数据仓库--拉链表
作者:互联网
拉链表
记录历史数据的每个状态,记录一个事物从开始,一直到当前状态的所有变化的信息
拉链表通常是对账户信息的历史变动进行处理保留的结果
拉链表形成过程
订单当日全部数据和mysql中每天变化的数据拼接在一起,形成一个新的临时拉链表数据
用临时的拉链表覆盖旧的拉链表数据(这就解决了hive表中数据不能更新的问题)
拉链表就增加了两个字段信息:有效开始日期和有效结束日期
拉链表简单实例(转自知乎 https://zhuanlan.zhihu.com/p/75070697)
用户表(user)

用户表的变化过程如下:
- 2019-07-01日用户A注册

- 2019-07-02日用户B注册但是手机号码未填写
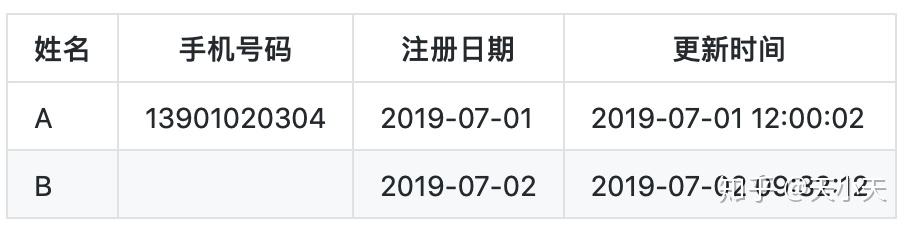
- 2019-07-02日A修改手机号码
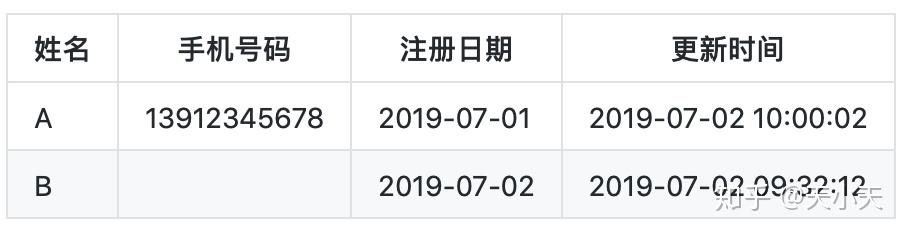
- 2019-07-02日B填写手机号码
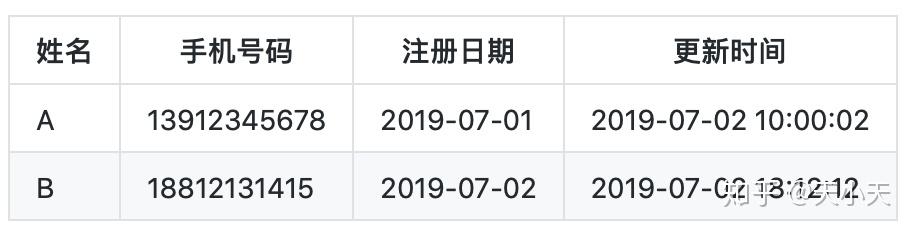
以上罗列了每次修改记录后用户表的变化情况,接下来会介绍拉链表如何实现,及优化的历程
拉链表概述
下面的表结构是用户表对应的拉链表(user_link) 的表结构:

其中相对于原始表增加两个字段分别为:生效日期和失效日期,这两个字段代表每条记录的有效区间
一般来讲,拉链表的更新是按天更新的。所以接下来我们分别看下7月1日和7月2日拉链表的记录
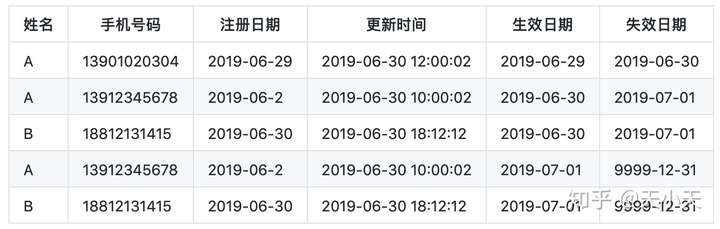
截止7月1日全量数据

