Packet fragmentation and segmentation offload in UDP and VXLAN
作者:互联网
对于以太网,每个传输的数据帧的大小受限于PMTU,PMTU一般为1500字节(不包括L2 header本身)。当应用层下发的数据超过PMTU(严格来说是PMTU - L4 header - L3 header)时,就会在L4/L3进行分片,保证下发给NIC的数据不会超过PMTU。当然,对于TSO/GSO/UFO,情况又不太一样。我们先看看UDP的分片过程,从而更好的理解TSO/GSO。
UDP fragmentation
老的内核通常在IP层处理IP分段,IP层可以接收0~64KB的数据。因此,当数据IP packet大于PMTU时,就必须把数据分成多个IP分段。 较新的内核中,L4会尝试进行分段:L4不会再把超过PMTU的缓冲区直接传给IP层,而是传递一组和PMTU相匹配的缓冲区。这样,IP层只需要给每个分段增加IP报头。但是这并不意味着IP层就不做分段的工作了,一些情况下,IP层还会进行分段操作,见ip_fragment。
对于UDP,分片工作主要在ip_append_data(ip_apepend_page)中完成。
Memory allocation in skb_buff
ip_append_data会创建一个或者多个skb_buff对象,每个skb_buff表示一个IP packet。并根据下面两个因素决给skb分配的内存大小:
-
<1> MSG_MORE:如果socket设置了MSG_MORE,意味着应用层还有数据要发送,所以,可以分配大一点的缓冲区(PMTU),使得后续的数据可以合并到同一个skb。
-
<2>Scatter/Gather I/O:如果NIC支持SG,分段可以更有效的方式存储至内存页面(不用每次都分配PMTU大小缓冲区)。
if ((flags & MSG_MORE) &&
!(rt->u.dst.dev->features&NETIF_F_SG))
alloclen = mtu;
else
alloclen = datalen + fragheaderlen;
///最后一个分段,考虑trailer是否存在
if (datalen == length)
alloclen += rt->u.dst.trailer_len;
如果设置了MSG_MORE且设备不支持SG,则分配PMTU大小的skb,否则,分配只需要能够容纳当前数据大小的skb。
查看NIC是否支持SG IO:
# ethtool -k eth1|grep scatter
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: off [fixed]
- IP packet that does not need fragmentation, with IPsec
不需要分片的IP packet(IPsec)的skb的内存结构:
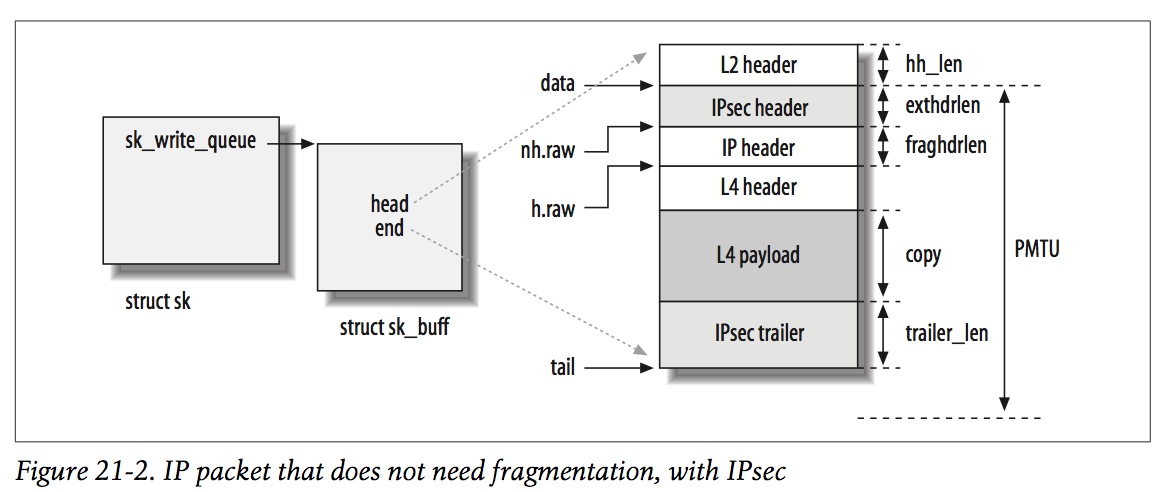
注意,对于IPsec,exthdrlen为IPsec header的长度,对于普通IP packet,exthdrlen为0。
- Fragmentation without Scatter/Gather I/O
