XGBoost
作者:互联网
XGBoost
1 XGBoost的概念
xgboost英文全称为extreme gradient boosting,译为极限梯度提升算法
它是继承算法中的boosting提升法的代表算法。
它的要求为弱评估器的结果必须比随机的结果好,即准确率高于50%。
xgboost是由梯度提升树发展而来,背后为CART树,所以xgboost中的所有树都是二叉的。
2 XGBoost的安装
# windows
pip install xgboost
pip install --upgrade xgboost
# mac
brew install gcc@7
pip3 install xgboost
3 XGBoost的建模参数
3.1 弱评估器数量num_round
数量越多,模型越容易过拟合,与随机森林一样
数量过少,模型可能欠拟合
xgboost:
num_round 默认10
sklearn:
n_estimators 默认100
3.2 是否打印每次迭代的训练结果verbosity
xgboost:
slient 默认False
# verbosity 范围[0,1,2,3] 0为silent 3为debug
sklearn:
slient 默认True
3.3 有放回随机抽样比例subsample
抽样比例小可能会导致过拟合
因为数据少,模型见识少,更倾向于这小部分数据的趋势
通常在样本量大时调整该参数
xgboost:
subsample 默认1 范围(0,1]
sklearn:
subsample 默认1 范围(0,1]
3.4 学习率/步长eta
xgboost同样使用梯度下降的方法使损失函数降到局部最低点
可以设置步长控制下降的速率。
速率越高下降越快,但速率过高可能难以达到最低点,一直在两侧往返。
速率过低可能导致到达最大迭代次数时还未抵达最低点。
xgboost:
eta 默认0.3 范围[0,1]
sklearn:
learning_rate 默认0.1 范围[0,1]
3.5 弱评估器xgb_model
xgboost可以选择不同的弱评估器类型,包括树模型,线性模型。
xgboost:
xgb_model 默认gbtree 可以输入gbtree,gblinear或dart
sklearn:
booster 默认gbtree 可以输入gbtree,gblinear或dart
gbtree代表梯度提升树,
gblinear代表线性模型,
dart是dropouts meet multiple additive regression trees,即抛弃提升树,建树过程中会抛弃一部分树,比梯度提升树有更好的防过拟合功能。
