来谈谈GIL
作者:互联网
GIL
GIL,Golbal Interprter Lock(全局解释器锁)
从底层实现来看,GIL锁是结构为pthreads互斥锁(mutex)和一个条件变量(cond)构造的二进制信号量(semaphore)的一个实例(instance),这种semaphore的结构如下:
struct
locked = 0 // Lock status
mutex = pthreads_mutex() // Lock for the status
cond = pthreads_cond() // Used for waiting/wakeup
locked和mutex区别,locked是程序标记位,在程序中标记锁是否被使用;mutex是pthreads互斥锁,在互斥关系中标记锁确实被使用
lock release
release() {
mutex.acquire()
locked = 0
mutex.release()
cond.signal() // send release signal
}
locak acquire
acquire() {
mutex.acquire()
while (locked) {
cond.wait(mutex) // wait 下面有讲wait中主要运行原理
}
locked = 1
mutex.release()
}
下面先设想一种很简单的切换情况,两个线程,其中一个正在运行时遇到了
I/O操作
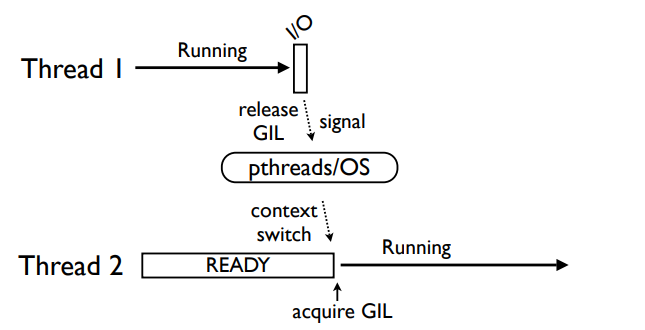
从上图可以看出,此时Thread1遇到了I/O操作,随后释放了GIL锁,并发送signal,pthreads/OS也就是操作系统层面与pthread库进行接收,随后切换Thread2的上下文,并且进行GIL获取操作
非I/O操作
当然上面是最简单的情况,我们假设线程1直接遇到了I/O操作,但是如果线程1没有遇到I/O操作,只是正常的调度,那么是如何实现的?
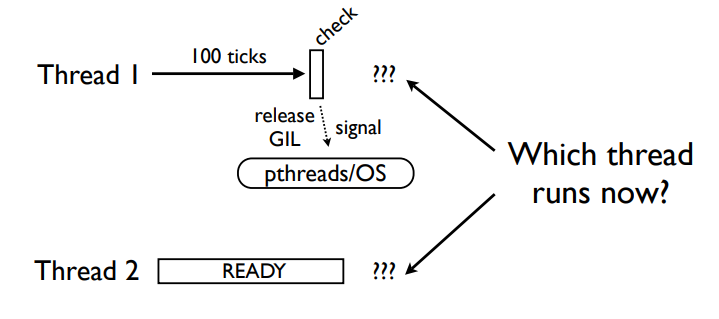
如上图所示,如果是上一个例子遇到I/O时,线程1就不用CPU了,自然只能把锁给Thread2;但是目前这种情况,调度时间到了释放了锁,那么这两个线程该怎样去争夺这个锁?其实奥秘在下图所示:
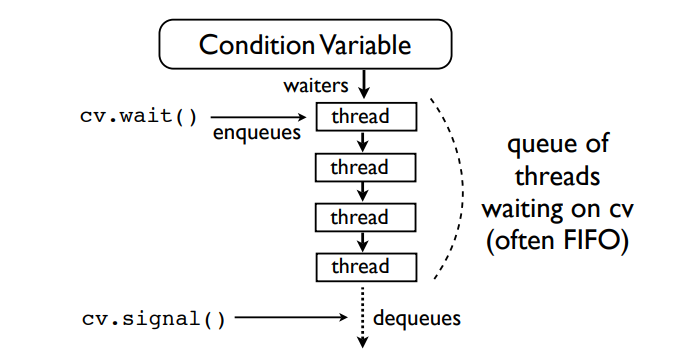
从上图可以看出,cond在内部维护了一个队列,当收到wait指令时则放入内部队列(通常是FIFO)最后位置,当收到signal信号时(此时mutex已经释放过了),将队列第一个thread弹出
highest priority wins
NEW GIL
python3.2之后,使用了最新的GIL,下面来看下做出了哪些优化
非I/O调度 .p.s:堵塞耗时I/O操作等与3.2之前版本并没有太大差异,就不再列举
