语音识别系列之区分性训练和LF-MMI【转】
作者:互联网
在传统的语音识别中,区分性训练扮演着非常重要的角色,是语音识别学习中的一个重点和难点。如今,端到端的语音识别系统虽初露锋芒,是目前语音识别研究的热点,但在实际工业应用中,传统的语音识别仍然占据着主导地位,区分性训练仍然发挥着重要角色。并且,区分性训练更重要的是其基本思想,相信其思想和基本方法未来也会在端到端的语音识别系统中有广泛应用。所以,值得一写,值得一看,值得一学。
本文介绍区分性训练、其改进版本LF-MMI(Lattice Free Maximum Mutual Information)和Kaldi中的LF-MMI的特定实现chain model。本文在准备过程中参考的相关资料在文末的参考资料中有详列。
本文假定读者已经有了HMM-GMM、DNN、语言模型、解码、Lattice的基本知识。
区分性训练
先回顾下语音识别的基本公式,如下图所示,我们要在给定语音观测序列O的情况下,求词序列W的概率,概率最大的W序列即为最有可能的识别结果。该公式可以通过贝叶斯公式展开,其中
- P(W)称为语言模型,描述词序列W的概率。
- P(O|W)称为为声学模型,描述在W上观测到O的概率。在传统声学模型中,通常不直接使用W,而是使用更细粒度的音素的状态作为声学模型建模单元。
 语音识别目标
语音识别目标
一般声学模型的训练即最大化P(O|W)的概率,称之为最大似然(Maximum Likelihood, ML)的声学模型训练。
那我们可不可以在声学模型的训练中直接最大化P(W|O)?前人说可以,经验证明可以,效果也很不错,并且把这种直接在声学模型训练中直接最大化P(W|O)的训练方法称之为区分性训练(Discriminative Training),并将这种准则称之为MMI(Maximum Mutual Information, 最大互信息,从公式形式上看,很难直接看出P(W|O)和互信息有什么关联,有点类似CRF/CTC等,很难见名知义,可以不用纠结,把MMI直接当个抽象目标函数的专有名词理解该公式更直接更简单)。
进一步,我们分别把ML和MMI的目标函数取log,并在整个数据集上展开,其结果如下图所示(其中MMI用贝叶斯公式先做了展开,再把分母P(O)用全概率公式展开)。
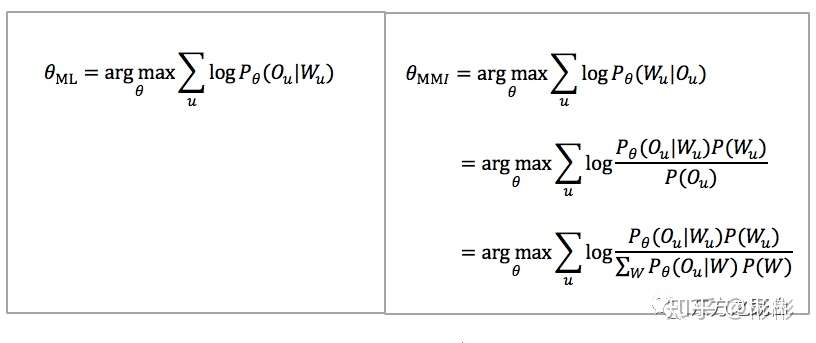 最大似然ML准则和区分性训练MMI准则
最大似然ML准则和区分性训练MMI准则
简单直接的去比较一下这两个目标函数,可以看到:
- ML目标函数仅与正确的标注有关系
- MMI目标函数不仅与正确的标注(分子)有关系,还与其他的所有可能的W序列(分母)有关系;不仅与声学模型有关系,还与语言模型P(W)有关系。要最大化该式,要么使分子尽可能的大,要么使分母尽可能的小,要么同时去优化两者。
到这里,大家可能会有两个明显的问题:
- MMI中的分母虽然可以这样表示,但实际上无法穷举,不具有操作性,怎么办?
- 该式是否对声学模型(GMM/DNN)的参数可求导?
