深度学习之模型量化
作者:互联网
深度学习之模型量化
各位小伙伴,大家好。深度学习具体工作你有没有碰到模型占用空间偏大、PC 平台与移植到板子上的运行效率差距偏大,进而无法满足高帧率、实时性的要求?AI 奶油小生也碰到上述问题,以下是小生针对训练后深度学习模型量化的处理理论,详细介绍模型压缩领域中的量化实操,希望对您的有所帮助。
1.1 需求背景
为了满足各种 AI 应用对检测精度的要求,深度神经网络结构的宽度、层数、深度以及各类参数等数量急速上升,导致深度学习模型需要更大的空间需求,更低的推理效率;同时商业对模型应用越来越倾向于从云端部署到边缘侧,受限于边缘侧设备的计算资源,我们不得不考虑设备存储、内存、功耗及时延性等问题,特别是在移动终端和嵌入式设备等应用场景更加需要优化。作为通用的深度学习优化的手段之一,模型量化将深度学习模型量化为更小的定点模型和更快的推理速度,而且几乎不会有精度损失,其适用于绝大数模型和使用场景。
1.2 模型量化可行性
模型量化以损失推理精度为代价,将网络中连续取值或离散取值的浮点型参数( 权重或张量)线性映射为定点近似(int8 / uint8)的离散值,取代原有的 float32 格式数据,同时保持输入输出为浮点型,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。定点量化近似表示如图 1.1 所示。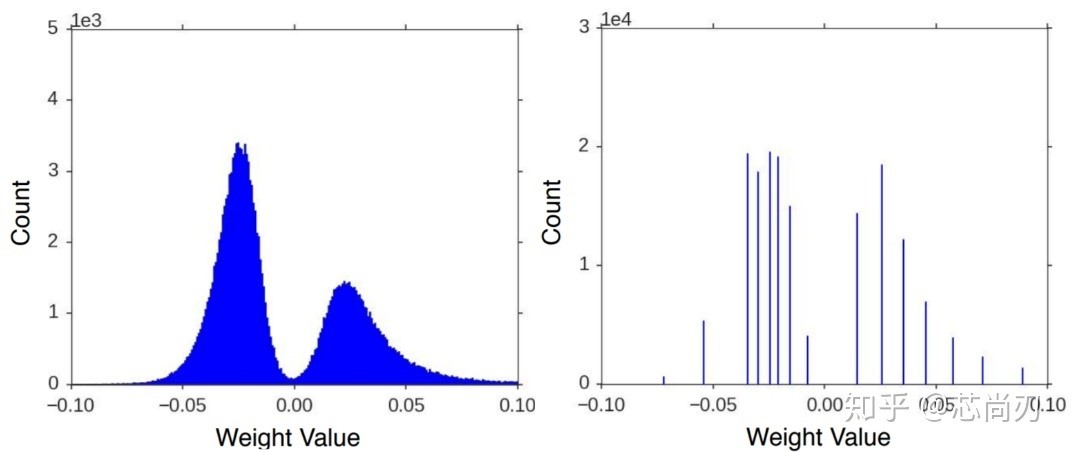
图 1.1 定点量化近似表示
1.3 模型量化原理
模型量化为定点与浮点等数据之间建立一种数据映射关系,详细如下:
R 表示真实的浮点值,Q 表示量化后的定点值,Z 表示0 浮点值对应的量化定点值,S 则为定点量化后可表示的最小刻度。由浮点到定点的量化公式如下: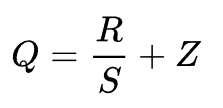
由定点到浮点反量化公式如下: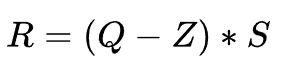
同时,S 和Z 的求值公式如下:
量化后的 Q 还是反推求得的浮点值 R,若它们超出各自可表示的最大范围,则需进行截断处理。
特别说明:一是浮点值 0 在神经网络里有着举足轻重的意义,比如 padding 就是用的 0,因而必须有精确的整型值来对应浮点值 0。二是以往一般使用 uint8 进行定点量化,而目前有提供 float16 和 int8 等定点量化方法,而 int8 定点量化针对不同的数据有不同的范围定义:
1.4 模型量化内部流程
深度模型的前向推导通过量化实现 8-bit 版本运算符(包括卷积、矩阵乘、激活函数、下采样和拼接)运行;同时,量化对象包含实数与矩阵乘法等类型。则以激活函数 Relu 为例,传统、实数量化、矩阵乘法量化等三种前向推导流程如图 1.2 所示。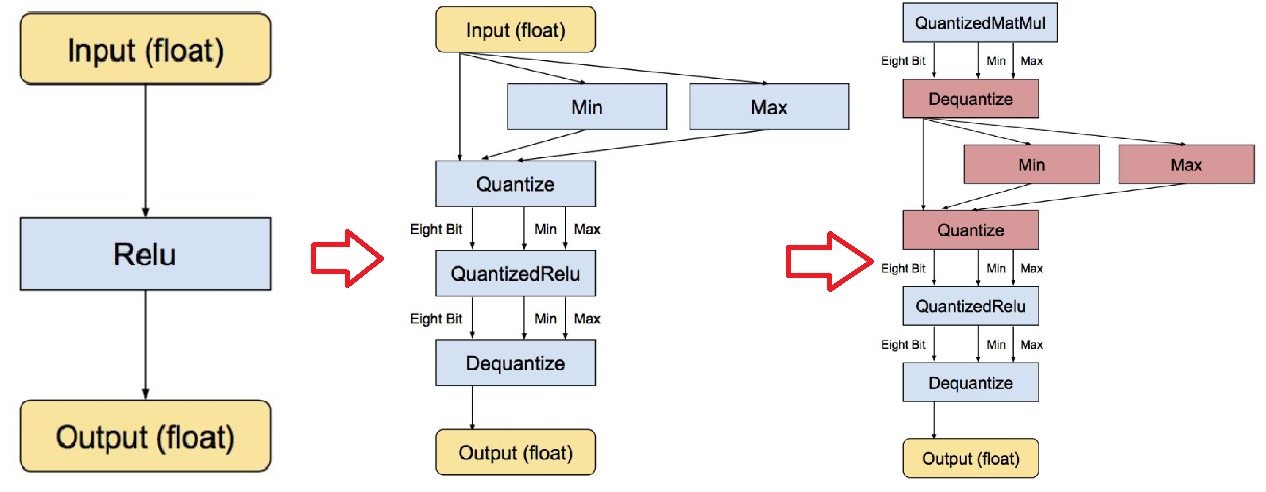