3.2版本之前,掌握GIL的线程会以每100ticks为一段定时调度周期的进行调度,到达调度周期后,就会进入check流程,释放GIL锁,并由pthread/OS重新判定GIL归属权;
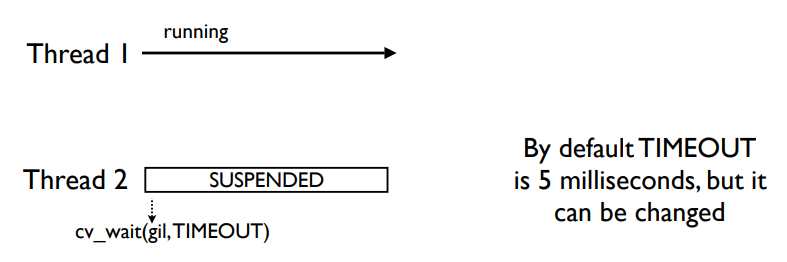
3.2版本后如上图,掌握GIL的线程永远不会主动的释放GIL(I/O时、或任何堵塞操作时当然是会主动释放的),而Thread2会进行一段时间的等待(默认时间是5ms),超出等待时间线程一仍然没有因为某些耗时而释放GIL,则会主动发送gil_drop_request=1指令给Thread1,Thread1接收到指令时,发送signal信号并挂起,Thread2收到Thread1的signal,返回signal ack确认收到释放信号,类似于TCP握手的思想,如此两边就都确认了GIL的归属,步骤如下图所示
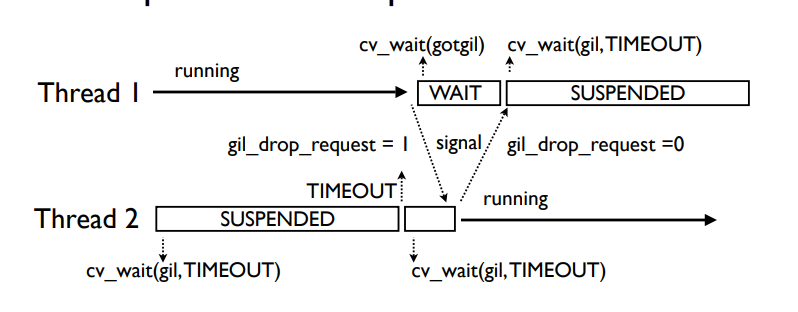
当Thread2收到signal时,就获得了GIL锁。
旧GIL本身的设计存在的问题,在于多线程争夺GIL时有大量的资源消耗,此版本使用等待策略改进了原有的定时释放策略,较大的优化了多计算密集型线程时,耗时比单线程还要大的多的问题,当然并不是解决了这个问题,此种情况时,新的GIL耗时还是会比单线程要多,只不过比旧的GIL要耗时少的多,原因下节会解释。
GIL的缺点所在?
-
从上节最后一图可以想到,如果是在运行计算密集型任务,CPU就会一直被占用,也就是说上述的超时会一直发生,其实就和单线程一样了,不仅如此还增加了signal接收的时间,结果会比单线程还要慢。
-
非即时性,如下图所示
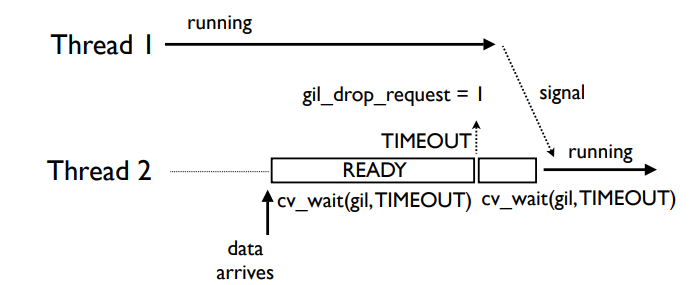
当前两个线程Thread1为计算密集型,Thread2为I/O密集(作者假设其为堵塞待接收数据的一个server),
当Thread2收到了数据,需要处理时才发起cv_wait和gil_drop_request发送请求,增加了响应时间。 -
非公平的线程分配
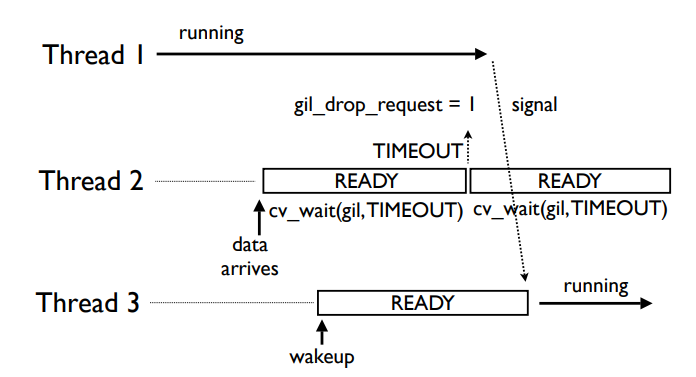
如上图所示,有三个线程,Thread2接收了数据进入等待获取GIL阶段,稍后Thread3也发起等待流程,当Thread1收到gil_drop_request信号时,他会根据cond(还记得cond是啥吗,在GIL节中有介绍)内的队列顺序给予GIL,所以如果内队列中Thread3优先级更高,会导致GIL直接释放给Thread3,此时Thread2必须重新请求,导致时间的增加。
-
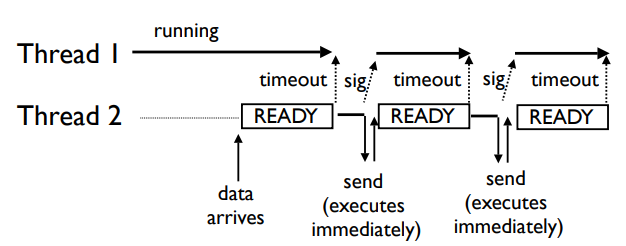
护航效应
