07-19 逻辑回归 R(编程语言) 验证 赞同 15 4 条评论 分享 喜欢 收藏 申请转载 标签:45,校准,##,Nomogram,模型,验证,Logistic,绘制 来源: https://blog.csdn.net/weixin_43156127/article/details/121182740