图 1.2 三种量化前向推导流程
- Tensorflow 量化实操
Tensorflow 模型量化分为训练量化、训练时量化。上述两者详细介绍如下:
2.1 训练后量化( post training quantization )
此处处理对象是训练好的模型,借用 tensorflow 量化工具通过压缩权重或量化权重和激活输出等方式缩减模型大小,进而加速预测速度。仅对权重量化即为实数量化,只需将权重精度从浮点型映射为 8 bit 整型,此类型方便传输和存储(本文主要实现模型权重的量化进行实操);量化权重和激活输出即为矩阵乘法量化,除了对大量参数进行量化,也需要标定数据与激活输出的动态范围共同辅助后者的量化。权重量化实操详细如下:
2.1.1 环境配置
量化训练后的模型需借助 bazel 对 Tensorflow 编译和移植。首先,bazel 与 Tensorflow 需要进行版本匹配,部分内容如图 2.1 所示。其次,根据模型训练时使用的 tensorflow 版本(本文使用 tensorflow 1.13.1),下载与之对应的 bazel 安装软件(对应版本为 0.19.2),下载链接为 https://github.com/bazelbuild/bazel/releases,本次下载 bazel-0.19.2-installer-linux-x86_64.sh,如图 2.2 所示。再次,扩展内存,即构建内存交换空间 swap,解决后期物理内存不足问题。本次采用文件构建 swap,如图 2.3 所示。最后,配置与安装 bazel 及其环境,详细内容如下:
************************************ 部分参照 google **********************************************
Step 1: Install the JDK #Install JDK 8:
sudo apt-get install openjdk-8-jdk #On Ubuntu 14.04 LTS you must use a PPA:
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update && sudo apt-get install oracle-java8-installer
Step 2: Add Bazel distribution URI as a package source #Note: This is a one-time setup step.
echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.list
curl https://bazel.build/bazel-release.pub.gpg | sudo apt-key add - #If you want to install the #testing version of Bazel, replace stable with testing.
Step 3: sudo apt update && sudo apt install bazel-0.19.2 # Install and update Bazel
或者 sudo bash bazel-0.19.2-installer-linux-x86_64.sh
Step 4: bazel version #查看 bazel 版本
**************************************** OVER ****************************************************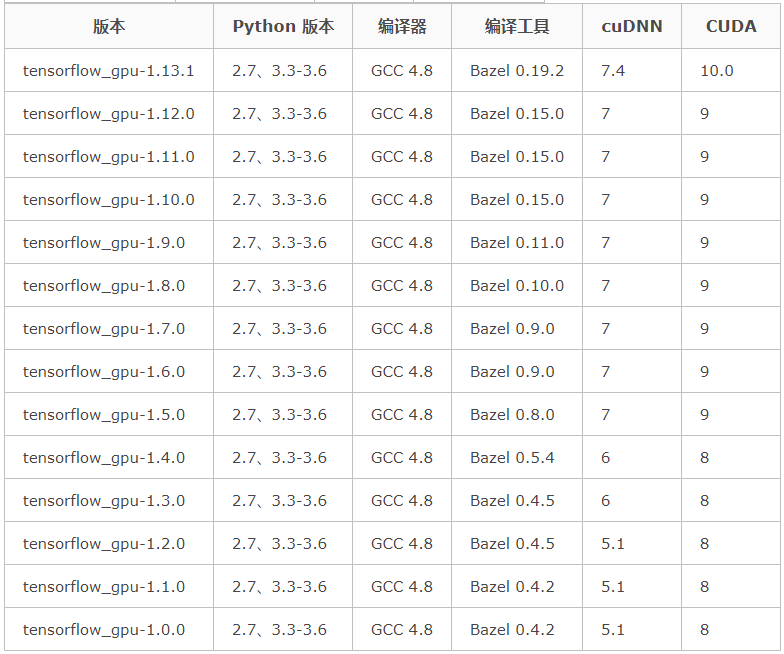
图 2.1 bazel 与 tensorflow 版本列表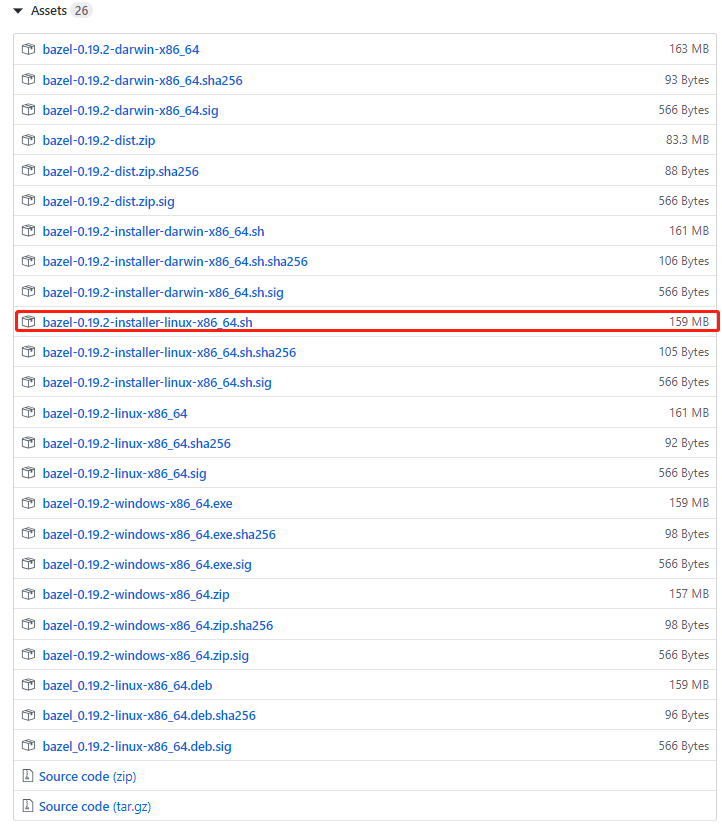
图 2.2 bazel 下载示例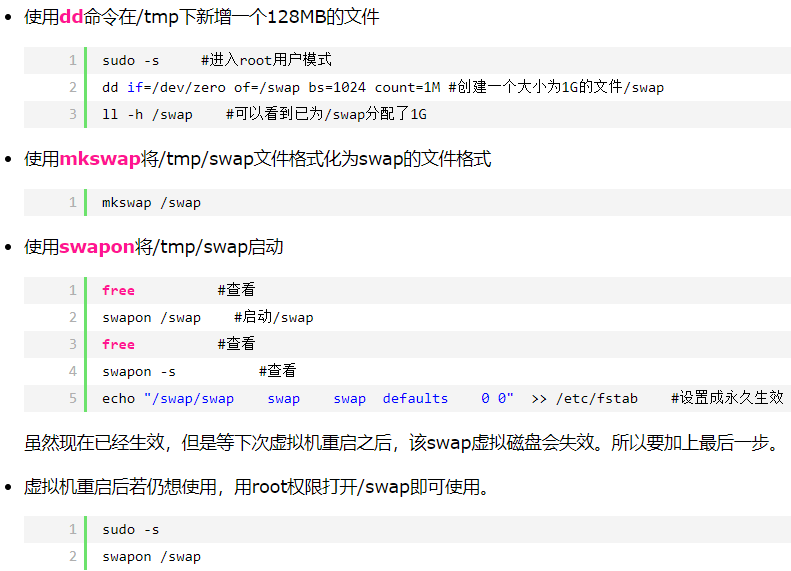