3.6 目标函数obj
目标函数包含两部分:传统算法的损失函数+算法复杂度
xgb使用目标函数来衡量模型的效果,效果包括 准确度 和 模型复杂度(运算效率)
在xgboost的迭代过程中,每一棵树都最小化目标函数以获取最优的预测值。
可以说xgboost的损失函数就是目标函数。
在将算法复杂度加入损失函数后可以有效的控制xgboost过拟合的程度
作者也是受到泛化误差计算方式的启发,设计了目标函数
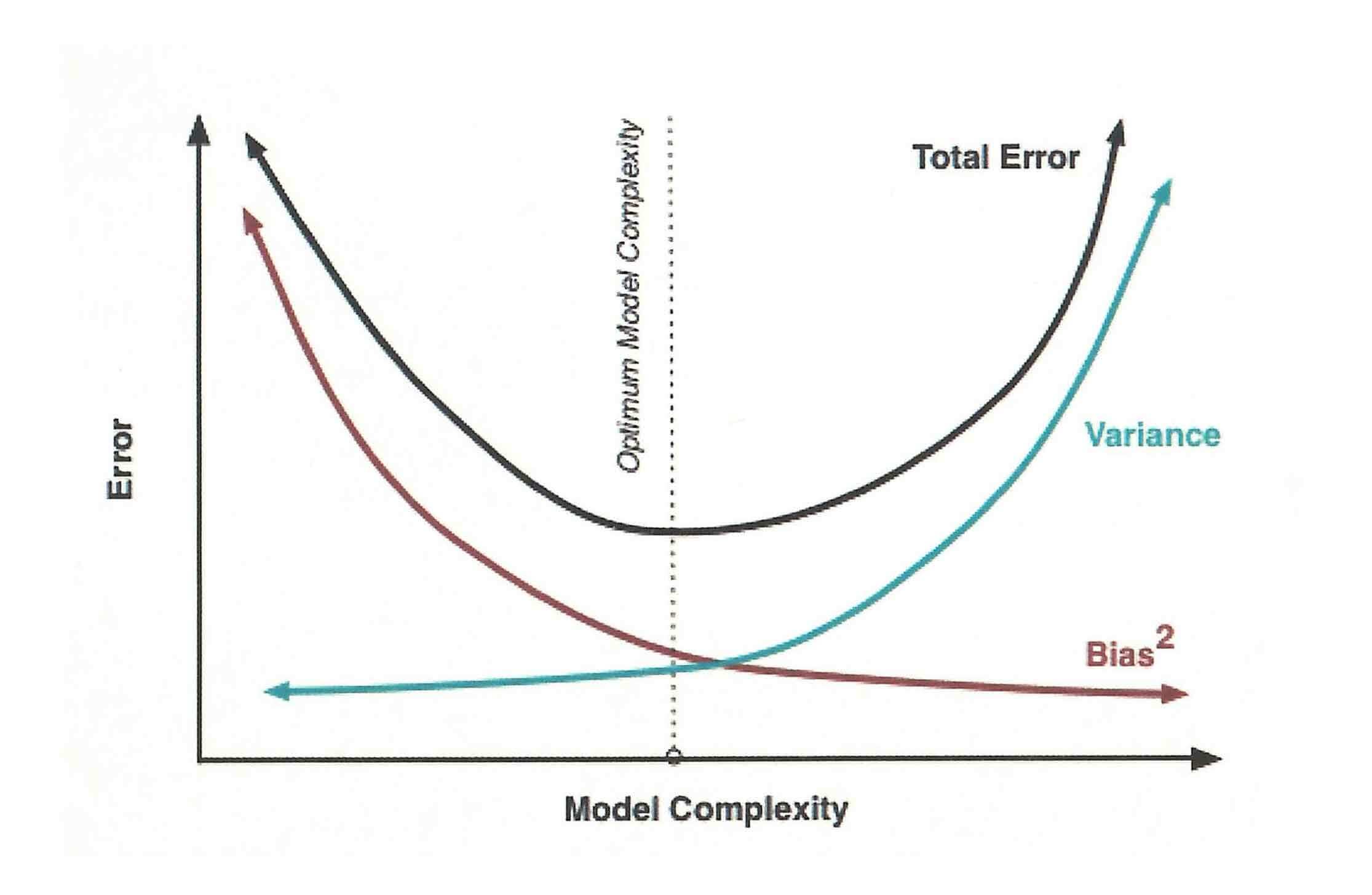
泛化误差 = 偏差**2 + 方差 + 噪声**2
E(f;D) = bais**2 + var + ξ**2
树模型会随着模型复杂度的提升,产生过拟合,导致偏差变小但方差变大
偏差+复杂度也可以类比为偏差+方差
因此使用目标函数也同时能一定程度上保证模型的泛化误差
损失函数可以根据需求自由选择,包含均方误差,错误率,对数损失等
复杂度为 叶子个数*超参数gamma+正则项
xgboost:
obj 默认binary:logistic
sklearn之XGBClassifier:
objective 默认binary:logistic
sklearn之XGBRegression:
objective 默认reg:linear
可选范围:
reg:linear 使用线性回归的损失函数,均方误差,回归时使用
binary:logistic 使用逻辑回归的损失函数,对数损失,二分类时使用
binary:hinge 使用支持向量机的损失函数,Hinge Loss,二分类时使用
multi:softmax 使用softmax损失函数,多分类时使用
3.7 正则化参数alpha/lambda
控制过拟合
xgboost:
alpha 默认0 范围: [0,+∞] l1正则项的参数
lambda 默认1 范围: [0,+∞] l2正则项的参数
sklearn之xgb.XGBRegression:
reg_alpha 默认0 范围: [0,+∞] l1正则项的参数
reg_lambda 默认1 范围: [0,+∞] l2正则项的参数
3.8 分枝阈值gamma
xgboost规定gain大于零时就可继续分枝,所以传统损失函数的值大于gamma时即可继续分枝。
可以通过调节gamma控制分支的阈值。
xgboost:
gamma 默认0 范围: [0,+∞]
sklearn之xgb.XGBRegression:
gamma 默认0 范围: [0,+∞]
3.9 剪枝参数max_depth,colsample_bytree...
