模板攻击
作者:互联网
模板攻击是一种强大的侧信道攻击。它是“建模类”攻击(profiling attack)的一种,所谓建模类攻击,是指攻击者会在目标设备的同类型设备或者其复制品上创建一个"profile",随后利用这一"profile"快速恢复目标设备的密钥。
相较于CPA,模板攻击对攻击者的要求更高。攻击者需要对目标设备的复制品具有完全的控制权,并且进行大量的前期工作以建立模板,不过,一旦模板建立,攻击者能够以很小的代价完成攻击。在模板足够好的情况下(如建模所用的能量迹数量足够大),攻击者仅需一条能量迹即可恢复密钥。(下文中以“曲线”一词替代“能量迹”)
模板攻击分为以下四步:
- 利用一个可以完全控制的目标设备的复制品,使用不同的输入(明文和密钥)进行计算并采集曲线,确保采集的曲线足够提供给攻击者每一种密钥猜测对应的信息
- 创建模板,模板是一种POIs(points of interest)的多元分布
- 在目标设备上,使用少量的不同明文加密获取相应的曲线(目标设备的密钥不受攻击者控制)
- 利用模板进行攻击,找到最可能正确的密钥猜测值
本文译自http://wiki.newae.com/Template_Attacks
信号、噪声和统计学
开始讨论模板攻击的细节前,理解其涉及的统计学概念是非常重要的。所谓模板就是一种描述曲线上关键点的多元分布。这一部分就是介绍何为多元分布以及它是如何在侧信道这一背景下使用的。
噪声分布
电信号是内在的噪声。无论何时我们进行电压测量,我们都不会看到一个完美、恒定的结果。例如,如果我们把万用表接到一个5V的电源上并进行4次测量,得到的结果更可能是类似于(4.95、5.01、5.06、4.98)这样,可以考虑用如下方式对这一电压建模:
\[\boldsymbol{X} = X_{actual}+\boldsymbol{N} \]其中,\(X_{actual}\)代表无噪声的电压测量,\(\boldsymbol{N}\)代表额外的噪声。在上面的例子中,\(X_{actual}\)为5V。\(\boldsymbol{N}\)为随机变量,每次测量的结果都不同。注:\(\boldsymbol{N}、\boldsymbol{X}\)加粗表示它们是随机变量。
高斯分布(即正态分布)是一种可以用来描述这些随机变量的模型。高斯分布的概率密度函数(PDF)是:
\[f(x) = \frac{1}{\sigma \sqrt{2 \pi}}e^{-(x-\mu)^2/2\sigma^2} \]其中, \(\mu\)表示平均值、\(\sigma\)表示标准差。如在上面的例子中,如果均值为5,标准差为0.5,那么它对应的概率密度函数为
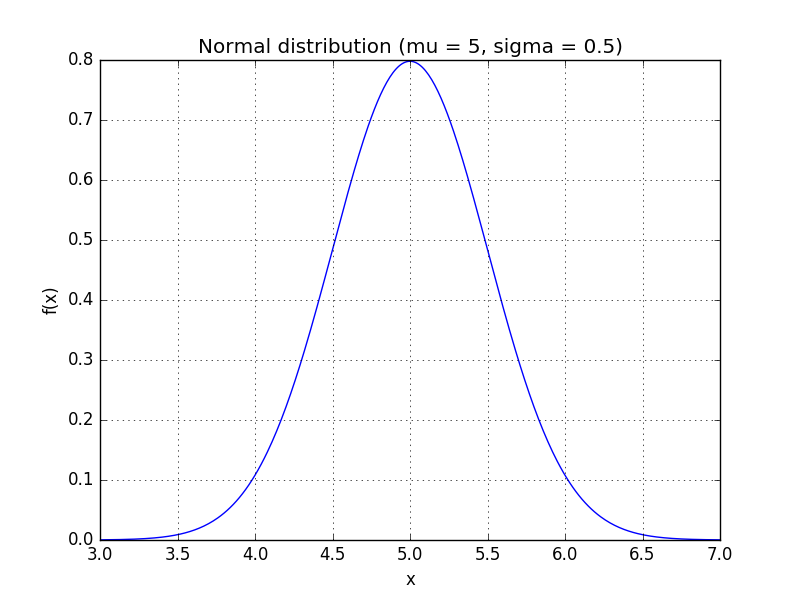
我们可以利用概率密度函数来评估一个测量值出现的可能性,如:
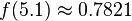
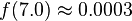
由此可见,测量结果为7V的概率是极小的。我们将这一特点应用在模板攻击中,如果某一个密钥猜测对应的概率密度值较小,那它极有可能是错误的。
多元统计
上面的例子告诉我们,对于一个值的测量来讲一元高斯分布能够有很好的表现,但如果我们需要同时处理多个随机变量呢?