当天只有A注册了用户,表数据如上表。其中生效日期为记录插入的时间(即2019-07-01)
同时由于这条记录是有效记录所以失效时间用一个很大的日期占位(即9999-12-31)
截止7月2日全量数据
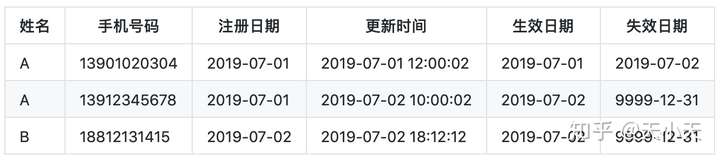
用户A在7月2日更新过手机号码,此时拉链表会留下两条A的记录
一条是更新手机号之前(即2019-07-01日)的记录,并且失效时间更改为2019-07-02
一条是更新手机号码之后(即2019-07-02日)的记录,并且生效日期为2019-07-02,失效日期为9999-12-31
用户B在7月2日有两次操作,一次是注册,一次是更新手机号码
但是在拉链表中只保留当日最新的记录
查询方式
想要查询2019-07-02日的快照的查询语句如下:
select * from user_link where st_date<='2019-07-02' and end_date>'2019-07-02'
如果想要查询2019-07-01至2019-07-02的数据查询语句如下:
select * from user_link where st_date<='2019-07-02' and end_date>'2019-07-01'
- 上面的查询语句会查出两条姓名为A的数据
- 如果想要只查询此区间最新的状态可以用主键去重选出生效日期最大的那条记录
简单的分区方式(hive分区)
以上的拉链表是没有分区的,在查询的时候查询效率会非常低
我们可以用生效日期和失效日期作为分区字段来提升查询效率
create table if not exit user_link_partition(
name string,
phone string,
sign_up_date string,
modify_time string
)
partitoned by (start_date string, end_date string)
stored as orc;
生效日期和失效日期作为分区字段
带来查询效率优势的同时也引入了一些问题
- 分区数过多,如果按照一年来算极限的情况下会有 365*365/2=66612.5个分区,这会给NameNode带来压力
- 查询时需要扫描的分区会比较多
- 数据量一定的情况下会引起过多小文件问题
基于以上的问题我们可以做一些优化
按月分区
每月2日把上一月的所有还未失效的数据归并到1日的分区中,并且把start_date改为1日

7月2日在计算2019-07-01日的数据时除了会处理从原始表抽取过来数据之外还会把拉链表中6月30日还未失效的数据抽取过来
此方式可以保证生效和失效日期不会跨月,即使数据还未失效也会移动到新的月份
支持delete
在之前的更新拉链表的方式都是基于原始表的数据,这会导致无法感知数据删除
如果要感知删除的数据成本会很高
一个简单的方式是同步binlog数据,binlog中会标记每条数据的转态,以此方式就能快速知道删除的数据
- binlog流水表(user_binlog)
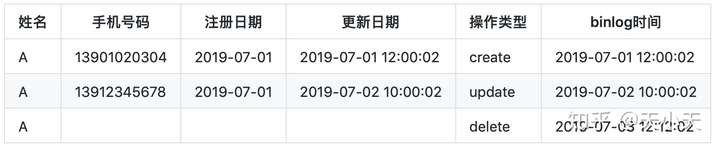
在7月3日的拉链表中就可以通过主键找到要删除的记录,并且把失效日期改为2019-07-03,以此实现拉链表的删除
标签:02,07,拉链,--,数据仓库,日期,2019,数据 来源: https://www.cnblogs.com/YC-L/p/14454632.html