如果设备不支持SG(Scatter/Gather I/O),会根据是否设置MSG_MORE,情况会不一样:
(1)No SG and No MSG_MORE
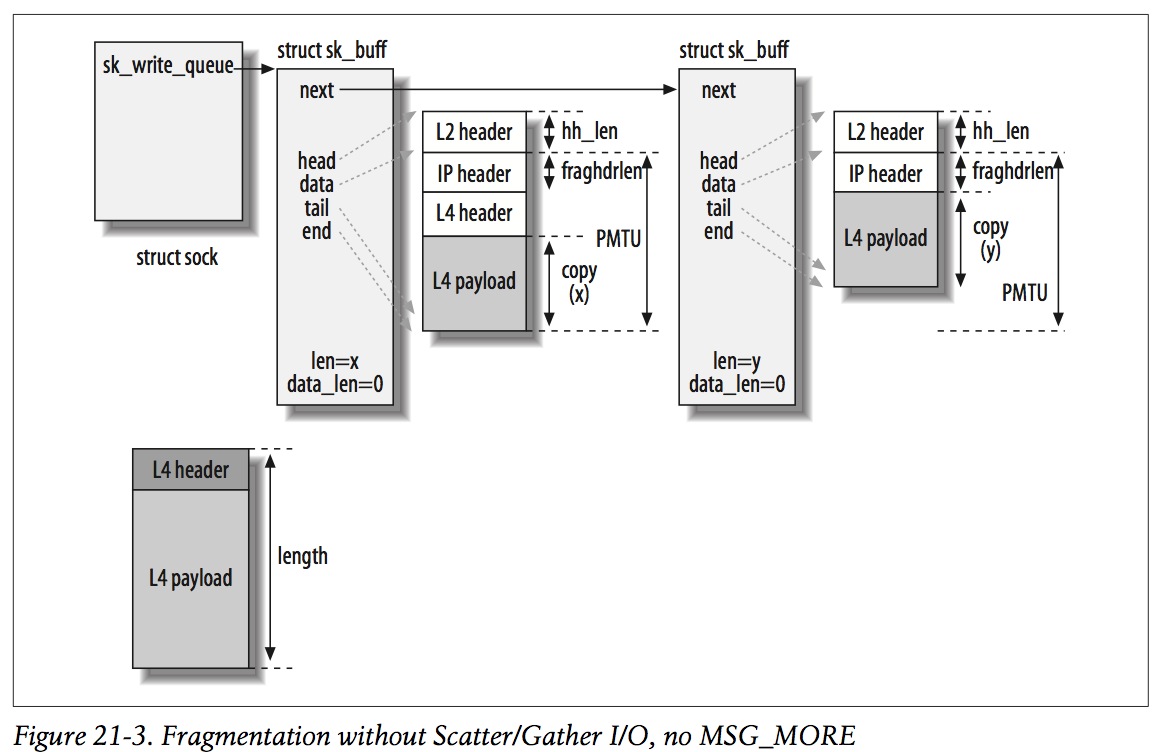
左下角的对象为ip_append_data需要处理的数据,length=x+y。由于长度(include L4 header)大于PMTU(严格来说是length+fraghdrlen > PMTU),会分成2个skb,第1个skb的大小为PMTU(include L3 header),第2个skb存储剩下的数据。
值得注意是第2个skb没有L4 header。
(2)No SG but MSG_MORE
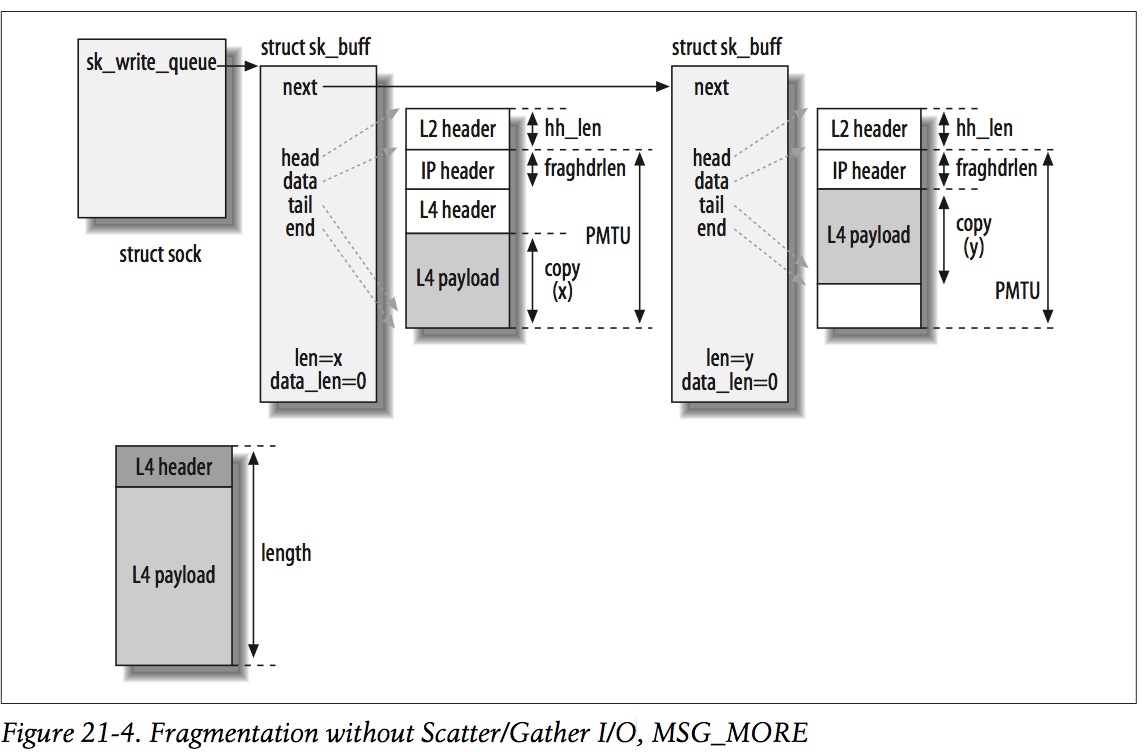
与情况(1)的区别在于,由于设置了MSG_MORE,所以第2个skb仍然分配PMTU大小的空间。当再次调用ip_append_data的时候,会先将数据填充到第2个skb的剩余空间,然后再创建第3个skb(如果第2个skb空间不够)。
- Fragmentation with Scatter/Gather I/O
如果设备支持SG,skb->data指向的内存只会在SKB第一次填充数据时才会使用(skb->data指向的内存刚好能容下第一次调用ip_append_data的数据),接着调用ip_append_data的数据会写到专门分配的内存页中。当支持SG时,第二次调用ip_append_data时,数据如下存放:
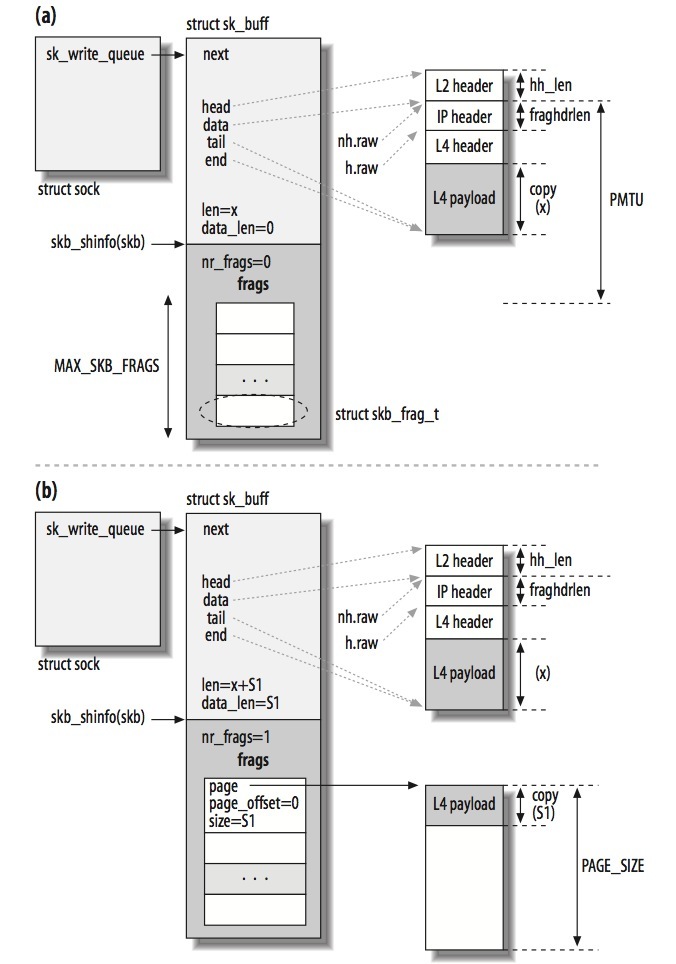
当第二次调用ip_append_data时,数据(S1)会写到由frags指向的page中。S1不需要header:skb_buff实例中的所有数据分片(fragments)都属于同一个IP packet,这也意味着X+S1仍然小于PMTU。
每个skb_buff都有一个struct skb_shared_info的字段(可以通过skb_shinfo(skb)得到)。
//include/linux/skb_buff.h
struct skb_shared_info {
unsigned char nr_frags;///frags number
...
struct sk_buff *frag_list; ///IP packet所有分段(skb)链表,在从L4->L3时,内核会将一个IP packet的所有skb对象都加到该链表
...
/* must be last field, see pskb_expand_head() */
skb_frag_t frags[MAX_SKB_FRAGS]; ///page array
};
/* To allow 64K frame to be packed as single skb without frag_list we
* require 64K/PAGE_SIZE pages plus 1 additional page to allow for
* buffers which do not start on a page boundary.
*
* Since GRO uses frags we allocate at least 16 regardless of page
* size.