假设我们正在测量两个夹杂着噪声的电压源,记为\(\boldsymbol{X}、 \boldsymbol{Y}\),其中,\(\boldsymbol{X}\)符合正态分布,\(\boldsymbol{Y}\)符合另一种分布。然而,这不一定是有效的。如果二者遵循不同的分布,,那我们则认为这二者是独立的,即当\(\boldsymbol{X}\)发生变化时,\(\boldsymbol{Y}\)不一定会随之变化。
多元分布能够帮助我们对相关或不相关的多个随机变量进行建模。在多元分布中,不再使用方差,而是使用一个协方差矩阵。例如,对三个随机变量(\(\boldsymbol{X}, \boldsymbol{Y}, \boldsymbol{Z}\))建模,该协方差矩阵为:
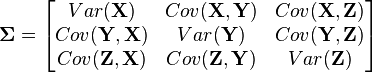
相应地,这种分布要求每一个随机变量都有一个平均值:
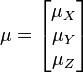
多元分布的概率密度函数要更复杂一些:不再使用单个数作为参数,而是使用一个包含全部变量的向量\(\boldsymbol{x}=[x, y, z,...]^T\)。k个随机变量的概率密度函数为:
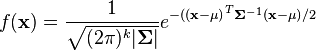
如果觉得这个公式太复杂了,不用担心,python中的scipy科学计算包已经给我们提供了底层的实现。上一部分中我们将单个值输入概率密度函数得到了对应的测量出现的可能性。换句话说,只要将曲线上的点(POIs)放入\(\boldsymbol{x}\)中进行计算,那么\(f(x)\)就能告诉我们这一密钥猜测正确的可能性了。
创建模板
模板是多个概率分布的集合,每个概率分布描述了一个密钥可能对应的曲线的样子。也可以这么说:“如果你使用了密钥\(k\),那么你的能量曲线会符合\(f_k(\boldsymbol{x})\)。”利用这一性质,我们就可以区分能量曲线之间的细微不同,并作出准确的密钥猜测。
曲线数量
模板攻击的一大缺点就在于在开始攻击前攻击者需要收集大量的曲线用于建模阶段。这是因为要对每一个可能的密钥都能得到一个好的模型,就需要对每个可能的密钥都收集足够多的曲线用以建模。例如,如果要攻击AES-128的子密钥(一次S盒操作用到的一个字节),就需要对0-255这256个可能的值分别建模。所以,往往我们需要上万的曲线才能在建模阶段有一个好的结果。
当然,如果我们不对每个可能的密钥值建模,而是对密钥的汉明重量建模,同样在AES-128的情况下,只需要0-8共9个模型即可,需要的曲线数量大大减少。不过,这样做缺点也很明显,不再能使用单条曲线即可恢复密钥,还需要一些其他的信息。
Points of Interest
我们的目标是创建多元概率分布来描述每一个可能的密钥对应的曲线。如果我们用这种方式对整个曲线(如有3000个点)建模,那么就需要一个3000维的分布。这是很夸张的,所以我们需要一种更好的方式来替代它。好消息是,并不是曲线上的每一个点对我们都有用,原因如下:
- 每个时钟周期可能会取样多次。因此我们可以从一个适当的点获取大量的信息而无需处理曲线上所有的点
- 私钥不一定会影响整条曲线,它可能只影响曲线的一些关键部位。找出这些部位,我们就可以舍弃掉无关的点
这两点意味着我们可以从曲线中选择最重要的3-5个点作为POIs(points of interest),如果我们可以选出这些点,那么就可以使用一个3维到5维的分布来描述曲线,相较于3000维这是一个非常大的提升。
如何选择POIs
有很多种选择POIs的方法,主要目标是找到在操作数不同(不同的密钥或汉明重量)的曲线上差异较大的点。这里介绍最简单的方法--差值求和。
- 对于每一个操作数\(k\)对应的曲线上的第\(i\)个点求平均值\(M_{k,i}\),例如当我们采集到使用密钥\(k\)进行加密的\(T_k\)条曲线后,就会有\(M_{k,i} = \frac{1}{T_k}\sum_{j=1}^{T_k}{t_{j,i}}\)
