AWS 大数据实战 Lab2 - 批量数据处理(三)
作者:互联网
在本练习中,您将学习如何使用 Amazon EMR(Spark)和 AWS Glue(ETL)构建批量数据分析处理程序。为了使本实验的练习更加贴近实际的业务场景,我们模拟了完整的从数据产生(模拟历史数据和流数据)、数据存储、数据处理、到数据分析和数据可视化的完整过程(数据可视化在 Lab3/Lab4 中完成)。
具体可参考如下架构图:
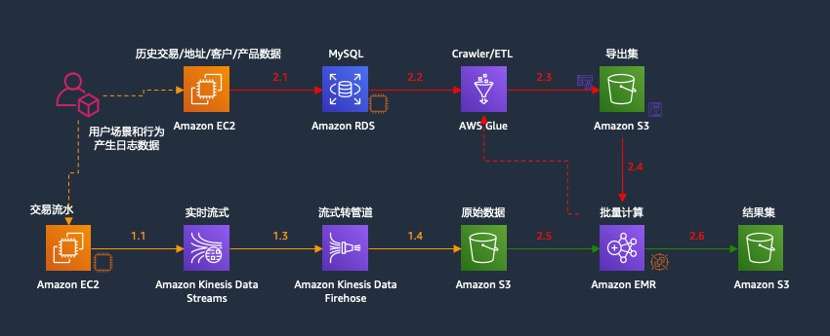
组件说明如下:
• RDS 作为 Lab2 次实验的历史数据源,RMDBS 格式,包含人员信息表 tbl_customer、产品信息表 tbl_product、地址信息表 tbl_address、交易历史流水表 tbl_transaction,等 4 张表,参与批处理计算;
• Lab1 实验中 Kinesis 的输出(存放在 Lab1 指定的 S3 文件夹中,Json 格式),为近实时当日交易流水,也可以作为 Lab2 批处理的输入,参与批处理计算(注意:学员可以考虑使用 Lab1 的输出数据或者使用我们提前准备好的数据);
• S3 桶作为数据湖的存储基础,包含 input 文件夹(用于 EMR Spark 批处理的输入),存放通过 Glue ETL 加载进来的 RDS 历史数据源和 Kinesis 当日近实时数据,以 Parquet 格式存放。output 文件夹,存放 EMR Spark 批处理的结果数据(Parquet 格式);
详细的数据流步骤说明如下:
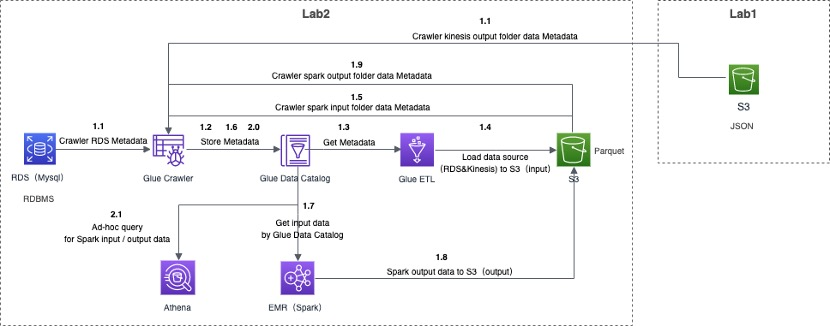
具体说明如下:
1.1 通过 Glue Crawler 功能爬取 RDS 库中 4 张表的元数据和 Kinesis 输出的数据的元数据;