*/
#if (65536/PAGE_SIZE + 1) < 16
#define MAX_SKB_FRAGS 16UL
#else
#define MAX_SKB_FRAGS (65536/PAGE_SIZE + 1)
#endif
struct skb_frag_struct {
struct {
struct page *p;
} page;
__u16 page_offset;
__u16 size;
};
skb_shared_info->frags指向这些缓冲区,nr_frags记录有多少个缓冲区(一个缓冲区一个page)最多MAX_SKB_FRAGS个,基于一个IP packet最大64KB。
如果设备不支持SG,frags数组是不会使用的,内核会按PMTU给skb->data分配内存: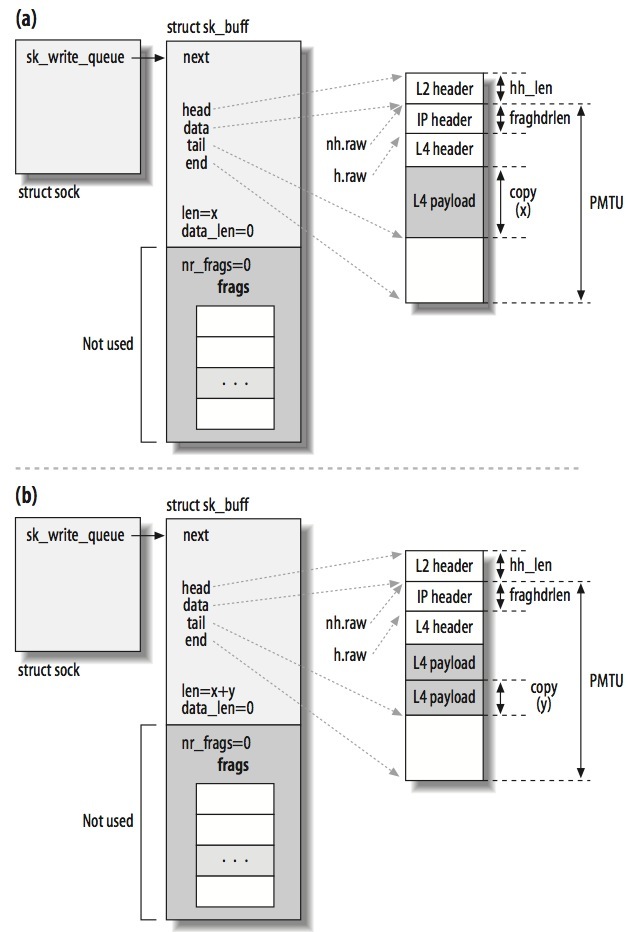
一个SKB可能包括多个skb_frag_struct,这些frags可能指向一个或者多个page。如下所示,SKB有2个frags,指向同一个page。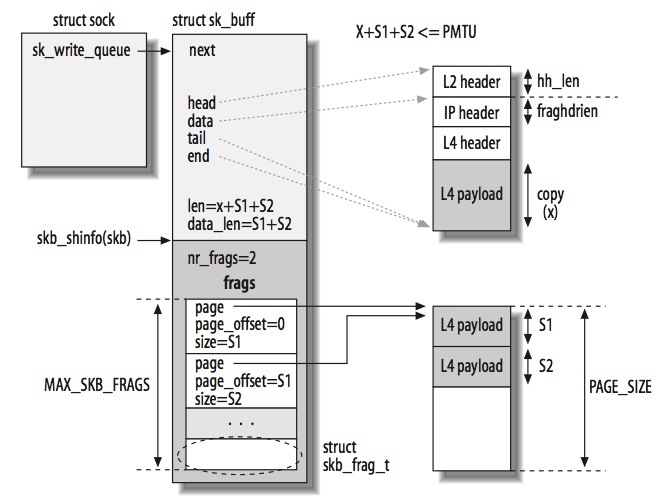
值得注意的是,SG与IP packet分段是互相独立的。SG IO只是让程序和硬件可以使用非相邻的内存区域,就像它们是相邻的那样。但是,每个IP分段必须受限于PMTU。也就是说,即使PAGE_SIZE大于PMTU,但是sk_buff的数据(skb->data所指)加上frags所引用的数据不能超过PMTU。一旦超过,就要创建新的skb_buff。
再记一遍,frags指向的分片与IP packet分段是两回事,只要设备支持SG,skb_buff就可能使用frags保存数据,
而IP packet的每个分段都对应一个skb_buff对象。
另外一个值得注意是skb_shared_info->frag_list,它表示IP packet所有分段(skb)链表,在从L4->L3时,内核会将一个IP packet的所有skb对象都加到该链表:
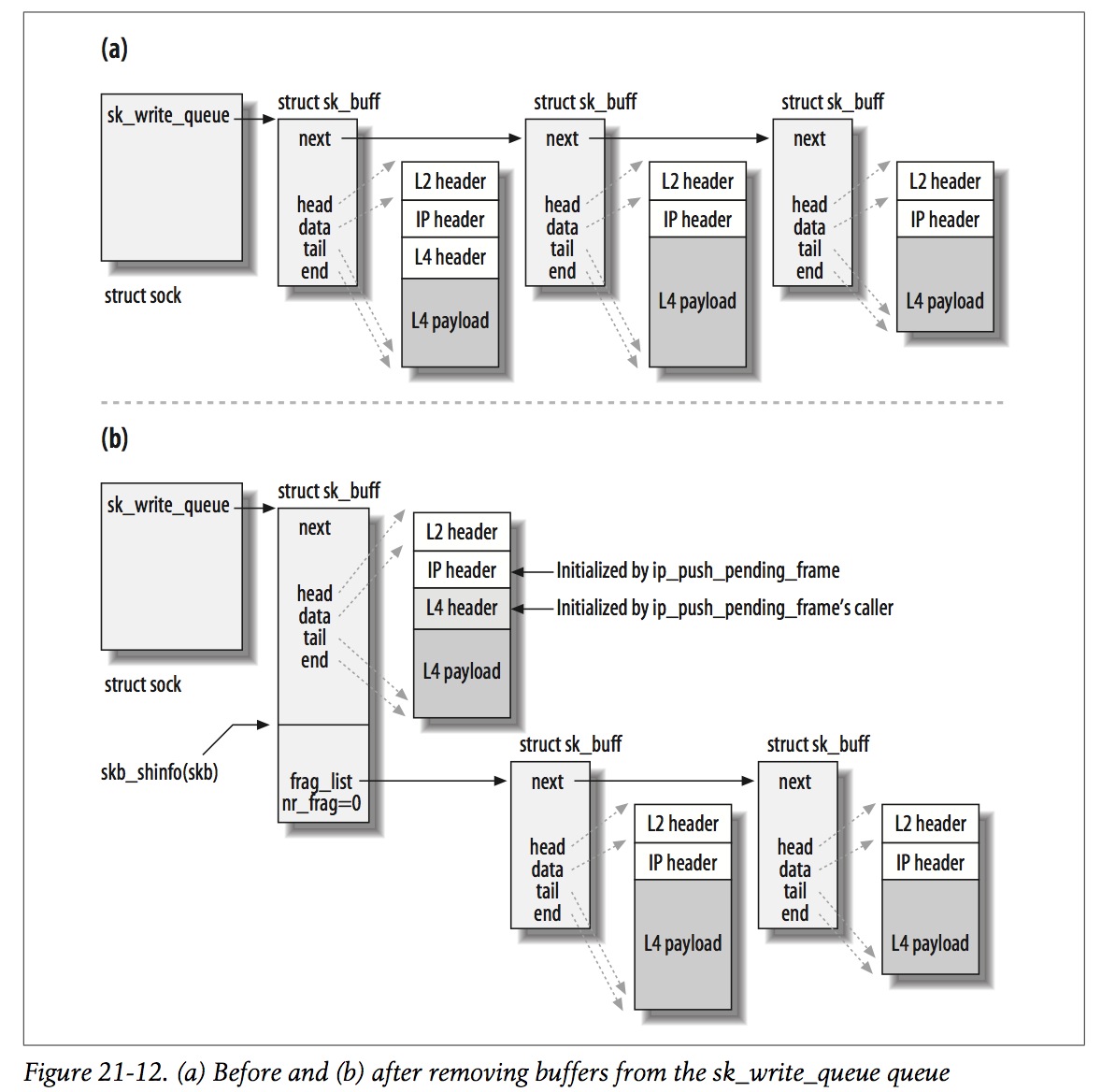
udp_push_pending_frames -> ip_finish_skb -> __ip_make_skb
/*
* Combined all pending IP fragments on the socket as one IP datagram
* and push them out.