图 2.3 构建 swap 流程
2.1.2 构建与量化
此处分别执行 tensorflow 量化模块的构建、指定模型的量化操作等。首先,在 tensorflow 文件目录下,终端执行命令:bazel build tensorflow/tools/graph_transforms:transform_graph ,执行示例与效果如图 2.4 所示。其次,同一个终端执行模型量化命令如下:
bazel-bin/tensorflow/tools/graph_transforms/transform_graph --in_graph=./tmp/frozen_inference_graph20200315.pb --outputs='output_weights_name' --out_graph=./tmp/quantized_frozen_inference_graphV6.pb --transforms='quantize_weights'
其中,in_graph 为模型及其输入路径,out_graph 为量化模型及其输出路径,transforms 为 模型权重由 32 bit 转化为 8 bit,执行效果如图 2.5 所示:生成的量化模型大小约为原始模型的 32%。
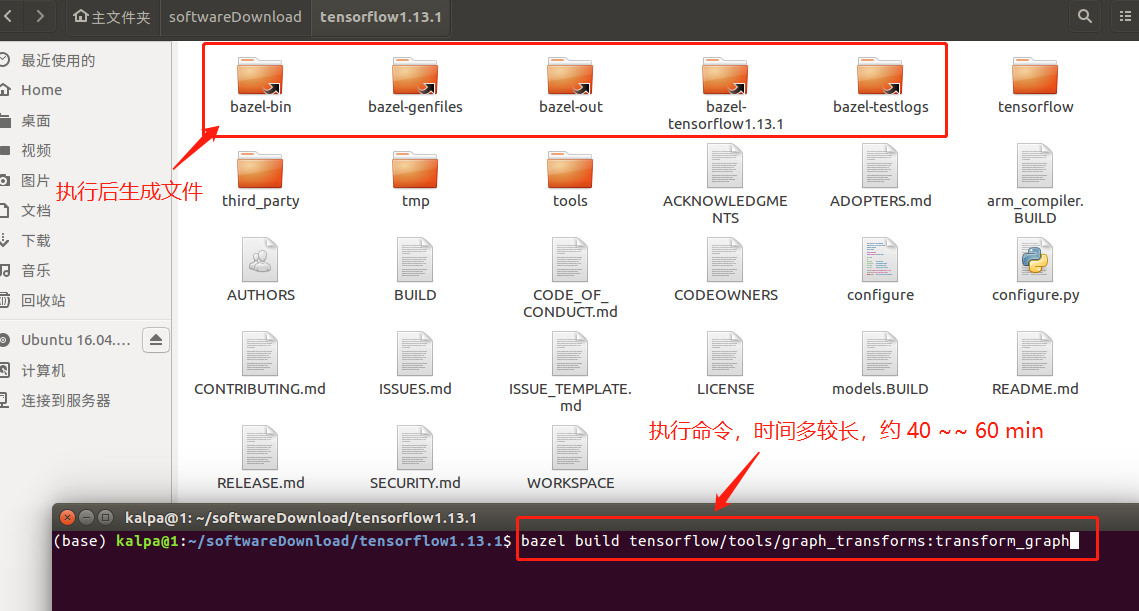
图 2.4 编译 tensorflow 与效果示例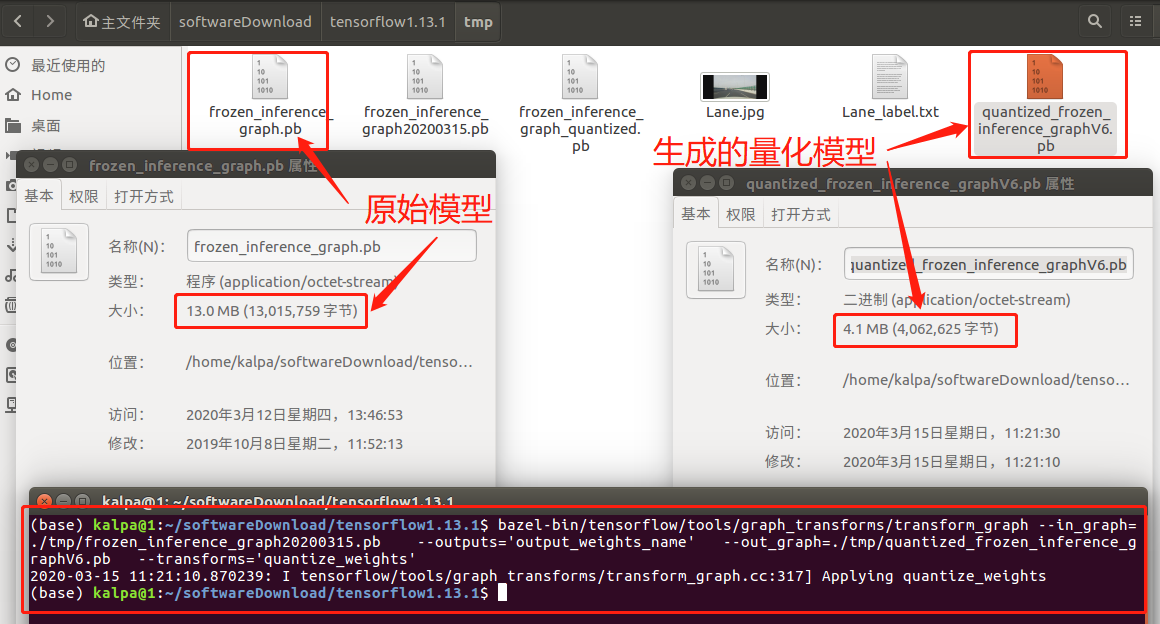