1.2 Glue Crawler 将爬取 RDS和 Kinesis 的元数据,存入到 Glue 的 Data Catalog 数据库;
1.3 Glue ETL 通过 Data Catalog 识别 RDS 表元数据和 Kinesis 元数据,以便 ETL 作业引用;
1.4 Glue ETL 加载 4 张表数据和 Kinesis 输出的数据,到指定的 S3 存储桶的 input 文件夹中,作为 Spark 批处理的数据源输入;
1.5 通过 Glue Crawler 功能爬取 S3 桶中 input 文件夹中数据的元数据;
1.6 Glue Crawler 将爬取 input 文件夹中数据的元数据,存入 Glue 的 Data Catalog 数据库;
1.7 EMR Spark 环境通过 Data Catalog 获取 input 文件夹的元数据,进而开展批处理作业;
1.8 将 EMR Spark 批处理作业的结果输出至指定的 S3 存储桶的 output 文件夹中;
1.9 通过 Glue Crawler 功能爬取 S3 桶中 output 文件夹中数据的元数据;
2.0 Glue Crawler 将爬取 output 文件夹中数据的元数据,存入 Glue 的 Data Catalog 数据库;
2.1 利用 Athena 服务,查询 input、output 数据;
其中步骤 1.9/2.0/2.1 和 Lab3 有重叠,所以在此处不做演示或说明。
数据处理(ETL)
本实验演示数据处理的过程(ETL过程,此处我们使用AWS Glue服务),数据分析在下个章节。
连接到RDS
登录并打开AWS Glue控制台,选择添加数据库连接:
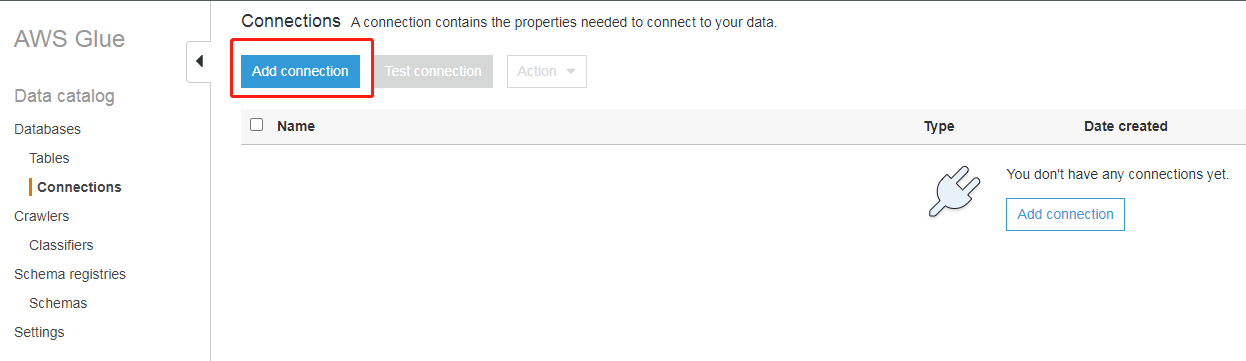