*/
struct sk_buff *__ip_make_skb(struct sock *sk,
struct flowi4 *fl4,
struct sk_buff_head *queue,
struct inet_cork *cork)
{
...
if ((skb = __skb_dequeue(queue)) == NULL)
goto out;
tail_skb = &(skb_shinfo(skb)->frag_list);
/* move skb->data to ip header from ext header */
if (skb->data < skb_network_header(skb))
__skb_pull(skb, skb_network_offset(skb));
///move from sock->sk_write_queue to skb_shinfo(skb)->frag_list
while ((tmp_skb = __skb_dequeue(queue)) != NULL) {
__skb_pull(tmp_skb, skb_network_header_len(skb));
*tail_skb = tmp_skb;
tail_skb = &(tmp_skb->next);
skb->len += tmp_skb->len;
skb->data_len += tmp_skb->len;
skb->truesize += tmp_skb->truesize;
tmp_skb->destructor = NULL;
tmp_skb->sk = NULL;
}
...
UDP fragmentation example
发送1472字节的UDP数据,不会发生分片: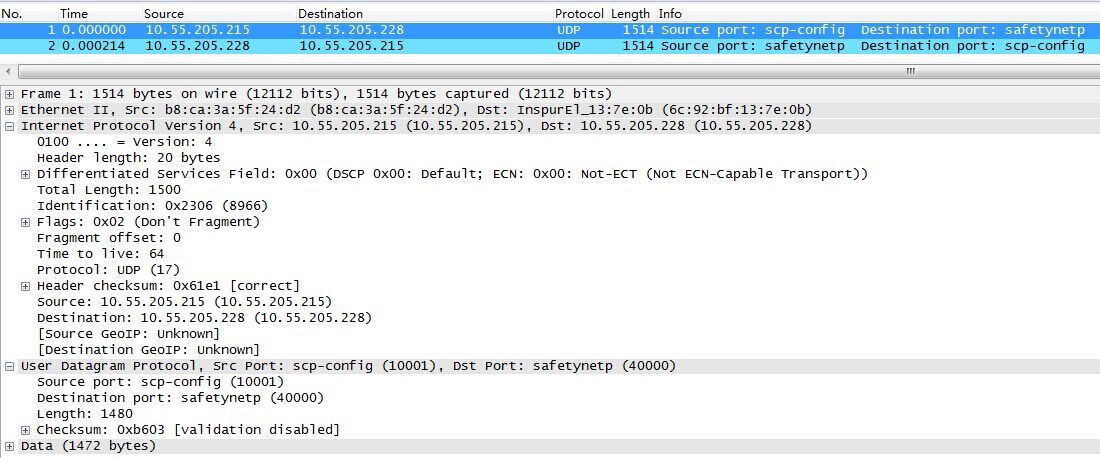
发送1473字节的时候,发生分片: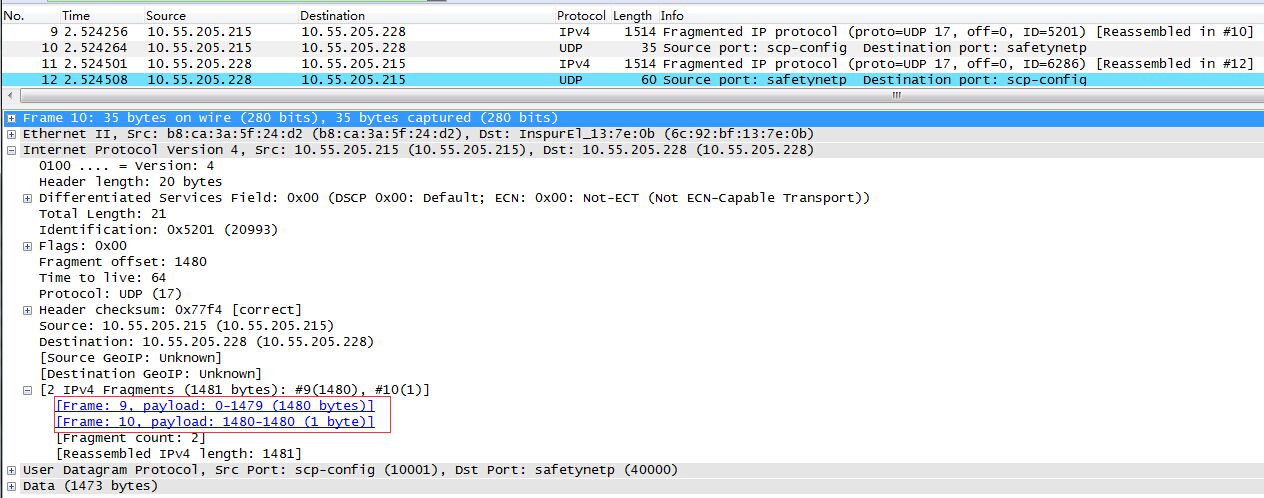
注意,第2个分片对应的frame的总长度为35字节,包括L2 header(14 bytes)、L3 header(20 bytes)、data(1 byte)。
发送过程如下: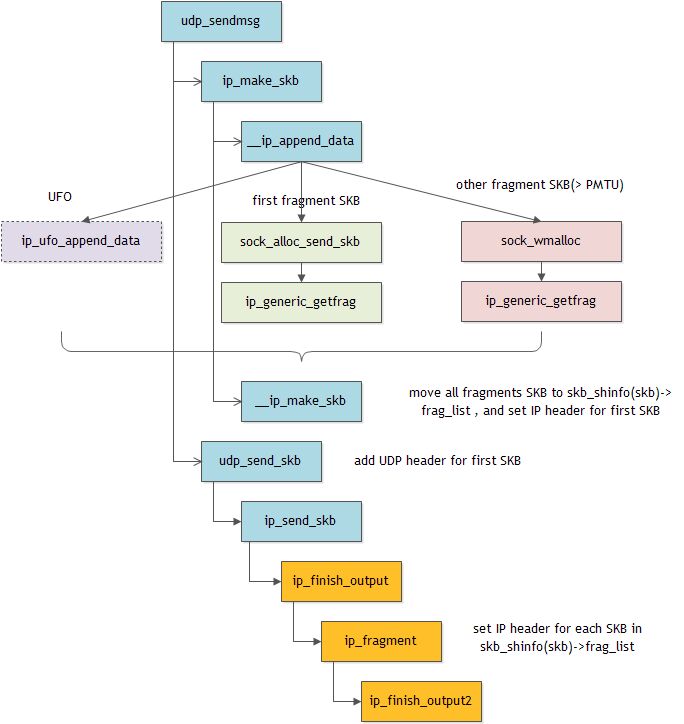
几个注意点:
(1)2个分片会创建2个skb_buff对象
(2)__ip_make_skb将除第1个SKB的其它SKB加到第1个SKB的frag_list
(3)ip_fragment对frag_list中的每个SKB设置IP header
TCP fragmentation
每个TCP数据包(segment)的大小受MSS(TCP_MAXSEG选项)限制。最大报文段长度 ( MSS )表示 TCP 传往另一端的最大块数据的长度。当一个连接建立时(SYN packet), 连接的双方都要通告各自的MSS。
一般说来,如果没有分段发生, MSS还是越大越好。报文段越大允许每个报文段传送的数据就越多,相对IP和TCP首部有更高的网络利用率。当TCP发送一个SYN时,或者是因为一个本地应用进程想发起一个连接,或者是因为另一端的主机收到了一个连接请求,它能将MSS值设置为外出接口上的MTU长度减去固定的IP首部(20 bytes)和TCP首部长度(20 bytes)。对于一个以太网,MSS值可达1460字节。详细参考tcp_sendmsg。
TCP/SCTP会将数据按MTU进行切片,然后3层的工作只需要给传递下来的切片加上 ip头就可以了(也就是说调用这个函数的时候,其实4层已经切好片了)。所以ip_queue_xmit(TCP调用该函数将数据下发至L3)的实现非常简单。
Fragmentation in L3
一般来说,L4已经根据PMTU完成分片,L3只需要给每个分片加下IP header即可。如果skb的数据长度仍然超过PMTU,L3就会进行分片,保证每个分片的大小不超过PMTU:
int ip_output(struct sk_buff *skb)
{
IP_INC_STATS(IPSTATS_MIB_OUTREQUESTS);
///大于MTU(且不支持GSO),必须在IP层进行分片
if (skb->len > dst_pmtu(skb->dst) && !skb_shinfo(skb)->tso_size)
return ip_fragment(skb, ip_finish_output);
else
return ip_finish_output(skb);
}
///skbuff.h
static inline bool skb_is_gso(const struct sk_buff *skb)
{
return skb_shinfo(skb)->gso_size;
}
有几个地方值得注意:
-
(1) 第1个skb_buff->len等于skb->data、skb_shinfo(skb)->frags和skb_shinfo(skb)->frag_list中的所有数据之和。
-
(2) 对于UDP,只有NIC支持UFO,skb_shinfo(skb)->gso_size才会被设置:
static int __ip_append_data(struct sock *sk,
struct flowi4 *fl4,
struct sk_buff_head *queue,
struct inet_cork *cork,
struct page_frag *pfrag,
int getfrag(void *from, char *to, int offset,
int len, int odd, struct sk_buff *skb),
void *from, int length, int transhdrlen,
unsigned int flags)
{
...
if (((length > mtu) || (skb && skb_has_frags(skb))) && ///len(L4 header + user data) > mtu and UFO
(sk->sk_protocol == IPPROTO_UDP) &&
(rt->dst.dev->features & NETIF_F_UFO) && !rt->dst.header_len &&
(sk->sk_type == SOCK_DGRAM)) {///UDP offload
err = ip_ufo_append_data(sk, queue, getfrag, from, length,
hh_len, fragheaderlen, transhdrlen,
maxfraglen, flags);
if (err)
goto error;
return 0;
}
...
static inline int ip_ufo_append_data(struct sock *sk,
struct sk_buff_head *queue,
int getfrag(void *from, char *to, int offset, int len,
int odd, struct sk_buff *skb),