对于问题1,一种方法是对W的可能进行限制,让W是有穷的,可枚举的。并且,前辈们告诉我们,可以使用该语音对应语音识别解码的Lattice近似W。语音识别解码生成的Lattice的示例如下图所示(图示为一个word级别的Lattice),在解码过程中,除了保留最优路径之外,我们还将未被解码器剪枝的其他路径也保存下来,并且合并一些相同的前缀和后缀,表示为图的形式。并且,该图示有穷的,可枚举,Lattice对所有W的近似,相当于通过识别解码仅仅保留了概率大的W,而将大部分小概率的W忽略掉。
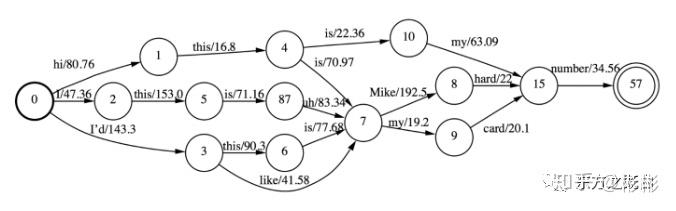 word级别的Lattice
word级别的Lattice
对于问题2,答案也是肯定的。以DNN作为声学模型举例,下图中直接给出ML和MMI目标函数相对于神经网络softmax之前的输出a的倒数(这里W已经被展开成其对应的状态序列S,该公式来源于"Sequence-discriminative training of deep neural networks",详细推导可以参考http://placebokkk.github.io/asr/2019/12/24/asr-paper-se-mmi-note.html),这里仅仅从最终形式上去分析一下两种目标函数在导数上的异同点。
 ML和MMI的梯度公式
ML和MMI的梯度公式
y_ut^DEN(s)解释, 在MMI分母所有可能的序列中在t时刻处于状态s的概率, s_ut是在t时刻对应的对齐状态。
- 两个目标函数,ML最小化,MMI最大化,给MMI目标函数加一个负号,则相应的梯度也加个负号,则两者的梯度形式完全一样,仅仅是y_ut的计算形式不一样。
- ML的y_ut是神经网络在t时刻上计算的s状态的概率值,仅依赖当前帧。MMI的y_ut是在整个序列(Lattice)中在t时候处于状态s的概率,依赖整个Lattice。因为Lattice中即包含语言模型的信息,也包含声学模型的信息,所以最终y_ut的计算同时依赖声学信息和语言信息。
解决了上述两个问题后,我们就可以基于MMI的准则训练声学模型了,区分性训练(MMI)的一般流程如下:
 区分性训练MMI的流程
区分性训练MMI的流程
因为MMI的训练依赖Lattice,Lattice又依赖已经训练好的声学模型,所以在DNN的声学模型中,我们要先基于ML准则先训练好DNN模型,然后做MMI的训练。并且,Lattice是一个解码过程,其生成代价很高,并且只能在CPU上进行解码生成。一般我们只生成一次Lattice,区分性训练的过程中我们并不根据当前更新后的声学模型实时生成Lattice,也就是不使用实时的Lattice做MMI训练。所以在这种方式中,Lattice是滞后的,和当前的声学模型并不同步。
区分性训练曾一度是语音识别的研究热点,除了MMI的准则之外,前人还提出过许多其他的区分性准则,如MCE、MPE、sMBR等等,其核心思想是一样的,形式上也大同小异,读者可以阅读文末的参考资料做进一步了解。目前,除了MMI之外,sMBR也比较常用。
在DNN CE模型的基础上进一步进行区分性训练,一般可以拿到5~15%的收益(WERR)。文章“Sequence-discriminative training of deep neural networks”中进行各种区分性准则训练的结果比较如下表所示,从结果上来看,各个准则都有比较相近稳定的收益。
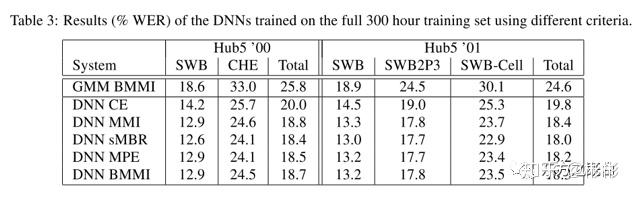 "Sequence-discriminative training of deep neural networks"区分性训练实验
"Sequence-discriminative training of deep neural networks"区分性训练实验
LF-MMI
回到上面的提到的问题1,即MMI中的分母表示,在基于Lattice的MMI训练过程中,我们使用Lattice近似其分母。那还有没有别的方法?