设置连接名称(Lab2-Glue-RDS-connection)和类型
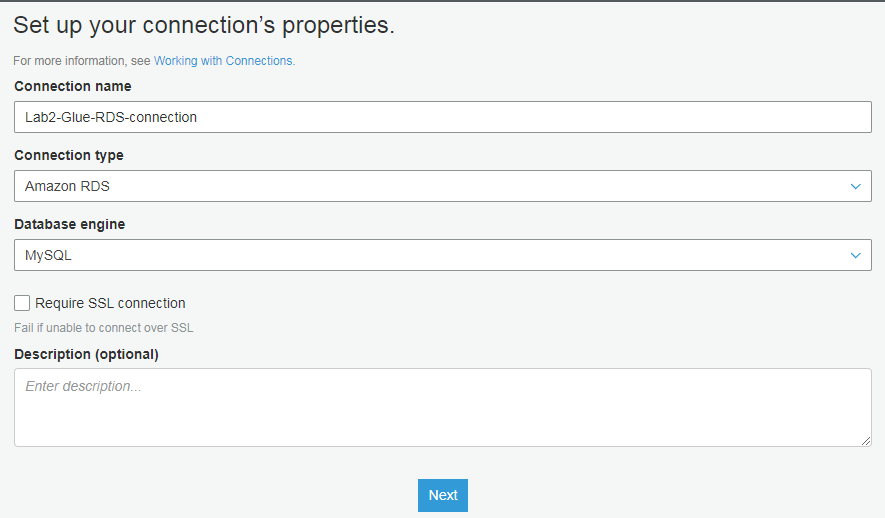
选择对应配置(请输入之前部署 rds 时admin的密码,此处为wzlinux2021)
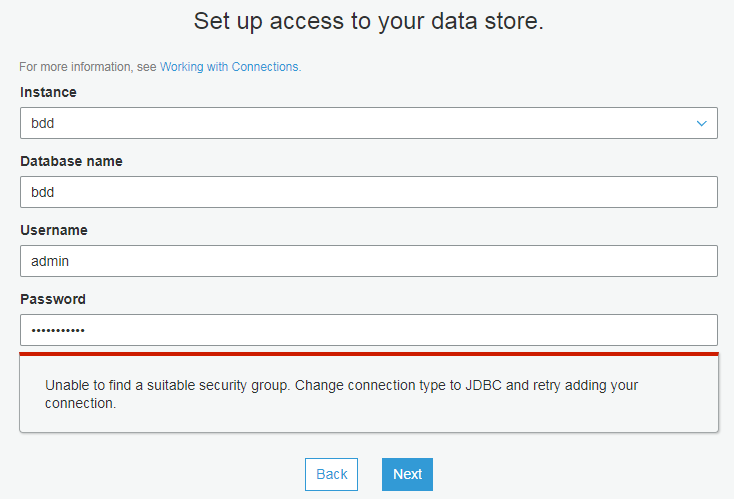
当连接中使用的安全组入站规则中没有添加自引用规则会生成错误"unable to find suitable security group error"。为了解决该问题,您需要添加一个自引用规则,以允许 AWS Glue 组件进行通信。具体来讲,添加或确认有一条类型为 All TCP 的规则,协议为 TCP,端口范围包括所有端口,其源具有与组 ID相同的安全组名。
- 从RDS控制台中选择要从 AWS Glue 访问的 Amazon RDS Engine (引擎) 和 DB Instance (数据库实例) 名称。
- 选择查看详细信息。在 Details (详细信息) 选项卡上,查找要从 AWS Glue 访问的 Security Groups (安全组) 名称。记录下该安全组的名称以供将来参考。
- 选择安全组以打开 Amazon EC2 控制台。
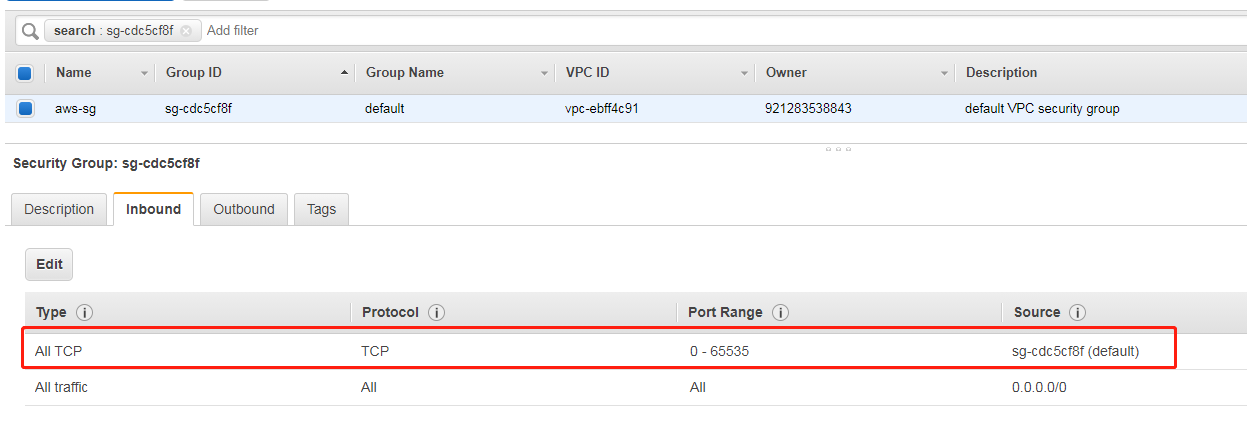
- 确认已选择来自 Amazon RDS 的 Group ID (组 ID),然后选择 Inbound (入站) 选项卡。
- 添加一个自引用规则,以允许 AWS Glue 组件进行通信。具体来讲,添加或确认有一条类型为 All TCP 的规则,协议为 TCP,端口范围包括所有端口,其源具有与组 ID相同的安全组名。
这时候告警就消失了,我们可以进行连接了
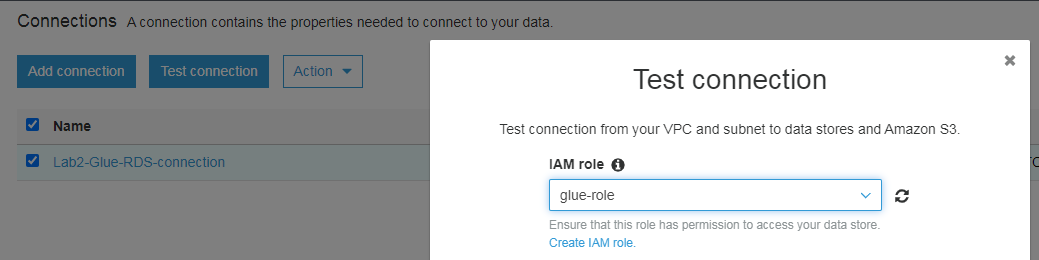
