Regularization in Deep Learning (正则化)
作者:互联网
Regularization in Deep Learning (正则化)
Table of Contents
- What is Regularization?
- How does Regularization help in reducing Overfitting?
- Different Regularization techniques in Deep Learning
- L2 and L1 regularization
- Dropout
- Data augmentation
- Early stopping
- Case Study on MNIST data using Keras
What is Regularization?
Before we deep dive into the topic, take a look at this image:
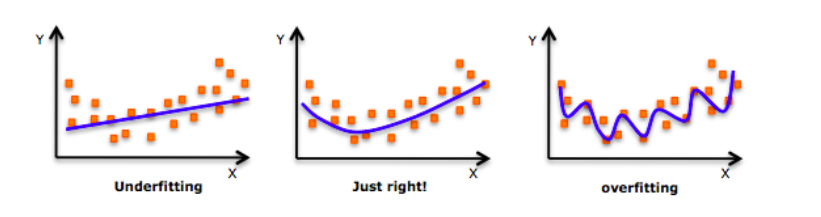
Have you seen this image before? As we move towards the right in this image, our model tries to learn too well the details and the noise from the training data, which ultimately results in poor performance on the unseen data.
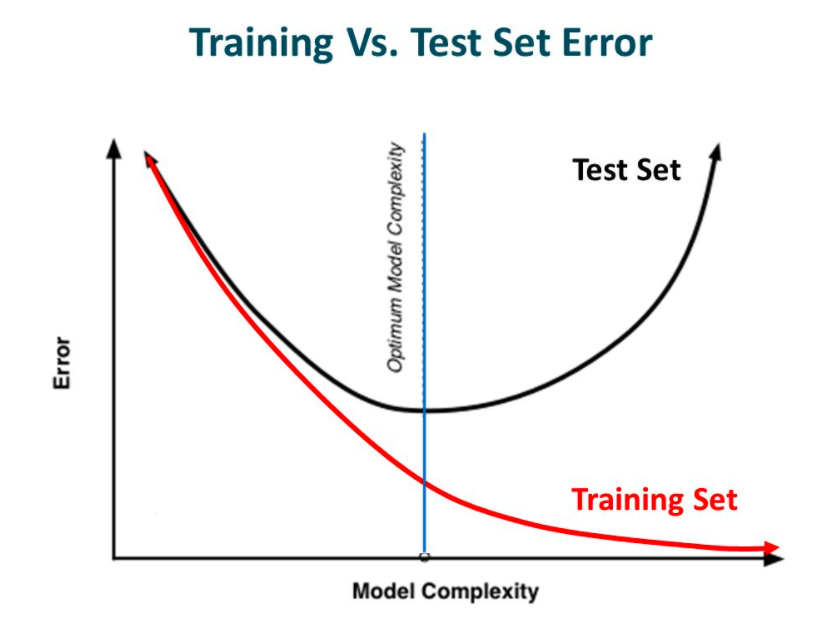
In other words, while going towards the right, the complexity of the model increases such that the training error reduces but the testing error doesn’t. This is shown in the image below.
If you’ve built a neural network before, you know how complex they are. This makes them more prone to overfitting.

Regularization is a technique which makes slight modifications to the learning algorithm such that the model generalizes better. This in turn improves the model’s performance on the unseen data as well.
标签:Regularization,image,Deep,Learning,model,data 来源: https://www.cnblogs.com/BlairGrowing/p/14456711.html