MMI中分母实际上是在考虑W的各种可能,即词序列的各种可能,在语言模型中我们通过统计n-gram的方式表示为概率模型,同样的,这里,我们也可以通过概率统计模型n-gram去表示该分母。假设我们将W表示为一个和语音识别解码时类似的语言模型G,并为MMI分母构建一个类似HCLG的解码图,则该解码图中组合了MMI中的声学模型和语言模型的信息。对于任意特征观测O,我们将该HCLG当作一个巨大的HMM拓扑结构,在该拓扑结构上进行动态前向后向算法(和Lattice不同,Lattice在前向后向算法时,整个时间序列都已经展开,而这里需要根据观测O的长度动态展开成时间序列,和标准的HMM前向后向算法一样),最终可以得到上述所需的y_ut^DEN(s)。
但是,我们提到W一定要是有限的,可枚举的,当MMI分母和语音识别解码图是一样时,即以词Word作为语言模型的单元,一般的语音识别系统词级别在数十万到百万之间,即使做个简单的bi-gram,其复杂度也非常非常高(HCLG的大小),训练代价非常高。为了降低复杂度,考虑以:
- Phone作为语言模型单元。识别系统中Phone的一般在几十个到一百多个,考虑到数据稀疏性,即使做tri-gram或者4-gram复杂度也在合理区间内。以Phone作为建模单元时,MMI的分母图为HCG(没有词典L了,并且G的单元是Phone)。
- State作为语言模型建模单元。识别系统中的State一般在几千个左右,考虑到数据稀疏性,做tri-gram复杂度也在合理区间内。以State作为建模单元时,MMI的分母图为G(G以State作为建模单元,这里State是指上下文相关的CD-State/senone)。
其中,Phone和State的训练语料都可以由语音识别的训练数据通过对齐生成。合理的控制Phone和State的MMI分母的大小,可以将其前向后向计算塞进GPU进行计算,也就是将MMI训练迁移到GPU,从而大大提高了MMI的训练速度。在业界中,Phone和State的两者都有实际应用。Kaldi的chain model中,使用Phone作为MMI分母建模单元。在一些其他工作或文章中,如"Achieving Human Parity in Conversational Speech Recognition"这篇文章中,以State作为MMI分母的建模单元,该论文中的结果如下表所示,可以看到,LF-MMI也拿到了合理的收益,其收益和Lattice based的MMI收益相近。
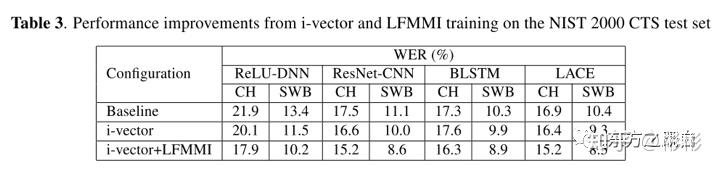 "Achieving Human Parity in Conversational Speech Recognition" LF-MMI实验结果
"Achieving Human Parity in Conversational Speech Recognition" LF-MMI实验结果
当使用语言模型的思想表示MMI的分母时,我们无需再对训练语料进行解码,无需生成Lattice,所以称之为Lattice Free MMI(LF-MMI)。对于所有训练语料来讲,MMI的分母图是以一样的,并且,因为我们限制了MMI分母图的空间,该前向后向算法是on-the-fly的,在训练过程中直接计算,其与声学模型是同步更新。LF-MMI的训练流程如下:
 LF-MMI训练流程
LF-MMI训练流程
Kaldi chain model
Kaldi中的chain model是kaldi中关于LF-MMI的一种实现,但其有如下优点:
- 从初始化的模型直接使用LF-MMI准则训练,无需基于DNN CE model,简化了区分性训练的流程。chain model的训练流程如下图所示:
- 更好的识别率。chain model有着比先使用CE而后MMI更好的效果,是Kaldi中目前大部分标准数据集上最好的识别率的模型,是Kaldi中的标准配置。
- 快速的训练和解码。Kaldi中采用了一些列技巧,加速训练和解码。
 Kaldi chain model训练流程
Kaldi chain model训练流程
从最终chain model的实现和训练策略上来看,chain model中采用了一系列的tirck,稳定、加速训练,提升模型效果,用的多了,会觉得这个模型好复杂,但本质上来讲,其基本思想仍是LF-MMI。所以这里理解这些tirck的方法就是It just works,^_^。
chain model中比较重要的tirck有:
- HMM拓扑结构改变,从标准的三状态改为单状态的HMM。