审核并完成,然后开始连接测试,测试时需要使用第一步创建的 role(这是在准备阶段创建的 IAM 角色 glue-role)
需要1-2分钟的时间,略微等待即可
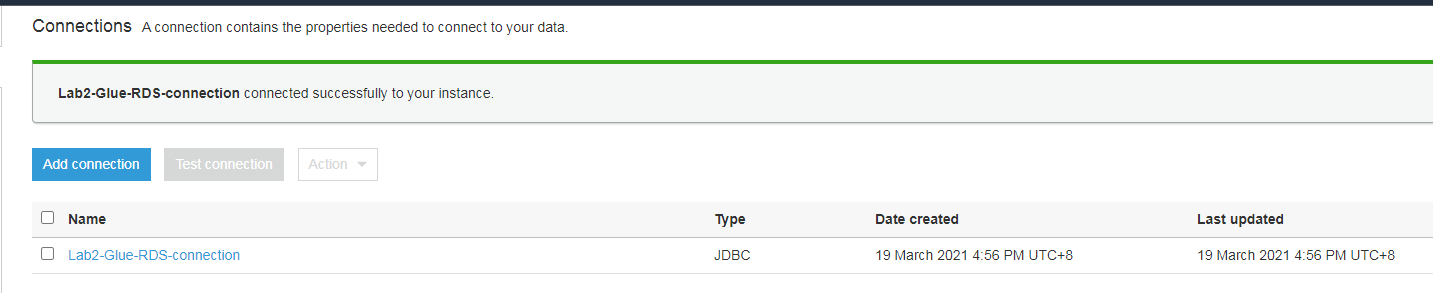
爬取RDS元数据
创建名为my-lab2-crawler-rds的爬网程序,设置爬网程序名称
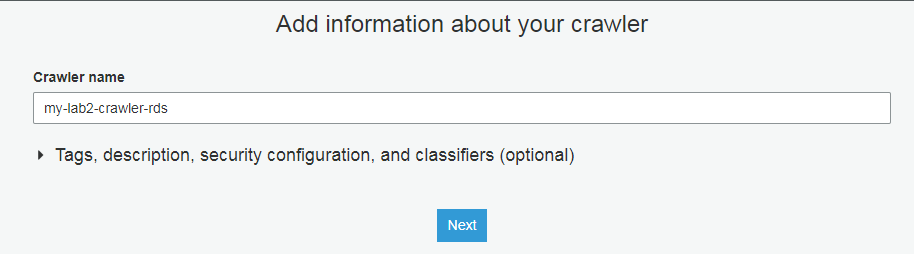
配置对应参数(包含路径那里输入:bdd/%)
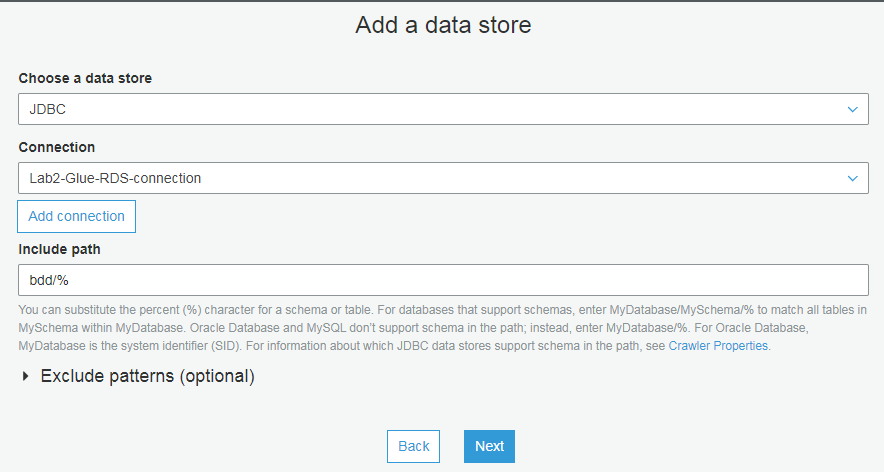
选择对应的 role
配置输出(点击添加数据库,名字为default即可)
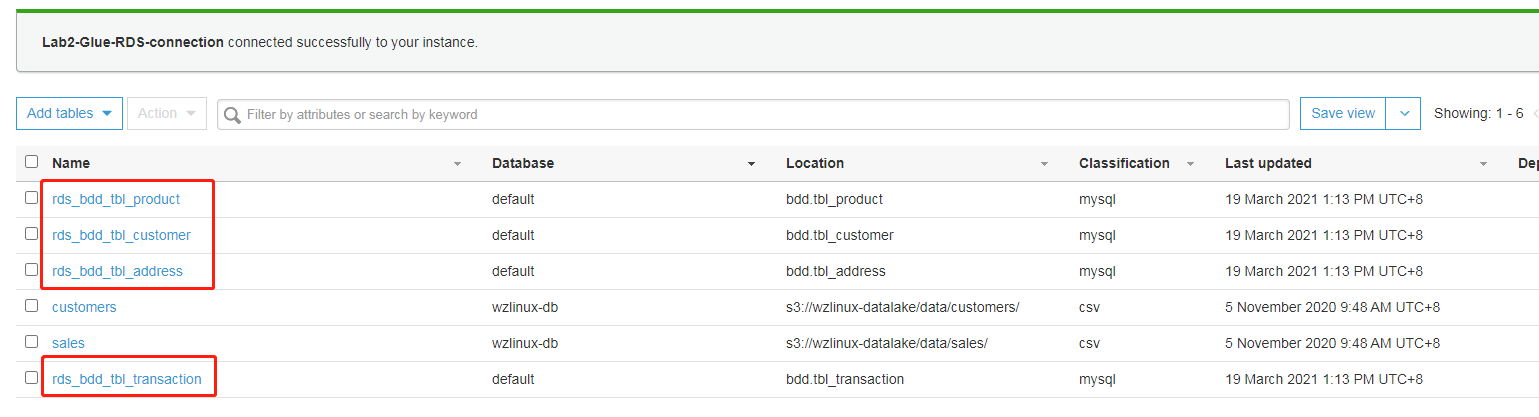
完成后,运行爬网程序,爬取成功后,元数据目录中会出现 4 张 RDS 元数据表
爬取kinesis输出的元数据
创建名为my-lab2-crawler-kinesis的爬网程序
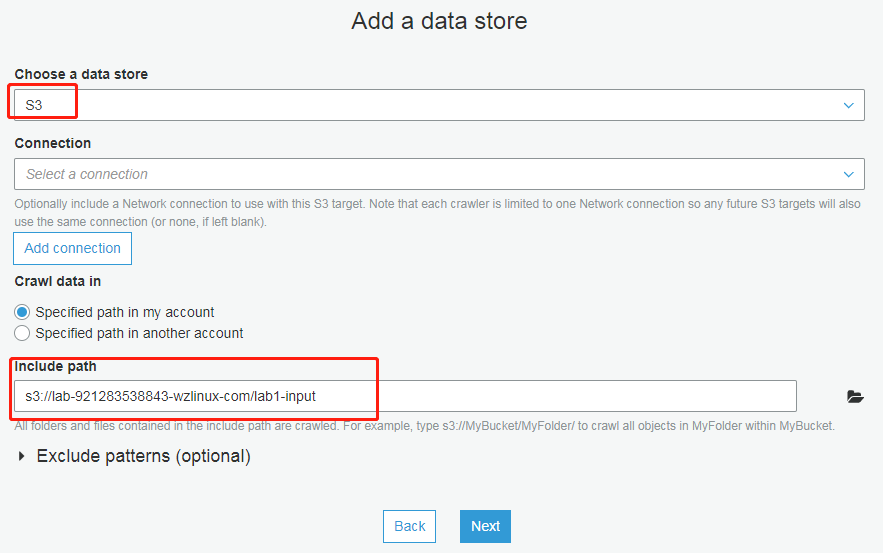
添加数据存储(此处选择Lab1的输出)
选择对应的role
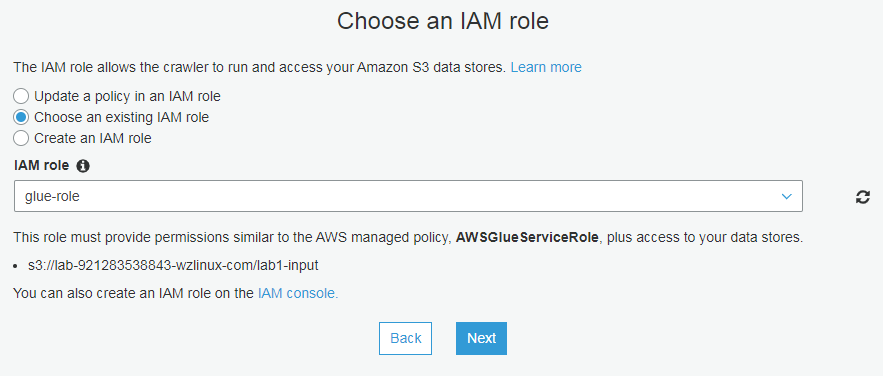
配置输出
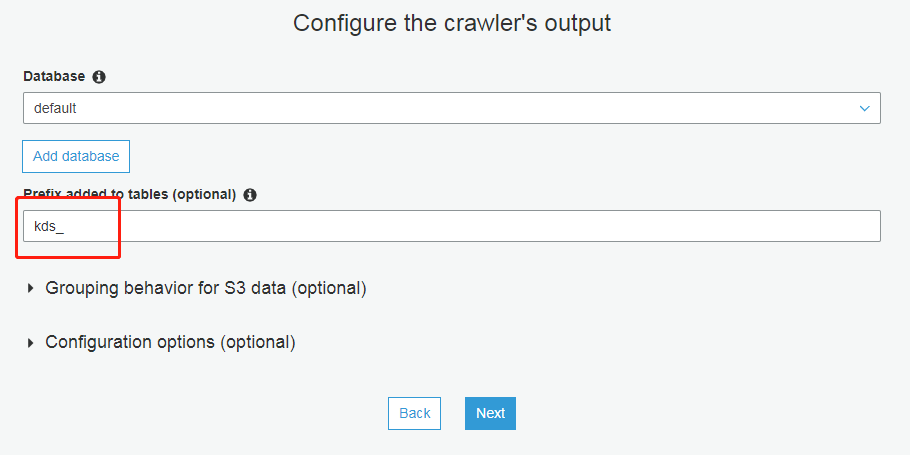
完成后,运行爬网程序,元数据目录中会出现 1 张 Kinesis 元数据表
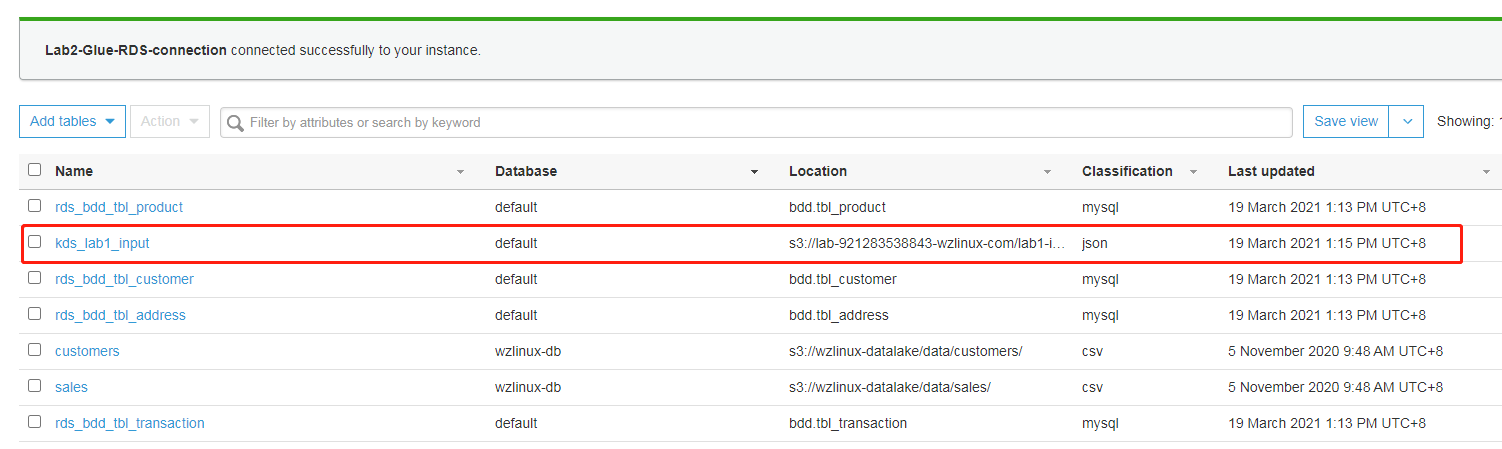
合并rds和kinesis的数据输出到s3
此处需要一个作业处理脚本
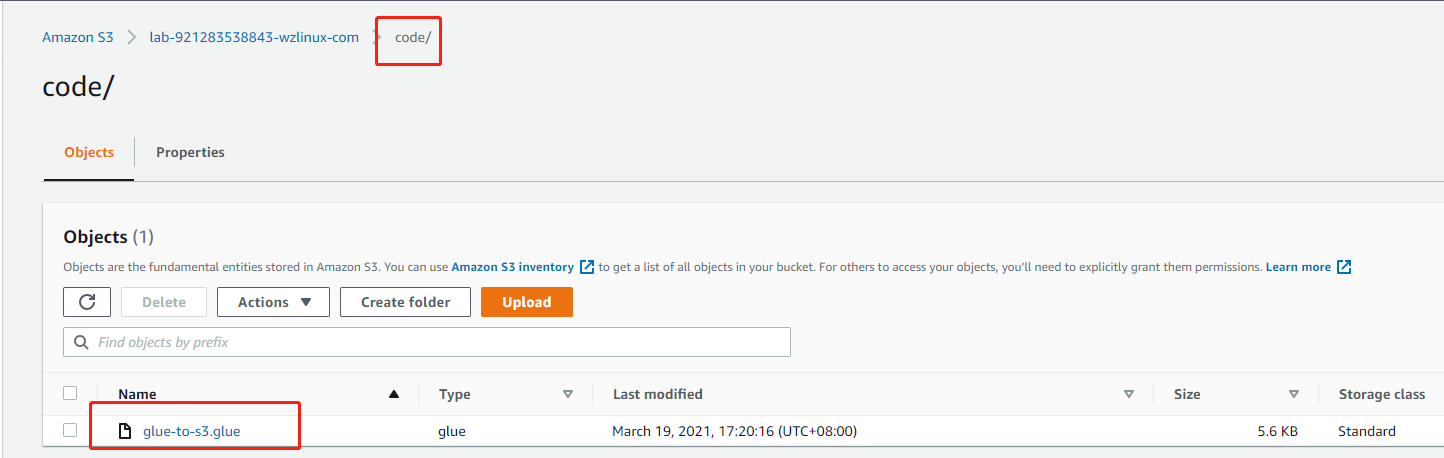