图 2.5 模型量化与效果示例
2.2 训练时量化( Quantization Aware Training )
训练时量化方法相比于训练后量化,能够得到更高的精度。训练时量化方案可以利用 tensorflow 的量化库,在训练和预测时在模型图中自动插入模拟量化操作来实现。鉴于篇幅有限,本文暂且不做实操,后期将针对此量化类型进行详细讲解,敬请期待。如需了解此类型量化步骤,请查阅参考资料(3)。
2.3 tensorflow 量化感知训练
作为一种伪量化手段,tensorflow 量化感知训练是在可识别的某些操作内嵌入伪量化节点( fake quantization nodes ),用以统计训练时流经该节点数据的最大最小值,同时参与前向传播提升精确度(不参与反向传播中梯度更新部分);但其在 TOCO 工具转换为 tflite 格式的量化模型后,其工作原理还是与训练后量化方式一致的,relu 激活函数原理如图 2.6 所示。鉴于篇幅有限,本文暂且不做实操,后期将针对此量化类型进行详细讲解,敬请期待。如需了解此类型量化步骤,请查阅参考资料(1)。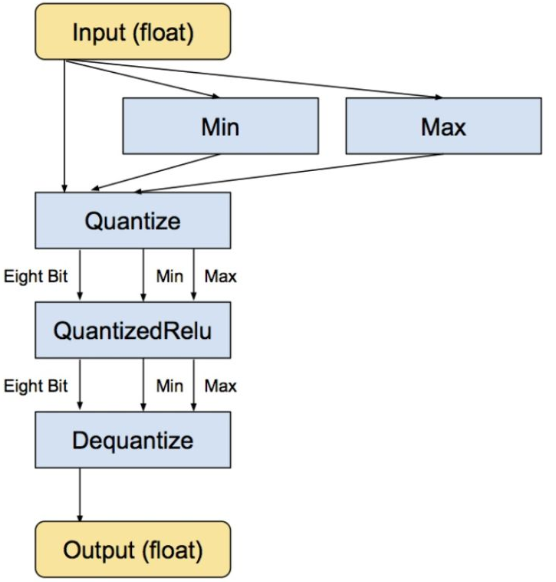
图 2.6 relu 伪量化原理图
- 总结
本文分别对模型量化的理论与实际操作进行详细介绍,并补充训练中量化、tensorflow 量化感知训练等量化理论。除上述三种量化方法外,模型量化还包括全整型量化(群众和激活值量化)、float32 转 float16 的半精度量化等等,而具体的实现途径不仅仅不含 bazel 编译和移植 tensorflow ,还包含了模型中代码修改、实时量化等,鉴于篇幅限制,后续将依需补充相关内容,敬请期待。欢迎在大大通上关注我(花名:AI 奶油小生),给我留言。
- lonlon ago—— TensorFlow 模型 Quantization 离散化或量化
链接:https://zhuanlan.zhihu.com/p/33535898
- wxquare—— tensorflow模型权重量化(weight quantization)实践
链接:https://zhuanlan.zhihu.com/p/86440423?from_voters_page=true
- ChrisZZ—— 安装和配置bazel
链接:https://www.cnblogs.com/zjutzz/p/10182099.html
- 雨天的小尾巴—— 虚拟机无法分配内存 virtual memory exhausted: Cannot allocate memory
链接:https://www.cnblogs.com/ettie999/p/8143712.html
标签:训练,bazel,模型,深度,浮点,tensorflow,量化 来源: https://www.cnblogs.com/bonelee/p/14781693.html