void *from, int length, int hh_len, int fragheaderlen,
int transhdrlen, int maxfraglen, unsigned int flags)
{
struct sk_buff *skb;
int err;
/* There is support for UDP fragmentation offload by network
* device, so create one single skb packet containing complete
* udp datagram
*/
if ((skb = skb_peek_tail(queue)) == NULL) {
skb = sock_alloc_send_skb(sk,
hh_len + fragheaderlen + transhdrlen + 20,
(flags & MSG_DONTWAIT), &err);
if (skb == NULL)
return err;
/* reserve space for Hardware header */
skb_reserve(skb, hh_len);
/* create space for UDP/IP header */
skb_put(skb, fragheaderlen + transhdrlen);
/* initialize network header pointer */
skb_reset_network_header(skb);
/* initialize protocol header pointer */
skb->transport_header = skb->network_header + fragheaderlen;
skb->ip_summed = CHECKSUM_PARTIAL;
skb->csum = 0;
/* specify the length of each IP datagram fragment */
skb_shinfo(skb)->gso_size = maxfraglen - fragheaderlen; ///L4 header + user data
skb_shinfo(skb)->gso_type = SKB_GSO_UDP;
__skb_queue_tail(queue, skb);
}
return skb_append_datato_frags(sk, skb, getfrag, from,
(length - transhdrlen));
}
Segmentation offload
现在很多网卡本身支持数据分片,这样,上层L4/L3就可以不用进行分片(最大64KB),而由NIC来完成,从而提高网络性能。见NIC Offloads。
TCP Segmentation Offload (TSO)
如果网路适配器支持TSO功能,需要声明网卡的能力支持 TSO,这是通过以NETIF_F_TSO标志设置 net_device structure 的 features字段来表明,例如,在ixgbe网卡的驱动程序中,设置NETIF_F_TSO的代码如下:
static int __devinit ixgbe_probe(struct pci_dev *pdev,
const struct pci_device_id __always_unused *ent)
{
...
netdev->features |= ixgbe_tso_features();
...
static inline unsigned long ixgbe_tso_features(void)
{
unsigned long features = 0;
#ifdef NETIF_F_TSO
features |= NETIF_F_TSO;
#endif /* NETIF_F_TSO */
#ifdef NETIF_F_TSO6
features |= NETIF_F_TSO6;
#endif /* NETIF_F_TSO6 */
return features;
}
当一个TCP的socket被创建,其中一个职责是设置该连接的能力,在网络层的socket的表示是 struck sock,其中有一个字段 sk_route_caps 标示该连接的能力,在TCP的三次握手完成之后,将基于NIC的features和连接来设置该字段。
/* This will initiate an outgoing connection. */
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
...
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
...
void sk_setup_caps(struct sock *sk, struct dst_entry *dst)
{
__sk_dst_set(sk, dst);
sk->sk_route_caps = dst->dev->features;///hardware feature
if (sk->sk_route_caps & NETIF_F_GSO)
sk->sk_route_caps |= NETIF_F_GSO_SOFTWARE;
sk->sk_route_caps &= ~sk->sk_route_nocaps;
if (sk_can_gso(sk)) {
if (dst->header_len) {
sk->sk_route_caps &= ~NETIF_F_GSO_MASK;
} else {
sk->sk_route_caps |= NETIF_F_SG | NETIF_F_HW_CSUM;
sk->sk_gso_max_size = dst->dev->gso_max_size;
sk->sk_gso_max_segs = dst->dev->gso_max_segs;
}
}
}
现在,一切的准备工作都已经做好了,当实际的数据需要传输时,需要使用我们设置好的 gso_max_size,我们知道,TCP 向 IP 层发送数据会考虑 MSS,使得发送的 IP 包在 MTU 内,不用分片。而 TSO 设置的 gso_max_size 就影响该过程,这主要是在计算 mss_now 字段时使用。如果内核不支持 TSO 功能,mss_now 的最大值为”MTU – HLENS”,而在支持 TSO 的情况下,mss_now 的最大值为”gso_max_size - HLENS”,这样,从网络层到驱动的路径就被打通了。
static unsigned int tcp_xmit_size_goal(struct sock *sk, u32 mss_now,
int large_allowed)
{
...
xmit_size_goal = mss_now;
if (large_allowed && sk_can_gso(sk)) {
...
xmit_size_goal = min_t(u32, gso_size,
sk->sk_gso_max_size - 1 - hlen);
...