https://imgs.wzlinux.com/aws/glue-to-s3.glue
把这个脚本上传到 S3 桶内,例如
创建 ETL 作业
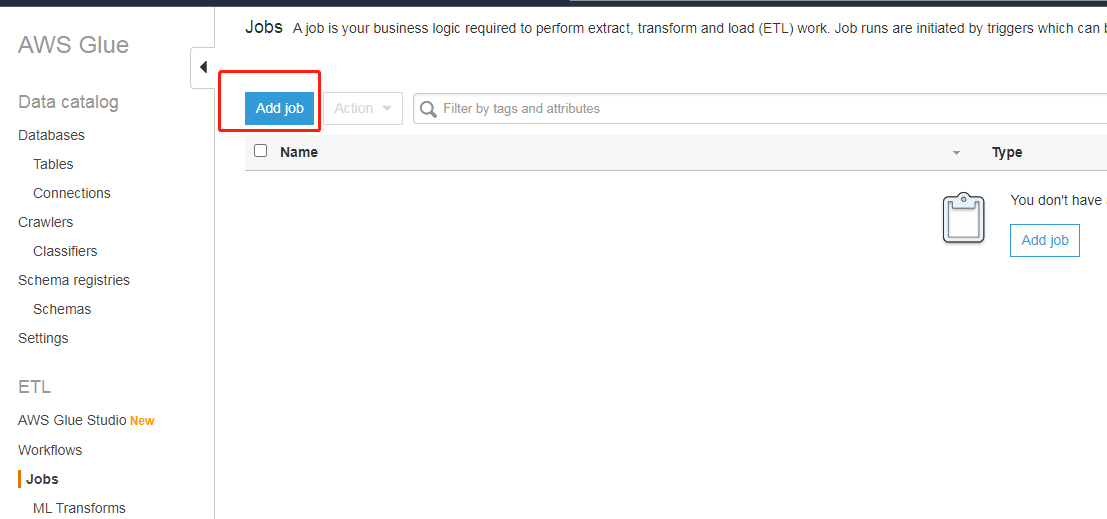
配置作业属性
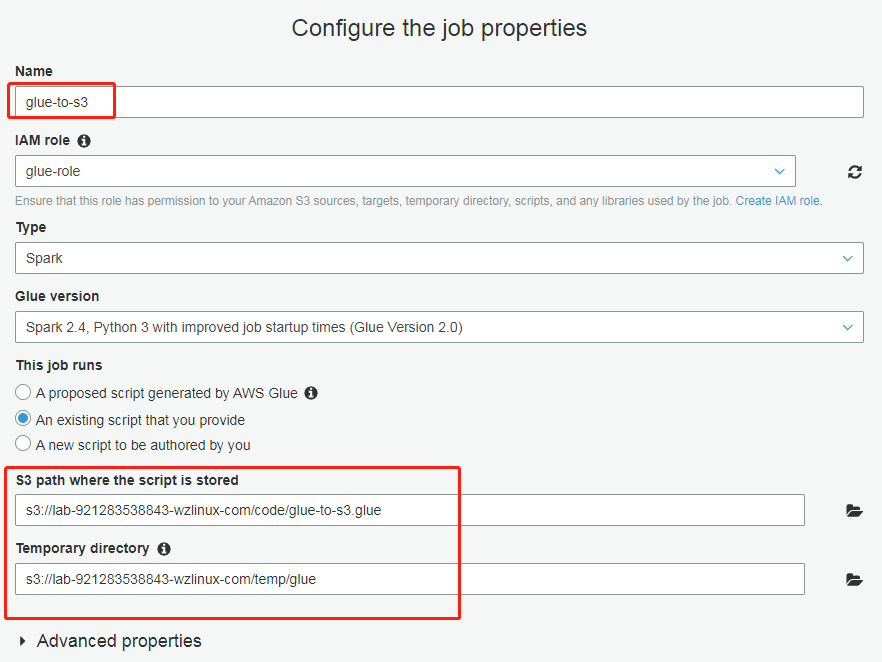
选择对应连接,然后选择“保存作业并编辑脚本”
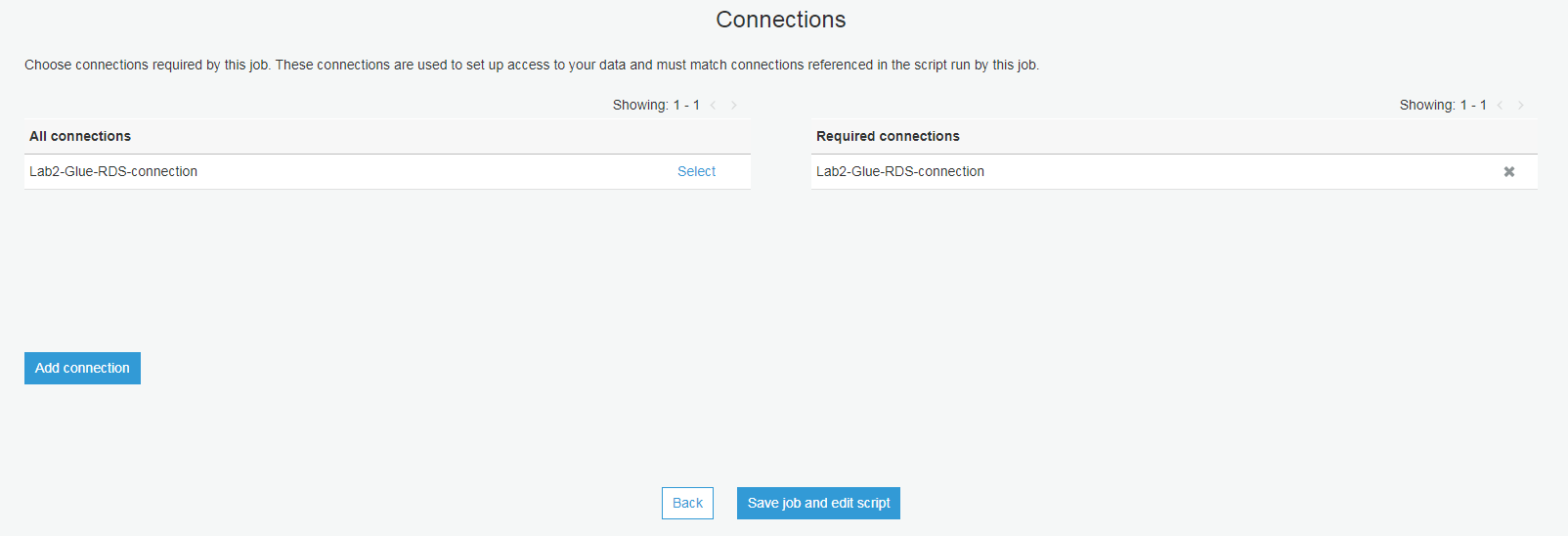
确认表名和输出位置的桶名是否正确,参考下图(一定要确认爬虫爬取出来的表名和S3桶名字的正确性)
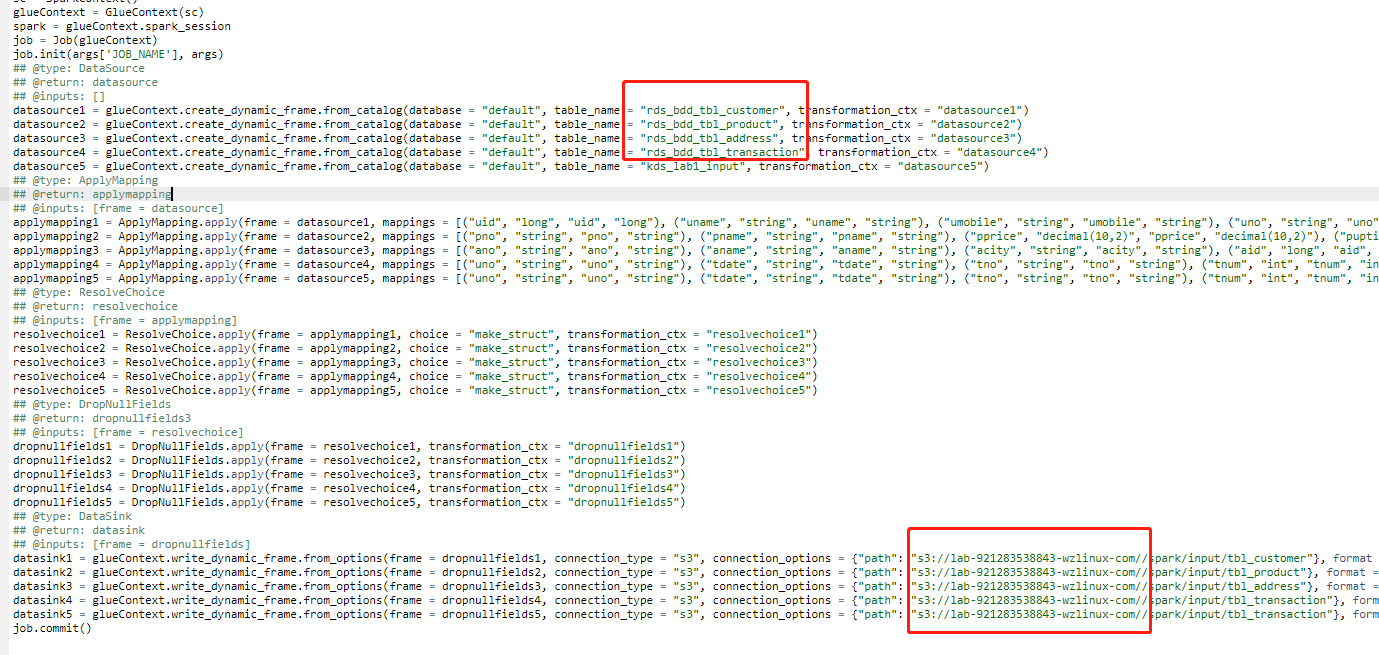
作业运行中(根据数据量不同,所需时间略有不同),考虑到 Kinesis Data Streams 在不停的打进来数据,所以每次跑 EMR 任务之前,这个都需要运行一次,否则数据就不是最新的,可以考虑按某个时间间隔(例如天)运行一次
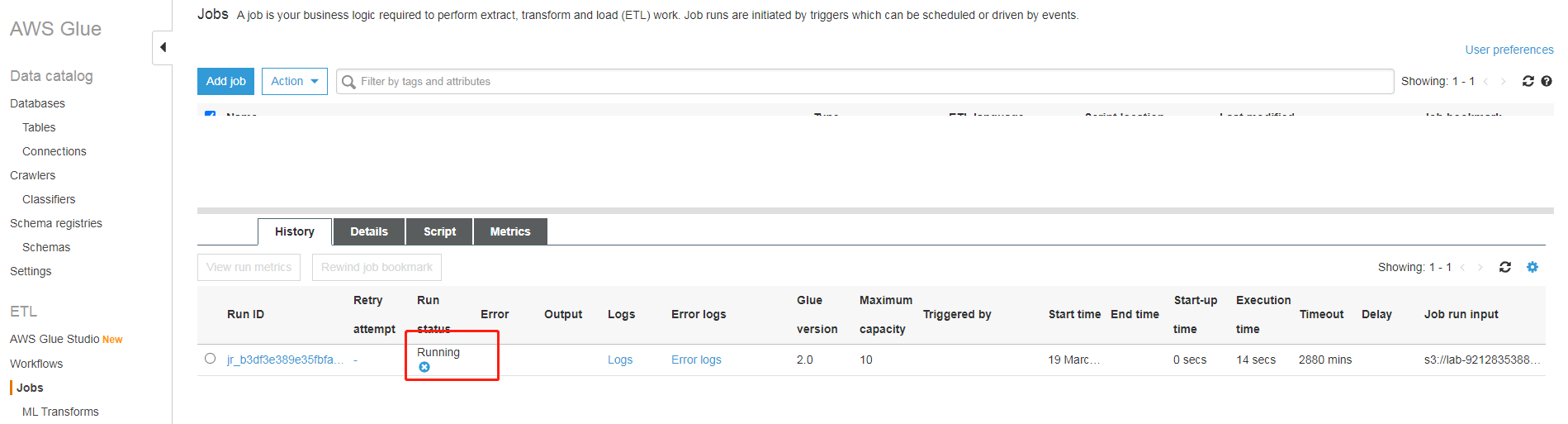
作业运行完成后,可检查s3://lab-921283538843-wzlinux-com/spark/input/目录下的"tbl_customer、tbl_product、tbl_address、tbl_transaction"文件夹中,是否产生对应的parquet格式的数据,以验证 ETL 作业是否执行成功。
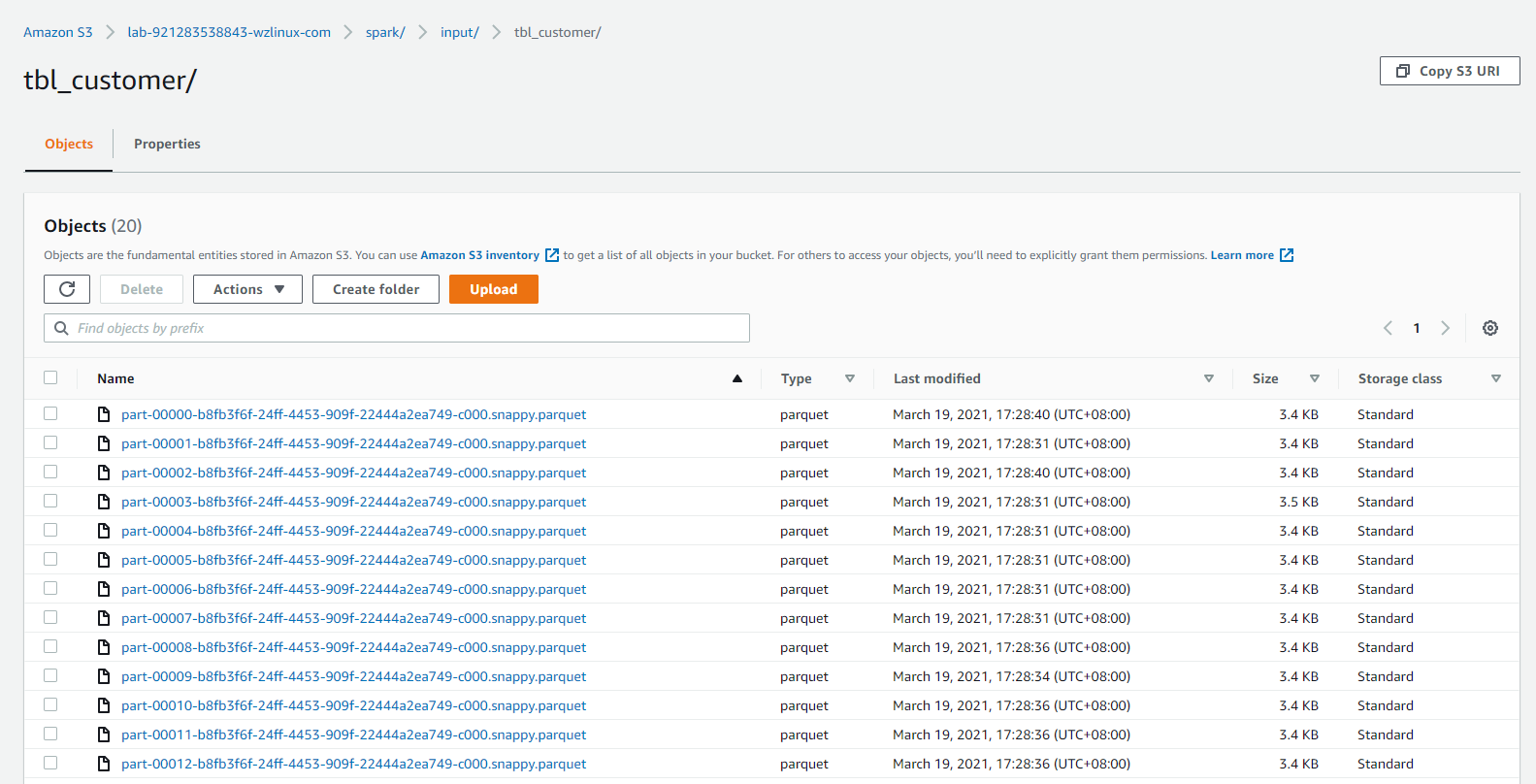
爬取合并在S3上的输出的元数据
创建名为my-lab2-crawler-s3的爬网程序
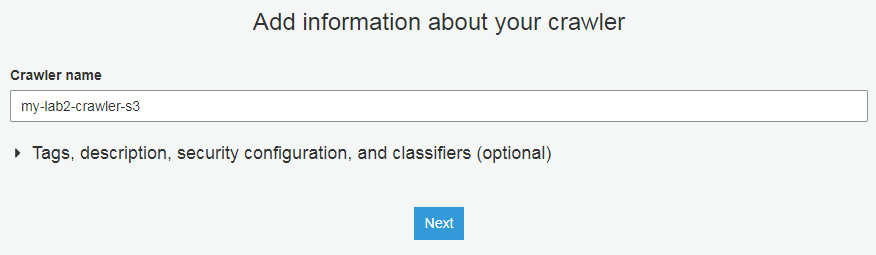
配置存储的包含路径为前一个任务的输出地(此处为:s3://lab-921283538843-wzlinux-com/spark/input)