- 求得每个\(k\)的均值后,两两作差,并对这些差值求和。这将会得到一条有尖峰的曲线(如下图),尖峰处即为上面提到的差异大的点。计算方式为\(D_i = \sum_{k_1, k_2} |M_{k_1, i}, M_{k_2, i}|\)
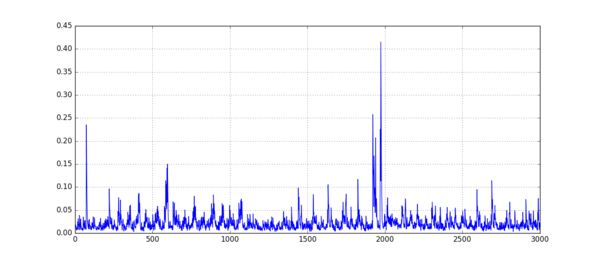
- 尖峰位置即为重要的点,但考虑到上一部分中的第一条,相邻很近的尖峰我们需要舍弃一部分。下面这个算法可以帮我们选择最终的POIs:
- 选择最高的尖峰,并将其索引选为一个POI
- 舍弃最近的N个点(N为POIs之间的最小距离)
- 重复前面两个步骤直至选取足够的POIs
分析数据
假设我们已经确定了I个POIs,记为\(s_i,(0<=i<I)\)。那么我们下面的任务就是为每一个候选的子密钥或者中间值的汉明权重求得一个均值和一个协方差矩阵,设共有K个候选项。
对一个单独的候选项\(k\)而言,步骤如下:
-
获取\(k\)对应的所有曲线,共\(T_k\)条,则\(t_{j,s_i}\)表示第\(j\)条曲线第\(s_i\) 个POI的值
-
计算每个POI的值的均值\(\mu_i\)
\[\mu_i = \frac{1}{T_k}\sum_{j=1}^{T_k}t_{j, s_i} \] -
计算每个POI的值的方差\(v_i\)
\[v_i = \frac{1}{T_k}\sum_{j=1}^{T_k}(t_{j, s_i}-\mu_i)^2 \] -
计算每一个POI点对(\(i、i^*\))的协方差\(c_{i,i^*}\)
\[c_{i,i^*}=\frac{1}{T_k}\sum_{j=1}^{T_k}(t_{j, s_i}-\mu_i)(t_{j,s_i^*}-\mu_i^*) \] -
得到均值向量和协方差矩阵
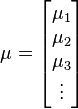
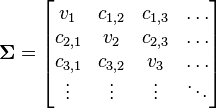
对每个\(k\)都执行一遍上述操作,我们就完成了对\(K\)个候选者的建模工作
使用模板
建模完成后,就可以开始进行攻击了。完成攻击需要若干条曲线,设该值为\(A\),那么\(a_{j,s_i},(1<=j<=A)\)就表示第\(j\)条曲线的第\(i\)个POI的值。
应用模板
首先我们尝试将上一节中建立的模板应用在单条曲线上,目标是得到所有密钥猜测的可能性。
- 将POIs的值放入向量,得到
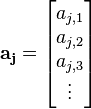
- 计算每个密钥猜测的概率密度函数(PDF):\(p_{k,j} = f_k(a_j)\)
- 对每一条曲线重复上述步骤
这部分操作得到一系列的\(p_{k,j}\),代表第\(j\)条曲线表示的候选者是\(k\)的概率
组合结果
最后一步就是根据所有的\(p_{k,j}\)判断哪个密钥猜测更可能是最终的答案。最简单的方法就是:
\[P_k = \prod_{j=1}^Ap_{k,j} \]例如,如果我们的一个密钥猜测为0x00,并且三条曲线对应的概率密度为(0.9, 0.95, 0.8),那么计算结果会是0.684。只要有一条曲线不符合模板,就会使得最终值迅速下降,这非常有助于我们消除错误选项。最终,我们选择\(P_k\)值最高的\(k\)作为攻击结果。
这种将每条曲线的结果直接组合起来的方法容易出现精度问题。将很多数相乘后,最终得到的结果可能超出了浮点数的表示范围,造成精度问题。一个非常简单的解决方法就是使用对数。使用如下方法:
\[\log{P_k} = \sum_{j=1}^{A}\log{p_{k,j}} \]代替直接计算\(P_k\),使用对数结果即可作出正确且不存在精度问题的结论。
标签:曲线,攻击,boldsymbol,建模,POIs,密钥,模板 来源: https://www.cnblogs.com/chuaner/p/14617354.html