【AKD】2020-CVPR-Search to Distill Pearls are Everywhere but not the Eyes-论文阅读
作者:互联网
AKD
2020-CVPR-Search to Distill Pearls are Everywhere but not the Eyes
- Institute:Google AI,Google Brain,CUHK
- Author:Yu Liu,Xuhui Jia,Mingxing Tan
- GitHub:/
- Citation: 13
Introduction
在RL的NAS方法基础上,在评估阶段,使用蒸馏对采样的子网进行训练少量epoch,使RL可以生成性能越来越好的模型
Architecture-aware Knowledge Distillation (AKD) approach
Motivation
传统的 KD,都是在参数层面上将 teacher 的参数知识迁移到 student 的参数上,但作者发现 teacher 还存在结构知识,即尽管传统的KD方法可以让 student 学到参数知识,但不一定能学到结构知识。
传统的KD,对于给定的 teacher,都是使用 pre-define 的 student,但 teacher 和 student 之间可能不是最佳匹配,即 student 无法学到 teacher 的结构知识,即 teacher 和 student 在结构上也需要一定的匹配。
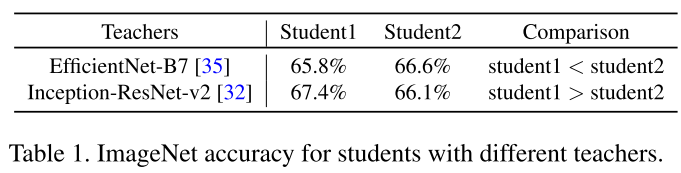
从以上结果可以得出,student 的相对性能和所选择的 teacher 有关
本文的目标就是针对给定的 teacher,搜索适合该 teacher 的最佳的 student 结构,即该 student 更最大限度的学习到 teacher 的结构知识
Teacher-Student relationship
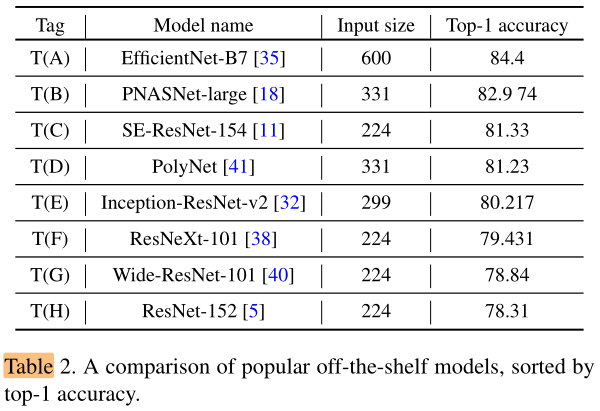
不同的 teacher network 的性能:
随机选择5个(在one-hot label下训练的性能相似的)student network:
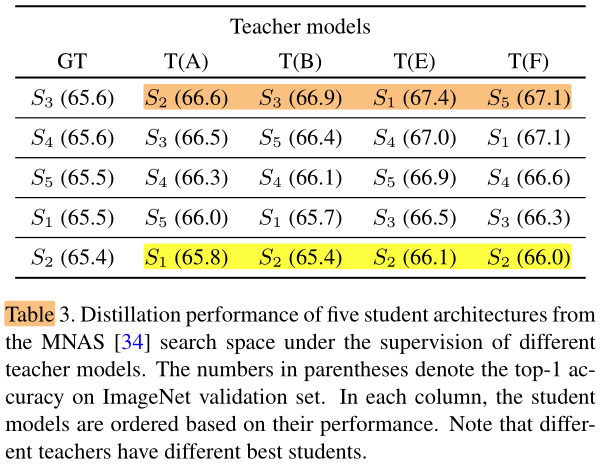
表3可以看出:
- 没有哪个 student 在不同的teacher指导下,获得一致的最高性能
- teacher 的性能和 student 的性能没有必然关系
Contribution
Method
基于RL的NAS:NASNet
- RL从模型空间中采样 model
- 正常训练每个 sample 5 个 epoch
- 计算 classification-guided reward,更新 RL
基于RL+KD的NAS:**AKDNet **