}
return max(xmit_size_goal, mss_now);
}
Generic Segmentation Offload (GSO)
TSO是使得网络协议栈能够将超过PMTU的数据推送至网卡,然后网卡执行分片工作,这样减轻了CPU的负荷,但 TSO 需要硬件来实现分片功能;而性能上的提高,主要是因为延缓分片而减轻了 CPU 的负载,因此,可以考虑将 TSO 技术一般化,因为其本质实际是延缓分片,这种技术,在 Linux 中被叫做 GSO(Generic Segmentation Offload),它比TSO 更通用,原因在于它不需要硬件的支持分片就可使用,对于支持 TSO 功能的硬件,则先经过 GSO 功能,然后使用网卡的硬件分片能力执行分片;而对于不支持 TSO 功能的网卡,将分片的执行,放在了将数据推送的网卡的前一刻,也就是在调用驱动的 xmit 函数前。
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq)
{
...
if (netif_needs_gso(skb, features)) {
if (unlikely(dev_gso_segment(skb, features)))///GSO
goto out_kfree_skb;
if (skb->next)
goto gso;
}
函数netif_needs_gso根据skb->gso_type和dev->features判断对当前SKB实例是否进行软件GSO。
///检查硬件的features能否满足gso_type(可能是多个组合,比如对于VXLAN包可能为SKB_GSO_UDP|SKB_GSO_UDP_TUNNEL)
///如果dev->features & gso_type = gso_type,则表明NIC满足SKB的要求.
static inline bool net_gso_ok(netdev_features_t features, int gso_type)
{
netdev_features_t feature = gso_type << NETIF_F_GSO_SHIFT;
/* check flags correspondence */
BUILD_BUG_ON(SKB_GSO_TCPV4 != (NETIF_F_TSO >> NETIF_F_GSO_SHIFT));
BUILD_BUG_ON(SKB_GSO_UDP != (NETIF_F_UFO >> NETIF_F_GSO_SHIFT));
BUILD_BUG_ON(SKB_GSO_DODGY != (NETIF_F_GSO_ROBUST >> NETIF_F_GSO_SHIFT));
BUILD_BUG_ON(SKB_GSO_TCP_ECN != (NETIF_F_TSO_ECN >> NETIF_F_GSO_SHIFT));
BUILD_BUG_ON(SKB_GSO_TCPV6 != (NETIF_F_TSO6 >> NETIF_F_GSO_SHIFT));
BUILD_BUG_ON(SKB_GSO_FCOE != (NETIF_F_FSO >> NETIF_F_GSO_SHIFT));
return (features & feature) == feature;
}
static inline bool skb_gso_ok(struct sk_buff *skb, netdev_features_t features)
{
return net_gso_ok(features, skb_shinfo(skb)->gso_type) &&
(!skb_has_frag_list(skb) || (features & NETIF_F_FRAGLIST));
}
static inline bool netif_needs_gso(struct sk_buff *skb,
netdev_features_t features)
{
return skb_is_gso(skb) && (!skb_gso_ok(skb, features) ||
unlikely((skb->ip_summed != CHECKSUM_PARTIAL) &&
(skb->ip_summed != CHECKSUM_UNNECESSARY)));
}
UDP fragmentation offload (UFO)
# ip -d link show flannel.1
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 6e:83:99:5b:8c:51 brd ff:ff:ff:ff:ff:ff
vxlan
# ethtool -k flannel.1|grep udp
udp-fragmentation-offload: on
tx-udp_tnl-segmentation: off [fixed]
static init __ip_append_data(){
...
if (((length > mtu) || (skb && skb_has_frags(skb))) && ///len(L4 header + user data) > mtu and UFO
(sk->sk_protocol == IPPROTO_UDP) &&
(rt->dst.dev->features & NETIF_F_UFO) && !rt->dst.header_len &&
(sk->sk_type == SOCK_DGRAM)) {///UDP offload
err = ip_ufo_append_data(sk, queue, getfrag, from, length,
hh_len, fragheaderlen, transhdrlen,
maxfraglen, flags);
static inline int ip_ufo_append_data(){
...
/* specify the length of each IP datagram fragment */
skb_shinfo(skb)->gso_size = maxfraglen - fragheaderlen; ///L4 header + user data
skb_shinfo(skb)->gso_type = SKB_GSO_UDP;
...
从上面的代码可以知道,如果NIC支持UFO,且数据长度length超过MTU时,就会走UFO的逻辑。
** 值得注意的是上面的length包括L4 header和user data,却没有包含L3 header,因为一般来说,考虑MTU时,应该考虑L3 header **
由于flannel.1的MTU为1450,所以,对于UDP,如果user data为1443字节,就会满足上面的条件:1443 + 8 (UDP header) = 1451。
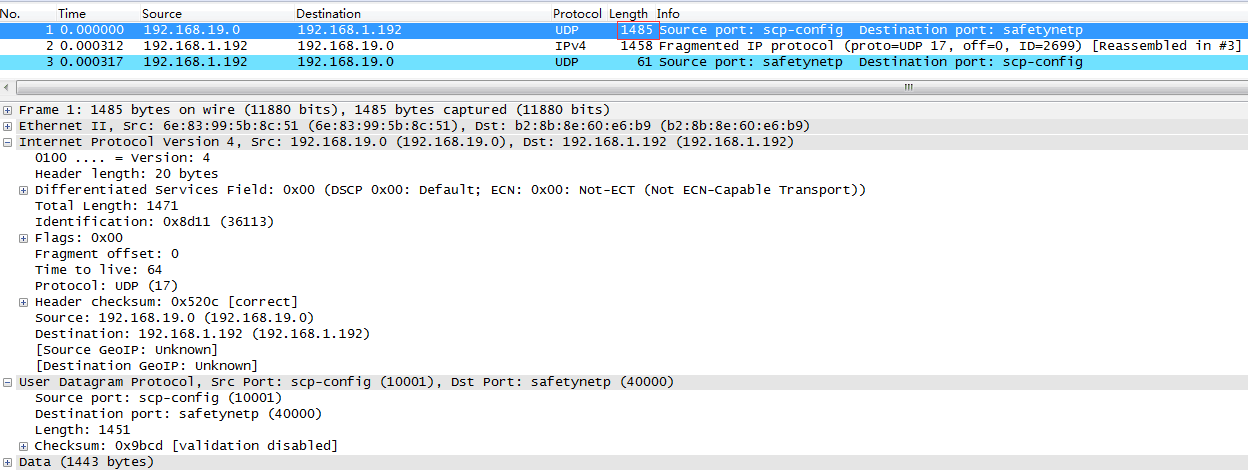
可以看到,从flannel.1来看,在发送的时候没有发生分片,但接收的时候发生了分片(???)。发送时,如果下层物理NIC不支持UFO,在将SKB推送给驱动之前,会走GSO的逻辑,完成分片操作:
对于igb/ixgbe驱动,默认都不支持UFO:
# ethtool -i eth1
driver: ixgbe
version: 4.1.1
firmware-version: 0x8000039c, 14.0.12
bus-info: 0000:01:00.1
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
supports-priv-flags: no
# ethtool -k eth1|grep udp
udp-fragmentation-offload: off [fixed]
tx-udp_tnl-segmentation: on
UDP encapsulation offload
对于UDP encapsulation packet,不会对外层UDP进行分片,只会对根据PMTU对内层packet进行分片。
GSO for UDP encapsulation packet
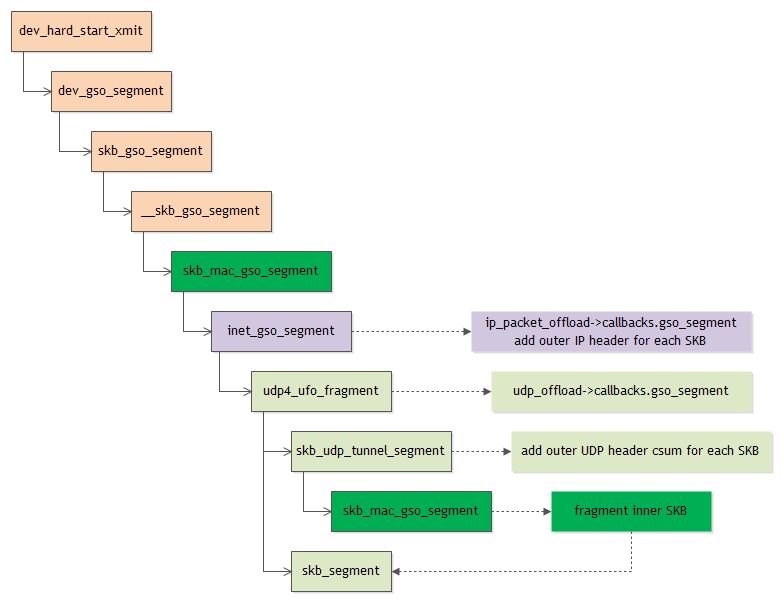
详细过程参考ixgbe.