| 参数含义 | xgb.train() | xgb.XGBRegressor() |
|---|---|---|
| 树的最大深度 | max_depth,默认6 | max_depth,默认6 |
| 每次生成树时随机抽样特征的比例 | colsample_bytree,默认1 | colsample_bytree,默认1 |
| 每次生成树的一层时随机抽样特征的比例 | colsample_bylevel,默认1 | colsample_bylevel,默认1 |
| 每次生成一个叶子节点时随机抽样特征的比例 | colsample_bynode,默认1 | N/A |
| 一个叶子节点上所需要的最小h,即叶子节点上的二阶导数之和,类似于样本权重 | min_child_weight,默认1 | min_child_weight,默认1 |
3.10 样本不均衡 scale_pos_weight
该参数在分类问题中出现样本不均衡问题时使用
(还可以考虑使用base_score,详见3.11.2)
xgboost:
scale_pos_weight 默认1 负样本数量/正样本数量
sklearn之xgb.XGBClassifier:
scale_pos_weight 默认1 负样本数量/正样本数量
如果样本不均衡的同时想要得到高准确率,就不能使用scale_pos_weight了,
二分类时可以设置参数max_delta_step为一个有限的数(比如1)来帮助收敛
3.11 其他参数
3.11.1 n_jobs计算资源
nthread和n_jobs都是算法运行所使用的线程
输入整数表示使用的线程,
输入-1表示使用计算机全部的计算资源。
如果我们的数据量很大,则我们可能需要这个参数来为我们调用更多线程。
3.11.2 base_score降低学习难度
base_score:全局偏差
样本不均衡时可以使用
分类问题中它就是分类的先验概率
如有1000个样本,300个正样本和700个负样本,则base_score就是0.3
对于回归来说这个分数默认为0.5,但是理论上而言这个分数应该设置为标签的均值更好
3.11.3 random_state随机模式
填入该参数可以控制模型的随机性
3.11.4 missing自动处理缺失值
该参数设计初衷是为了处理稀疏矩阵
可以在missing参数传入一个对象,如np.nan,表示将该值全部作为空值处理(稀疏矩阵的0)
4 XGBoost的模型评估指标
先使用网格搜索找出比较合适的n_estimators和eta组合,
然后使用gamma或 者max_depth观察模型处于什么样的状态
是过拟合还是欠拟合,处于方差-偏差图像的左边还是右边?
最后再决定是否要进行剪枝。
xgboost.cv(params, dtrain, num_boost_round=10, nfold=3, stratified=False, folds=None, metrics=(), obj=None,feval=None, maximize=False, early_stopping_rounds=None, fpreproc=None, as_pandas=True, verbose_eval=None,show_stdv=True, seed=0, callbacks=None, shuffle=True)
rmse 回归用,均方根误差
mae 回归用,绝对平均误差
logloss 二分类用,对数损失
mlogloss 多分类用,对数损失
error 分类用,分类误差,等于1-准确率
auc 分类用,AUC面积
5 模型保存及调用
5.1 pickle
5.1.1 保存
import pickle
model = xgb.train(param, dtrain, num_round)
with open('model.dat','wb') as f:
pickle.dump(model,f)
5.1.2 调用
import pickle
with open('model.dat','rb') as f:
model = pickle.load(f)
y_pred = model.predict(xtest)
5.2 joblib
5.2.1 保存
import joblib
model = xgb.train(param, dtrain, num_round)
joblib.dump(model,'model.dat')
5.2.2 调用
import joblib
model = joblib.load(model,'model.dat')
y_pred = model.predict(xtest)
标签:xgboost,函数,XGBoost,xgb,默认,参数,model 来源: https://www.cnblogs.com/achai222/p/14649420.html