- 帧率从10ms降低到30ms。
- MMI分母使用Phone作为语言模型建模单元,最终表示为HCG,且为简化,C为bi-phone。
- 训练数据均做等长(1.5s)切分,分子使用该句话的Lattice表示。且在分子Lattice上引入一定时间扰动。
- CE正则化。训练时同时引入CE作为第二个任务进行multi task learning。所以,最终chain model的网络结构如下图所示:
- L2正则化/Leaky HMM等
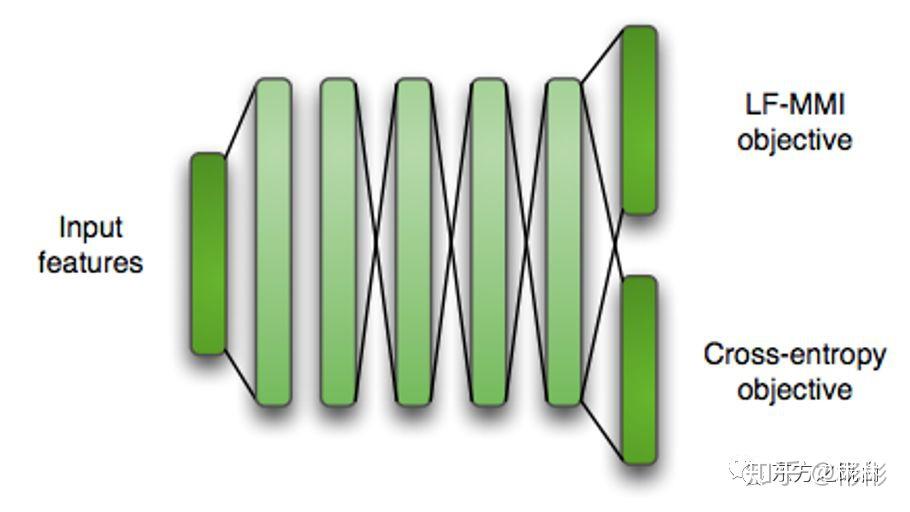 Kaldi chain model网络结构
Kaldi chain model网络结构
关于这些tirck详细的说明和实验结果详情参考"Purely sequence-trained neural networks for ASR based on lattice-free MMI",这里直接给出原文中chain model在各个数据集上最终的实验结果,如下表所示:
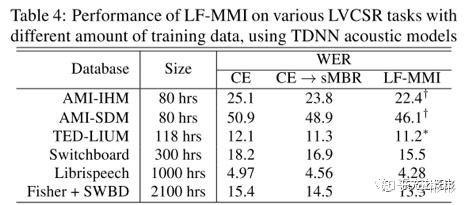 "Purely sequence-trained neural networks for ASR based on lattice-free MMI"实验结果
"Purely sequence-trained neural networks for ASR based on lattice-free MMI"实验结果
可以看到:1) chain model的LF-MMI比CE->sMBR效果好;2) chain model的LF-MM在不同数据集,不同大小的数据集上收益都很稳定。
总结
如下图所示,本文先介绍了基于Lattice的区分性训练,再到LF-MMI,再到chain model,可以看到语音识别的流程在逐步简化。并且,我们在追求进一步的简化,目前看到的工作有:
- 声学模型层面的简化:不依赖GMM-HMM系统,直接进行基于DNN的声学模型训练,如E2E-LF-MMI、CTC、CRF-CTC。
- 整个语音识别简化,即当下研究热点End to End的语音识别系统,如CTC、LAS、RNN-T、Transformer。
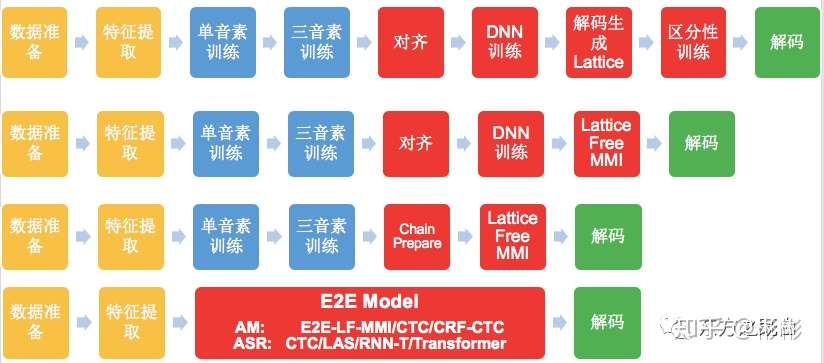 区分性训练/LF-MMI/Kaldi chain model/E2E模型系统流程对比
区分性训练/LF-MMI/Kaldi chain model/E2E模型系统流程对比
参考资料
- 2007 - Gales, Young - The application of hidden Markov Models in speech recognition
- 2013 - Veselý et al. - Sequence-discriminative training of deep neural networks
- 2016 - Povey et al. - Purely sequence-trained neural networks for ASR based on lattice-free MMI
- 2016 - Xiong et al. - Achieving Human Parity in Conversational Speech Recognition
- 2018 - Hadian et al. - End-to-end speech recognition using lattice-free MMI
- 2019 - Peter Bell - Lattice-free MMI(lecture, http://www.inf.ed.ac.uk/teaching/courses/asr/2018-19/asr12-lfmmi.pdf)
- 2020 – Chao Yang - Sequence-discriminative training of DNNs笔记(blog,http://placebokkk.github.io/asr/2019/12/24/asr-paper-se-mmi-note.html)
来源:https://zhuanlan.zhihu.com/p/113715935?utm_source=wechat_session
标签:LF,训练,模型,Lattice,MMI,语音,model,分母 来源: https://www.cnblogs.com/tibetanmastiff/p/14419947.html