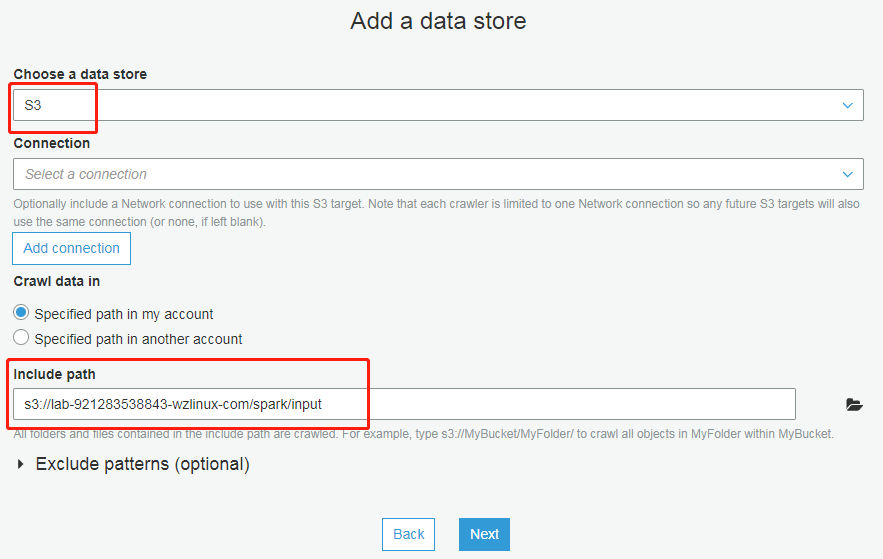
配置 IAM 角色
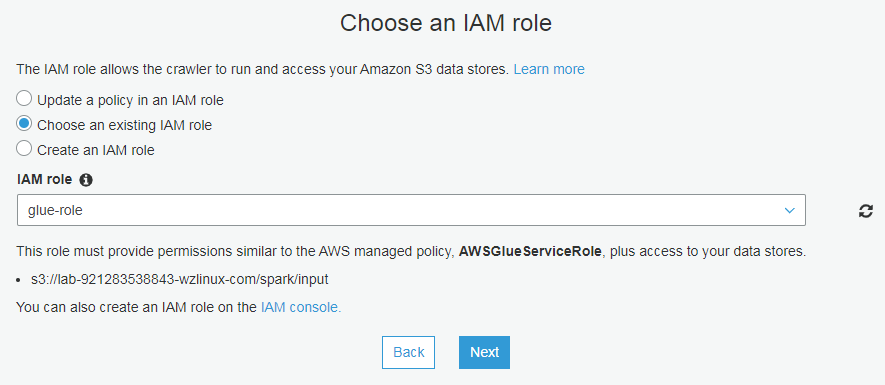
配置输出
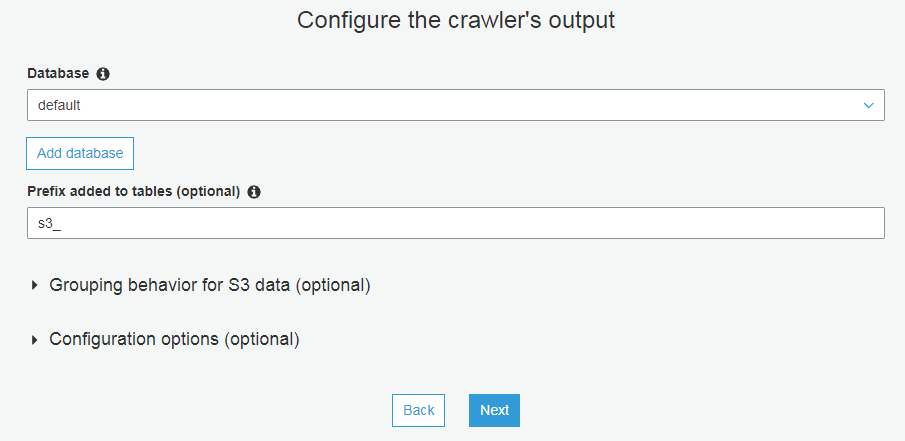
审核并确认完成。然后运行爬网程序,元数据目录中会出现 4 张 input 文件夹中数据的元数据表
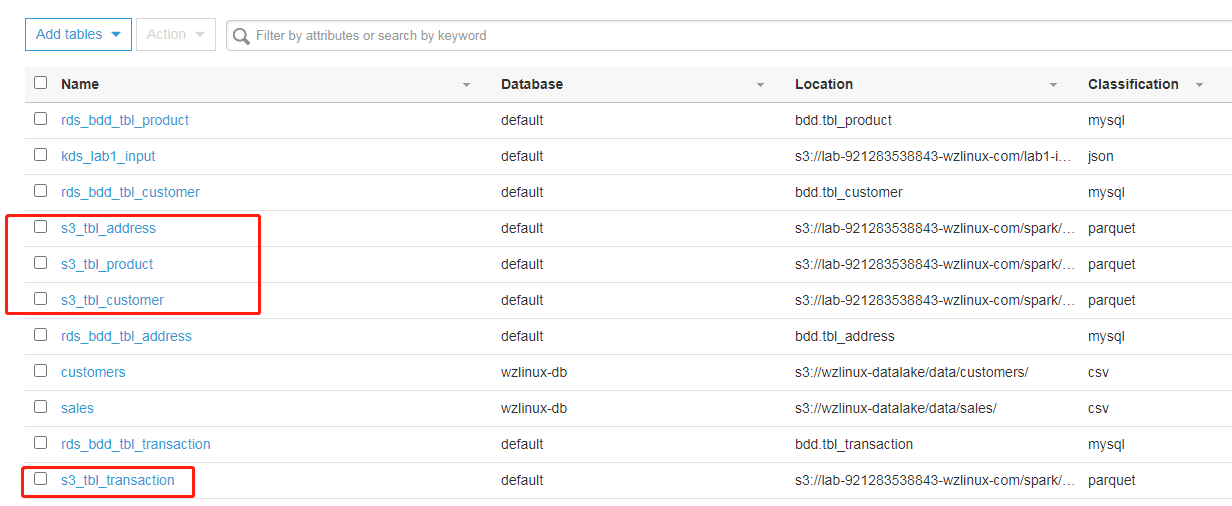
现在我们合并了历史数据,有了不断输入的流数据(如果需要实时的流数据结果,需要运行一遍上面的作业),接下来就可以开始下一步的分析数据了。
数据分析(EMR)
本实验演示数据分析的过程(Spark),数据处理(ETL)在上个章节。
登录EMR Master
如果按照实验准备的环节部署的 EMR 集群,是可以直接远程登录 Master 节点的,不过需要放开 Master 节点的 22 端口。
打开控制台关于安全组的页面(可以从VPC控制台或者EC2控制台进入),修改Master相关的安全组(此处为:sg-0b1fb24e11bcf2c16 - ElasticMapReduce-master),编辑它的入站规则,添加22端口许可,然后保存即可(其他的不要动)
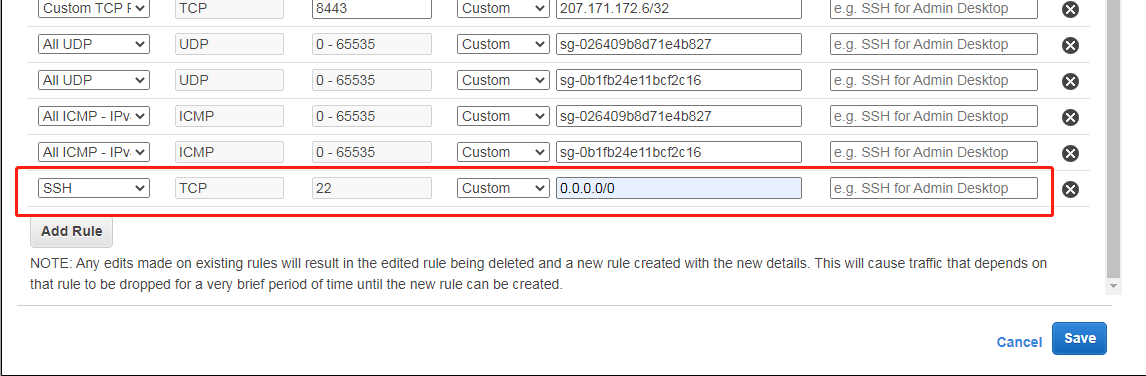
确认EMR集群状态时绿色状态,点击“Connect to the Master Node Using SSH”
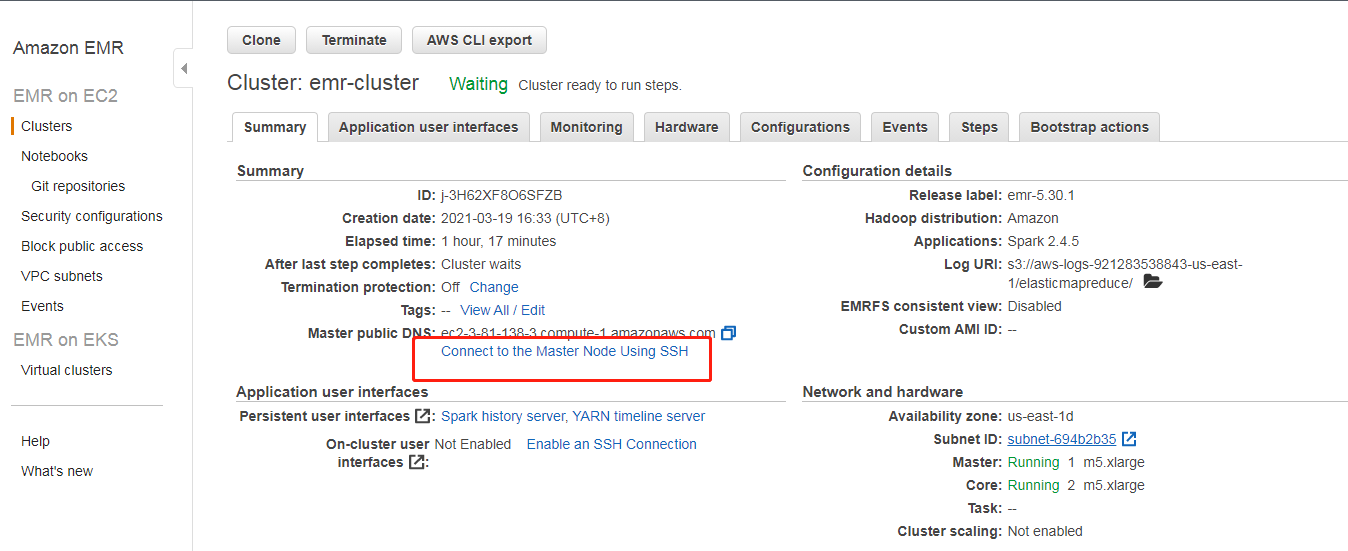
登录后如下图所示
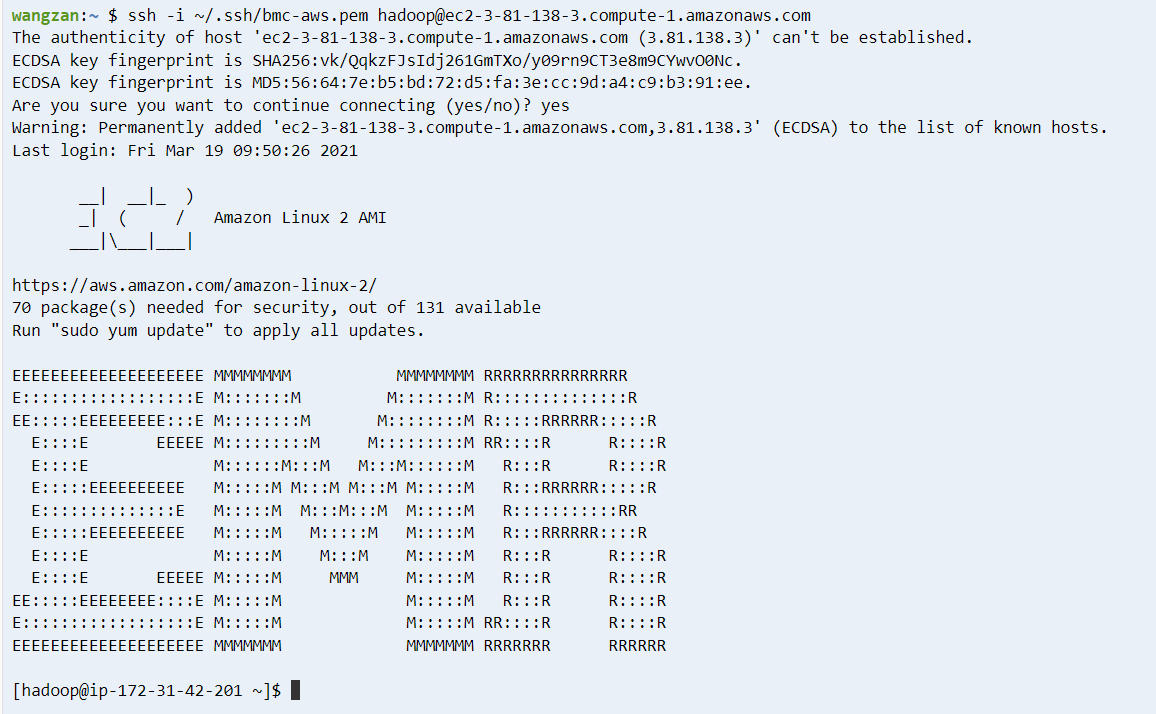
提交任务