VXLAN example
对于VXLAN,有50字节的额外开销:Outer L2 header(14 bytes) + Outer L3 header(20 bytes) + Outer UDP header(8 bytes) + VXLAN header(8 bytes)。如果underlay network的MTU为1500,需要将VXLAN设备的MTU设置为1450。
如果基于VXLAN发送一个1422字节(1450 - 20 - 8)的UDP包,内层UDP包不会发生分片: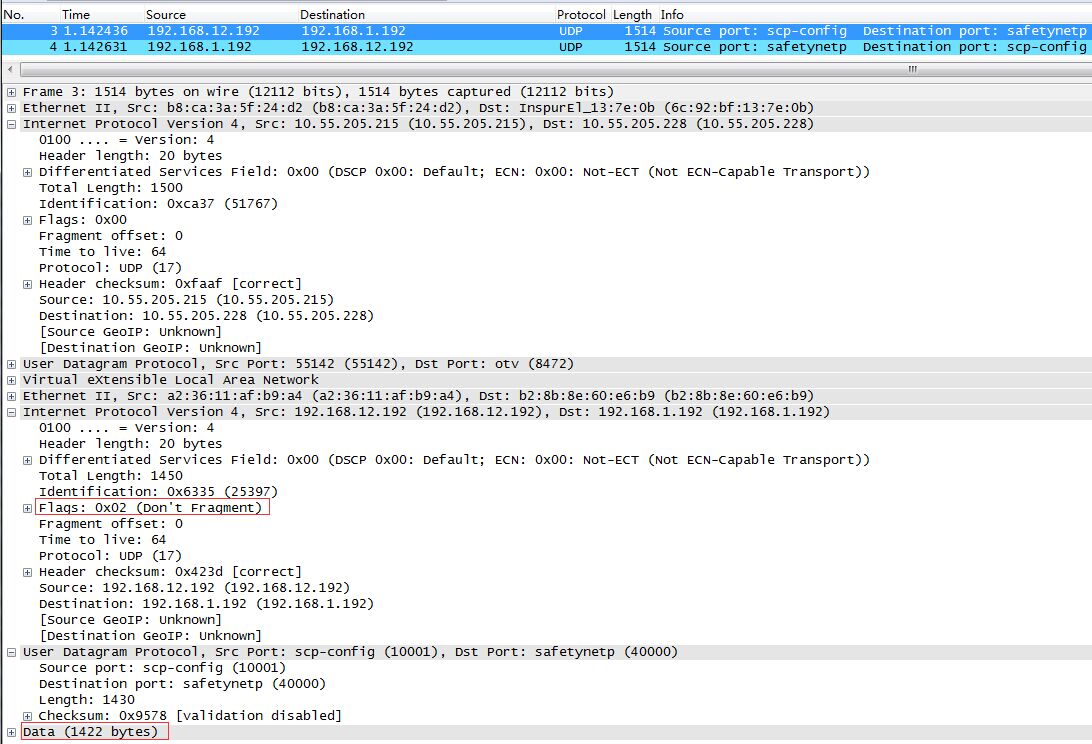
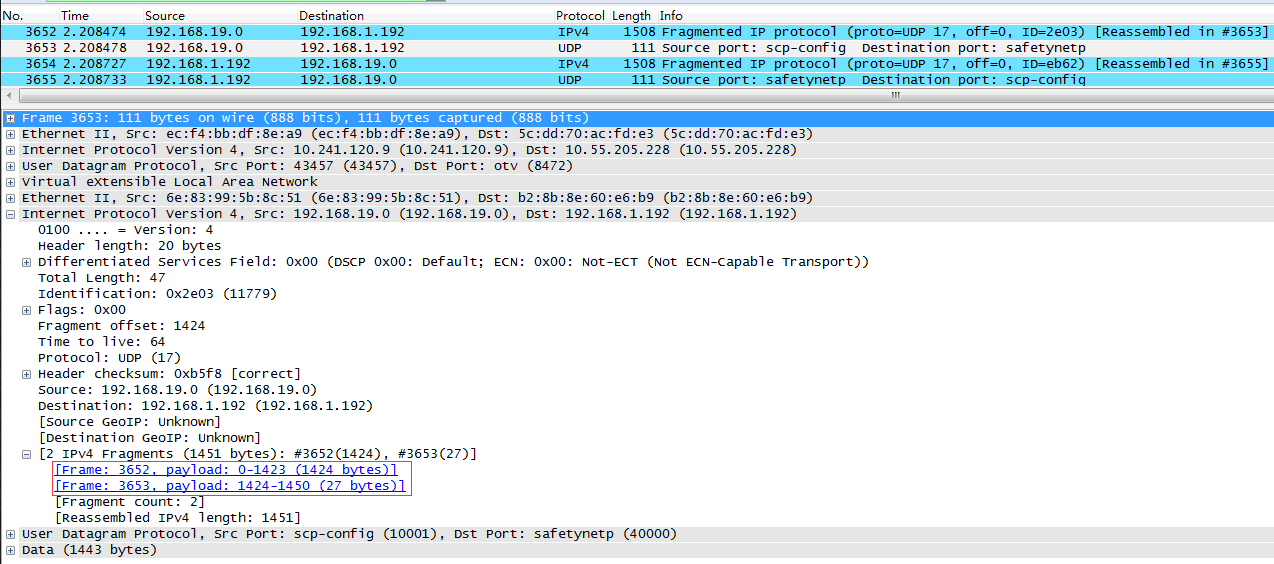
如果发送一个1423字节的UDP包,我们就会观察内层UDP包发生分片: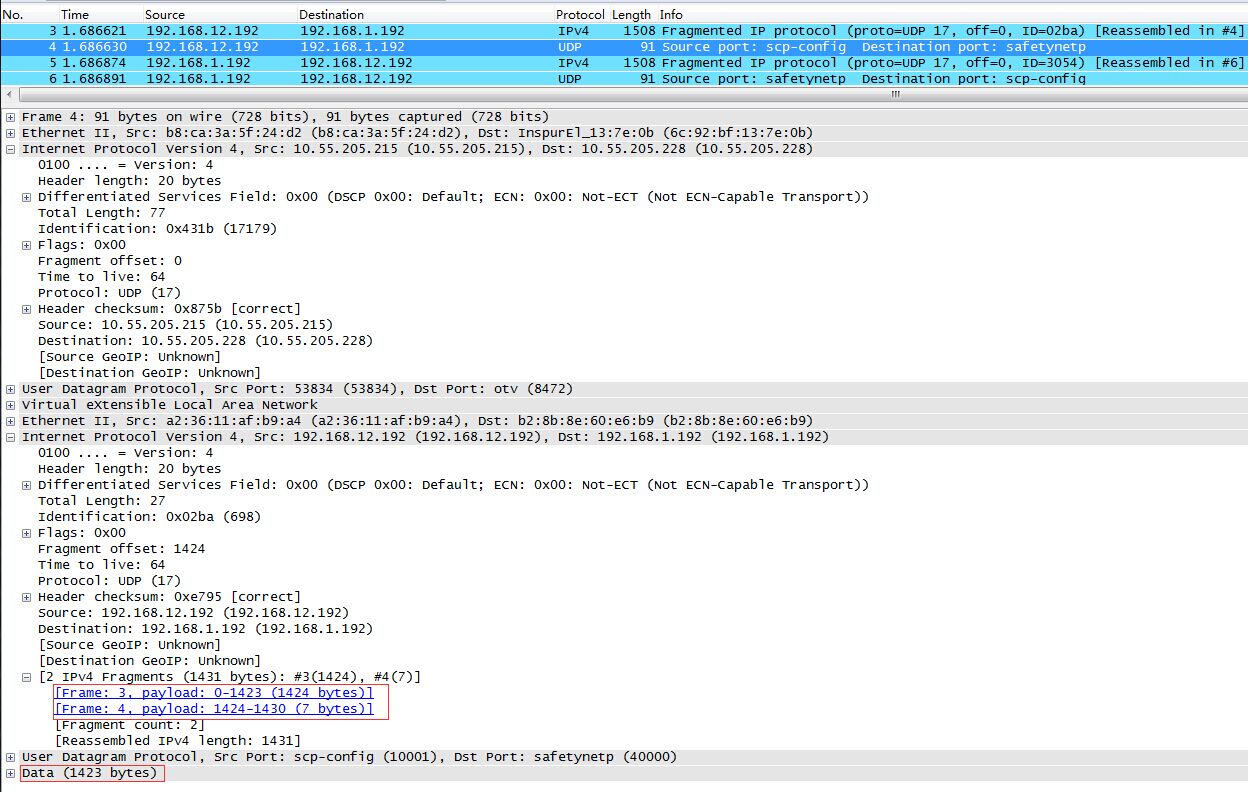
** 值得注意的是,第1个frame只有1508字节,也就是说只包含1416字节的用户数据,第2个frame包含剩下的7个字节。(原因呢???) **
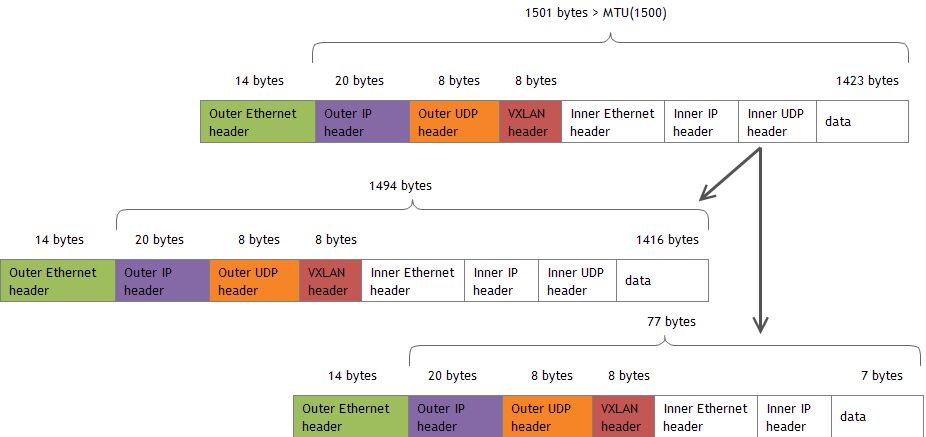
VXLAN hardware offload
Intel X540默认支持VXLAN offload:
tx-udp_tnl-segmentation: on
static int __devinit ixgbe_probe(struct pci_dev *pdev,
const struct pci_device_id __always_unused *ent)
{
...
#ifdef HAVE_ENCAP_TSO_OFFLOAD
netdev->features |= NETIF_F_GSO_UDP_TUNNEL; ///UDP tunnel offload
#endif
static const char netdev_features_strings[NETDEV_FEATURE_COUNT][ETH_GSTRING_LEN] = {
...
[NETIF_F_GSO_UDP_TUNNEL_BIT] = "tx-udp_tnl-segmentation",
VXLAN设备在发送数据时,会设置SKB_GSO_UDP_TUNNEL:
static int handle_offloads(struct sk_buff *skb)
{
if (skb_is_gso(skb)) {
int err = skb_unclone(skb, GFP_ATOMIC);
