【动手学Paddle2.0系列】DropBlock理论与实战
作者:互联网
【动手学Paddle2.0系列】DropBlock理论与实战
1.DropBlock理论介绍
dropout被广泛地用作全连接层的正则化技术,但是对于卷积层,通常不太有效。dropout在卷积层不work的原因可能是由于卷积层的特征图中相邻位置元素在空间上共享语义信息,所以尽管某个单元被dropout掉,但与其相邻的元素依然可以保有该位置的语义信息,信息仍然可以在卷积网络中流通。因此,针对卷积网络,我们需要一种结构形式的dropout来正则化,即按块来丢弃。在本文中,我们引入DropBlock,这是一种结构化的dropout形式,它将feature map相邻区域中的单元放在一起drop掉。
dropout的主要缺点是它随机drop特征。虽然这对于全连接层是有效的,但是对于卷积层则是无效的,因为卷积层的特征在空间上是相关的。当这些特性相互关联时,即使有dropout,有关输入的信息仍然可以发送到下一层,这会导致网络overfit。
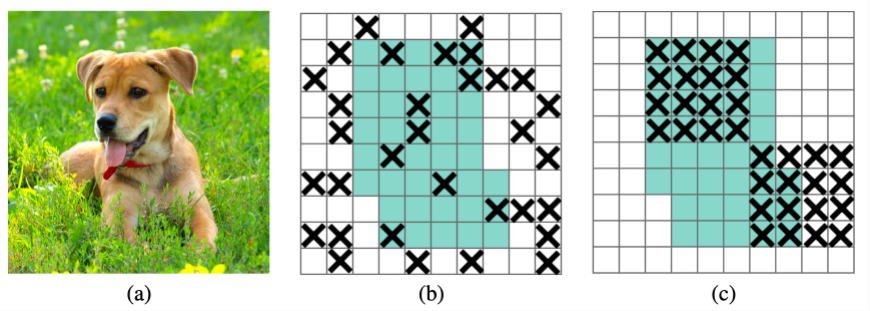
(a)原始输入图像
(b)绿色部分表示激活的特征单元,b图表示了随机dropout激活单元,但是这样dropout后,网络还会从drouout掉的激活单元附近学习到同样的信息
©绿色部分表示激活的特征单元,c图表示本文的DropBlock,通过dropout掉一部分相邻的整片的区域(比如头和脚),网络就会去注重学习狗的别的部位的特征,来实现正确分类,从而表现出更好的泛化。
2.DropBlock代码实战
# 导入相关库
import paddle
import paddle.nn.functional as F
from paddle.vision.transforms import ToTensor
from paddle import fluid
import paddle.nn as nn
from paddle.fluid.optimizer import ExponentialMovingAverage
print(paddle.__version__)
2.0.2
transform = ToTensor()
cifar10_train = paddle.vision.datasets.Cifar10(mode='train',
transform=transform)
cifar10_test = paddle.vision.datasets.Cifar10(mode='test',
transform=transform)
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(cifar10_train, batch_size=64, shuffle=True)
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(cifar10_test, batch_size=64, shuffle=True)
# DropBlock
class DropBlock(nn.Layer):
def __init__(self, block_size, keep_prob, name):
super(DropBlock, self).__init__()
self.block_size = block_size
self.keep_prob = keep_prob
self.name = name
def forward(self, x):
if not self.training or self.keep_prob == 1:
return x
else:
gamma = (1. - self.keep_prob) / (self.block_size**2)
for s in x.shape[2:]:
gamma *= s / (s - self.block_size + 1)
matrix = paddle.cast(paddle.rand(x.shape, x.dtype) < gamma, x.dtype)
mask_inv = F.max_pool2d(
matrix, self.block_size, stride=1, padding=self.block_size // 2)
mask = 1. - mask_inv
y = x * mask * (mask.numel() / mask.sum())
return y
#定义模型
class MyNet_drop(paddle.nn.Layer):
def __init__(self, num_classes=10):
super(MyNet_drop, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding = 1)
# self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
# self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
self.DropBlock = DropBlock(block_size=5, keep_prob=0.9, name='le')
self.conv4 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# x = self.pool1(x)
# print(x.shape)
x = self.conv2(x)
x = F.relu(x)
# x = self.pool2(x)
# print(x.shape)
x = self.conv3(x)
x = F.relu(x)
# print(x.shape)
x = self.DropBlock(x)
x = self.conv4(x)
x = F.relu(x)
# print(x.shape)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
# 可视化模型
cnn1 = MyNet_drop()
model1 = paddle.Model(cnn1)
model1.summary((64, 3, 32, 32))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-5 [[64, 3, 32, 32]] [64, 32, 32, 32] 896
Conv2D-6 [[64, 32, 32, 32]] [64, 64, 15, 15] 18,496
Conv2D-7 [[64, 64, 15, 15]] [64, 64, 7, 7] 36,928
DropBlock-2 [[64, 64, 7, 7]] [64, 64, 7, 7] 0
Conv2D-8 [[64, 64, 7, 7]] [64, 64, 4, 4] 36,928
Flatten-4 [[64, 64, 4, 4]] [64, 1024] 0
Linear-3 [[64, 1024]] [64, 64] 65,600
Linear-4 [[64, 64]] [64, 10] 650
===========================================================================
Total params: 159,498
Trainable params: 159,498
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 27.13
Params size (MB): 0.61
Estimated Total Size (MB): 28.49
---------------------------------------------------------------------------
{'total_params': 159498, 'trainable_params': 159498}
from paddle.metric import Accuracy
