杂题选放
作者:互联网
提示:点击解题思路即可展开。
UOJ62「UR #5」怎样跑得更快
题目大意
给定整数 \(n,c,d\) 和个长度为 \(n\) 的数组 \(b[]\),求另一个数组 \(x[]\),对于 \(P=998244353\),满足
\[\sum_{j=1}^n\gcd(i,j)^c\times lcm(i,j)^d\times x_j=b_i \pmod P \]数据范围
\[1 \le n \le 10^5 \] 解题思路
先说题解给出的解法,首先一步转化
\[\sum_{j=1}^n\gcd(i,j)^{c-d}\times \frac{x_j}{j^d}=\frac{b_i}{i^d} \pmod P\\ \sum_{j=1}^n\gcd(i,j)^{c-d} X_j=B_i \pmod P\\ \]第一波直接设 \(f(n)=\sum_{d|n}f_r(d)\) 这样 \(f_r(n)=f(n)-\sum_{d|n\and d \neq n}f_r(d)\) 是可以 \(\Theta(n\log n)\) 求的。然后推一波式。
\[\sum_{j=1}^nf(\gcd(i,j))X_j=B_i\\ \sum_{j=1}^n\sum_{d|i,d|j}f_r(d)X_j=B_i\\ \sum_{d|i}f_r(d)\sum_{j=kd}X_j=B_i\\ \sum_{d|i}f_r(d)S(d)=B_i\\ \]可以算得 \(f_r(n)S(n)=B_n-\sum_{d|n\and d \neq n}{f_r(d)S(d)}\)
因为 \(f_r(n)\) 有可能等于 0,这时候判一下无解或多解,这样我们就把 \(S(n)\) 全算出来了。
然后考虑解出 \(X_j\),有 \(S(d)=\sum_{i=kd}^{n}X_i\),所以 \(X_d=S(d)-\sum_{i=(k+1)d}^{n}X_i\)
然后就做完啦,容易发现这里一共用了三次莫比乌斯反演!
CF232C Doe Graphs
题目大意
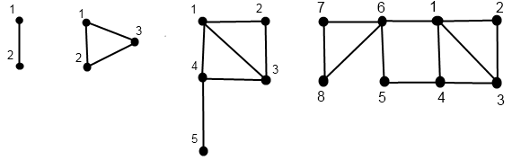
递归的定义一个 \(n\) 阶无向图 \(D(n)\),边权均为 1
- \(D(0)\) 由节点 1 构成
- \(D(1)\) 由节点 1, 2 和边 (1, 2) 构成
- \(D(n)\) 以如下方式构造
- 将 \(D(n-2)\) 的中的点编号都加上 \(|D(n-1)|\)
- 在点 \(|D(n-1)|\) 和点 \(|D(n-1)|+1\) 之间连边。
- 在点 \(|D(n-1)|+1\) 和点 1 之间连边
对于 n 阶无向图 \(D(n)\) 多次询问求出点 \(x, y\) 之间的最短路
数据范围
\[1 \le n, q \le 10^5\\ 1 \le x ,y \le 10^{16} \] 解题思路
情况一:a 在左部图,b 在右部图
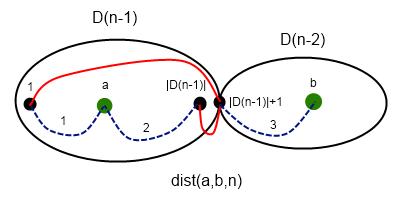
首先观察发现 \(|D(n-1)|+1\) 事这个图的割点,也就是说左边到右边一定要经过这个点,所以递归去做
\[Dis(a,b,n)=\min(Dis(1,a,n-1),Dis(a,|D(n-1)|,n-1))+Dis(1,B-|D(n-1)|,n-2) \]情况二:a,b 均在右部图
容易发现 \(Dis(a,b,n)=Dis(a-|D(n-1)|,b-|D(n-1)|,n-2)\)
情况三:a,b 均在左部图
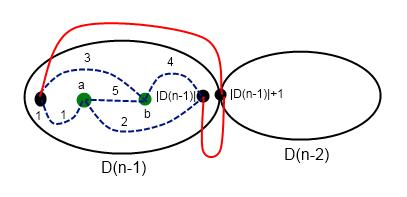
容易发现要么直接从 a 走到 b,否则有可能到 \(|D(n-1)+1|\) 这个点汇集,有
\[Dis(a,b,n)=\min\left\{ \begin{matrix} Dis(a,b,n-1)\\ Dis(1,a,n-1)+Dis(b,|D(n-1)|,n-1)+2\\ Dis(1,b,n-1)+Dis(a,|D(n-1)|,n-1)+2\\ \end{matrix}\right. \]这样就可以递归着做了,然而我们还是发现第三种情况分生出的太多,\(\log\) 的时间内事不行的,但考虑到 n 的大小事 \(\log\) 的,另外算的 \(Dis\) 值大多与 \(1,|D(n)|\) 相关。
所以我们预处理出,\(A1[n] = Dis(1,a,n),A2[n]=Dis(a,|D(n)|,n)\),对于 b 类似,这样就没有那么多分支了。
预处理的过程和上面三种情况一致,注意还要处理 \(g[n] = Dis(1,|D(n)|,n)\),递推式为 \(g[n] = g[n-2]+1\)
CF1310 Au Pont Rouge
题目大意
给出一个长度为 \(n\) 的字符串 \(S\) 以及整数 \(m,k\)。
对于一个把 \(S\) 分割成非空的 \(m\) 段的一个方案,我们用这个方案中分割出的字典序最小的一个串代表这个分割方案。
eg. \(S=abaabb,m=3\),存在分割方案 \(\{ab,aab,b\}\),则我们用字典序最小的 \(aab\) 来代表这个分割方案。
现在把所有分割方案对应的代表该方案的串按字典序从大到小排序,求排序后的第 \(k\) 个串。
数据范围
$ 2 \le n \le 1,000,1 \le m \le 1,000, 1 \le k \le 10^{18} $
解题思路
第 k 大肯定能想到二分,我们把它的所有子串按字典序排序,然后二分第 k 个串是什么,然后 dp \(\Theta(n^2)\) 算出方案数即可。
难点大概在 dp 上,设 \(dp[x][y]\) 表示前 x 个位置,划分了 y 个字典序大于二分串,且第 x 个位置处一定被划分的方案数,容易发现这样事 \(\Theta(n^3)\)的,有没有复杂度更低的方法呢?
考虑倒着 dp,\(dp[x][y]\) 表示考虑了 \(x\text~n\),恰好划分了 m 段的方案数,\(fp[x][y]\) 表示考虑了 \(x\text~ n\),已经划分了 m 段的方案数,设 t 表示 \(s[x\dots t]\) 字典序恰好大于二分串的位置,那么转移为
\[dp[x][y] = d[t][y-1]\\ d[x][y] = dp[x][y]+d[x+1][y] \]是不是非常简单
标签:le,mathbf,选放,sum,像素,杂题,straight,Dis 来源: https://www.cnblogs.com/Hs-black/p/14807086.html