- RL从模型空间中采样 model
- 使用 teacher 蒸馏训练每个 sample 5 个 epoch
- 计算 KD-guided reward,更新RL
reward包含2部分:latency + acc 的加权求和
对 teacher 有更高匹配度的模型,在第2步中就会有更高的acc,使得RL会生成能从teacher中收益更多的模型
Experiments
Cost
In each searching experiment, the RL agent samples ∼10K models
the searching time of AKD is 3∼4 times longer than the conventional NAS
Each experiment takes about 5 days on 200 TPUv2 Donut devices
Setup
- teacher:Inception-ResNetv2
- latency:measure in Pixel 1 phone
- search: RL agent sample ∼10K models
- retrain:pick (meet latency constant) top models,(w/, w/o KD) train 400 epochs
searching process

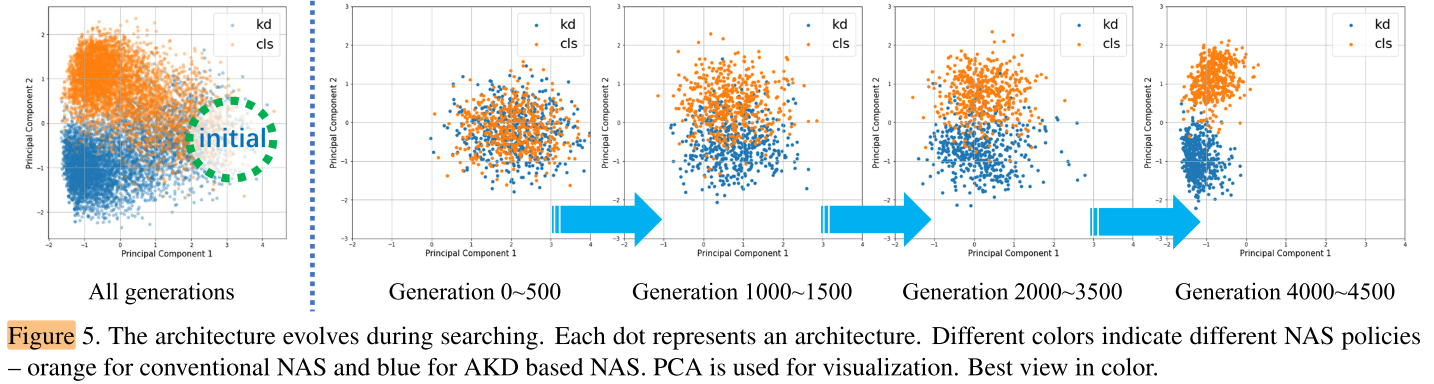
AKDNet 和 NASNet 会收敛到搜索空间中不同的区域
Understanding the structural knowledge
Existence of structural knowledge
以上的方法都基于一个假设:即 teacher network 中包含结构知识,不同student对结构知识的学习能力是有限的
如何证明 teacher network 中结构知识的存在?回答2个问题:
- 2个初始状态相同的 RL agents 使用2个不同的 teacher 执行AKD,搜索的到 student 结构是否会收敛到不同的区域?
- 2个初始状态不同的 RL agents 使用相同的 teacher 执行 AKD,搜索到的 student 结构是否会收敛到相同的区域?
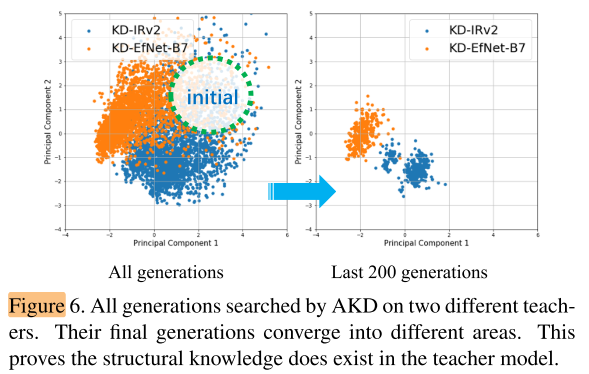
Different teachers with same RL agent
- Teacher:Inception-ResNetv2,EfficientNet-B7
- RL agent:same random seed, same mini-train / mini-val split
Same teacher with different RL agent