# 配置模型
# 定义优化器
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model1.parameters())
model1.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# 模型训练与评估
model1.fit(train_loader,
test_loader,
epochs=3,
verbose=1,
)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/3
step 782/782 [==============================] - loss: 1.2412 - acc: 0.4302 - 123ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.0604 - acc: 0.5404 - 37ms/step
Eval samples: 10000
Epoch 2/3
step 782/782 [==============================] - loss: 1.2764 - acc: 0.5712 - 121ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.7736 - acc: 0.6277 - 37ms/step
Eval samples: 10000
Epoch 3/3
step 782/782 [==============================] - loss: 1.1458 - acc: 0.6297 - 122ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.5729 - acc: 0.6558 - 36ms/step
Eval samples: 10000
对比实验
对比实验在网络结构中不使用DropBlock模块,作为对比。
#定义模型
class MyNet(paddle.nn.Layer):
def __init__(self, num_classes=10):
super(MyNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding = 1)
# self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
# self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
# self.DropBlock = DropBlock(block_size=5, keep_prob=0.9, name='le')
self.conv4 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# x = self.pool1(x)
# print(x.shape)
x = self.conv2(x)
x = F.relu(x)
# x = self.pool2(x)
# print(x.shape)
x = self.conv3(x)
x = F.relu(x)
# print(x.shape)
# x = self.DropBlock(x)
x = self.conv4(x)
x = F.relu(x)
# print(x.shape)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
# 可视化模型
cnn2 = MyNet()
model2 = paddle.Model(cnn2)
model2.summary((64, 3, 32, 32))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[64, 3, 32, 32]] [64, 32, 32, 32] 896
Conv2D-2 [[64, 32, 32, 32]] [64, 64, 15, 15] 18,496
Conv2D-3 [[64, 64, 15, 15]] [64, 64, 7, 7] 36,928
Conv2D-4 [[64, 64, 7, 7]] [64, 64, 4, 4] 36,928
Flatten-1 [[64, 64, 4, 4]] [64, 1024] 0
Linear-1 [[64, 1024]] [64, 64] 65,600
Linear-2 [[64, 64]] [64, 10] 650
===========================================================================
Total params: 159,498
Trainable params: 159,498
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 25.60
Params size (MB): 0.61
Estimated Total Size (MB): 26.96
---------------------------------------------------------------------------
{'total_params': 159498, 'trainable_params': 159498}
# 配置模型
from paddle.metric import Accuracy
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model2.parameters())
model2.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# 模型训练与评估
model2.fit(train_loader,
test_loader,
epochs=3,
verbose=1,
)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/3
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
step 782/782 [==============================] - loss: 1.6163 - acc: 0.4633 - 113ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.6008 - acc: 0.5512 - 36ms/step
Eval samples: 10000
Epoch 2/3
step 782/782 [==============================] - loss: 0.9042 - acc: 0.6083 - 112ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.3076 - acc: 0.6223 - 36ms/step
Eval samples: 10000
Epoch 3/3
step 782/782 [==============================] - loss: 0.3164 - acc: 0.6757 - 115ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.6358 - acc: 0.6442 - 36ms/step
Eval samples: 10000
总结
本来我的想法是对比的重点是网络参数量与模型大小,不对二者的精度做对比。但经过模型的可视化之后,我发现二者的参数量和模型大小都是相同的。所以,DropBlock只是一种模型正则化方法,它不会带来任何参数量的增加,但是在大模型上能够有效的提升模型的泛化能力。
标签:实战,nn,Paddle2.0,self,paddle,step,64,DropBlock,size 来源: https://blog.csdn.net/lxm12914045/article/details/116160619