提交任务的方式有两种,一种是 spark-shell 的方式,一种是 spark-submit 的方式。
用 spark-shell 提交
登录 Master 节点后,输入 spark-shell 命令,启动 spark-shell 环境,使用如下代码生成聚合数据集(注意检查表名称必须一致,且复制的时候别出现换行的问题–这个在 windows 下的记事本最容易出现)
val result = spark.sql("SELECT tt.tno tno, tt.tdate tdate, tt.uno uno, tt.pno pno, tt.tnum tnum, tc.uname uname, tc.umobile umobile, ta.ano ano, ta.acity acity, ta.aname aname, tp.pclass pclass, tp.pname pname, tp.pprice price FROM s3_tbl_transaction tt, s3_tbl_customer tc, s3_tbl_address ta, s3_tbl_product tp WHERE tp.pno = tt.pno and tt.uno = tc.uno and tc.ano = ta.ano ORDER BY tt.tuptime desc");然后查询 schema 是否符合我们预期
result.printSchema();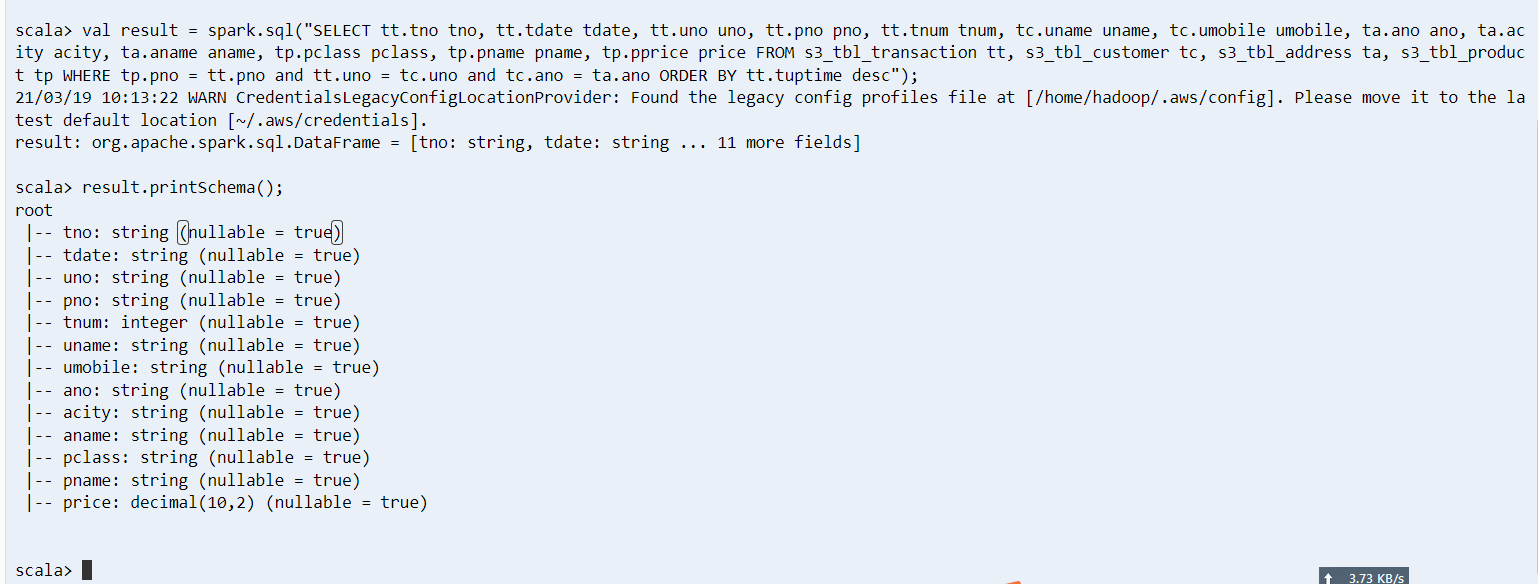
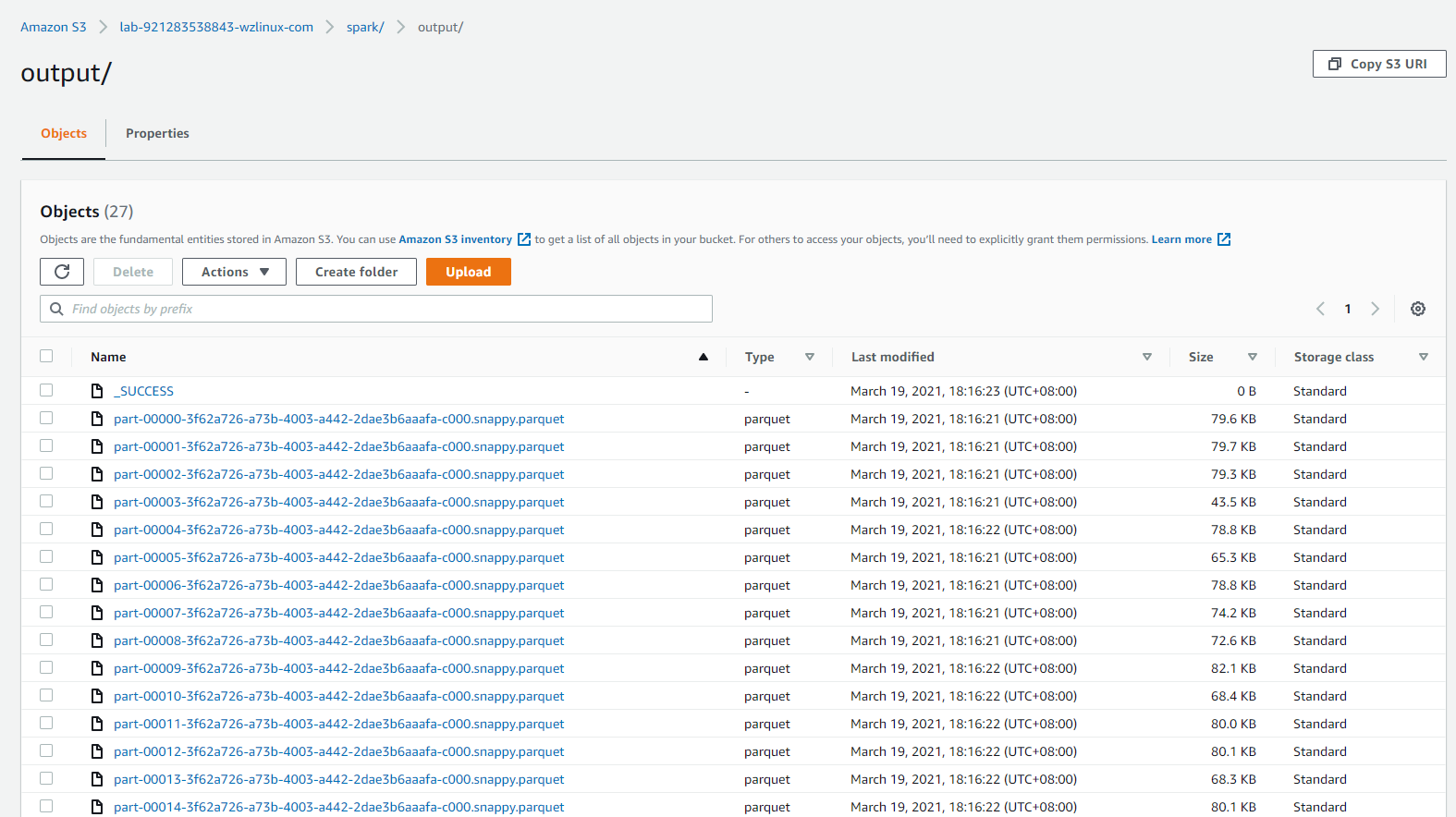
接下来把结果输出到S3即可(注意S3桶的名称)