- Teacher:Inception-ResNetv2
- RL agent:different random seed, different mini-train / mini-val split
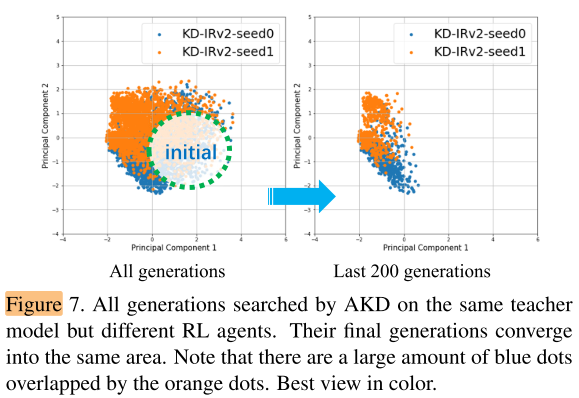
图6和图7说明了结构知识确实存在
main result
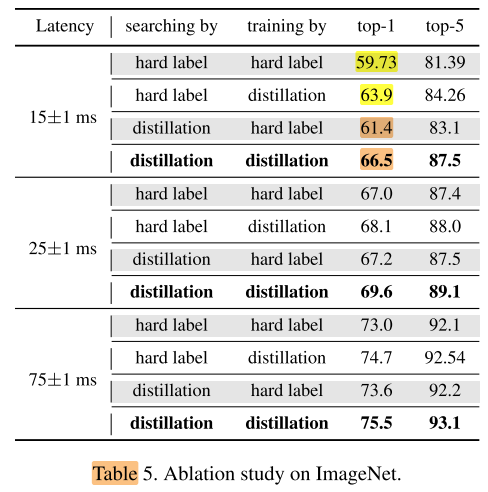
NASNet 的KD收益 = KD(NASNet) − CLS(NASNet) = 63.9 - 57.7 = 4.17(1.1/1.7)
AKDNet 的KD收益 = KD(AKDNet) − CLS(AKDNet) = 66.5 - 61.4 = 5.1 (2.4/1.9)
说明AKDNet 更容易从KD中获益(KD-friendly)
AKDNet对其他KD方法的适应性
以上在retrain阶段都是使用标准KD,在retrain阶段改为更强的KD方法,说明AKDNet对不同KD方法的适应性:
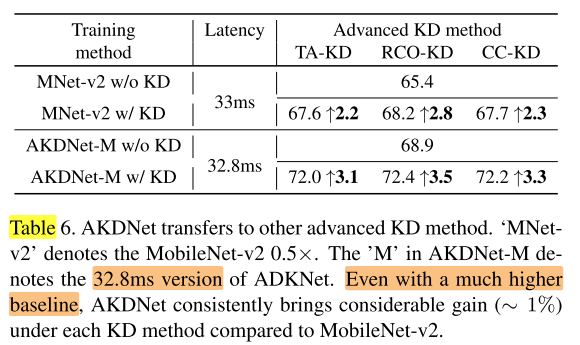
在相同的 latency 下,AKDNet 在 baseline 已经很高的情况下,还是在3中KD方法中都获得了更高的收益,即 AKDNet 可以在 retrain+KD 下获得更高的收益与 retrain 时使用的KD方法无关。
Compare with SOTA architectures
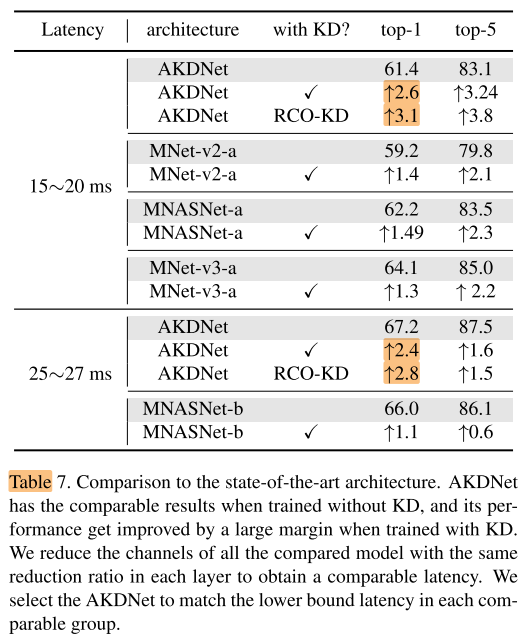
与 MNASNet 相比,AKDNet 依然在 KD 中可以获得更高的收益
Conclusion
Summary
pros:
- 证明了 KD 中 teacher network 的结构知识确实存在
- 对于给定的 teacher,存在对该 teacher KD-friendly 的 student 网络,合适的 student 可以更好地学习 teacher 的结构知识
- 实验很丰富
cons:
- 没有使用任何降低计算开销的方法(如supernet),使用简单粗暴的 RL sample,计算开销非常大
To Read
Reference
https://blog.csdn.net/luzheai6913/article/details/106391507
https://zhuanlan.zhihu.com/p/93351373
https://zhuanlan.zhihu.com/p/93287223
标签:Search,KD,Pearls,知识,Eyes,AKDNet,student,RL,teacher 来源: https://www.cnblogs.com/chenbong/p/14545815.html