if (unlikely(err))
return err;
skb_shinfo(skb)->gso_type |= SKB_GSO_UDP_TUNNEL;
} else if (skb->ip_summed != CHECKSUM_PARTIAL)
skb->ip_summed = CHECKSUM_NONE;
return 0;
}
值得注意的是,该特性只有当内层的packet为TCP协议时,才有意义。前面已经讨论ixgbe不支持UFO,所以对UDP packet,最终会在推送给物理网卡时(dev_hard_start_xmit)进行软件GSO。
Discussion
- (1) Is it necessary to change MTU of flannel.1 to 1450 ?
对于TCP,veth/flannel.1都开启了TSO和GSO。对于inner packet > flannel.1 MTU,如果物理网卡支持VXLAN offload,最终由物理网卡完成分片;如果物理网卡不支持vxlan offload,走内核的GSO完成分片。但是,对于inner packet < flannel.1 MTU,inner packet + outer header > 物理网卡MTU,就会导致outer packet在ip_fragment中进行第二次分片,影响性能。
对于UDP,veth默认没有UFO,flannel.1开启了UFO,如果不减小flannel.1的MTU,可能会导致inner packet + outer header > 物理网卡的MTU,这可能会导致outer packet在ip_fragment中进行第二次分片,影响性能。
所以,不管怎样,减少flannel.1的MTU都是必要的。
- (2) Should enable UDP RSS for vxlan ?
Related posts
- UDP Encapsulation in Linux
- TCP/IP over VXLAN Bandwidth Overheads
- VXLAN Offload
- MTU Considerations for VXLAN
- Optimizing the Virtual Network with VXLAN Overlay Offloading
- Linux 下网络性能优化方法简析
标签:UDP,offload,struct,IP,segmentation,sk,header,skb 来源: https://www.cnblogs.com/dream397/p/14506813.html