result.write.format("parquet").mode("append").save("s3://lab-921283538843-wzlinux-com/spark/output");去对应S3目录(s3://lab-921283538843-wzlinux-com/spark/output)查看是否正常输出结果(这些结果会在Lab3里面用到)。
用spark-submit提交(可选)
我们已经准备好java实验代码,可以从这里下载并上传到S3上(例如上传保存在s3://921283538843-wzlinux-com/code/spark/)
https://imgs.wzlinux.com/aws/original-emr-0.0.1-SNAPSHOT.jar
登录Master节点后,输入spark-submit 提价任务(注意,为了不和上面 spark-shell 提交的任务冲突,我们把这个任务的结果保存到 output2 目录下了,如果哪个同学还处于上一步的spark-shell环境中,记得退出到 shell 环境中)
spark-submit --master yarn --deploy-mode client --class com.demo.emr.spark.Lab2 s3://lab-921283538843-wzlinux-com/code/spark/original-emr-0.0.1-SNAPSHOT.jar s3://lab-921283538843-wzlinux-com/spark/output2如果在此期间没有去重复执行 glue 的合并数据的作业的话,这个输出结果跟上面的结果是一致的
至此,批量处理数据的实验我们也已经完成了。
欢迎大家扫码关注,获取更多信息

标签:s3,AWS,Lab2,tbl,数据处理,spark,Glue,数据,S3 来源: https://blog.51cto.com/wzlinux/2670705