护航效应 (Convoy effect): 假设有一个CPU进程和许多I/O型进程 当CPU进程占用CPU运行时, I/O型进程可能完成了其I/O操作,回到就绪队列等待CPU, I/O设备空闲 CPU进程释放CPU后, I/O型进程陆续使用CPU,并很快转为I/O操作,CPU空闲下图可以看出,作者假设Thread2是个非堵塞的server,当收到数据会立马进入等待GIL程序,之后Thread2获取到GIL,一段时间CPU占用完毕,发送数据,但是现在数据非常多,刚发出去又收到了新的,而GIL的规则是I/O操作时必须释放,虽然此时的I/O占用几乎就是瞬间;但是GIL已经释放了,所以当接收到新的数据时又要重新进入等待程序,这样子CPU就出现了大量的GIL切换的时间,造成CPU利用率的低下。
GIL 价值所在?
GIL的宿主CPython解释器,直面的是Python程序的bytecode,CPU每次单独处理一个Thread,保证了bytecode层面的线程安全以及bytecode的原子性,当然了其实对编程时作用不是特别大,因为往往基于bytecode的线程切换并不能保证程序层的线程安全,由于bytecode粒度往往太细,所以一般的python编程还是需要额外的线程锁。
那么GIL存在的价值在哪里?上面说了GIL保证了bytecode的原子性也就是线程安全,确没有阐述这具体有什么用,下面来简单说下。
CPython中一个很人性化的设计是自动化垃圾回收(GC-Garbage collection),其实python的GC整体实现主要依赖引用计数、标记清除、分代回收,其中主要一部分内容就是依赖于引用计数算法,结合标记清楚和分代回收这两个GC的优化算法,绝大部分情况下能够保证内存空间的正常释放;但引用计数的缺点在于:
① 无法释放循环引用的对象
② 必须在引用发生增减时对引用计数做出正确的增减
③ 引用计数管理并不适合并行处理(其实很好理解,并行的计数肯定会产生冲突)
第一点一般是由标记清除来做优化;第二点保证引用计数加减的准确性就不深入了;唯独第三点,因为引用计数不能做并行处理,当一个Python线程在运行时,它会获取GIL以保证它对对象引用计数的更新是全局同步的,保证引用计数值的准确,而此时引用计数函数获取到GIL时,一定是已经保证了原子性的。
上述来看,GIL的存在虽然被大多数人诟病,并有很多大牛建议以及计划去移除;但由于GIL的存在保证了bytecode的原子性,所以是否取消GIL这个想法到今天依然备受争论。
个人理解下,目前CPython解释器GIL会造成多线程状况下的一些弊端,比如当有I/O非堵塞状况或者CPU密集线程比较多的状况等,一个解决方案是可以利用多进程模块代替。
.P.S:程序是死的人是活的,解决方案是人为决定的;而解决方案的层次是能力决定的。⛵
参考文章:
Understanding the Python GIL by David Beazley
标签:signal,谈谈,mutex,Thread2,线程,GIL,CPU 来源: https://www.cnblogs.com/seasen/p/14754660.html